Amazon Forecast is no longer available to new customers. Existing customers of
Amazon Forecast can continue to use the service as normal.
Learn more"
DeepAR+ Algorithm
Amazon Forecast DeepAR+ is a supervised learning algorithm for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNNs). Classical forecasting methods, such as autoregressive integrated moving average (ARIMA) or exponential smoothing (ETS), fit a single model to each individual time series, and then use that model to extrapolate the time series into the future. In many applications, however, you have many similar time series across a set of cross-sectional units. These time-series groupings demand different products, server loads, and requests for web pages. In this case, it can be beneficial to train a single model jointly over all of the time series. DeepAR+ takes this approach. When your dataset contains hundreds of feature time series, the DeepAR+ algorithm outperforms the standard ARIMA and ETS methods. You can also use the trained model for generating forecasts for new time series that are similar to the ones it has been trained on.
Python notebooks
For a step-by-step guide on using the DeepAR+ algorithm, see Getting Started with DeepAR+
How DeepAR+ Works
During training, DeepAR+ uses a training dataset and an optional testing dataset. It uses
the testing dataset to evaluate the trained model. In general, the training and testing
datasets don't have to contain the same set of time series. You can use a model trained on a
given training set to generate forecasts for the future of the time series in the training
set, and for other time series. Both the training and the testing datasets consist of
(preferably more than one) target time series. Optionally, they can be associated with a
vector of feature time series and a vector of categorical features (for details, see DeepAR
Input/Output Interface in the SageMaker AI Developer
Guide). The following example shows how this works for an element of a training
dataset indexed by i. The training dataset consists of a target time series,
zi,t, and two associated feature time series,
xi,1,t and
xi,2,t.
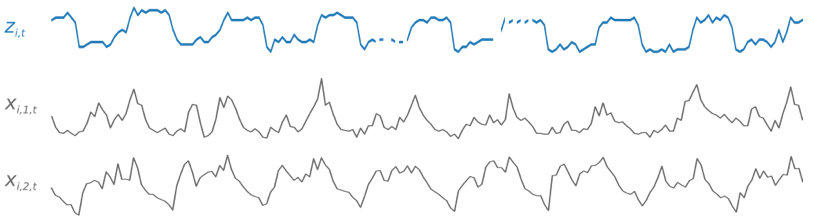
The target time series might contain missing values (denoted in the graphs by breaks in the time series). DeepAR+ supports only feature time series that are known in the future. This allows you to run counterfactual "what-if" scenarios. For example, "What happens if I change the price of a product in some way?"
Each target time series can also be associated with a number of categorical features. You can use these to encode that a time series belongs to certain groupings. Using categorical features allows the model to learn typical behavior for those groupings, which can increase accuracy. A model implements this by learning an embedding vector for each group that captures the common properties of all time series in the group.
To facilitate learning time-dependent patterns, such as spikes during weekends, DeepAR+
automatically creates feature time series based on time-series granularity. For example,
DeepAR+ creates two feature time series (day of the month and day of the year) at a weekly
time-series frequency. It uses these derived feature time series along with the custom feature
time series that you provide during training and inference. The following example shows two
derived time-series features: ui,1,t represents the hour
of the day, and ui,2,t the day of the week.

DeepAR+ automatically includes these feature time series based on the data frequency and the size of training data. The following table lists the features that can be derived for each supported basic time frequency.
| Frequency of the Time Series | Derived Features |
|---|---|
| Minute | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| Hour | hour-of-day, day-of-week, day-of-month, day-of-year |
| Day | day-of-week, day-of-month, day-of-year |
| Week | week-of-month, week-of-year |
| Month | month-of-year |
A DeepAR+ model is trained by randomly sampling several training examples from each of the
time series in the training dataset. Each training example consists of a pair of adjacent
context and prediction windows with fixed predefined lengths. The context_length
hyperparameter controls how far in the past the network can see, and the
ForecastHorizon parameter controls how far in the future predictions can be
made. During training, Amazon Forecast ignores elements in the training dataset with time
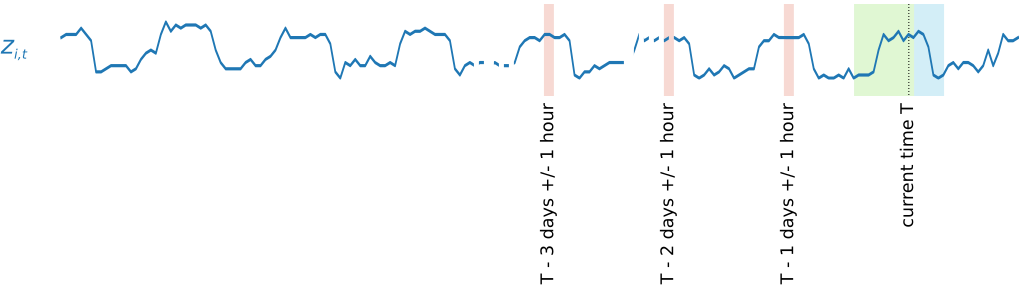
series shorter than the specified prediction length. The following example shows five samples,
with a context length (highlighted in green) of 12 hours and a prediction length (highlighted
in blue) of 6 hours, drawn from element i. For the sake of brevity, we've
excluded the feature time series xi,1,t and
ui,2,t.

To capture seasonality patterns, DeepAR+ also automatically feeds lagged (past period)
values from the target time series. In our example with samples taken at an hourly frequency,
for each time index t = T, the model exposes the
zi,t values which occurred approximately one, two, and
three days in the past (highlighted in pink).
For inference, the trained model takes as input the target time series, which might or
might not have been used during training, and forecasts a probability distribution for the
next ForecastHorizon values. Because DeepAR+ is trained on the entire dataset,
the forecast takes into account learned patterns from similar time series.
For information on the mathematics behind DeepAR+, see DeepAR: Probabilistic Forecasting with Autoregressive
Recurrent Networks
DeepAR+ Hyperparameters
The following table lists the hyperparameters that you can use in the DeepAR+ algorithm. Parameters in bold participate in hyperparameter optimization (HPO).
| Parameter Name | Description |
|---|---|
context_length |
The number of time points that the model reads in before making the prediction.
The value for this parameter should be about the same as the
|
epochs |
The maximum number of passes to go over the training data. The optimal value depends on your data size and learning rate. Smaller datasets and lower learning rates both require more epochs, to achieve good results.
|
learning_rate |
The learning rate used in training.
|
learning_rate_decay |
The rate at which the learning rate decreases. At most, the learning rate is
reduced
|
likelihood |
The model generates a probabilistic forecast, and can provide quantiles of the distribution and return samples. Depending on your data, choose an appropriate likelihood (noise model) that is used for uncertainty estimates. Valid values
|
max_learning_rate_decays |
The maximum number of learning rate reductions that should occur.
|
num_averaged_models |
In DeepAR+, a training trajectory can encounter multiple models. Each model might have different forecasting strengths and weaknesses. DeepAR+ can average the model behaviors to take advantage of the strengths of all models.
|
num_cells |
The number of cells to use in each hidden layer of the RNN.
|
num_layers |
The number of hidden layers in the RNN.
|
Tune DeepAR+ Models
To tune Amazon Forecast DeepAR+ models, follow these recommendations for optimizing the training process and hardware configuration.
Best Practices for Process Optimization
To achieve the best results, follow these recommendations:
-
Except when splitting the training and testing datasets, always provide entire time series for training and testing, and when calling the model for inference. Regardless of how you set
context_length, don't divide the time series or provide only a part of it. The model will use data points further back thancontext_lengthfor the lagged values feature. -
For model tuning, you can split the dataset into training and testing datasets. In a typical evaluation scenario, you should test the model on the same time series used in training, but on the future
ForecastHorizontime points immediately after the last time point visible during training. To create training and testing datasets that satisfy these criteria, use the entire dataset (all of the time series) as a testing dataset and remove the lastForecastHorizonpoints from each time series for training. This way, during training, the model doesn't see the target values for time points on which it is evaluated during testing. In the test phase, the lastForecastHorizonpoints of each time series in the testing dataset are withheld and a prediction is generated. The forecast is then compared with the actual values for the lastForecastHorizonpoints. You can create more complex evaluations by repeating time series multiple times in the testing dataset, but cutting them off at different end points. This produces accuracy metrics that are averaged over multiple forecasts from different time points. -
Avoid using very large values (> 400) for the
ForecastHorizonbecause this slows down the model and makes it less accurate. If you want to forecast further into the future, consider aggregating to a higher frequency. For example, use5mininstead of1min. -
Because of lags, the model can look further back than
context_length. Therefore, you don't have to set this parameter to a large value. A good starting point for this parameter is the same value as theForecastHorizon. -
Train DeepAR+ models with as many time series as are available. Although a DeepAR+ model trained on a single time series might already work well, standard forecasting methods such as ARIMA or ETS might be more accurate and are more tailored to this use case. DeepAR+ starts to outperform the standard methods when your dataset contains hundreds of feature time series. Currently, DeepAR+ requires that the total number of observations available, across all training time series, is at least 300.
