Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Performances et mise à l'échelle pour Aurora Serverless v2
Les procédures et exemples suivants montrent comment définir la plage de capacité pour les clusters Aurora Serverless v2 et leurs instances de base de données associées. Vous pouvez également utiliser les procédures suivantes pour surveiller le niveau d'occupation de vos instances de base de données. Vous pouvez ensuite utiliser vos résultats pour déterminer si vous devez augmenter ou réduire la plage de capacité.
Avant d'utiliser ces procédures, assurez-vous de bien savoir comment fonctionne la mise à l’échelle d'Aurora Serverless v2. Le mécanisme de mise à l'échelle est différent de celui d'Aurora Serverless v1. Pour en savoir plus, consultez Mise à l'échelle d'Aurora Serverless v2.
Table des matières
Choix de la plage de capacité Aurora Serverless v2 pour un cluster Aurora
Choix de la valeur minimale de capacité Aurora Serverless v2 pour un cluster
Choix de la valeur maximale de capacité Aurora Serverless v2 pour un cluster
Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora MySQL
Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora PostgreSQL
Utilisation des groupes de paramètres pour Aurora Serverless v2
Statistiques Amazon CloudWatch importantes pour Aurora Serverless v2
Surveillance des performances d'Aurora Serverless v2 avec Performance Insights
Choix de la plage de capacité Aurora Serverless v2 pour un cluster Aurora
Avec les instances de base de données Aurora Serverless v2, vous définissez la plage de capacité qui s'applique à toutes les instances de base de données de votre cluster de bases de données en même temps que vous ajoutez la première instance de base de données Aurora Serverless v2 au cluster de bases de données Pour savoir comment procéder, consultez Définition de la plage de capacité Aurora Serverless v2 d'un cluster.
Vous pouvez également modifier la plage de capacité d'un cluster existant. Les sections suivantes expliquent plus en détail comment choisir les valeurs minimales et maximales appropriées et ce qui se passe lorsque vous modifiez la plage de capacité. Par exemple, la modification de la plage de capacité peut modifier les valeurs par défaut de certains paramètres de configuration. L'application de toutes les modifications des paramètres peut exiger de redémarrer chaque instance de base de données Aurora Serverless v2.
Rubriques
Choix de la valeur minimale de capacité Aurora Serverless v2 pour un cluster
Choix de la valeur maximale de capacité Aurora Serverless v2 pour un cluster
Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora MySQL
Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora PostgreSQL
Choix de la valeur minimale de capacité Aurora Serverless v2 pour un cluster
Il peut s'avérer tentant de toujours choisir 0,5 comme valeur minimale de capacité Aurora Serverless v2. Cette valeur permet à l'instance de base de données de réduire sa capacité au minimum lorsqu'elle est complètement inactive, tout en restant active. Vous pouvez également activer le comportement de pause automatique en spécifiant une capacité minimale de 0 ACUs, comme expliqué dansMise à l'échelle jusqu'à zéro ACUs avec pause et reprise automatiques pour Aurora Serverless v2. Toutefois, selon la façon dont vous utilisez ce cluster et les autres paramètres que vous configurez, une capacité minimale différente peut être la plus efficace. Tenez compte des facteurs suivants lors du choix de la valeur minimale de capacité :
-
Le taux de mise à l'échelle d'une instance de base de données Aurora Serverless v2 dépend de sa capacité actuelle. Plus sa capacité actuelle est élevée, plus son augmentation d'échelle est rapide. Si vous avez besoin d'augmenter rapidement l'échelle de l'instance de base de données jusqu'à une capacité très élevée, envisagez de définir la capacité minimale sur une valeur où le taux de mise à l’échelle satisfait à vos exigences.
-
Si vous modifiez généralement la classe d'instance de base de données de vos instances de base de données en prévision d'une charge de travail particulièrement élevée ou faible, vous pouvez utiliser cette expérience pour effectuer une estimation approximative de la plage de capacité Aurora Serverless v2 équivalente. Pour déterminer la taille de mémoire à utiliser en période de faible trafic, consultez Spécifications matérielles pour les classes d'instance de base de données pour Aurora.
Par exemple, supposons que vous utilisiez la classe d'instance de base de données db.r6g.xlarge lorsque la charge de travail de votre cluster est faible. Cette classe d'instance de base de données dispose de 32 Gio de mémoire. Vous pouvez donc spécifier un nombre minimal d'unités de capacité Aurora (ACU) de 16 pour configurer une instance de base de données Aurora Serverless v2 pouvant faire l'objet d'une réduction d'échelle à cette même capacité environ. En effet, chaque ACU correspond à environ 2 Gio de mémoire. Vous pouvez spécifier une valeur légèrement inférieure pour prolonger la réduction d'échelle de l'instance de base de données au cas où votre instance de base de données db.r6g.xlarge soit parfois sous-exploitée.
-
Si votre application fonctionne le plus efficacement lorsque les instances de base de données contiennent une certaine quantité de données dans le cache de mémoire tampon, envisagez de spécifier un nombre d'ACU minimal pour lequel la mémoire est suffisamment volumineuse pour contenir les données fréquemment consultées. Sinon, certaines données sont expulsées du cache de mémoire tampon lorsque les instances de base de données Aurora Serverless v2 font l'objet d'une réduction d'échelle jusqu'à une taille de mémoire inférieure. Ensuite, lorsque les instances de base de données font à nouveau l'objet d'une augmentation d'échelle, les informations sont relues dans le cache de mémoire tampon au fil du temps. Si la quantité de données I/O à remettre dans le cache tampon est importante, il peut être plus efficace de choisir une valeur ACU minimale plus élevée.
-
Si vos instances de base de données Aurora Serverless v2 s'exécutent la plupart du temps à une capacité particulière, envisagez de spécifier une valeur minimale de capacité inférieure à cette valeur de référence, sans la définir sur une valeur trop faible. Les instances de base de données Aurora Serverless v2 peuvent estimer le plus efficacement dans quelle mesure et avec quelle rapidité procéder à l'augmentation d'échelle lorsque la capacité actuelle n'est pas nettement inférieure à la capacité requise.
-
Si votre charge de travail approvisionnée présente des exigences en mémoire trop élevées pour les petites classes d'instance de base de données telles que T3 ou T4g, choisissez un nombre minimal d'ACU qui fournit une quantité de mémoire comparable à une instance de base de données R5 ou R6g.
Nous recommandons particulièrement d'utiliser la capacité minimale suivante avec les fonctionnalités spécifiées (ces recommandations peuvent être modifiées) :
-
Informations sur les Performances — 2 ACUs
-
Bases de données globales Aurora — 8 ACUs (s'applique uniquement à la base Région AWS)
-
-
Dans Aurora, la réplication s'effectue au niveau de la couche de stockage, de sorte que la capacité du lecteur n'affecte pas directement la réplication. Toutefois, pour les instances de base de données de Aurora Serverless v2 lecture qui évoluent indépendamment, assurez-vous que la capacité minimale est suffisante pour gérer les charges de travail pendant les périodes d'écriture intensive afin d'éviter la latence des requêtes. Si les instances de base de données de lecteur des niveaux de promotion 2 à 15 rencontrent des problèmes de performances, envisagez d'augmenter la capacité minimale du cluster. Pour savoir comment choisir si les instances de base de données de lecteur sont mises à l'échelle en même temps que l'enregistreur ou indépendamment, consultez Choix du niveau de promotion pour un lecteur Aurora Serverless v2.
-
Si vous avez un cluster de base de données avec des instances de base de données de Aurora Serverless v2 lecture, les lecteurs ne sont pas dimensionnés en même temps que l'instance de base de données d'écriture lorsque le niveau de promotion des lecteurs n'est pas 0 ou 1. Dans ce cas, la définition d'une valeur minimale de capacité faible peut entraîner un retard de réplication excessif. En effet, la capacité des lecteurs peut ne pas être suffisante pour appliquer les modifications depuis l'enregistreur lorsque la base de données est occupée. Nous vous recommandons de définir la capacité minimale sur une valeur représentant une quantité de mémoire et de processeur comparable à celle de l'instance de base de données Writer.
-
La valeur du
max_connectionsparamètre pour les Aurora Serverless v2 instances de base de données est basée sur la taille de mémoire dérivée du maximum ACUs. Toutefois, lorsque vous spécifiez une capacité minimale de 0 ou 0,5 ACUs sur des instances de base de données compatibles avec PostgreSQL, la valeur maximale demax_connectionsest plafonnée à 2 000.Si vous avez l'intention d'utiliser le cluster Aurora PostgreSQL pour une charge de travail à connexion élevée, envisagez d'utiliser un nombre minimal d'ACU de 1 ou plus. Pour plus de détails sur la façon dont Aurora Serverless v2 gère le paramètre de configuration
max_connections, consultez Nombre maximal de connexions pour Aurora Serverless v2. -
La durée nécessaire à une instance de base de données Aurora Serverless v2 pour être mise à l'échelle de sa capacité minimale à sa capacité maximale dépend de la différence entre ses valeurs d'ACU minimale et maximale. Lorsque la capacité actuelle de l'instance de base de données est élevée, Aurora Serverless v2 fait l'objet d'une augmentation d'échelle par incréments plus importants que lorsque l'instance de base de données part d'une faible capacité. Par conséquent, si vous spécifiez une capacité maximale relativement élevée et que l'instance de base de données se rapproche la plupart du temps de cette capacité, envisagez d'augmenter le nombre minimal d'ACU. De cette façon, une instance de base de données inactive peut rétablir sa capacité maximale plus rapidement.
Choix de la valeur maximale de capacité Aurora Serverless v2 pour un cluster
Il peut s'avérer tentant de toujours choisir une valeur élevée pour la valeur maximale de capacité Aurora Serverless v2. Une capacité maximale élevée permet à l'instance de base de données de faire l'objet d'une augmentation d'échelle maximale lorsqu'elle exécute une charge de travail exigeant beaucoup de ressources. Une valeur faible évite la possibilité de frais inattendus. Selon votre utilisation de ce cluster et des autres paramètres que vous configurez, la valeur la plus efficace peut être supérieure ou inférieure à celle à laquelle vous pensiez initialement. Tenez compte des facteurs suivants lors du choix de la valeur maximale de capacité :
-
La capacité maximale doit être au moins aussi élevée que la capacité minimale. Vous pouvez définir la capacité minimale et la capacité maximale pour qu'elles soient identiques. Cependant, dans ce cas, la capacité ne fait jamais l'objet d'une augmentation ou d'une réduction d'échelle. Par conséquent, l'utilisation de valeurs identiques pour les capacités minimale et maximale n'est pas appropriée en dehors des situations de test.
-
La capacité maximale doit être supérieure à 0,5 ACUs. Vous pouvez définir la capacité minimale et la capacité maximale pour qu'elles soient identiques dans la plupart des cas. Toutefois, vous ne pouvez pas spécifier 0,5 à la fois pour les capacités minimale et maximale. Utilisez une valeur supérieure ou égale à 1 pour la capacité maximale.
-
Si vous modifiez généralement la classe d'instance de base de données de vos instances de base de données en prévision d'une charge de travail particulièrement élevée ou faible, vous pouvez utiliser cette expérience pour estimer la plage de capacité Aurora Serverless v2 équivalente. Pour déterminer la taille de mémoire à utiliser en période de trafic élevé, consultez Spécifications matérielles pour les classes d'instance de base de données pour Aurora.
Par exemple, supposons que vous utilisiez la classe d'instance de base de données db.r6g.4xlarge lorsque la charge de travail de votre cluster est élevée. Cette classe d'instance de base de données dispose de 128 Gio de mémoire. Vous pouvez donc spécifier un nombre maximal d'ACU de 64 pour configurer une instance de base de données Aurora Serverless v2 pouvant faire l'objet d'une augmentation d'échelle à cette même capacité environ. En effet, chaque ACU correspond à environ 2 Gio de mémoire. Vous pouvez spécifier une valeur légèrement supérieure pour prolonger l'augmentation d'échelle de l'instance de base de données au cas où votre instance de base de données db.r6g.4xlarge manque parfois de capacité pour gérer efficacement la charge de travail.
-
Si votre budget d'utilisation de la base de données est plafonné, choisissez une valeur inférieure à ce plafond, même si toutes vos instances de base de données Aurora Serverless v2 s'exécutent en permanence à leur capacité maximale. N'oubliez pas que lorsque votre cluster comporte n instances de base de données Aurora Serverless v2, la capacité maximale théorique pour Aurora Serverless v2 que le cluster peut consommer à tout moment correspond à n fois le nombre maximal d'ACU pour le cluster. (La quantité réelle consommée peut être inférieure, par exemple si certains lecteurs sont mis à l'échelle indépendamment de l'enregistreur.)
-
Si vous utilisez des instances de base de données de lecteur Aurora Serverless v2 pour décharger une partie de la charge de travail en lecture seule de l'instance de base de données d'enregistreur, vous pourrez peut-être choisir une valeur maximale de capacité inférieure. Cela permet de refléter que chaque instance de base de données de lecteur n'a pas besoin de faire l'objet d'une mise à l’échelle aussi importante que si le cluster ne contenait qu'une seule instance de base de données.
-
Supposons que vous souhaitiez vous protéger contre une utilisation excessive due à une mauvaise configuration des paramètres de base de données ou à l'inefficacité des requêtes de votre application. Dans ce cas, vous pouvez éviter une surutilisation accidentelle en choisissant une valeur maximale de capacité inférieure à la valeur absolue la plus élevée que vous pourriez définir.
-
Si les pics dus à l'activité réelle de l'utilisateur sont rares mais existent, vous pouvez les prendre en compte lorsque vous choisissez la valeur maximale de capacité. Si la priorité est que l'application continue de s'exécuter à des performances et une capacité de mise à l’échelle optimales, vous pouvez spécifier une valeur maximale de capacité supérieure à celle que vous constatez dans le cas d'une utilisation normale. S'il est admis que l'application s'exécute à un débit réduit pendant les pics d'activité très élevés, vous pouvez choisir une valeur maximale de capacité légèrement inférieure. Assurez-vous de choisir une valeur dont les ressources de mémoire et de processeur sont suffisantes pour maintenir l'application en cours d'exécution.
-
Si vous activez les paramètres de votre cluster qui augmentent l'utilisation de la mémoire pour chaque instance de base de données, tenez compte de cette mémoire lorsque vous choisissez le nombre maximal d'ACU. Ces paramètres incluent les paramètres de Performance Insights, les requêtes parallèles Aurora MySQL, le schéma de performances Aurora MySQL et la réplication des journaux binaires Aurora MySQL. Assurez-vous que le nombre maximal d'ACU permet aux instances de base de données Aurora Serverless v2 de faire l'objet d'une augmentation d'échelle suffisante pour gérer la charge de travail lorsque ces fonctionnalités sont utilisées. Pour plus d'informations sur le dépannage des problèmes provoqués par la combinaison d'un nombre maximal d'ACU faible et de fonctionnalités Aurora qui imposent une surcharge de mémoire, consultez Éviter les out-of-memory erreurs.
Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora MySQL
L' AWS CLI exemple suivant montre comment mettre à jour la plage ACU pour les instances de Aurora Serverless v2 base de données dans un cluster Aurora MySQL existant. Au départ, la plage de capacités du cluster est comprise entre 8 ACUs et 32.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
L'instance de base de données est inactive et réduite à 8 ACUs. Les paramètres de capacité suivants s'appliquent à l'instance de base de données à ce stade. Pour représenter la taille du groupe de mémoires tampons en unités facilement lisibles, nous la divisons par 2 puissance 30, ce qui donne une mesure en gibioctets (Gio). En effet, les mesures liées à la mémoire pour Aurora utilisent des unités basées sur des puissances de 2 et non des puissances de 10.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 9294577664 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 8.65625 | +-----------+ 1 row in set (0.00 sec)
Ensuite, nous modifions la plage de capacité du cluster. Une fois la commande modify-db-cluster terminée, la plage d'ACU du cluster est comprise entre 12,5 et 80.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
La modification de la plage de capacité a modifié les valeurs par défaut de certains paramètres de configuration. Aurora peut appliquer immédiatement certaines de ces nouvelles valeurs par défaut. Cependant, certaines modifications de paramètre ne prennent effet qu'après un redémarrage. Le statut pending-reboot indique qu'un redémarrage est nécessaire pour appliquer certaines modifications de paramètre.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
À ce stade, le cluster est inactif et l'instance de base de données serverless-v2-instance-1 consomme 12,5 ACUs. Le paramètre innodb_buffer_pool_size est déjà ajusté en fonction de la capacité actuelle de l'instance de base de données. Le paramètre max_connections reflète toujours la valeur de l'ancienne capacité maximale. La réinitialisation de cette valeur exige de redémarrer l'instance de base de données.
Note
Si vous définissez le max_connections paramètre directement dans un groupe de paramètres de base de données personnalisé, aucun redémarrage n'est nécessaire.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 15572402176 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +---------------+ | gibibytes | +---------------+ | 14.5029296875 | +---------------+ 1 row in set (0.00 sec)
À présent, nous redémarrons l'instance de base de données et nous attendons qu'elle soit de nouveau disponible.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
L'état pending-reboot est effacé. La valeur in-sync confirme qu'Aurora a appliqué l'ensemble des modifications de paramètre en attente.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
Le paramètre innodb_buffer_pool_size a augmenté jusqu'à sa taille finale pour une instance de base de données inactive. Le paramètre max_connections a augmenté pour refléter une valeur dérivée du nombre maximal d'ACU. La formule utilisée par Aurora pour max_connections entraîne une augmentation de 1 000 lorsque la taille de mémoire double.
mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 16139681792 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 15.03125 | +-----------+ 1 row in set (0.00 sec) mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 4000 | +-------------------+ 1 row in set (0.00 sec)
Nous définissons la plage de capacité entre 0,5 et 128 ACUs et redémarrons l'instance de base de données. À présent, l'instance de base de données inactive a une taille de cache de mémoire tampon inférieure à 1 Gio. Nous la mesurons donc en mébioctets (Mio). La valeur 5 000 de max_connections est dérivée de la taille de mémoire du paramètre de capacité maximale.
mysql> select @@innodb_buffer_pool_size / pow(2,20) as mebibytes, @@max_connections; +-----------+-------------------+ | mebibytes | @@max_connections | +-----------+-------------------+ | 672 | 5000 | +-----------+-------------------+ 1 row in set (0.00 sec)
Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora PostgreSQL
Les exemples d'interface de ligne de commande suivants montrent comment mettre à jour la plage d'ACU pour les instances de base de données Aurora Serverless v2 d'un cluster Aurora PostgreSQL existant.
-
La plage de capacité du cluster commence entre 0,5 et 1 ACU.
-
Modifiez la plage de capacité sur 8—32. ACUs
-
Modifiez la plage de capacité sur 12,5 à 80. ACUs
-
Modifiez la plage de capacité sur 0,5 à 128. ACUs
-
Ramenez la capacité à sa plage initiale de 0,5 à 1 ACU.
La figure suivante montre les changements de capacité sur Amazon CloudWatch.
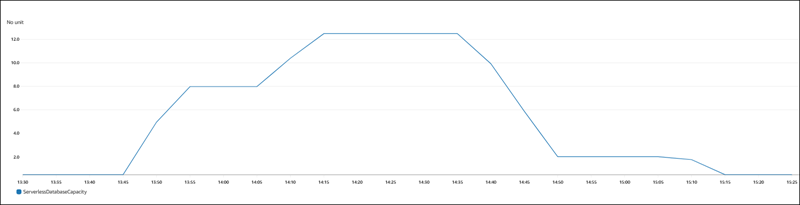
L'instance de base de données est inactive et réduite à 0,5 ACUs. Les paramètres de capacité suivants s'appliquent à l'instance de base de données à ce stade.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Ensuite, nous modifions la plage de capacité du cluster. Une fois la commande modify-db-cluster terminée, la plage ACU pour le cluster est de 8 à 32.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
La modification de la plage de capacité modifie les valeurs par défaut de certains paramètres de configuration. Aurora peut appliquer immédiatement certaines de ces nouvelles valeurs par défaut. Cependant, certaines modifications de paramètre ne prennent effet qu'après un redémarrage. Le statut pending-reboot indique qu'un redémarrage est nécessaire pour appliquer certaines modifications de paramètre.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
À ce stade, le cluster est inactif et l'instance serverless-v2-instance-1 de base de données consomme 8.0 ACUs. Le paramètre shared_buffers est déjà ajusté en fonction de la capacité actuelle de l'instance de base de données. Le paramètre max_connections reflète toujours la valeur de l'ancienne capacité maximale. La réinitialisation de cette valeur exige de redémarrer l'instance de base de données.
Note
Si vous définissez le max_connections paramètre directement dans un groupe de paramètres de base de données personnalisé, aucun redémarrage n'est nécessaire.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Nous redémarrons l'instance de base de données et nous attendons qu'elle soit de nouveau disponible.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
Maintenant que l'instance de base de données est redémarrée, le statut pending-reboot est effacé. La valeur in-sync confirme qu'Aurora a appliqué l'ensemble des modifications de paramètre en attente.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
Après le redémarrage, max_connections indique la valeur de la nouvelle capacité maximale.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Ensuite, nous modifions la plage de capacité du cluster de 12,5 à 80. ACUs
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
À ce stade, le cluster est inactif et l'instance de base de données serverless-v2-instance-1 consomme 12,5 ACUs. Le paramètre shared_buffers est déjà ajusté en fonction de la capacité actuelle de l'instance de base de données. La valeur max_connections est toujours de 5 000.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Nous redémarrons à nouveau, mais les valeurs des paramètres restent les mêmes. C'est parce que max_connections présente une valeur maximale de 5 000 pour un cluster de bases de données Aurora Serverless v2 exécutant Aurora PostgreSQL.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Nous définissons maintenant la plage de capacité de 0,5 à 128 ACUs. Le cluster de base de données est réduit à 10 ACUs, puis à 2. Nous redémarrons l'instance de base de données.
postgres=> show max_connections; max_connections ----------------- 2000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
La max_connections valeur des Aurora Serverless v2 instances de base de données est basée sur la taille de mémoire dérivée du maximum ACUs. Toutefois, lorsque vous spécifiez une capacité minimale de 0 ou 0,5 ACUs sur des instances de base de données compatibles avec PostgreSQL, la valeur maximale de max_connections est plafonnée à 2 000.
Maintenant, nous remettons la capacité à sa plage initiale de 0,5 0 1 ACU et nous redémarrons l'instance de base de données. Le paramètre max_connections a retrouvé sa valeur d'origine.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Utilisation des groupes de paramètres pour Aurora Serverless v2
Lorsque vous créez votre cluster de base de données Aurora Serverless v2, vous choisissez un moteur de bases de données Aurora spécifique et un groupe de paramètres de cluster de base de données associé. Si vous n'êtes pas familier avec la façon dont Aurora utilise les groupes de paramètres pour appliquer les paramètres de configuration de manière cohérente entre les clusters, consultez Groupes de paramètres pour Amazon Aurora (). Toutes ces procédures de création, de modification, d'application et d'autres actions pour les groupes de paramètres s'appliquent à Aurora Serverless v2.
La fonction de groupe de paramètres fonctionne généralement de la même manière entre les clusters approvisionnés et les clusters contenant des instances de base de données Aurora Serverless v2 :
-
Les valeurs de paramètre par défaut pour l'ensemble des instances de base de données du cluster sont définies par le groupe de paramètres du cluster.
-
Vous pouvez remplacer certains paramètres pour des instances de base de données spécifiques en spécifiant un groupe de paramètres de base de données personnalisé pour ces instances de base de données. Vous pouvez le faire pendant le débogage ou le réglage des performances pour certaines instances de base de données. Par exemple, supposons que vous disposez d'un cluster contenant des instances de base de données Aurora Serverless v2 et des instances de base de données approvisionnées. Dans ce cas, vous pouvez spécifier des paramètres différents pour les instances de base de données approvisionnées à l'aide d'un groupe de paramètres de base de données personnalisé.
-
Pour Aurora Serverless v2, vous pouvez utiliser tous les paramètres ayant la valeur
provisioneddans l'attributSupportedEngineModesdu groupe de paramètres. Dans Aurora Serverless v1, vous ne pouvez utiliser que le sous-ensemble de paramètres ayantserverlessdans l'attributSupportedEngineModes.
Rubriques
Valeurs des paramètres par défaut
La différence cruciale entre les instances de base de données approvisionnées et les instances de base de données Aurora Serverless v2 réside dans le fait qu'Aurora remplace toutes les valeurs de paramètre personnalisées pour certains paramètres liés à la capacité d'instance de base de données. Les valeurs de paramètre personnalisées s'appliquent toujours à l'ensemble des instances de base de données approvisionnées de votre cluster. Pour en savoir plus sur la façon dont les instances de base de données Aurora Serverless v2 interprètent les paramètres des groupes de paramètres Aurora, consultez Paramètres de configuration des clusters Aurora. Pour obtenir les paramètres qui sont remplacés par Aurora Serverless v2, consultez Paramètres ajustés par Aurora en fonction de l'augmentation et de la réduction d'échelle d'Aurora Serverless v2 et Paramètres calculés par Aurora en fonction de la capacité maximale d'Aurora Serverless v2.
Vous pouvez obtenir une liste des valeurs par défaut pour les groupes de paramètres par défaut des différents moteurs de base de données Aurora en utilisant la commande describe-db-cluster-parametersCLI et en interrogeant le Région AWS. Les valeurs suivantes peuvent être utilisées pour les options --db-parameter-group-family et -db-parameter-group-name pour les versions de moteur compatibles avec Aurora Serverless v2.
| Moteur de base de données et version | Famille du groupe de paramètres | Nom du groupe de paramètres par défaut |
|---|---|---|
|
Aurora MySQL version 3 |
|
|
|
Aurora PostgreSQL version 13.x |
|
|
|
Aurora PostgreSQL version 14.x |
|
|
|
Aurora PostgreSQL version 15.x |
|
|
|
Aurora PostgreSQL version 16.x |
|
|
|
Aurora PostgreSQL version 17.x |
|
|
L'exemple suivant illustre l'obtention d'une liste de paramètres depuis le groupe de clusters de bases de données par défaut pour Aurora MySQL version 3 et Aurora PostgreSQL version 13. Ce sont les versions d'Aurora MySQL et d'Aurora PostgreSQL que vous utilisez avec Aurora Serverless v2.
Pour LinuxmacOS, ou Unix :
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-mysql8.0 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-postgresql13 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text
Dans Windows :
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-mysql8.0 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-postgresql13 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text
Nombre maximal de connexions pour Aurora Serverless v2
Pour Aurora MySQL et Aurora PostgreSQL, les instances de base de données Aurora Serverless v2 maintiennent une valeur constante pour le paramètre max_connections afin que les connexions ne soient pas interrompues lorsque l'instance de base de données fait l'objet d'une réduction d'échelle. La valeur par défaut de ce paramètre est dérivée d'une formule basée sur la taille de la mémoire de l'instance de base de données. Pour plus d'informations sur la formule et les valeurs par défaut des classes d'instance de base de données approvisionnée, consultez Nombre maximal de connexions à une instance de base de données Aurora MySQL et Nombre maximal de connexions à une instance de base de données Aurora PostgreSQL.
Lors de l'Aurora Serverless v2évaluation de la formule, elle utilise la taille de mémoire basée sur les unités de capacité Aurora maximales (ACUs) pour l'instance de base de données, et non sur la valeur ACU actuelle. Si vous modifiez la valeur par défaut, nous vous recommandons d'utiliser une variation de la formule plutôt que de spécifier une valeur constante. De cette façon, Aurora Serverless v2 peut utiliser un réglage approprié en fonction de la capacité maximale.
Lorsque vous modifiez la capacité maximale d'un cluster de bases de données Aurora Serverless v2, vous devez redémarrer les instances de base de données Aurora Serverless v2 pour mettre à jour la valeur max_connections. Cela est dû au fait que max_connections est un paramètre statique pour Aurora Serverless v2.
Le tableau suivant indique les valeurs par défaut de max_connections pour Aurora Serverless v2 en fonction de la valeur maximale d'ACU.
| Maximum ACUs | Nombre maximal de connexions par défaut sur Aurora MySQL | Nombre maximal de connexions par défaut sur Aurora PostgreSQL |
|---|---|---|
| 1 | 90 | 189 |
| 4 | 135 | 823 |
| 8 | 1 000 | 1 669 |
| 16 | 2 000 | 3 360 |
| 32 | 3 000 | 5 000 |
| 64 | 4 000 | 5 000 |
| 128 | 5 000 | 5 000 |
| 192 | 6 000 | 5 000 |
| 256 | 6 000 | 5 000 |
Note
La max_connections valeur des Aurora Serverless v2 instances de base de données est basée sur la taille de mémoire dérivée du maximum ACUs. Toutefois, lorsque vous spécifiez une capacité minimale de 0 ou 0,5 ACUs sur des instances de base de données compatibles avec PostgreSQL, la valeur maximale de max_connections est plafonnée à 2 000.
Pour obtenir des exemples spécifiques montrant comment max_connections évolue avec la valeur maximale d'ACU, consultez Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora MySQL et Exemple : Modification de la plage de capacité Aurora Serverless v2 d'un cluster Aurora PostgreSQL.
Paramètres ajustés par Aurora en fonction de l'augmentation et de la réduction d'échelle d'Aurora Serverless v2
Lors de la mise à l'échelle automatique, Aurora Serverless v2 doit être en mesure de modifier les paramètres pour que chaque instance de base de données fonctionne mieux en fonction de l'augmentation ou de la diminution de la capacité. Par conséquent, vous ne pouvez pas remplacer certains paramètres liés à la capacité. Pour les paramètres que vous pouvez remplacer, évitez de coder en dur les valeurs fixes. Les remarques suivantes s'appliquent aux paramètres liés à la capacité.
Pour Aurora MySQL, Aurora Serverless v2 redimensionne certains paramètres dynamiquement pendant la mise à l'échelle. Pour les paramètres suivants, Aurora Serverless v2 n'utilise aucune valeur de paramètre personnalisée que vous spécifiez :
-
innodb_buffer_pool_size -
innodb_purge_threads -
table_definition_cache -
table_open_cache
Pour Aurora PostgreSQL, Aurora Serverless v2 redimensionne dynamiquement le paramètre suivant pendant la mise à l'échelle. Pour les paramètres suivants, Aurora Serverless v2 n'utilise aucune valeur de paramètre personnalisée que vous spécifiez :
-
shared_buffers
Pour tous les paramètres autres que ceux énumérés ici, les instances de base de données Aurora Serverless v2 fonctionnent de la même manière que les instances de base de données provisionnées. La valeur de paramètre par défaut est héritée du groupe de paramètres de cluster. Vous pouvez modifier la valeur par défaut pour l'ensemble du cluster à l'aide d'un groupe de paramètres de cluster personnalisé. Sinon, vous pouvez modifier la valeur par défaut de certaines instances de base de données à l'aide d'un groupe de paramètres de base de données personnalisé. Les paramètres dynamiques sont immédiatement mis à jour. Les modifications apportées aux paramètres statiques ne prennent effet qu'après le redémarrage de l'instance de base de données.
Paramètres calculés par Aurora en fonction de la capacité maximale d'Aurora Serverless v2
Pour les paramètres suivants, Aurora PostgreSQL utilise des valeurs par défaut dérivées de la taille de mémoire basée sur le nombre maximal d'ACU, comme avec max_connections :
-
autovacuum_max_workers -
autovacuum_vacuum_cost_limit -
autovacuum_work_mem -
effective_cache_size -
maintenance_work_mem
Éviter les out-of-memory erreurs
Si l'une de vos instances de base de données Aurora Serverless v2 atteint systématiquement la limite de sa capacité maximale, Aurora indique cette condition en définissant le statut de l'instance de base de données sur incompatible-parameters. Lorsque l'instance de base de données a le statut incompatible-parameters, certaines opérations sont bloquées. Par exemple, vous ne pouvez pas mettre à niveau la version du moteur.
Généralement, votre instance de base de données passe dans cet état lorsqu'elle redémarre fréquemment en raison d' out-of-memoryerreurs. Aurora enregistre un événement lorsque ce type de redémarrage se produit. Vous pouvez afficher l'événement en suivant la procédure de la rubrique Consulter les RDS événements Amazon. Une utilisation exceptionnellement élevée de la mémoire peut se produire en raison de la surcharge provoquée par l'activation de paramètres tels que Performance Insights et l'authentification IAM. Elle peut également se produire en raison d'une charge de travail importante sur votre instance de base de données ou de la gestion des métadonnées associées à un grand nombre d'objets de schéma.
Si la pression de la mémoire diminue de sorte que l'instance de base de données n'atteint pas très souvent sa capacité maximale, Aurora rétablit automatiquement le statut available de l'instance de base de données.
Pour vous remettre de cet état, vous pouvez prendre tout ou partie des mesures suivantes :
-
Augmentez la limite inférieure de capacité pour les instances de base de données Aurora Serverless v2 en modifiant le nombre minimal d'ACU pour le cluster. Cela évite les situations problématiques où une base de données inactive fait l'objet d'une réduction d'échelle jusqu'à une capacité où la mémoire est inférieure à la mémoire nécessaire pour les fonctionnalités activées dans votre cluster. Après avoir modifié les paramètres d'ACU du cluster, redémarrez l'instance de base de données Aurora Serverless v2. Cela permet d'évaluer si Aurora peut réinitialiser le statut sur
available. -
Augmentez la limite supérieure de capacité pour les instances de base de données Aurora Serverless v2 en modifiant le nombre maximal d'ACU pour le cluster. Cela évite les situations problématiques où une base de données occupée ne peut pas faire l'objet d'une augmentation d'échelle jusqu'à une capacité où la mémoire est suffisante pour les fonctionnalités activées dans votre cluster et pour la charge de travail de la base de données. Après avoir modifié les paramètres d'ACU du cluster, redémarrez l'instance de base de données Aurora Serverless v2. Cela permet d'évaluer si Aurora peut réinitialiser le statut sur
available. -
Désactivez les paramètres de configuration exigeant une surcharge de mémoire. Supposons, par exemple, que des fonctionnalités telles que AWS Identity and Access Management (IAM), Performance Insights ou la réplication des journaux binaires Aurora MySQL soient activées mais que vous ne les utilisez pas. Si c'est le cas, vous pouvez les désactiver. Vous pouvez également augmenter les valeurs de capacité minimale et maximale du cluster pour tenir compte de la mémoire utilisée par ces fonctionnalités. Pour obtenir des directives sur le choix des valeurs de capacité minimale et maximale, consultez Choix de la plage de capacité Aurora Serverless v2 pour un cluster Aurora.
-
Réduisez la charge de travail sur l'instance de base de données. Par exemple, vous pouvez ajouter des instances de base de données de lecteur au cluster afin de répartir la charge issue des requêtes en lecture seule sur d'autres instances de base de données.
-
Réglez le code SQL utilisé par votre application pour utiliser moins de ressources. Par exemple, vous pouvez examiner vos plans de requête, vérifier le journal des requêtes lentes ou ajuster les index de vos tables. Vous pouvez également effectuer d'autres types de réglages SQL traditionnels.
Statistiques Amazon CloudWatch importantes pour Aurora Serverless v2
Pour commencer à utiliser Amazon CloudWatch pour votre Aurora Serverless v2 instance de base de données, consultezAfficher Aurora Serverless v2 les journaux sur Amazon CloudWatch. Pour en savoir plus sur la façon de surveiller les clusters de base de données Aurora via CloudWatch, consultezSurveillance des événements du journal sur Amazon CloudWatch.
Vous pouvez afficher vos Aurora Serverless v2 instances de base de données CloudWatch pour surveiller la capacité consommée par chaque instance de base de données à l'aide de la ServerlessDatabaseCapacity métrique. Vous pouvez également surveiller toutes les CloudWatch métriques Aurora standard, telles que DatabaseConnections etQueries. Pour obtenir la liste complète des CloudWatch mesures que vous pouvez surveiller pour Aurora, consultez CloudWatch Métriques Amazon pour Amazon Aurora. Les métriques, de niveau cluster et de niveau instance, sont décrites aux rubriques Métriques de niveau cluster pour Amazon Aurora et Métriques de niveau instance pour Amazon Aurora.
Il est important de surveiller les métriques suivantes CloudWatch au niveau de l'instance afin de comprendre comment vos Aurora Serverless v2 instances de base de données augmentent ou diminuent. Toutes ces métriques sont calculées toutes les secondes. De cette façon, vous pouvez surveiller le statut actuel de vos instances de base de données Aurora Serverless v2. Vous pouvez définir des alarmes qui vous avertissent si une instance de base de données Aurora Serverless v2 se rapproche d'un seuil pour les métriques liées à la capacité. Vous pouvez déterminer si les valeurs de capacité minimale et maximale sont appropriées ou si vous devez les ajuster. Vous pouvez déterminer où concentrer vos efforts pour optimiser l'efficacité de votre base de données.
-
ServerlessDatabaseCapacity. En tant que métrique au niveau de l'instance, elle indique le nombre de personnes ACUs représentées par la capacité actuelle de l'instance de base de données. En tant que métrique de niveau cluster, elle représente la moyenne des valeursServerlessDatabaseCapacityde toutes les instances de base de données Aurora Serverless v2 du cluster. Cette métrique est uniquement une métrique de niveau cluster dans Aurora Serverless v1. Dans Aurora Serverless v2, elle est disponible au niveau de l'instance de base de données et au niveau du cluster. -
ACUUtilization. Il s'agit d'une nouvelle métrique dans Aurora Serverless v2. Cette valeur est représentée sous forme de pourcentage. Elle est calculée comme la valeur de la métriqueServerlessDatabaseCapacitydivisée par le nombre maximal d'ACU du cluster de bases de données. Tenez compte des directives suivantes pour interpréter cette métrique et prendre les mesures nécessaires :-
Si cette métrique se rapproche de la valeur
100.0, l'instance de base de données a fait l'objet d'une augmentation d'échelle aussi élevée que possible. Envisagez d'augmenter le nombre maximal d'ACU pour le cluster. De cette façon, les instances de base de données de lecteur et d'enregistreur peuvent être mis à l'échelle jusqu'à une capacité supérieure. -
Supposons qu'une charge de travail en lecture seule force une instance de base de données de lecteur à se rapprocher de la valeur
100.0pourACUUtilization, alors que l'instance de base de données d'enregistreur n'est pas proche de sa capacité maximale. Dans ce cas, envisagez d'ajouter des instances de base de données de lecteur supplémentaires au cluster. De cette façon, vous pouvez répartir la partie en lecture seule de la charge de travail sur un plus grand nombre d'instances de base de données, réduisant ainsi la charge sur chaque instance de base de données de lecteur. -
Supposons que vous exécutiez une application de production, où les performances et la capacité de mise à l’échelle sont les principaux facteurs à prendre en compte. Dans ce cas, vous pouvez définir le nombre maximal d'ACU du cluster sur une valeur élevée. Votre objectif est que la métrique
ACUUtilizationsoit toujours inférieure à100.0. Avec un nombre maximal d'ACU élevé, vous avez la garantie que l'espace est suffisant en cas de pics d'activité inattendus de la base de données. Seule la capacité de base de données réellement consommée vous est facturée.
-
-
CPUUtilization. Cette métrique est interprétée différemment dans Aurora Serverless v2 par rapport aux instances de base de données approvisionnées. Pour Aurora Serverless v2, cette valeur est un pourcentage calculé comme la quantité de processeur actuellement utilisée, divisée par la capacité de processeur disponible sous le nombre maximal d'ACU du cluster de bases de données Aurora surveille automatiquement cette valeur et augmente l'échelle de votre instance de base de données Aurora Serverless v2 lorsque cette dernière utilise systématiquement une proportion élevée de sa capacité de processeur.Si cette métrique se rapproche de la valeur
100.0, l'instance de base de données a atteint sa capacité de processeur maximale. Envisagez d'augmenter le nombre maximal d'ACU pour le cluster. Si cette métrique se rapproche de la valeur100.0sur une instance de base de données de lecteur, envisagez d'ajouter des instances de base de données de lecteur supplémentaires au cluster. De cette façon, vous pouvez répartir la partie en lecture seule de la charge de travail sur un plus grand nombre d'instances de base de données, réduisant ainsi la charge sur chaque instance de base de données de lecteur. -
FreeableMemory. Cette valeur représente la quantité de mémoire inutilisée disponible lorsque l'instance de base de données Aurora Serverless v2 est mise à l'échelle jusqu'à sa capacité maximale. Pour chaque ACU dont la capacité actuelle est inférieure à la capacité maximale, cette valeur augmente d'environ 2 Gio. Par conséquent, cette métrique ne se rapproche pas de zéro tant que l'instance de base de données ne fait pas l'objet d'une augmentation d'échelle aussi élevée que possible.Si cette métrique se rapproche de la valeur
0, l'instance de base de données a fait l'objet d'une augmentation d'échelle aussi élevée que possible et se rapproche de la limite de sa mémoire disponible. Envisagez d'augmenter le nombre maximal d'ACU pour le cluster. Si cette métrique se rapproche de la valeur0sur une instance de base de données de lecteur, envisagez d'ajouter des instances de base de données de lecteur supplémentaires au cluster. De cette façon, vous pouvez répartir la partie en lecture seule de la charge de travail sur un plus grand nombre d'instances de base de données, réduisant ainsi l'utilisation de la mémoire sur chaque instance de base de données de lecteur. -
TempStorageIOPS. Nombre d'E/S par seconde réalisées sur le stockage local attaché à l'instance de base de données. Il inclut les E/S par seconde pour les lectures et les écritures. Cette métrique représente un nombre et est mesurée une fois par seconde. Il s'agit d'une nouvelle mesure pour Aurora Serverless v2. Pour en savoir plus, consultez Métriques de niveau instance pour Amazon Aurora. -
TempStorageThroughput. Volume de données transférées depuis et vers le stockage local associé à l'instance de base de données. Cette métrique représente des octets et est mesurée une fois par seconde. Il s'agit d'une nouvelle mesure pour Aurora Serverless v2. Pour en savoir plus, consultez Métriques de niveau instance pour Amazon Aurora.
Généralement, la plupart des augmentations d'échelle pour Aurora Serverless v2 est engendrée par l'utilisation de la mémoire et l'activité du processeur. Les métriques TempStorageIOPS et TempStorageThroughput peuvent vous aider à diagnostiquer les rares cas où l'activité du réseau pour les transferts entre votre instance de base de données et vos périphériques de stockage locaux est responsable d'augmentations de capacité inattendues. Pour surveiller d'autres activités du réseau, vous pouvez utiliser ces métriques existantes :
-
NetworkReceiveThroughput -
NetworkThroughput -
NetworkTransmitThroughput -
StorageNetworkReceiveThroughput -
StorageNetworkThroughput -
StorageNetworkTransmitThroughput
Vous pouvez demander à Aurora de publier une partie ou la totalité des journaux de base de données sur Amazon CloudWatch Logs. Pour obtenir des instructions, consultez les rubriques suivantes en fonction de votre moteur de base de données :
Comment Aurora Serverless v2 les indicateurs s'appliquent à votre AWS facture
Les Aurora Serverless v2 frais figurant sur votre AWS facture sont calculés en fonction des mêmes ServerlessDatabaseCapacity indicateurs que vous pouvez surveiller. Le mécanisme de facturation peut différer de la CloudWatch moyenne calculée pour cette métrique dans les cas où vous n'utilisez la Aurora Serverless v2 capacité que pendant une partie d'heure. Cela peut également être différent si des problèmes du système rendent la CloudWatch métrique indisponible pendant de brèves périodes. Par conséquent, la valeur correspondant aux heures ACU peut être légèrement différente sur votre facture que si vous calculez vous-même le nombre à partir de la valeur moyenne de ServerlessDatabaseCapacity.
Exemples de CloudWatch commandes pour les Aurora Serverless v2 métriques
Les AWS CLI exemples suivants montrent comment vous pouvez surveiller les CloudWatch indicateurs les plus importants liés àAurora Serverless v2. Dans chaque cas, remplacez la chaîne Value= du paramètre --dimensions par l'identifiant de votre propre instance de base de données Aurora Serverless v2.
L'exemple Linux suivant affiche les valeurs de capacité minimale, maximale et moyenne d'une instance de base de données, mesurées toutes les 10 minutes sur une heure. La commande Linux date indique les heures de début et de fin par rapport à la date et à l'heure actuelles. La fonction sort_by du paramètre --query trie les résultats par ordre chronologique en fonction du champ Timestamp.
aws cloudwatch get-metric-statistics --metric-name "ServerlessDatabaseCapacity" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Les exemples Linux suivants illustrent la surveillance de la capacité de chaque instance de base de données d'un cluster. Ils mesurent l'utilisation de capacité minimale, maximale et moyenne de chaque instance de base de données. Les mesures sont effectuées une fois par heure sur une période de trois heures. Ces exemples utilisent la ACUUtilization métrique représentant un pourcentage de la limite supérieure de ACUs, au lieu de ServerlessDatabaseCapacity représenter un nombre fixe de ACUs. De cette façon, vous n'avez pas besoin de connaître les chiffres réels pour les nombres d'ACU minimal et maximal dans la plage de capacité. Les pourcentages sont compris entre 0 et 100.
aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_writer_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_reader_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
L'exemple Linux suivant effectue des mesures similaires aux précédentes. Dans ce cas, les mesures concernent la métrique CPUUtilization. Les mesures sont effectuées toutes les 10 minutes sur une période d'une heure. Les chiffres représentent le pourcentage de processeur disponible utilisé, en fonction des ressources de processeur disponibles pour la valeur de capacité maximale de l'instance de base de données.
aws cloudwatch get-metric-statistics --metric-name "CPUUtilization" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
L'exemple Linux suivant effectue des mesures similaires aux précédentes. Dans ce cas, les mesures concernent la métrique FreeableMemory. Les mesures sont effectuées toutes les 10 minutes sur une période d'une heure.
aws cloudwatch get-metric-statistics --metric-name "FreeableMemory" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Surveillance des performances d'Aurora Serverless v2 avec Performance Insights
Vous pouvez utiliser Performance Insights pour surveiller les performances des instances de base de données Aurora Serverless v2. Pour connaître les procédures relatives à Performance Insights, consultez Surveillance de la charge de la base de données avec Performance Insights sur .
Les nouveaux compteurs Performance Insights suivants s'appliquent aux instances de base de données Aurora Serverless v2.
-
os.general.serverlessDatabaseCapacity— La capacité actuelle de l'instance de base de données dans ACUs. La valeur correspond à laServerlessDatabaseCapacityCloudWatch métrique de l'instance de base de données. -
os.general.acuUtilization: pourcentage de la capacité actuelle par rapport à la capacité maximale configurée. La valeur correspond à laACUUtilizationCloudWatch métrique de l'instance de base de données. -
os.general.maxConfiguredAcu: capacité maximale que vous avez configurée pour cette instance de base de données Aurora Serverless v2. C'est mesuré en ACUs. -
os.general.minConfiguredAcu– Capacité minimale que vous avez configurée pour cette instance de base de données Aurora Serverless v2. Il est mesuré en ACUs
Pour obtenir la liste complète des compteurs Performance Insights, consultez Métrique de compteur de Performance Insights.
Lorsque les valeurs vCPU sont affichées pour une instance de base de données Aurora Serverless v2 dans Performance Insights, ces valeurs représentent des estimations basées sur le nombre d'ACU pour l'instance de base de données. À l'intervalle par défaut d'une minute, toutes les valeurs vCPU fractionnelles sont arrondies au nombre entier le plus proche. Pour les intervalles plus longs, la valeur vCPU affichée correspond à la moyenne des valeurs entières de vCPU pour chaque minute.
Résolution des problèmes de capacité d'Aurora Serverless v2
Dans certains cas, Aurora Serverless v2 ne se réduit pas à la capacité minimale, même si la base de données n'est pas chargée. Plusieurs raisons sont possibles :
-
Certaines fonctionnalités peuvent augmenter l'utilisation des ressources et empêcher la réduction de la base de données à sa capacité minimale. Les principales fonctions sont notamment :
-
Bases de données globales Aurora
-
Exportation de CloudWatch journaux
-
Activation de
pg_auditsur les clusters de bases de données compatibles avec Aurora PostgreSQL -
Surveillance améliorée
-
Performance Insights
Pour de plus amples informations, veuillez consulter Choix de la valeur minimale de capacité Aurora Serverless v2 pour un cluster.
-
-
Si une instance de lecture n'est pas réduite au minimum et reste à une capacité identique ou supérieure à celle de l'instance d'écriture, vérifiez le niveau de priorité de l'instance de lecture. Les instances de base de données Aurora Serverless v2 de lecture de niveau 0 ou 1 sont maintenues à une capacité minimale au moins aussi élevée que l'instance de base de données d'écriture. Changez le niveau de priorité du processus de lecture à 2 ou plus pour qu'il augmente et diminue indépendamment du processus d'écriture. Pour de plus amples informations, veuillez consulter Choix du niveau de promotion pour un lecteur Aurora Serverless v2.
-
Définissez tous les paramètres de la base de données qui ont un impact sur la taille de la mémoire partagée à leurs valeurs par défaut. La définition d'une valeur supérieure à la valeur par défaut augmente les besoins en mémoire partagée et empêche la base de données de se réduire à la capacité minimale. Par exemple,
max_connectionsetmax_locks_per_transaction.Note
La mise à jour des paramètres de mémoire partagée nécessite un redémarrage de la base de données pour que les changements prennent effet.
-
De lourdes charges de travail de base de données peuvent augmenter l'utilisation des ressources.
-
D'importants volumes de base de données peuvent augmenter l'utilisation des ressources.
Amazon Aurora utilise des ressources de mémoire et de processeur pour la gestion des clusters de bases de données. Aurora nécessite plus d'UC et de mémoire pour gérer des clusters de bases de données comportant d'importants volumes de base de données. Si la capacité minimale de votre cluster est inférieure à la capacité minimale requise pour la gestion du cluster, votre cluster ne sera pas réduit à la capacité minimale.
-
Les processus d'arrière-plan, tels que la purge, peuvent également augmenter l'utilisation des ressources.
-
Les limites de version de la plate-forme peuvent affecter les capacités de mise à l'échelle. La plage de mise à l'échelle disponible pour un cluster donné dépend à la fois de la version du moteur et du matériel (version de la plate-forme). Il est possible qu'une version de moteur plus performante fonctionne sur une version de plate-forme moins performante et vice-versa.
Si la base de données n'est toujours pas réduite à la capacité minimale configurée, arrêtez et redémarrez la base de données pour récupérer les fragments de mémoire qui ont pu s'accumuler au fil du temps. L'arrêt et le démarrage d'une base de données entraînent un temps d'arrêt, il est donc recommandé de le faire avec parcimonie.
