Escenario 5: supervisión de datos de telemetría en tiempo real con Apache Kafka
ABC1Cabs es una empresa de servicios de reserva de taxis en línea. Todos los taxis tienen dispositivos IoT que recopilan datos de telemetría de los vehículos. Actualmente, ABC1Cabs ejecuta clústeres de Apache Kafka que están diseñados para el consumo de eventos en tiempo real, recopilan métricas de estado del sistema, realizan el seguimiento de la actividad e incorporan datos en la plataforma Apache Spark Streaming, basada en un clúster de Hadoop local.
ABC1Cabs utiliza OpenSearch Dashboards para métricas empresariales, depuración, alertas y creación de otros paneles. Tiene interés en Amazon MSK, Amazon EMR con Spark Streaming y OpenSearch Service con OpenSearch Dashboards. Su requisito es reducir la sobrecarga administrativa para mantener los clústeres de Apache Kafka y Hadoop, al tiempo que utilizan API y software de código abierto conocidos para orquestar su canalización de datos. El siguiente diagrama de arquitectura muestra su solución en AWS.
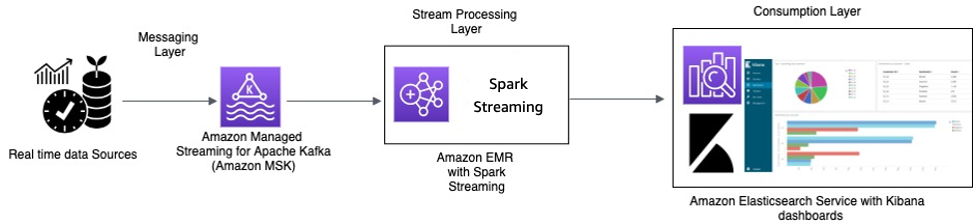
Procesamiento en tiempo real con Amazon MSK y procesamiento de secuencias mediante Apache Spark Streaming en Amazon EMR y Amazon OpenSearch Service con OpenSearch Dashboards
Los dispositivos IoT del taxi recopilan datos de telemetría y los envían a un concentrador de origen. El concentrador de origen está configurado para enviar datos en tiempo real a Amazon MSK. Con las API de la biblioteca del productor de Apache Kafka, Amazon MSK se ha configurado para transmitir los datos en un clúster de Amazon EMR. El clúster de Amazon EMR tiene un cliente de Kafka y Spark Streaming instalados para poder consumir y procesar las secuencias de datos.
Spark Streaming tiene conectores receptores que pueden escribir datos directamente en índices definidos de Elasticsearch. Los clústeres de Elasticsearch con OpenSearch Dashboards se pueden usar para las métricas y los paneles. Amazon MSK, Amazon EMR con Spark Streaming y OpenSearch Service con OpenSearch Dashboards son servicios administrados, en los que AWS administra el pesado trabajo indiferenciado de la administración de la infraestructura de diferentes clústeres, lo que le permite crear su aplicación utilizando un software de código abierto familiar con unos pocos clics. La siguiente sección analiza en detalle estos servicios.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Apache Kafka es una plataforma de código abierto que permite a los clientes capturar datos de streaming como eventos de streaming de clics, transacciones, eventos de IoT y registros de aplicaciones y máquinas. Con esta información, puede desarrollar aplicaciones que realicen análisis en tiempo real, ejecuten transformaciones continuas y distribuyan estos datos a lagos de datos y bases de datos en tiempo real.
Puede usar Kafka como almacén de datos de streaming para desacoplar las aplicaciones del productor y los consumidores, y permitir una transferencia de datos fiable entre los dos componentes. Si bien Kafka es una conocida plataforma de streaming de datos y mensajería empresarial, puede resultar difícil de configurar, escalar y administrar en producción.
Amazon MSK se encarga de estas tareas de administración y facilita la preparación, la configuración y la ejecución de Kafka, junto con Apache Zookeeper, en un entorno que sigue las prácticas recomendadas para ofrecer alta disponibilidad y seguridad. Aún puede usar las operaciones del plano de control y las operaciones del plano de datos de Kafka para administrar la producción y el consumo de datos.
Como Amazon MSK ejecuta y administra Apache Kafka de código abierto, facilita a los clientes migrar y ejecutar aplicaciones Apache Kafka existentes en AWS sin necesidad de realizar cambios en su código de aplicación.
Escalado
Amazon MSK ofrece operaciones de escalado para que el usuario pueda escalar el clúster de forma activa mientras está en ejecución. Al crear un clúster de Amazon MSK, puede especificar el tipo de instancia de los agentes en el lanzamiento del clúster. Puede empezar con unos pocos agentes en un clúster de Amazon MSK y, a continuación, con AWS Management Console o AWS CLI, puede escalar hasta cientos de agentes por clúster.
De manera alternativa, puede escalar sus clústeres al cambiar el tamaño o la familia de sus agentes de Apache Kafka. Cambiar el tamaño o la familia de los agentes proporciona la flexibilidad de ajustar la capacidad de computación de los clústeres de Amazon MSK en función de los cambios en las cargas de trabajo. Utilice la hoja de cálculo de tamaños y precios de Amazon MSK
Después de crear el clúster de Amazon MSK, puede aumentar la cantidad de almacenamiento de EBS por agente, con la excepción de reducir el almacenamiento. Los volúmenes de almacenamiento siguen estando disponibles durante esta operación de ampliación. Ofrece dos tipos de operaciones de escalado: automático y manual.
Amazon MSK admite la expansión automática del almacenamiento de su clúster para responder al aumento del uso mediante políticas de escalado automático de aplicaciones. La política de escalado automático establece el uso de disco de destino y la capacidad de escalado máxima.
El umbral de utilización de almacenamiento ayuda a Amazon MSK a desencadenar una operación de escalado automático. Para aumentar el almacenamiento mediante el escalado manual, espere a que el clúster se encuentre en el estado ACTIVE. El escalado del almacenamiento tiene un período de recuperación de al menos seis horas entre eventos. Aunque la operación hace que haya almacenamiento adicional disponible de inmediato, el servicio realiza optimizaciones en el clúster que pueden tardar 24 horas o más.
La duración de estas optimizaciones es proporcional al tamaño del almacenamiento. Además, también ofrece replicación de múltiples zonas de disponibilidad en una región de AWS para proporcionar alta disponibilidad.
Configuración
Amazon MSK ofrece una configuración predeterminada para agentes, temas y nodos de Apache Zookeeper. También puede crear configuraciones personalizadas y utilizarlas para crear nuevos clústeres de Amazon MSK o actualizar clústeres existentes. Al crear un clúster de MSK sin especificar una configuración de Amazon MSK personalizada, Amazon MSK crea y utiliza una configuración predeterminada. Para obtener una lista de valores predeterminados, consulte esta configuración de Apache Kafka.
Con fines de supervisión, Amazon MSK recopila métricas de Apache Kafka y las envía a Amazon CloudWatch, donde puede consultarlas. Las métricas que configure para su clúster de MSK se recopilan y envían automáticamente a CloudWatch. La supervisión del retraso del consumidor le permite identificar a los consumidores lentos o atascados que no se mantienen actualizados con los datos más recientes disponibles en un tema. Cuando sea necesario, puede tomar medidas correctivas, como escalar o reiniciar esos consumidores.
Migración a Amazon MSK
La migración desde un entorno local a Amazon MSK se puede lograr mediante uno de los siguientes métodos.
-
MirrorMaker2.0: MirrorMaker2.0 (MM2) MM2 es un motor de replicación de datos de varios clústeres basado en el marco Apache Kafka Connect. MM2 es una combinación de un conector de origen Apache Kafka y un conector de receptor. Puede usar un único clúster MM2 para migrar datos entre varios clústeres. MM2 detecta automáticamente los nuevos temas y particiones, a la vez que garantiza que las configuraciones de los temas se sincronicen de un clúster a otro. MM2 admite migraciones de ACL, configuraciones de temas y traducción de desplazamiento. Para obtener más detalles relacionados con la migración, consulte Migración de clústeres mediante MirrorMaker de Apache Kafka. MM2 se utiliza para casos de uso relacionados con la replicación de configuraciones de temas y la traslación compensada automáticamente.
-
Apache Flink: MM2 admite al menos una vez semántica. Los registros se pueden duplicar en el destino y se espera que los consumidores sean idempotentes para gestionar los registros duplicados. En escenarios de exactamente una vez, se requiere semántica y los clientes pueden usar Apache Flink. Proporciona una alternativa para lograr exactamente una sola semántica.
Apache Flink también se puede usar para escenarios en los que los datos requieren acciones de asignación o transformación antes de enviarlos al clúster de destino. Apache Flink proporciona conectores para Apache Kafka con orígenes y receptores que pueden leer datos de un clúster de Apache Kafka y escribir en otro. Apache Flink se puede ejecutar en AWS mediante el lanzamiento de un clúster de Amazon EMR o mediante la ejecución de Apache Flink como una aplicación mediante Amazon Kinesis Data Analytics.
-
AWS Lambda: con compatibilidad con Apache Kafka como origen de eventos para AWS Lambda
, los clientes ahora pueden consumir mensajes de un tema mediante una función Lambda. El servicio AWS Lambda sondea internamente en busca de nuevos registros o mensajes del origen de eventos y, a continuación, invoca de forma sincrónica la función Lambda de destino para consumir estos mensajes. Lambda lee los mensajes en lotes y proporciona los lotes de mensajes a su función en la carga del evento para su procesamiento. Los mensajes consumidos se pueden transformar o escribir directamente en el clúster de Amazon MSK de destino.
Amazon EMR con Spark Streaming
Amazon EMR
Amazon EMR proporciona las capacidades de Spark y se puede usar para iniciar Spark Streaming para consumir datos de Kafka. Spark Streaming es una extensión de la API principal de Spark que permite el procesamiento de secuencias de datos en directo escalable, de alto rendimiento y con tolerancia a errores.
Puede crear un clúster de Amazon EMR con AWS Command Line Interface
Los datos procesados se pueden enviar a sistemas de archivos, bases de datos y paneles en directo.
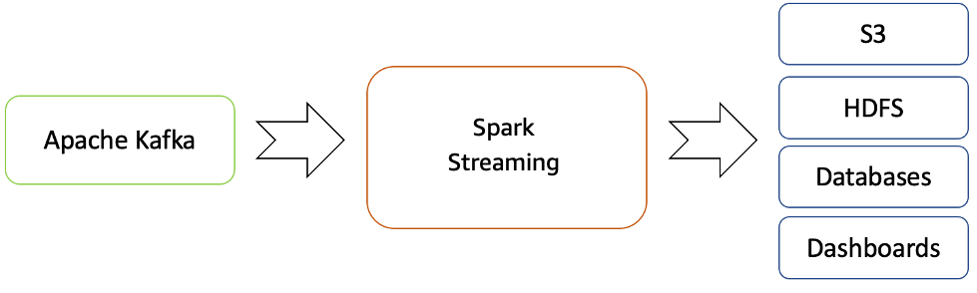
Flujo de streaming en tiempo real desde el ecosistema de Apache Kafka a Hadoop
De forma predeterminada, Apache Spark Streaming tiene un modelo de ejecución de microlotes. Sin embargo, desde que se lanzó Spark 2.3, Apache ha incorporado un nuevo modo de procesamiento de baja latencia llamado procesamiento continuo, que puede lograr latencias de extremo a extremo de hasta un milisegundo con garantías de «al menos una vez».
Sin cambiar las operaciones de Dataset/DataFrames en sus consultas, puede elegir el modo en función de los requisitos de su aplicación. Algunas de los beneficios de Spark Streaming son:
-
Lleva la API integrada en el lenguaje
de Apache Spark al procesamiento de secuencias, lo que le permite escribir trabajos de streaming de la misma manera que escribe trabajos por lotes. -
Es compatible con Java, Scala y Python.
-
Puede recuperar tanto el trabajo perdido como el estado del operador (como ventanas deslizantes) desde el primer momento, sin código adicional de su parte.
-
Al ejecutarse en Spark, Spark Streaming te permite reutilizar el mismo código para el procesamiento por lotes, unir transmisiones con datos históricos o ejecutar consultas ad hoc sobre el estado de la secuencia y crear aplicaciones interactivas potentes, no solo análisis.
-
Después de procesar el flujo de datos con Spark Streaming, se puede usar OpenSearch Sink Connector para escribir datos en el clúster de OpenSearch Service y, a su vez, OpenSearch Service con OpenSearch Dashboards se puede usar como capa de consumo.
Amazon OpenSearch Service con OpenSearch Dashboards
OpenSearch Service es un servicio administrado que facilita las tareas de implementación, operación y escalado de clústeres OpenSearch en la nube de AWS. OpenSearch es un conocido motor de búsqueda y análisis, y de código abierto para casos de uso como análisis de registros, supervisión de aplicaciones en tiempo real y análisis de secuencias de clics.
OpenSearch Dashboards
OpenSearch Dashboards proporciona una estrecha integración con OpenSearch
Resumen
Con Apache Kafka ofrecido como un servicio administrado en AWS, puede centrarse en el consumo en lugar de en administrar la coordinación entre los agentes, lo que generalmente requiere una comprensión detallada de Apache Kafka. La plataforma Amazon MSK administra funciones como la alta disponibilidad, la escalabilidad de los agentes y el control de acceso detallado.
ABC1Cabs utilizó estos servicios para crear aplicaciones de producción sin necesidad de tener experiencia en administración de la infraestructura. Podía centrarse en la capa de procesamiento para consumir datos de Amazon MSK y propagarlos a la capa de visualización.
Spark Streaming en Amazon EMR puede ayudar a realizar análisis en tiempo real de datos de transmisión y publicar en OpenSearch Dashboards
