Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Haute disponibilité avec les groupes de réplication
Les clusters Amazon ElastiCache Redis OSS à nœud unique sont des entités en mémoire dotées de services de protection des données (AOF) limités. Si votre cluster échoue pour une raison quelconque, vous perdez toutes les données du cluster. Toutefois, si vous utilisez le moteur Redis OSS, vous pouvez regrouper 2 à 6 nœuds dans un cluster avec des répliques où 1 à 5 nœuds en lecture seule contiennent les données de réplication du nœud principal en lecture/écriture unique du groupe. Dans ce scénario, si un nœud échoue pour une raison quelconque, vous ne perdez pas toutes vos données puisque celles-ci sont répliquées sur un ou plusieurs nœuds. Du fait de la latence de la réplication, des données pourraient être perdues si c'est le nœud de lecture/écriture primaire qui échoue.
Comme le montre le graphique suivant, la structure de réplication est contenue dans une partition (appelée groupe de nœuds dans l'API/CLI) contenue dans un cluster Redis OSS. Les clusters Redis OSS (mode cluster désactivé) ont toujours une partition. Les clusters Redis OSS (mode cluster activé) peuvent contenir jusqu'à 500 partitions, les données du cluster étant partitionnées entre les partitions. Vous pouvez créer un cluster contenant un nombre de partitions supérieur et un nombre de réplicas inférieur, qui conduisent à un nombre total de 90 nœuds par cluster. Cette configuration de cluster peut contenir de 90 partitions avec 0 réplica à 15 partitions avec 5 réplicas, ce qui correspond au nombre maximal de réplicas autorisé.
La limite de nœuds ou de partitions peut être augmentée jusqu'à un maximum de 500 par cluster si la version du moteur Redis OSS est 5.0.6 ou supérieure. Par exemple, vous pouvez choisir de configurer un cluster de 500 nœuds compris entre 83 (un principal et 5 réplicas par partition) et 500 partitions (un principal et aucun réplicas). Assurez-vous qu’il y ait suffisamment d’adresses IP disponibles pour faire face à l’augmentation. Les pièges courants incluent les sous-réseaux du groupe de sous-réseaux avec une plage CIDR trop petite ou les sous-réseaux partagés et fortement utilisés par d’autres clusters. Pour plus d’informations, consultez Création d'un groupe de sous-réseaux.
Pour les versions antérieures à 5.0.6, la limite est de 250 par cluster.
Pour demander une augmentation de cette limite, veuillez consulter AWS Service Limits et sélectionnez le type de limite Nœuds par cluster par type d'instance.
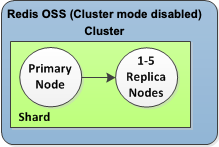
Le cluster Redis OSS (mode cluster désactivé) possède une partition et 0 à 5 nœuds de réplication
Si le mode Multi-AZ est activé pour le cluster avec réplicas et que le nœud principal échoue, le cluster bascule vers un réplica en lecture. Etant donné que les données sont mises à jour de façon asynchrone sur les nœuds de réplica, des données peuvent être perdues du fait de la latence des mises à jour des nœuds de réplication. Pour plus d'informations, voir Atténuer les défaillances lors de l'exécution de Redis OSS.
Rubriques
- Comprendre la réplication Redis OSS
- Réplication : Redis OSS (mode cluster désactivé) contre Redis OSS (mode cluster activé)
- Minimiser les temps d'arrêt dans ElastiCache (Redis OSS) grâce à la technologie multi-AZ
- Implémentation de la sauvegarde et de la synchronisation
- Création d'un groupe de réplication Redis OSS
- Affichage des détails d'un groupe de réplication
- Recherche des points de terminaison du groupe de réplication
- Modification d'un groupe de réplication
- Suppression d'un groupe de réplication
- Modification du nombre de réplicas
- Promotion d'une réplique en lecture au statut principal, pour les groupes de réplication Redis OSS (mode cluster désactivé)
