Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Meilleures pratiques pour gérer les many-to-many relations dans les tables DynamoDB
Les listes d'adjacence constituent un modèle de conception utile pour modéliser les many-to-many relations dans Amazon DynamoDB. Plus généralement, elles fournissent une manière de représenter des données de graphique (nœuds et arcs) dans DynamoDB.
Modèle de conception de liste adjacente
Lorsque différentes entités d'une application ont une many-to-many relation entre elles, cette relation peut être modélisée sous forme de liste d'adjacence. Dans ce modèle, toutes les entités de niveau supérieur (soit les nœuds dans le modèle de graphique) sont représentées à l'aide de la clé de partition. Toute relation avec d'autres entités (arcs dans un graphique) est représentée comme un élément de la partition via la définition de l'ID d'entité cible (nœud cible) en tant que valeur de la clé de tri.
Parmi les avantages de ce modèle, on peut citer la duplication minimale des données et les modèles de requête simplifiés pour la recherche de toutes les entités (nœuds) liées à une entité cible (disposant d'un arc vers un nœud cible).
Un système de facturation dans lequel les factures contiennent plusieurs notes constitue un exemple concret pour lequel ce modèle s'avère utile. Une note peut appartenir à plusieurs factures. Dans cet exemple, la clé de partition est InvoiceID ou BillID. Les partitions BillID ont tous les attributs spécifiques aux notes. Les partitions InvoiceID ont un élément qui stocke les attributs spécifiques à la facture, et un élément pour chaque BillID qui se regroupe dans la facture.
Le schéma se présente comme suit :
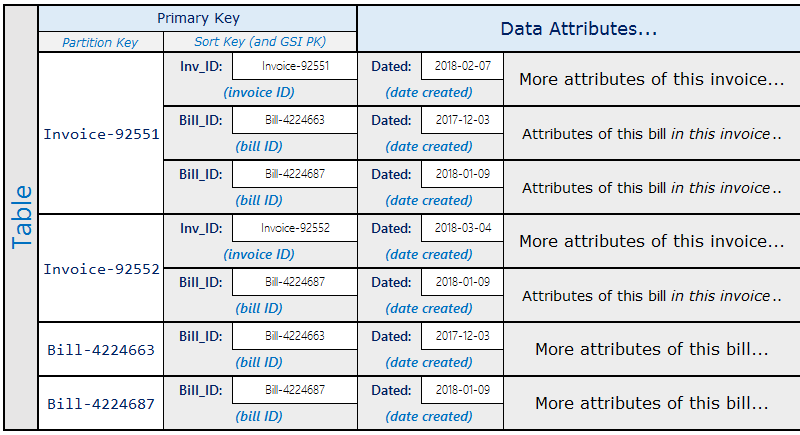
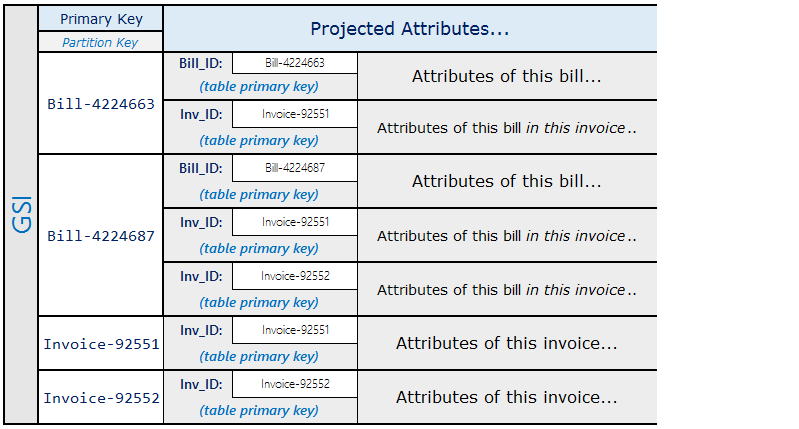
En utilisant le schéma précédent, vous pouvez voir que toutes les notes d'une facture peuvent être interrogées à l'aide de la clé primaire sur la table. Pour rechercher toutes les factures contenant une partie d'une note, créez un index secondaire global sur la clé de tri de la table.
Les projections pour l'index secondaire global se présentent comme suit :
Modèle de graphique matérialisé
De nombreuses applications sont construites autour de la compréhension des classements entre pairs, des relations communes entre entités, de l'état de l'entité voisine et d'autres types de flux de travail de style de graphique. Pour ces types d'applications, prenez en compte le modèle de conception de schéma suivant :
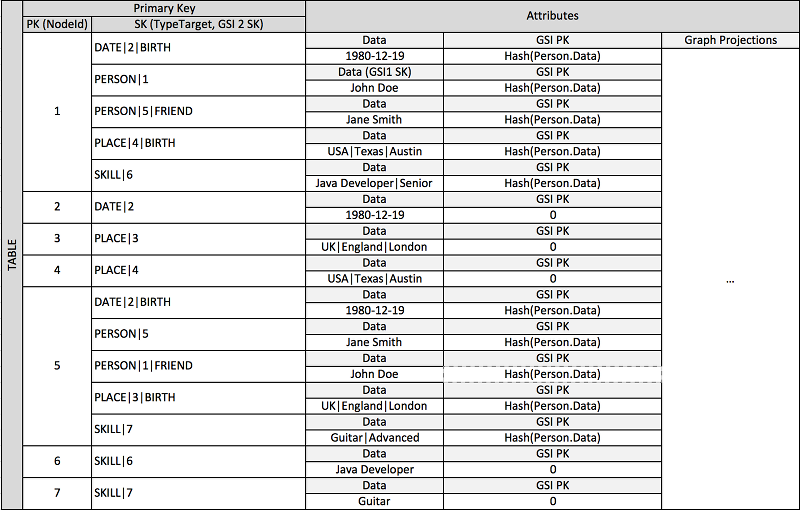
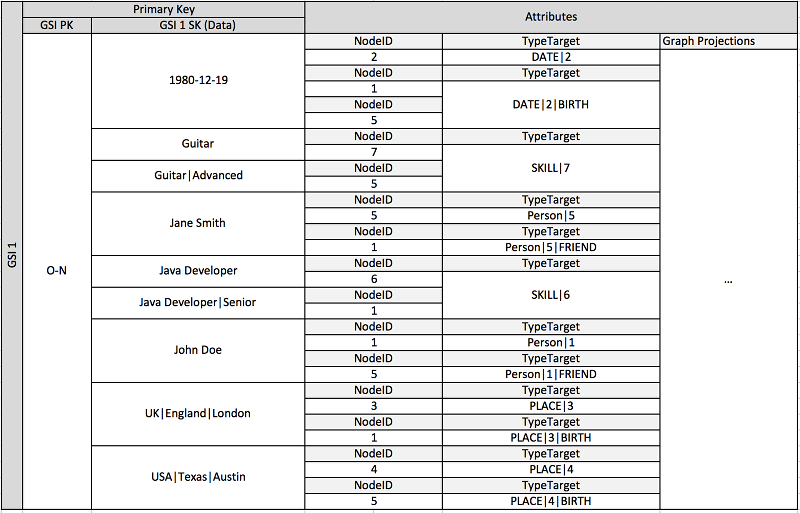
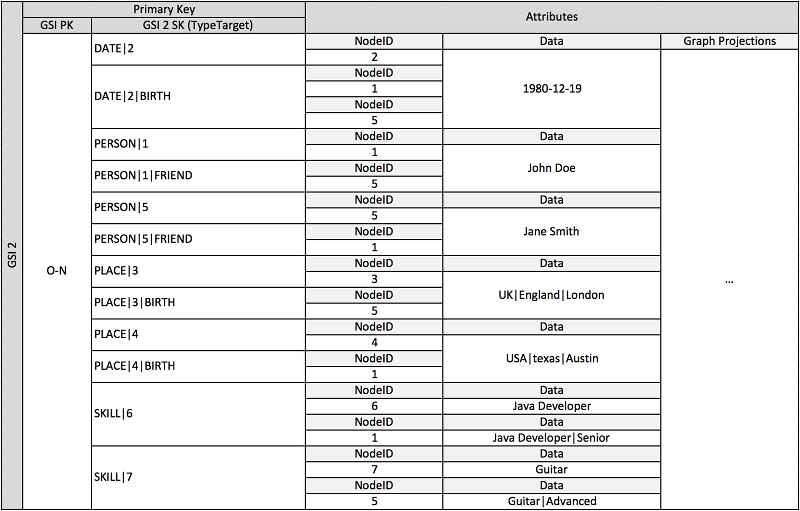
Le schéma précédent illustre une structure de données de graphique définie par un ensemble de partitions de données contenant les éléments qui définissent les arcs et les nœuds du graphique. Les éléments d'arc contiennent les attributs Target et Type. Ces attributs sont utilisés dans le cadre d'un nom de clé composite TypeTarget « » pour identifier l'élément dans une partition de la table principale ou dans un deuxième index secondaire global.
Le premier index secondaire global est construit en fonction de l'attribut Data. Cet attribut utilise la surcharge d'index secondaire global comme décrit précédemment pour indexer plusieurs types d'attribut différents, principalement Dates, Names, Places et Skills. Ici, un index secondaire global indexe effectivement quatre attributs différents.
À mesure que vous insérez des éléments dans la table, vous pouvez utilisez une stratégie de partitionnement intelligent pour répartir les ensembles d'éléments avec des regroupements importants (date de naissance, compétence) sur autant de partitions logiques sur les index secondaires globaux que nécessaire pour éviter les problèmes de lecture/écriture à chaud.
Le résultat de cette combinaison de modèles de conception est un magasin de données solide pour des flux de travail de graphiques en temps réel efficaces. Ces flux de travail peuvent fournir un état de l'entité voisine haute performance et des requêtes de regroupement d'arcs pour des moteurs de recommandations, des classements de nœuds, des regroupements de sous-arborescences, ainsi que d'autres cas d'utilisation de graphiques courants.
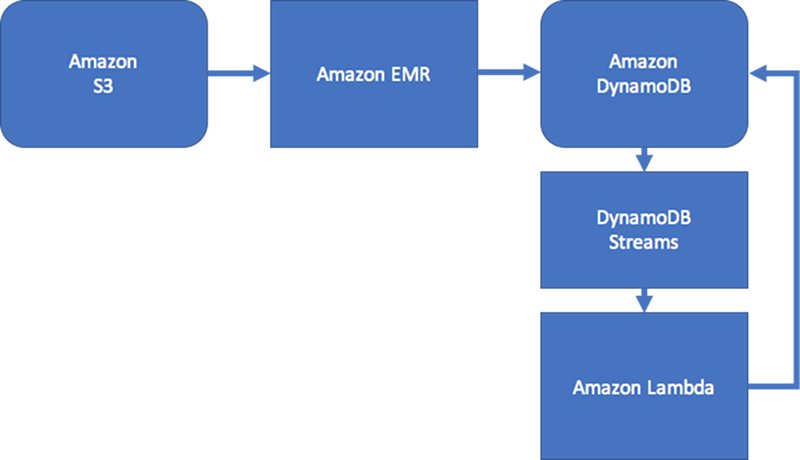
Si votre cas d'utilisation n'est pas sensible à la cohérence des données en temps réel, vous pouvez utiliser un processus Amazon EMR planifié pour remplir les arcs avec des regroupements récapitulatifs de graphique pour vos flux de travail. Si votre application n'a pas besoin de connaître immédiatement le moment où un arc est ajouté au graphique, vous pouvez utiliser un processus planifié pour regrouper les résultats.
Pour conserver un certain niveau de cohérence, la conception peut inclure Amazon DynamoDB Streams et AWS Lambda pour le traitement des mises à jour d'arc. Elle peut aussi utiliser une tâche Amazon EMR pour valider les résultats à intervalles réguliers. Le diagramme suivant illustre cette approche. Elle est généralement utilisée dans des applications de réseau social, où le coût d'une requête en temps réel est élevé, et où le besoin de connaître de manière immédiate les mises à jour utilisateur individuelles est faible.
Les applications de gestion de service ITSM et de sécurité ont généralement besoin de répondre en temps réel aux modifications de l'état d'une entité composées de regroupements d'arcs complexe. Ces applications nécessitent un système pouvant prendre en charge des regroupements en temps réel de plusieurs nœuds présentant des relations de deuxième ou de troisième niveau, ou des traversées d'arcs complexes. Si votre cas d'utilisation nécessite des types de flux de travail de requêtes de graphique en temps réel, nous vous recommandons d'envisager l'utilisation d'Amazon Neptune pour la gestion de ces flux de travail.
Note
Si vous devez interroger des jeux de données hautement connectés ou exécuter des requêtes qui doivent traverser plusieurs nœuds (également nommées requêtes à sauts multiples) avec une latence de quelques millisecondes, vous devriez envisager d'utiliser Amazon Neptune. Amazon Neptune est un moteur de base de données orientée graphe très performant et créé sur mesure, optimisé pour le stockage de milliards de relations et les requêtes de graphe avec une latence de l'ordre de quelques millisecondes.
