Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Résolution des problèmes de charge de travail pour les bases de données Aurora MySQL
La charge de travail de la base de données peut être considérée sous forme de lectures et d'écritures. En comprenant la charge de travail « normale » des bases de données, vous pouvez ajuster les requêtes et le serveur de base de données pour répondre à la demande à mesure qu'elle évolue. Les performances peuvent changer pour différentes raisons. La première étape consiste donc à comprendre ce qui a changé.
-
Y a-t-il eu une mise à niveau de version majeure ou mineure ?
Une mise à niveau de version majeure inclut des modifications du code du moteur, en particulier dans l'optimiseur, qui peuvent modifier le plan d'exécution des requêtes. Lorsque vous mettez à niveau des versions de base de données, en particulier des versions majeures, il est très important d'analyser la charge de travail de la base de données et de l'ajuster en conséquence. Le réglage peut impliquer l'optimisation et la réécriture de requêtes, ou l'ajout et la mise à jour de paramètres, en fonction des résultats des tests. Comprendre la cause de l'impact vous permettra de commencer à vous concentrer sur ce domaine spécifique.
Pour plus d'informations, consultez Nouveautés dans MySQL 8.0
et Serveur, ainsi que les variables et options d'état ajoutées, déconseillées ou supprimées dans MySQL 8.0 dans la documentation MySQL, et. Comparaison entre Aurora MySQL version 2 et Aurora MySQL version 3 -
Y a-t-il eu une augmentation du nombre de données traitées (nombre de lignes) ?
-
D'autres requêtes sont-elles exécutées simultanément ?
-
Y a-t-il des modifications au schéma ou à la base de données ?
-
Y a-t-il eu des défauts de code ou des corrections ?
Table des matières
Métriques relatives à l'hôte de
Surveillez les métriques de l'hôte de l'instance, telles que l'activité du processeur, de la mémoire et du réseau, afin de déterminer s'il y a eu un changement de charge de travail. Deux concepts principaux permettent de comprendre l'évolution de la charge de travail :
-
Utilisation : utilisation d'un périphérique, tel qu'un processeur ou un disque. Il peut être basé sur le temps ou sur les capacités.
-
Basé sur le temps : durée pendant laquelle une ressource est occupée au cours d'une période d'observation donnée.
-
Basé sur la capacité : débit qu'un système ou un composant peut fournir, en pourcentage de sa capacité.
-
-
Saturation : mesure dans laquelle une ressource demande plus de travail qu'elle ne peut en traiter. Lorsque l'utilisation basée sur la capacité atteint 100 %, le travail supplémentaire ne peut pas être traité et doit être mis en file d'attente.
Utilisation de l’UC
Vous pouvez utiliser les outils suivants pour identifier l'utilisation et la saturation du processeur :
-
CloudWatch fournit la
CPUUtilizationmétrique. Si ce chiffre atteint 100 %, l'instance est saturée. Cependant, CloudWatch les mesures sont moyennées sur une minute et manquent de granularité.Pour plus d'informations sur CloudWatch les métriques, consultezMétriques de niveau instance pour Amazon Aurora.
-
La surveillance améliorée fournit des métriques renvoyées par la
topcommande du système d'exploitation. Il affiche les moyennes de charge et les états du processeur suivants, avec une granularité d'une seconde :-
Idle (%)= Temps d'inactivité -
IRQ (%)= Interruptions logicielles -
Nice (%)= C'est le moment idéal pour les processus avec une bonne priorité. -
Steal (%)= Temps passé à servir les autres locataires (lié à la virtualisation) -
System (%)= Heure du système -
User (%)= Heure de l'utilisateur -
Wait (%)= Attendre les E/S
Pour plus d'informations sur les métriques de surveillance améliorée, consultezMétriques de système d'exploitation pour Aurora.
-
Utilisation de la mémoire
Si le système est soumis à une pression de mémoire et que la consommation de ressources atteint la saturation, vous devriez observer un degré élevé de numérisation de pages, de pagination, d'échange et out-of-memory d'erreurs.
Vous pouvez utiliser les outils suivants pour identifier l'utilisation et la saturation de la mémoire :
CloudWatch fournit la FreeableMemory métrique, qui indique la quantité de mémoire pouvant être récupérée en vidant certains caches du système d'exploitation et la mémoire libre actuelle.
Pour plus d'informations sur CloudWatch les métriques, consultezMétriques de niveau instance pour Amazon Aurora.
La surveillance améliorée fournit les mesures suivantes qui peuvent vous aider à identifier les problèmes d'utilisation de la mémoire :
-
Buffers (KB)— Quantité de mémoire utilisée pour mettre en mémoire tampon les demandes d'E/S avant d'écrire sur le périphérique de stockage, en kilo-octets. -
Cached (KB)— Quantité de mémoire utilisée pour la mise en cache des E/S basées sur le système de fichiers. -
Free (KB)— La quantité de mémoire non attribuée, en kilo-octets. -
Swap— Mis en cache, gratuit et total.
Par exemple, si vous constatez que votre instance de base de données utilise de la Swap mémoire, la quantité totale de mémoire pour votre charge de travail est supérieure à celle dont dispose actuellement votre instance. Nous vous recommandons d'augmenter la taille de votre instance de base de données ou de régler votre charge de travail pour utiliser moins de mémoire.
Pour plus d'informations sur les métriques de surveillance améliorée, consultezMétriques de système d'exploitation pour Aurora.
Pour des informations plus détaillées sur l'utilisation du schéma de performance et du sys schéma afin de déterminer les connexions et les composants qui utilisent de la mémoire, consultezRésolution des problèmes d'utilisation de la mémoire pour les bases de données Aurora MySQL.
Débit réseau
CloudWatch fournit les mesures suivantes pour le débit total du réseau, toutes calculées en moyenne sur une minute :
-
NetworkReceiveThroughput— Le débit réseau reçu des clients par chaque instance du cluster de base de données Aurora. -
NetworkTransmitThroughput— Le débit réseau envoyé aux clients par chaque instance du cluster de base de données Aurora. -
NetworkThroughput— Le débit réseau reçu et transmis aux clients par chaque instance du cluster de base de données Aurora. -
StorageNetworkReceiveThroughput— Le débit réseau reçu du sous-système de stockage Aurora par chaque instance du cluster de base de données. -
StorageNetworkTransmitThroughput— Le débit réseau envoyé au sous-système de stockage Aurora par chaque instance du cluster de base de données Aurora. -
StorageNetworkThroughput— Le débit réseau reçu et envoyé au sous-système de stockage Aurora par chaque instance du cluster de base de données Aurora.
Pour plus d'informations sur CloudWatch les métriques, consultezMétriques de niveau instance pour Amazon Aurora.
La surveillance améliorée fournit les graphiques network reçus (RX) et transmis (TX), avec une granularité allant jusqu'à une seconde.
Pour plus d'informations sur les métriques de surveillance améliorée, consultezMétriques de système d'exploitation pour Aurora.
Métriques de base de données
Examinez les CloudWatch mesures suivantes pour connaître les modifications de la charge de travail :
-
BlockedTransactions— Nombre moyen de transactions bloquées par seconde dans la base de données. -
BufferCacheHitRatio— Le pourcentage de demandes traitées par le cache tampon. -
CommitThroughput— Le nombre moyen d'opérations de validation par seconde. -
DatabaseConnections— Le nombre de connexions réseau client à l'instance de base de données. -
Deadlocks— Le nombre moyen de blocages dans la base de données par seconde. -
DMLThroughput— Nombre moyen d'insertions, de mises à jour et de suppressions par seconde. -
ResultSetCacheHitRatio— Le pourcentage de demandes traitées par le cache de requêtes. -
RollbackSegmentHistoryListLength— Les journaux d'annulation qui enregistrent les transactions validées avec des enregistrements marqués de suppression. -
RowLockTime— Le temps total passé à acquérir des verrous de ligne pour les tables InnoDB. -
SelectThroughput— Le nombre moyen de requêtes de sélection par seconde.
Pour plus d'informations sur CloudWatch les métriques, consultezMétriques de niveau instance pour Amazon Aurora.
Lorsque vous examinez la charge de travail, posez-vous les questions suivantes :
-
Y a-t-il eu des changements récents dans la classe d'instance de base de données, par exemple la réduction de la taille de l'instance de 8 x large à 4 x large, ou le passage de db.r5 à db.r6 ?
-
Pouvez-vous créer un clone et reproduire le problème, ou cela se produit-il uniquement sur cette instance ?
-
Y a-t-il un épuisement des ressources du serveur, un processeur élevé ou un épuisement de la mémoire ? Si c'est le cas, cela peut signifier que du matériel supplémentaire est nécessaire.
-
Une ou plusieurs requêtes prennent-elles plus de temps ?
-
Les modifications sont-elles causées par une mise à niveau, en particulier une mise à niveau de version majeure ? Dans l'affirmative, comparez les mesures avant et après la mise à niveau.
-
Y a-t-il des changements dans le nombre d'instances de base de données de lecture ?
-
Avez-vous activé la journalisation générale, la journalisation d'audit ou la journalisation binaire ? Pour plus d’informations, consultez Journalisation pour les bases de données Aurora MySQL.
-
Avez-vous activé, désactivé ou modifié votre utilisation de la réplication des journaux binaires (binlog) ?
-
Existe-t-il des transactions de longue durée comportant un grand nombre de verrous de ligne ? Examinez la longueur de la liste d'historique (HLL) d'InnoDB pour des indications de transactions de longue durée.
Pour plus d'informations, consultez La longueur de la liste d'historique InnoDB a considérablement augmenté le billet de blog Pourquoi ma requête SELECT s'exécute-t-elle lentement sur mon cluster de bases de données Amazon Aurora MySQL ?
. -
Si un HLL important est causé par une transaction d'écriture, cela signifie que les
UNDOjournaux s'accumulent (ils ne sont pas nettoyés régulièrement). Dans le cas d'une transaction d'écriture importante, cette accumulation peut augmenter rapidement. Dans MySQL,UNDOil est stocké dans le tablespace SYSTEM. Le SYSTEMtablespace n'est pas rétrécible. LeUNDOjournal peut entraîner une augmentationSYSTEMde l'espace disque logique jusqu'à plusieurs Go, voire plusieurs To. Après la purge, libérez l'espace alloué en effectuant une sauvegarde logique (vidage) des données, puis importez le vidage dans une nouvelle instance de base de données. -
Si un HLL important est provoqué par une transaction de lecture (requête de longue durée), cela peut signifier que la requête utilise une grande quantité d'espace temporaire. Libérez l'espace temporaire en redémarrant. Examinez les métriques de la base de données Performance Insights pour détecter toute modification apportée à la
Tempsection, telle quecreated_tmp_tables. Pour plus d’informations, consultez Surveillance de la charge de la base de données avec Performance Insights sur .
-
-
Pouvez-vous diviser les transactions de longue durée en transactions plus petites qui modifient moins de lignes ?
-
Y a-t-il des changements dans les transactions bloquées ou une augmentation des blocages ? Examinez les métriques de la base de données Performance Insights pour détecter toute modification apportée aux variables d'état dans la
Lockssectioninnodb_row_lock_time, telles queinnodb_row_lock_waits, etinnodb_dead_locks. Utilisez des intervalles de 1 minute ou 5 minutes. -
Y a-t-il une augmentation des temps d'attente ? Examinez les événements d'attente et les types d'attente de Performance Insights à intervalles d'une minute ou de 5 minutes. Analysez les principaux événements d'attente et déterminez s'ils sont corrélés à des modifications de la charge de travail ou à des conflits dans la base de données.
buf_pool mutexIndique, par exemple, la contention du pool de mémoire tampon. Pour plus d’informations, consultez Réglage d'Aurora MySQL avec des événements d'attente.
Résolution des problèmes d'utilisation de la mémoire pour les bases de données Aurora MySQL
Bien que CloudWatch Enhanced Monitoring et Performance Insights fournissent une bonne vue d'ensemble de l'utilisation de la mémoire au niveau du système d'exploitation, notamment de la quantité de mémoire utilisée par le processus de base de données, ils ne vous permettent pas de déterminer les connexions ou les composants du moteur susceptibles d'être à l'origine de cette utilisation de mémoire.
Pour résoudre ce problème, vous pouvez utiliser le schéma de performance et le sys schéma. Dans Aurora MySQL version 3, l'instrumentation de la mémoire est activée par défaut lorsque le schéma de performance est activé. Dans Aurora MySQL version 2, seule l'instrumentation de mémoire pour l'utilisation de la mémoire du schéma de performance est activée par défaut. Pour plus d'informations sur les tables disponibles dans le schéma de performance pour suivre l'utilisation de la mémoire et activer l'instrumentation de la mémoire du schéma de performance, consultez les tableaux récapitulatifs de la mémoire
Bien que des informations détaillées soient disponibles dans le schéma de performance pour suivre l'utilisation actuelle de la mémoire, le schéma
Dans le sys schéma, les vues suivantes sont disponibles pour suivre l'utilisation de la mémoire par connexion, composant et requête.
| Vue | Description |
|---|---|
|
Fournit des informations sur l'utilisation de la mémoire du moteur par hôte. Cela peut être utile pour identifier les serveurs d'applications ou les hôtes clients qui consomment de la mémoire. |
|
|
Fournit des informations sur l'utilisation de la mémoire du moteur par ID de thread. L'identifiant du thread dans MySQL peut être une connexion client ou un thread d'arrière-plan. Vous pouvez mapper les identifiants de thread aux identifiants de connexion MySQL en utilisant la vue sys.processlist |
|
|
Fournit des informations sur l'utilisation de la mémoire du moteur par l'utilisateur. Cela peut être utile pour identifier les comptes utilisateurs ou les clients consommant de la mémoire. |
|
|
Fournit des informations sur l'utilisation de la mémoire du moteur par composant du moteur. Cela peut être utile pour identifier l'utilisation globale de la mémoire par les tampons ou les composants du moteur. Par exemple, vous pouvez voir l' |
|
|
Fournit une vue d'ensemble de l'utilisation totale de la mémoire suivie dans le moteur de base de données. |
Dans Aurora MySQL version 3.05 et versions ultérieures, vous pouvez également suivre l'utilisation maximale de la mémoire par résumé des instructions dans les tableaux récapitulatifs des instructions du schéma de performanceMAX_TOTAL_MEMORY colonne peut vous aider à identifier la mémoire maximale utilisée par le résumé des requêtes depuis la dernière réinitialisation des statistiques ou depuis le redémarrage de l'instance de base de données. Cela peut être utile pour identifier des requêtes spécifiques susceptibles de consommer beaucoup de mémoire.
Note
Le schéma de performance et le sys schéma indiquent l'utilisation actuelle de la mémoire sur le serveur, ainsi que le maximum de mémoire consommée par connexion et par composant du moteur. Le schéma de performance étant conservé en mémoire, les informations sont réinitialisées au redémarrage de l'instance de base de données. Pour conserver un historique dans le temps, nous vous recommandons de configurer la récupération et le stockage de ces données en dehors du schéma de performance.
Rubriques
Exemple 1 : utilisation continue élevée de la mémoire
FreeableMemoryÀ l'échelle mondiale CloudWatch, nous pouvons constater que l'utilisation de la mémoire a considérablement augmenté le 26/03/2024 à 02:59 UTC.
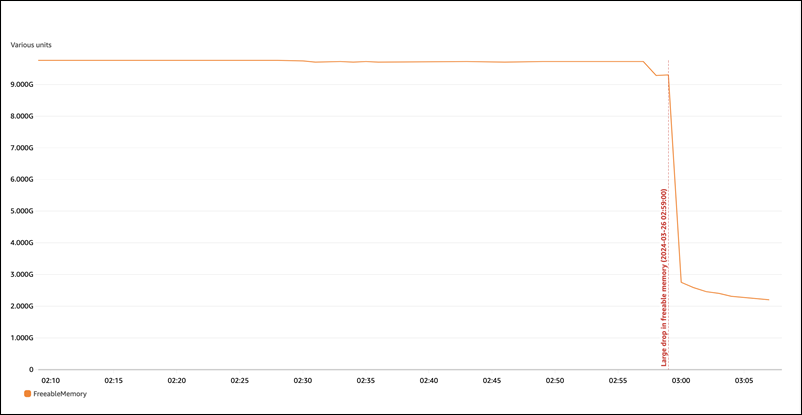
Cela ne nous donne pas une vue d'ensemble. Pour déterminer quel composant utilise le plus de mémoire, vous pouvez vous connecter à la base de données et consultersys.memory_global_by_current_bytes. Ce tableau contient une liste des événements de mémoire suivis par MySQL, ainsi que des informations sur l'allocation de mémoire par événement. Chaque événement de suivi de la mémoire commence parmemory/%, suivi d'autres informations sur le composant/la fonctionnalité du moteur auquel l'événement est associé.
Par exemple, memory/performance_schema/% concerne les événements de mémoire liés au schéma de performance, memory/innodb/% est destiné à InnoDB, etc. Pour plus d'informations sur les conventions de dénomination des événements, consultez les conventions de dénomination des instruments du schéma de performance
À partir de la requête suivante, nous pouvons trouver le coupable probable en fonction decurrent_alloc, mais nous pouvons également voir de nombreux memory/performance_schema/% événements.
mysql> SELECT * FROM sys.memory_global_by_current_bytes LIMIT 10; +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 512817 | 4.91 GiB | 10.04 KiB | 512823 | 4.91 GiB | 10.04 KiB | | memory/performance_schema/prepared_statements_instances | 252 | 488.25 MiB | 1.94 MiB | 252 | 488.25 MiB | 1.94 MiB | | memory/innodb/hash0hash | 4 | 79.07 MiB | 19.77 MiB | 4 | 79.07 MiB | 19.77 MiB | | memory/performance_schema/events_errors_summary_by_thread_by_error | 1028 | 52.27 MiB | 52.06 KiB | 1028 | 52.27 MiB | 52.06 KiB | | memory/performance_schema/events_statements_summary_by_thread_by_event_name | 4 | 47.25 MiB | 11.81 MiB | 4 | 47.25 MiB | 11.81 MiB | | memory/performance_schema/events_statements_summary_by_digest | 1 | 40.28 MiB | 40.28 MiB | 1 | 40.28 MiB | 40.28 MiB | | memory/performance_schema/memory_summary_by_thread_by_event_name | 4 | 31.64 MiB | 7.91 MiB | 4 | 31.64 MiB | 7.91 MiB | | memory/innodb/memory | 15227 | 27.44 MiB | 1.85 KiB | 20619 | 33.33 MiB | 1.66 KiB | | memory/sql/String::value | 74411 | 21.85 MiB | 307 bytes | 76867 | 25.54 MiB | 348 bytes | | memory/sql/TABLE | 8381 | 21.03 MiB | 2.57 KiB | 8381 | 21.03 MiB | 2.57 KiB | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 10 rows in set (0.02 sec)
Nous avons mentionné précédemment que le schéma de performance est stocké en mémoire, ce qui signifie qu'il est également suivi dans l'instrumentation de la performance_schema mémoire.
Note
Si vous constatez que le schéma de performance utilise beaucoup de mémoire et que vous souhaitez limiter son utilisation, vous pouvez ajuster les paramètres de base de données en fonction de vos besoins. Pour plus d'informations, consultez le modèle d'allocation de mémoire du schéma de performance
Pour des raisons de lisibilité, vous pouvez réexécuter la même requête mais exclure les événements du schéma de performance. Le résultat indique ce qui suit :
-
Le principal consommateur de mémoire est
memory/sql/Prepared_statement::main_mem_root. -
La
current_alloccolonne nous indique que MySQL dispose actuellement de 4,91 GiB alloués à cet événement. -
Cela nous
high_alloc columnindique que 4,91 GiB est le point culminant depuis la dernière réinitialisationcurrent_allocdes statistiques ou depuis le redémarrage du serveur. Cela signifie que c'memory/sql/Prepared_statement::main_mem_rootest à sa valeur la plus élevée.
mysql> SELECT * FROM sys.memory_global_by_current_bytes WHERE event_name NOT LIKE 'memory/performance_schema/%' LIMIT 10; +-----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +-----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 512817 | 4.91 GiB | 10.04 KiB | 512823 | 4.91 GiB | 10.04 KiB | | memory/innodb/hash0hash | 4 | 79.07 MiB | 19.77 MiB | 4 | 79.07 MiB | 19.77 MiB | | memory/innodb/memory | 17096 | 31.68 MiB | 1.90 KiB | 22498 | 37.60 MiB | 1.71 KiB | | memory/sql/String::value | 122277 | 27.94 MiB | 239 bytes | 124699 | 29.47 MiB | 247 bytes | | memory/sql/TABLE | 9927 | 24.67 MiB | 2.55 KiB | 9929 | 24.68 MiB | 2.55 KiB | | memory/innodb/lock0lock | 8888 | 19.71 MiB | 2.27 KiB | 8888 | 19.71 MiB | 2.27 KiB | | memory/sql/Prepared_statement::infrastructure | 257623 | 16.24 MiB | 66 bytes | 257631 | 16.24 MiB | 66 bytes | | memory/mysys/KEY_CACHE | 3 | 16.00 MiB | 5.33 MiB | 3 | 16.00 MiB | 5.33 MiB | | memory/innodb/sync0arr | 3 | 7.03 MiB | 2.34 MiB | 3 | 7.03 MiB | 2.34 MiB | | memory/sql/THD::main_mem_root | 815 | 6.56 MiB | 8.24 KiB | 849 | 7.19 MiB | 8.67 KiB | +-----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 10 rows in set (0.06 sec)
Le nom de l'événement indique que cette mémoire est utilisée pour des instructions préparées. Si vous voulez voir quelles connexions utilisent cette mémoire, vous pouvez vérifier memory_by_thread_by_current_bytes
Dans l'exemple suivant, environ 7 MiB sont alloués à chaque connexion, avec un maximum d'environ 6,29 MiB (). current_max_alloc Cela est logique, car l'exemple utilise sysbench 80 tables et 800 connexions avec des instructions préparées. Si vous souhaitez réduire l'utilisation de la mémoire dans ce scénario, vous pouvez optimiser l'utilisation des instructions préparées par votre application afin de réduire la consommation de mémoire.
mysql> SELECT * FROM sys.memory_by_thread_by_current_bytes; +-----------+-------------------------------------------+--------------------+-------------------+-------------------+-------------------+-----------------+ | thread_id | user | current_count_used | current_allocated | current_avg_alloc | current_max_alloc | total_allocated | +-----------+-------------------------------------------+--------------------+-------------------+-------------------+-------------------+-----------------+ | 46 | rdsadmin@localhost | 405 | 8.47 MiB | 21.42 KiB | 8.00 MiB | 155.86 MiB | | 61 | reinvent@10.0.4.4 | 1749 | 6.72 MiB | 3.93 KiB | 6.29 MiB | 14.24 MiB | | 101 | reinvent@10.0.4.4 | 1845 | 6.71 MiB | 3.72 KiB | 6.29 MiB | 14.50 MiB | | 55 | reinvent@10.0.4.4 | 1674 | 6.68 MiB | 4.09 KiB | 6.29 MiB | 14.13 MiB | | 57 | reinvent@10.0.4.4 | 1416 | 6.66 MiB | 4.82 KiB | 6.29 MiB | 13.52 MiB | | 112 | reinvent@10.0.4.4 | 1759 | 6.66 MiB | 3.88 KiB | 6.29 MiB | 14.17 MiB | | 66 | reinvent@10.0.4.4 | 1428 | 6.64 MiB | 4.76 KiB | 6.29 MiB | 13.47 MiB | | 75 | reinvent@10.0.4.4 | 1389 | 6.62 MiB | 4.88 KiB | 6.29 MiB | 13.40 MiB | | 116 | reinvent@10.0.4.4 | 1333 | 6.61 MiB | 5.08 KiB | 6.29 MiB | 13.21 MiB | | 90 | reinvent@10.0.4.4 | 1448 | 6.59 MiB | 4.66 KiB | 6.29 MiB | 13.58 MiB | | 98 | reinvent@10.0.4.4 | 1440 | 6.57 MiB | 4.67 KiB | 6.29 MiB | 13.52 MiB | | 94 | reinvent@10.0.4.4 | 1433 | 6.57 MiB | 4.69 KiB | 6.29 MiB | 13.49 MiB | | 62 | reinvent@10.0.4.4 | 1323 | 6.55 MiB | 5.07 KiB | 6.29 MiB | 13.48 MiB | | 87 | reinvent@10.0.4.4 | 1323 | 6.55 MiB | 5.07 KiB | 6.29 MiB | 13.25 MiB | | 99 | reinvent@10.0.4.4 | 1346 | 6.54 MiB | 4.98 KiB | 6.29 MiB | 13.24 MiB | | 105 | reinvent@10.0.4.4 | 1347 | 6.54 MiB | 4.97 KiB | 6.29 MiB | 13.34 MiB | | 73 | reinvent@10.0.4.4 | 1335 | 6.54 MiB | 5.02 KiB | 6.29 MiB | 13.23 MiB | | 54 | reinvent@10.0.4.4 | 1510 | 6.53 MiB | 4.43 KiB | 6.29 MiB | 13.49 MiB | . . . . . . | 812 | reinvent@10.0.4.4 | 1259 | 6.38 MiB | 5.19 KiB | 6.29 MiB | 13.05 MiB | | 214 | reinvent@10.0.4.4 | 1279 | 6.38 MiB | 5.10 KiB | 6.29 MiB | 12.90 MiB | | 325 | reinvent@10.0.4.4 | 1254 | 6.38 MiB | 5.21 KiB | 6.29 MiB | 12.99 MiB | | 705 | reinvent@10.0.4.4 | 1273 | 6.37 MiB | 5.13 KiB | 6.29 MiB | 13.03 MiB | | 530 | reinvent@10.0.4.4 | 1268 | 6.37 MiB | 5.15 KiB | 6.29 MiB | 12.92 MiB | | 307 | reinvent@10.0.4.4 | 1263 | 6.37 MiB | 5.17 KiB | 6.29 MiB | 12.87 MiB | | 738 | reinvent@10.0.4.4 | 1260 | 6.37 MiB | 5.18 KiB | 6.29 MiB | 13.00 MiB | | 819 | reinvent@10.0.4.4 | 1252 | 6.37 MiB | 5.21 KiB | 6.29 MiB | 13.01 MiB | | 31 | innodb/srv_purge_thread | 17810 | 3.14 MiB | 184 bytes | 2.40 MiB | 205.69 MiB | | 38 | rdsadmin@localhost | 599 | 1.76 MiB | 3.01 KiB | 1.00 MiB | 25.58 MiB | | 1 | sql/main | 3756 | 1.32 MiB | 367 bytes | 355.78 KiB | 6.19 MiB | | 854 | rdsadmin@localhost | 46 | 1.08 MiB | 23.98 KiB | 1.00 MiB | 5.10 MiB | | 30 | innodb/clone_gtid_thread | 1596 | 573.14 KiB | 367 bytes | 254.91 KiB | 970.69 KiB | | 40 | rdsadmin@localhost | 235 | 245.19 KiB | 1.04 KiB | 128.88 KiB | 808.64 KiB | | 853 | rdsadmin@localhost | 96 | 94.63 KiB | 1009 bytes | 29.73 KiB | 422.45 KiB | | 36 | rdsadmin@localhost | 33 | 36.29 KiB | 1.10 KiB | 16.08 KiB | 74.15 MiB | | 33 | sql/event_scheduler | 3 | 16.27 KiB | 5.42 KiB | 16.04 KiB | 16.27 KiB | | 35 | sql/compress_gtid_table | 8 | 14.20 KiB | 1.77 KiB | 8.05 KiB | 18.62 KiB | | 25 | innodb/fts_optimize_thread | 12 | 1.86 KiB | 158 bytes | 648 bytes | 1.98 KiB | | 23 | innodb/srv_master_thread | 11 | 1.23 KiB | 114 bytes | 361 bytes | 24.40 KiB | | 24 | innodb/dict_stats_thread | 11 | 1.23 KiB | 114 bytes | 361 bytes | 1.35 KiB | | 5 | innodb/io_read_thread | 1 | 144 bytes | 144 bytes | 144 bytes | 144 bytes | | 6 | innodb/io_read_thread | 1 | 144 bytes | 144 bytes | 144 bytes | 144 bytes | | 2 | sql/aws_oscar_log_level_monitor | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 4 | innodb/io_ibuf_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 7 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 8 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 9 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 10 | innodb/io_write_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 11 | innodb/srv_lra_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 12 | innodb/srv_akp_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 18 | innodb/srv_lock_timeout_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 248 bytes | | 19 | innodb/srv_error_monitor_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 20 | innodb/srv_monitor_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 21 | innodb/buf_resize_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 22 | innodb/btr_search_sys_toggle_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 32 | innodb/dict_persist_metadata_table_thread | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | | 34 | sql/signal_handler | 0 | 0 bytes | 0 bytes | 0 bytes | 0 bytes | +-----------+-------------------------------------------+--------------------+-------------------+-------------------+-------------------+-----------------+ 831 rows in set (2.48 sec)
Comme indiqué précédemment, la valeur de thread ID (thd_id) ici peut faire référence aux threads d'arrière-plan du serveur ou aux connexions à la base de données. Si vous souhaitez associer les valeurs des identifiants de thread aux identifiants de connexion à la base de données, vous pouvez utiliser la performance_schema.threads table ou la sys.processlist vue, où se conn_id trouve l'identifiant de connexion.
mysql> SELECT thd_id,conn_id,user,db,command,state,time,last_wait FROM sys.processlist WHERE user='reinvent@10.0.4.4'; +--------+---------+-------------------+----------+---------+----------------+------+-------------------------------------------------+ | thd_id | conn_id | user | db | command | state | time | last_wait | +--------+---------+-------------------+----------+---------+----------------+------+-------------------------------------------------+ | 590 | 562 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 578 | 550 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 579 | 551 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 580 | 552 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 581 | 553 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 582 | 554 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 583 | 555 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 584 | 556 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 585 | 557 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 586 | 558 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 587 | 559 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | . . . . . . | 323 | 295 | reinvent@10.0.4.4 | sysbench | Sleep | NULL | 0 | idle | | 324 | 296 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 325 | 297 | reinvent@10.0.4.4 | sysbench | Execute | closing tables | 0 | wait/io/redo_log_flush | | 326 | 298 | reinvent@10.0.4.4 | sysbench | Execute | updating | 0 | wait/io/table/sql/handler | | 438 | 410 | reinvent@10.0.4.4 | sysbench | Execute | System lock | 0 | wait/lock/table/sql/handler | | 280 | 252 | reinvent@10.0.4.4 | sysbench | Sleep | starting | 0 | wait/io/socket/sql/client_connection | | 98 | 70 | reinvent@10.0.4.4 | sysbench | Query | freeing items | 0 | NULL | +--------+---------+-------------------+----------+---------+----------------+------+-------------------------------------------------+ 804 rows in set (5.51 sec)
Nous arrêtons maintenant la sysbench charge de travail, qui ferme les connexions et libère de la mémoire. En vérifiant à nouveau les événements, nous pouvons confirmer que la mémoire est libérée, mais nous indique high_alloc tout de même quel est le point culminant. La high_alloc colonne peut être très utile pour identifier de courts pics d'utilisation de la mémoire, d'où il se peut que vous ne puissiez pas identifier immédiatement l'utilisationcurrent_alloc, car elle indique uniquement la mémoire actuellement allouée.
mysql> SELECT * FROM sys.memory_global_by_current_bytes WHERE event_name='memory/sql/Prepared_statement::main_mem_root' LIMIT 10; +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 17 | 253.80 KiB | 14.93 KiB | 512823 | 4.91 GiB | 10.04 KiB | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 1 row in set (0.00 sec)
Si vous souhaitez effectuer une réinitialisationhigh_alloc, vous pouvez tronquer les tableaux récapitulatifs de la performance_schema mémoire, mais cela réinitialise tous les instruments de mémoire. Pour plus d'informations, consultez la section Caractéristiques générales du tableau Performance Schema
Dans l'exemple suivant, nous pouvons voir que cela high_alloc est réinitialisé après la troncature.
mysql> TRUNCATE `performance_schema`.`memory_summary_global_by_event_name`; Query OK, 0 rows affected (0.00 sec) mysql> SELECT * FROM sys.memory_global_by_current_bytes WHERE event_name='memory/sql/Prepared_statement::main_mem_root' LIMIT 10; +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/sql/Prepared_statement::main_mem_root | 17 | 253.80 KiB | 14.93 KiB | 17 | 253.80 KiB | 14.93 KiB | +----------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 1 row in set (0.00 sec)
Exemple 2 : pics de mémoire transitoires
Les courts pics d'utilisation de la mémoire sur un serveur de base de données constituent un autre phénomène courant. Il peut s'agir de baisses périodiques de mémoire libre difficiles à résoudresys.memory_global_by_current_bytes, current_alloc car la mémoire a déjà été libérée.
Note
Si les statistiques du schéma de performance ont été réinitialisées ou si l'instance de base de données a été redémarrée, ces informations ne seront pas disponibles dans sys ou p. erformance_schema Pour conserver ces informations, nous vous recommandons de configurer la collecte de métriques externes.
Le graphique suivant de la os.memory.free métrique dans Enhanced Monitoring montre de brèves pointes de 7 secondes d'utilisation de la mémoire. La surveillance améliorée vous permet de surveiller à des intervalles aussi courts qu'une seconde, ce qui est parfait pour détecter de tels pics transitoires.
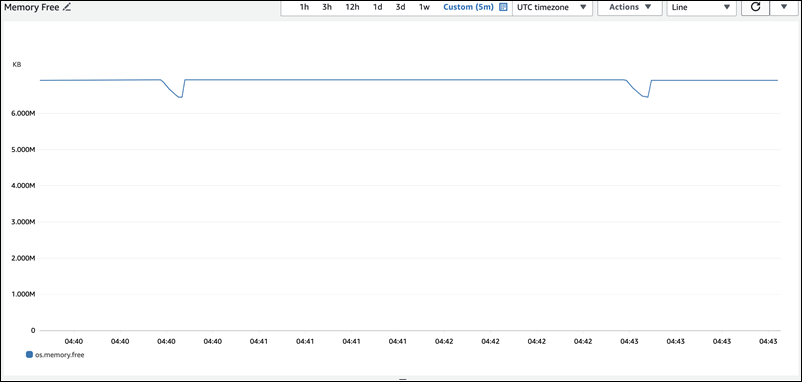
Pour aider à diagnostiquer la cause de l'utilisation de la mémoire, nous pouvons utiliser à la fois les vues récapitulatives de high_alloc la sys mémoire et les tableaux récapitulatifs des déclarations du schéma de performance
Comme on pouvait s'y attendre, étant donné que l'utilisation de la mémoire n'est pas élevée actuellement, nous ne voyons aucun délinquant majeur dans la vue du sys schéma ci-dessouscurrent_alloc.
mysql> SELECT * FROM sys.memory_global_by_current_bytes LIMIT 10; +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | event_name | current_count | current_alloc | current_avg_alloc | high_count | high_alloc | high_avg_alloc | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ | memory/innodb/hash0hash | 4 | 79.07 MiB | 19.77 MiB | 4 | 79.07 MiB | 19.77 MiB | | memory/innodb/os0event | 439372 | 60.34 MiB | 144 bytes | 439372 | 60.34 MiB | 144 bytes | | memory/performance_schema/events_statements_summary_by_digest | 1 | 40.28 MiB | 40.28 MiB | 1 | 40.28 MiB | 40.28 MiB | | memory/mysys/KEY_CACHE | 3 | 16.00 MiB | 5.33 MiB | 3 | 16.00 MiB | 5.33 MiB | | memory/performance_schema/events_statements_history_long | 1 | 14.34 MiB | 14.34 MiB | 1 | 14.34 MiB | 14.34 MiB | | memory/performance_schema/events_errors_summary_by_thread_by_error | 257 | 13.07 MiB | 52.06 KiB | 257 | 13.07 MiB | 52.06 KiB | | memory/performance_schema/events_statements_summary_by_thread_by_event_name | 1 | 11.81 MiB | 11.81 MiB | 1 | 11.81 MiB | 11.81 MiB | | memory/performance_schema/events_statements_summary_by_digest.digest_text | 1 | 9.77 MiB | 9.77 MiB | 1 | 9.77 MiB | 9.77 MiB | | memory/performance_schema/events_statements_history_long.digest_text | 1 | 9.77 MiB | 9.77 MiB | 1 | 9.77 MiB | 9.77 MiB | | memory/performance_schema/events_statements_history_long.sql_text | 1 | 9.77 MiB | 9.77 MiB | 1 | 9.77 MiB | 9.77 MiB | +-----------------------------------------------------------------------------+---------------+---------------+-------------------+------------+------------+----------------+ 10 rows in set (0.01 sec)
En élargissant la vue pour trier parhigh_alloc, nous pouvons maintenant constater que le memory/temptable/physical_ram composant est un très bon candidat ici. À son maximum, il consommait 515,00 MiB.
Comme son nom l'indique, il memory/temptable/physical_ram contrôle l'utilisation de la mémoire pour le moteur de TEMP stockage de MySQL, introduit dans MySQL 8.0. Pour plus d'informations sur la façon dont MySQL utilise les tables temporaires, consultez la section Utilisation interne des tables temporaires dans MySQL
Note
Nous utilisons la sys.x$memory_global_by_current_bytes vue dans cet exemple.
mysql> SELECT event_name, format_bytes(current_alloc) AS "currently allocated", sys.format_bytes(high_alloc) AS "high-water mark" FROM sys.x$memory_global_by_current_bytes ORDER BY high_alloc DESC LIMIT 10; +-----------------------------------------------------------------------------+---------------------+-----------------+ | event_name | currently allocated | high-water mark | +-----------------------------------------------------------------------------+---------------------+-----------------+ | memory/temptable/physical_ram | 4.00 MiB | 515.00 MiB | | memory/innodb/hash0hash | 79.07 MiB | 79.07 MiB | | memory/innodb/os0event | 63.95 MiB | 63.95 MiB | | memory/performance_schema/events_statements_summary_by_digest | 40.28 MiB | 40.28 MiB | | memory/mysys/KEY_CACHE | 16.00 MiB | 16.00 MiB | | memory/performance_schema/events_statements_history_long | 14.34 MiB | 14.34 MiB | | memory/performance_schema/events_errors_summary_by_thread_by_error | 13.07 MiB | 13.07 MiB | | memory/performance_schema/events_statements_summary_by_thread_by_event_name | 11.81 MiB | 11.81 MiB | | memory/performance_schema/events_statements_summary_by_digest.digest_text | 9.77 MiB | 9.77 MiB | | memory/performance_schema/events_statements_history_long.sql_text | 9.77 MiB | 9.77 MiB | +-----------------------------------------------------------------------------+---------------------+-----------------+ 10 rows in set (0.00 sec)
DansExemple 1 : utilisation continue élevée de la mémoire, nous avons vérifié l'utilisation actuelle de la mémoire pour chaque connexion afin de déterminer quelle connexion est responsable de l'utilisation de la mémoire en question. Dans cet exemple, la mémoire est déjà libérée, il n'est donc pas utile de vérifier l'utilisation de la mémoire pour les connexions en cours.
Pour approfondir et trouver les déclarations, les utilisateurs et les hôtes incriminés, nous utilisons le schéma de performance. Le schéma de performance contient plusieurs tableaux récapitulatifs des instructions divisés en différentes dimensions, telles que le nom de l'événement, le résumé de l'instruction, l'hôte, le thread et l'utilisateur. Chaque vue vous permettra de mieux comprendre où certaines instructions sont exécutées et ce qu'elles font. Cette section se concentre surMAX_TOTAL_MEMORY, mais vous pouvez trouver plus d'informations sur toutes les colonnes disponibles dans la documentation des tableaux récapitulatifs des déclarations du schéma de performance
mysql> SHOW TABLES IN performance_schema LIKE 'events_statements_summary_%'; +------------------------------------------------------------+ | Tables_in_performance_schema (events_statements_summary_%) | +------------------------------------------------------------+ | events_statements_summary_by_account_by_event_name | | events_statements_summary_by_digest | | events_statements_summary_by_host_by_event_name | | events_statements_summary_by_program | | events_statements_summary_by_thread_by_event_name | | events_statements_summary_by_user_by_event_name | | events_statements_summary_global_by_event_name | +------------------------------------------------------------+ 7 rows in set (0.00 sec)
Nous vérifierons d'abord events_statements_summary_by_digest pour voirMAX_TOTAL_MEMORY.
À partir de là, nous pouvons voir ce qui suit :
-
La requête avec digest
20676ce4a690592ff05debcffcbc26faeb76f22005e7628364d7a498769d0c4asemble être un bon candidat pour cette utilisation de la mémoire.MAX_TOTAL_MEMORYIl s'agit du 537450710, ce qui correspond au point culminant que nous avons observé pour l'événement.memory/temptable/physical_ramsys.x$memory_global_by_current_bytes -
Il a été diffusé quatre fois (
COUNT_STAR), d'abord le 26/03/2024 04:08:34.943 256, et la dernière le 26/03/2024 04:43:06.998 310.
mysql> SELECT SCHEMA_NAME,DIGEST,COUNT_STAR,MAX_TOTAL_MEMORY,FIRST_SEEN,LAST_SEEN FROM performance_schema.events_statements_summary_by_digest ORDER BY MAX_TOTAL_MEMORY DESC LIMIT 5; +-------------+------------------------------------------------------------------+------------+------------------+----------------------------+----------------------------+ | SCHEMA_NAME | DIGEST | COUNT_STAR | MAX_TOTAL_MEMORY | FIRST_SEEN | LAST_SEEN | +-------------+------------------------------------------------------------------+------------+------------------+----------------------------+----------------------------+ | sysbench | 20676ce4a690592ff05debcffcbc26faeb76f22005e7628364d7a498769d0c4a | 4 | 537450710 | 2024-03-26 04:08:34.943256 | 2024-03-26 04:43:06.998310 | | NULL | f158282ea0313fefd0a4778f6e9b92fc7d1e839af59ebd8c5eea35e12732c45d | 4 | 3636413 | 2024-03-26 04:29:32.712348 | 2024-03-26 04:36:26.269329 | | NULL | 0046bc5f642c586b8a9afd6ce1ab70612dc5b1fd2408fa8677f370c1b0ca3213 | 2 | 3459965 | 2024-03-26 04:31:37.674008 | 2024-03-26 04:32:09.410718 | | NULL | 8924f01bba3c55324701716c7b50071a60b9ceaf17108c71fd064c20c4ab14db | 1 | 3290981 | 2024-03-26 04:31:49.751506 | 2024-03-26 04:31:49.751506 | | NULL | 90142bbcb50a744fcec03a1aa336b2169761597ea06d85c7f6ab03b5a4e1d841 | 1 | 3131729 | 2024-03-26 04:15:09.719557 | 2024-03-26 04:15:09.719557 | +-------------+------------------------------------------------------------------+------------+------------------+----------------------------+----------------------------+ 5 rows in set (0.00 sec)
Maintenant que nous connaissons le résumé incriminé, nous pouvons obtenir plus de détails tels que le texte de la requête, l'utilisateur qui l'a exécutée et l'endroit où elle a été exécutée. Sur la base du texte du résumé renvoyé, nous pouvons constater qu'il s'agit d'une expression de table courante (CTE) qui crée quatre tables temporaires et effectue quatre analyses de tables, ce qui est très inefficace.
mysql> SELECT SCHEMA_NAME,DIGEST_TEXT,QUERY_SAMPLE_TEXT,MAX_TOTAL_MEMORY,SUM_ROWS_SENT,SUM_ROWS_EXAMINED,SUM_CREATED_TMP_TABLES,SUM_NO_INDEX_USED FROM performance_schema.events_statements_summary_by_digest WHERE DIGEST='20676ce4a690592ff05debcffcbc26faeb76f22005e7628364d7a498769d0c4a'\G; *************************** 1. row *************************** SCHEMA_NAME: sysbench DIGEST_TEXT: WITH RECURSIVE `cte` ( `n` ) AS ( SELECT ? FROM `sbtest1` UNION ALL SELECT `id` + ? FROM `sbtest1` ) SELECT * FROM `cte` QUERY_SAMPLE_TEXT: WITH RECURSIVE cte (n) AS ( SELECT 1 from sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte MAX_TOTAL_MEMORY: 537450710 SUM_ROWS_SENT: 80000000 SUM_ROWS_EXAMINED: 80000000 SUM_CREATED_TMP_TABLES: 4 SUM_NO_INDEX_USED: 4 1 row in set (0.01 sec)
Pour plus d'informations sur le events_statements_summary_by_digest tableau et les autres tableaux récapitulatifs des instructions du schéma de performance, consultez les tableaux récapitulatifs des
Vous pouvez également exécuter une instruction EXPLAIN
Note
EXPLAIN ANALYZEpeut fournir plus d'informations queEXPLAIN, mais il exécute également la requête, donc soyez prudent.
-- EXPLAIN mysql> EXPLAIN WITH RECURSIVE cte (n) AS (SELECT 1 FROM sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte; +----+-------------+------------+------------+-------+---------------+------+---------+------+----------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+------------+------------+-------+---------------+------+---------+------+----------+----------+-------------+ | 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 19221520 | 100.00 | NULL | | 2 | DERIVED | sbtest1 | NULL | index | NULL | k_1 | 4 | NULL | 9610760 | 100.00 | Using index | | 3 | UNION | sbtest1 | NULL | index | NULL | k_1 | 4 | NULL | 9610760 | 100.00 | Using index | +----+-------------+------------+------------+-------+---------------+------+---------+------+----------+----------+-------------+ 3 rows in set, 1 warning (0.00 sec) -- EXPLAIN format=tree mysql> EXPLAIN format=tree WITH RECURSIVE cte (n) AS (SELECT 1 FROM sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte\G; *************************** 1. row *************************** EXPLAIN: -> Table scan on cte (cost=4.11e+6..4.35e+6 rows=19.2e+6) -> Materialize union CTE cte (cost=4.11e+6..4.11e+6 rows=19.2e+6) -> Index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) -> Index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) 1 row in set (0.00 sec) -- EXPLAIN ANALYZE mysql> EXPLAIN ANALYZE WITH RECURSIVE cte (n) AS (SELECT 1 from sbtest1 UNION ALL SELECT id + 1 FROM sbtest1) SELECT * FROM cte\G; *************************** 1. row *************************** EXPLAIN: -> Table scan on cte (cost=4.11e+6..4.35e+6 rows=19.2e+6) (actual time=6666..9201 rows=20e+6 loops=1) -> Materialize union CTE cte (cost=4.11e+6..4.11e+6 rows=19.2e+6) (actual time=6666..6666 rows=20e+6 loops=1) -> Covering index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) (actual time=0.0365..2006 rows=10e+6 loops=1) -> Covering index scan on sbtest1 using k_1 (cost=1.09e+6 rows=9.61e+6) (actual time=0.0311..2494 rows=10e+6 loops=1) 1 row in set (10.53 sec)
Mais qui l'a dirigée ? Nous pouvons le voir dans le schéma de performance que l'destructive_operatorutilisateur avait MAX_TOTAL_MEMORY de 537450710, qui correspond à nouveau aux résultats précédents.
Note
Le schéma de performance est stocké en mémoire et ne doit donc pas être considéré comme la seule source d'audit. Si vous devez conserver un historique des instructions exécutées et à partir de quels utilisateurs, nous vous recommandons d'activer la journalisation des audits. Si vous devez également conserver des informations sur l'utilisation de la mémoire, nous vous recommandons de configurer la surveillance pour exporter et stocker ces valeurs.
mysql> SELECT USER,EVENT_NAME,COUNT_STAR,MAX_TOTAL_MEMORY FROM performance_schema.events_statements_summary_by_user_by_event_name ORDER BY MAX_CONTROLLED_MEMORY DESC LIMIT 5; +----------------------+---------------------------+------------+------------------+ | USER | EVENT_NAME | COUNT_STAR | MAX_TOTAL_MEMORY | +----------------------+---------------------------+------------+------------------+ | destructive_operator | statement/sql/select | 4 | 537450710 | | rdsadmin | statement/sql/select | 4172 | 3290981 | | rdsadmin | statement/sql/show_tables | 2 | 3615821 | | rdsadmin | statement/sql/show_fields | 2 | 3459965 | | rdsadmin | statement/sql/show_status | 75 | 1914976 | +----------------------+---------------------------+------------+------------------+ 5 rows in set (0.00 sec) mysql> SELECT HOST,EVENT_NAME,COUNT_STAR,MAX_TOTAL_MEMORY FROM performance_schema.events_statements_summary_by_host_by_event_name WHERE HOST != 'localhost' AND COUNT_STAR>0 ORDER BY MAX_CONTROLLED_MEMORY DESC LIMIT 5; +------------+----------------------+------------+------------------+ | HOST | EVENT_NAME | COUNT_STAR | MAX_TOTAL_MEMORY | +------------+----------------------+------------+------------------+ | 10.0.8.231 | statement/sql/select | 4 | 537450710 | +------------+----------------------+------------+------------------+ 1 row in set (0.00 sec)
Résolution des out-of-memory problèmes liés aux bases de données Aurora MySQL
Le paramètre de niveau instance Aurora MySQL aurora_oom_response peut autoriser l'instance de base de données à surveiller la mémoire système et à estimer la mémoire utilisée par différentes déclarations et connexions. Si le système manque de mémoire, il peut exécuter une liste d'actions pour tenter de libérer cette mémoire. Il le fait dans le but d'éviter le redémarrage de la base de données en raison de problèmes out-of-memory (OOM). Le paramètre instance-level prend une chaîne d'actions séparées par des virgules qu'une instance de base de données exécute lorsque sa mémoire est insuffisante. Le aurora_oom_response paramètre est pris en charge pour les versions 2 et 3 d'Aurora MySQL.
Les valeurs suivantes, ainsi que leurs combinaisons, peuvent être utilisées pour le aurora_oom_response paramètre. Une chaîne vide signifie qu'aucune action n'est entreprise et désactive effectivement la fonctionnalité, laissant la base de données sujette aux redémarrages OOM.
-
decline— Refuse les nouvelles requêtes lorsque la mémoire de l'instance de base de données est insuffisante. kill_connect— Ferme les connexions de base de données qui consomment une grande quantité de mémoire et met fin aux transactions en cours et aux instructions DDL (Data Definition Language). Cette réponse n'est pas prise en charge pour la version 2 d'Aurora MySQL.Pour plus d'informations, consultez l'instruction KILL
dans la documentation MySQL. -
kill_query— Termine les requêtes par ordre décroissant de consommation de mémoire jusqu'à ce que la mémoire de l'instance dépasse le seuil inférieur. Les instructions DDL ne sont pas terminées.Pour plus d'informations, consultez l'instruction KILL
dans la documentation MySQL. -
print— Imprime uniquement les requêtes consommant une grande quantité de mémoire. -
tune: affine les caches de table interne pour restituer de la mémoire au système. Aurora MySQL réduit la mémoire utilisée pour les caches, notammenttable_definition_cachedanstable_open_cachedes conditions de faible mémoire. Finalement, Aurora MySQL rétablit l'utilisation de la mémoire à des conditions normales lorsque le système n'est plus à court de mémoire.Pour plus d'informations, consultez table_open_cache et table_definition_cache
dans la documentation MySQL . tune_buffer_pool— Diminue la taille du pool de mémoire tampon afin de libérer de la mémoire et de la rendre disponible pour que le serveur de base de données puisse traiter les connexions. Cette réponse est prise en charge pour Aurora MySQL version 3.06 et supérieure.Vous devez effectuer une association
tune_buffer_poolavec l'unekill_queryou l'autre valeur duaurora_oom_responseparamètre oukill_connectdans celle-ci. Dans le cas contraire, le redimensionnement du pool de mémoire tampon ne se produira pas, même si vous inclueztune_buffer_poolla valeur du paramètre.
Dans les versions d'Aurora MySQL inférieures à 3.06, pour les classes d'instance de base de données dont la mémoire est inférieure ou égale à 4 GiB, lorsque l'instance est soumise à une pression de mémoire, les actions par défaut print incluenttune,decline, et. kill_query Pour les classes d'instance de base de données dont la mémoire est supérieure à 4 GiB, la valeur du paramètre est vide par défaut (désactivée).
Dans Aurora MySQL version 3.06 et versions supérieures, pour les classes d'instance de base de données dont la mémoire est inférieure ou égale à 4 GiB, Aurora MySQL ferme également les connexions les plus gourmandes en mémoire (). kill_connect Pour les classes d'instance de base de données dont la mémoire est supérieure à 4 GiB, la valeur du paramètre par défaut est. print
Si vous rencontrez fréquemment des out-of-memory problèmes, l'utilisation de la mémoire peut être surveillée à l'aide de tableaux récapitulatifs de la mémoireperformance_schema est activée.
