Paso 1: Recopilar y agregar datos
En la siguiente figura se muestra un modelo mental para el problema de previsión. El objetivo es prever la serie temporal z_t en el futuro, utilizando la mayor cantidad de información relevante posible para que la previsión sea lo más precisa posible. Por lo tanto, el primer paso, y el más importante, es recopilar la mayor cantidad posible de datos correctos.
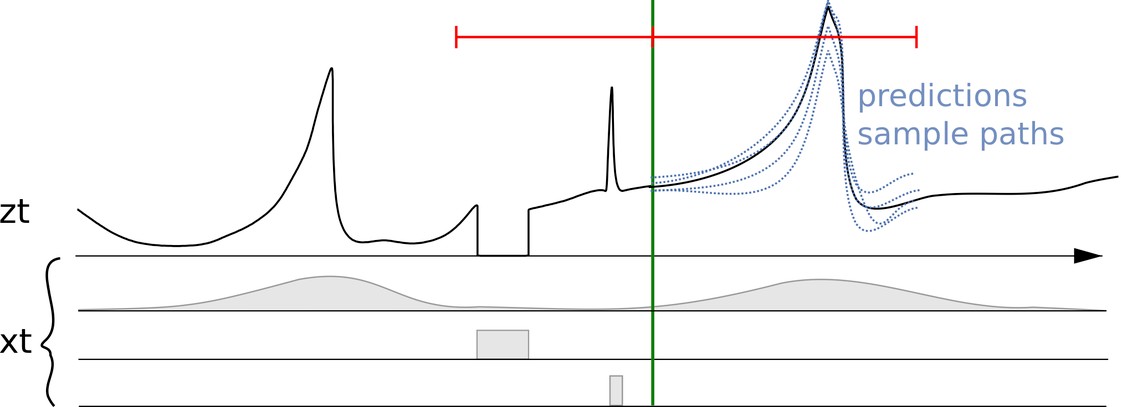
Una serie temporal z_t junto con características o covariables asociadas (x_t) y múltiples previsiones
En la figura anterior, se muestran varias previsiones a la derecha de la línea vertical. Estas previsiones son muestras de la distribución de la previsión probabilística (o, a la inversa, se pueden utilizar para representar la previsión probabilística).
La información clave que debe registrar una empresa de venta minorista es:
-
Los datos de ventas de las transacciones: por ejemplo, las unidades de mantenimiento de existencias (SKU), la ubicación, la marca temporal y las unidades vendidas.
-
Datos de detalles del artículo de la SKU: los metadatos de un producto. Por ejemplo, el color, el departamento, el tamaño, etc.
-
Datos de precios: la serie temporal de precios de cada producto con marcas temporales.
-
Datos informativos sobre promociones: diferentes tipos de promociones, ya sea sobre un conjunto de productos (categoría) o sobre productos individuales con marcas temporales.
-
Datos informativos sobre existencias: para cada unidad de tiempo, la información sobre si una SKU está en existencias o se puede adquirir o bien si esa SKU se ha agotado.
-
Datos de ubicación: la ubicación de un producto o una venta en un momento determinado se puede representar como una cadena
location_idostore_id, o bien como una geolocalización real. Las geolocalizaciones pueden ser un código de país más un código postal de cinco dígitos, o bien coordenadaslatitude_longitude. La ubicación se considera una "dimensión" de las ventas transaccionales.
En Amazon Forecast
Tenga en cuenta que la información sobre las existencias es importante, ya que este problema se centra en la previsión de la demanda y no en las ventas, pero la empresa solo registra las ventas. Cuando una SKU se agota, el número de ventas es inferior a la demanda potencial, por lo que es importante saber y registrar cuándo se producen dichos eventos de agotamiento de existencias.
Otros conjuntos de datos que se deben tener en cuenta incluyen el número de visitas a la página web, los detalles sobre los términos de búsqueda, las redes sociales y la información meteorológica. A menudo es importante disponer de datos del pasado y del futuro para poder utilizarlos en los modelos. Este es un requisito de muchos modelos de previsión y de pruebas retrospectivas (esto se describe en la sección Paso 4: Evaluar las previsiones).
Para algunos problemas de previsión, la frecuencia de los datos sin procesar coincide naturalmente con la del problema de previsión. Entre algunos ejemplos se incluyen la solicitud del volumen del servidor, que se muestrea por minuto, cuando se desea prever con una frecuencia de minutos.
A menudo, los datos se registran con una frecuencia más precisa o simplemente en marcas temporales arbitrarias dentro de un rango de tiempo, pero el problema de la previsión pertenece a un nivel de granularidad menos específico. Esto es algo habitual en los casos prácticos de venta minorista, en los que los datos de ventas se registran normalmente como datos transaccionales; por ejemplo, el formato consiste en una marca de tiempo con una alta granularidad del momento en que se produjeron las ventas. En el caso práctico de la previsión, puede que este nivel de granularidad no sea necesario y podría ser más apropiado agregar estos datos en ventas totales por hora o por día. En este caso, el nivel de agregación debe adecuarse al problema posterior; por ejemplo, la gestión del inventario o la planificación de recursos.
Ejemplo
En la siguiente figura, el gráfico de la izquierda muestra un ejemplo de los datos de ventas de clientes sin procesar que se pueden introducir en Amazon Forecast como un archivo de valores separados por comas (CSV). En este ejemplo, los datos de ventas se definen en una cuadrícula horaria diaria más precisa y el problema consiste en prever la demanda semanal futura en una cuadrícula horaria más general. Amazon Forecast realiza la agregación de los valores diarios de una semana determinada en la llamada a la API create_predictor.
El resultado transforma los datos sin procesar en una colección de series temporales bien formadas con una frecuencia semanal fija. El gráfico de la derecha ilustra esta agregación en la serie temporal objetivo mediante el método de agregación por suma predeterminado. Otros métodos de agregación son por media, por máximo, por mínimo o por elección de un solo punto (por ejemplo, el primero). El nivel de granularidad y el método de agregación deben elegirse de manera que se adapten mejor al caso práctico empresarial de los datos. En este ejemplo, el valor agregado se alinea con la agregación semanal. El usuario puede configurar otros métodos de agregación mediante la clave FeaturizationMethodParameters del parámetro FeaturizationConfig de la API create_predictor.
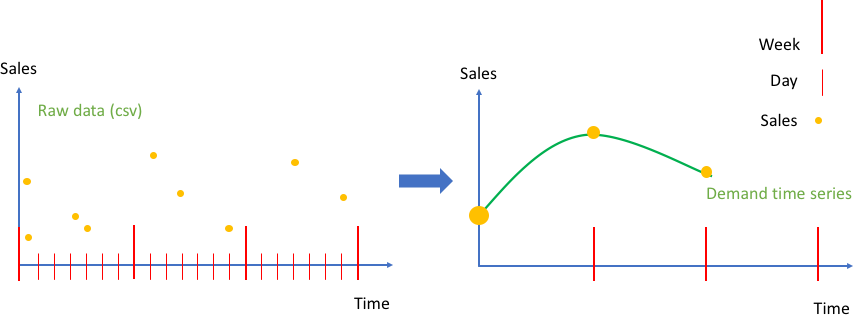
Agregación de datos de ventas sin procesar como eventos (izquierda), en una serie temporal espaciada a intervalos regulares (derecha)
