Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Premiers pas pour la modélisation des données relationnelles dans DynamoDB
Important
Pour concevoir un système NoSQL, il faut un autre état d'esprit que pour un SGBDR. Pour un SGBDR, vous pouvez créer un modèle de données normalisé sans réfléchir aux modèles d'accès. Vous pouvez l'étendre ultérieurement, pour répondre à de nouvelles questions et de nouveaux besoins d'interrogation. En revanche, dans Amazon DynamoDB, vous ne devez pas commencer à concevoir votre schéma tant que vous ne savez pas à quelle problématique celui-ci doit répondre. Il est absolument essentiel d'identifier au préalable les problèmes métier et les cas d'utilisation de l'application.
Pour commencer à concevoir une table DynamoDB qui pourra être efficacement mise à l'échelle, vous devez d'abord effectuer plusieurs étapes pour identifier les modèles d'accès qui sont requis par les systèmes de support d'exploitation et de support d'activités (OSS/BSS) que celle-ci doit prendre en charge :
Pour les nouvelles applications, consultez des témoignages d'utilisateurs sur les activités et les objectifs. Documentez les différents cas d'utilisation que vous identifiez et analysez les modèles d'accès dont ceux-ci ont besoin.
Pour des applications existantes, analysez les journaux de requêtes pour découvrir comment le système est actuellement utilisé et identifier les principaux modèles d'accès.
Après avoir terminé ce processus, vous devriez obtenir une liste ressemblant à ce qui suit :
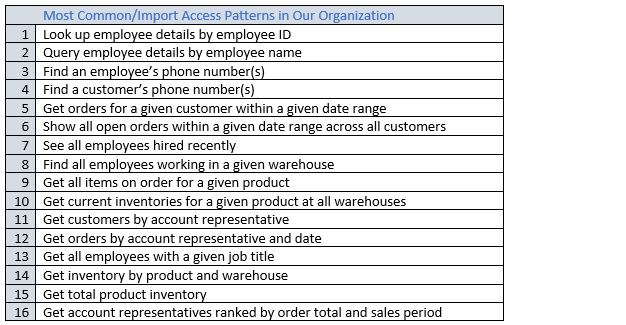
Dans une application réelle, votre liste peut être beaucoup plus longue. Mais cette collection représente toute la complexité d'un modèle de requête que vous pourriez trouver dans un environnement de production.
Une approche courante de la conception de schémas DynamoDB consiste à identifier les entités de la couche application et à utiliser la dénormalisation et l'agrégation de clés composites pour réduire la complexité des requêtes.
Dans DynamoDB, cela implique d'utiliser des clés de tri composites, des index secondaires globaux surchargés, des tables/index partitionnés et d'autres modèles de conception. Vous pouvez utiliser ces éléments pour structurer les données afin qu'une application puisse récupérer ce dont elle a besoin pour un modèle d'accès donné à l'aide d'une requête unique sur une table ou un index. Le modèle principal que vous pouvez utiliser pour modéliser le schéma normalisé illustré dans Modélisation relationnelle est le modèle de liste adjacente. D'autres modèles utilisés dans cette conception peuvent inclure le partitionnement d'écriture d'index secondaire global, la surcharge d'index secondaire globale, des clés composites et des regroupements matérialisés.
Important
En règle générale, vous devez gérer le moins de tables possible dans une application DynamoDB. Les cas où des données de série chronologique volumineuses sont impliquées ou dans lesquels les ensembles de données ont des modèles d'accès très différents sont des exemples d'exceptions. Une table unique avec des index inversés peut généralement permettre à des requêtes simples de créer et récupérer les structures de données hiérarchiques complexes dont votre application a besoin.
Pour utiliser NoSQL Workbench pour DynamoDB afin de mieux visualiser votre conception de clé de partition, consultez Création de modèles de données avec NoSQL Workbench.
