Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques de modélisation des données relationnelles dans DynamoDB
Cette section présente les bonnes pratiques de modélisation des données relationnelles dans Amazon DynamoDB Tout d'abord, nous présentons les concepts traditionnels de modélisation des données. Ensuite, nous décrivons les avantages liés à l'utilisation de DynamoDB par rapport aux systèmes de gestion de base de données relationnelle traditionnels, en expliquant en quoi cela dispense d'utiliser des opérations JOIN et réduit les frais généraux.
Nous expliquons ensuite comment concevoir une table DynamoDB qui se met à l'échelle de manière efficace. Enfin, nous proposons un exemple de modélisation de données relationnelles dans DynamoDB.
Rubriques
Modèles de base de données relationnelle traditionnels
Un système de gestion de base de données relationnelle (SGBDR) traditionnel stocke les données dans une structure relationnelle normalisée. L'objectif du modèle de données relationnel est de réduire la duplication des données (par le biais de la normalisation) afin de garantir l'intégrité référentielle et de réduire les anomalies des données.
Le schéma suivant est un exemple de modèle de données relationnel pour une application de saisie de commandes générique. Cette application prend en charge un schéma de ressources humaines qui soutient les systèmes de support d'exploitation et d'activités d'un fabricant fictif.
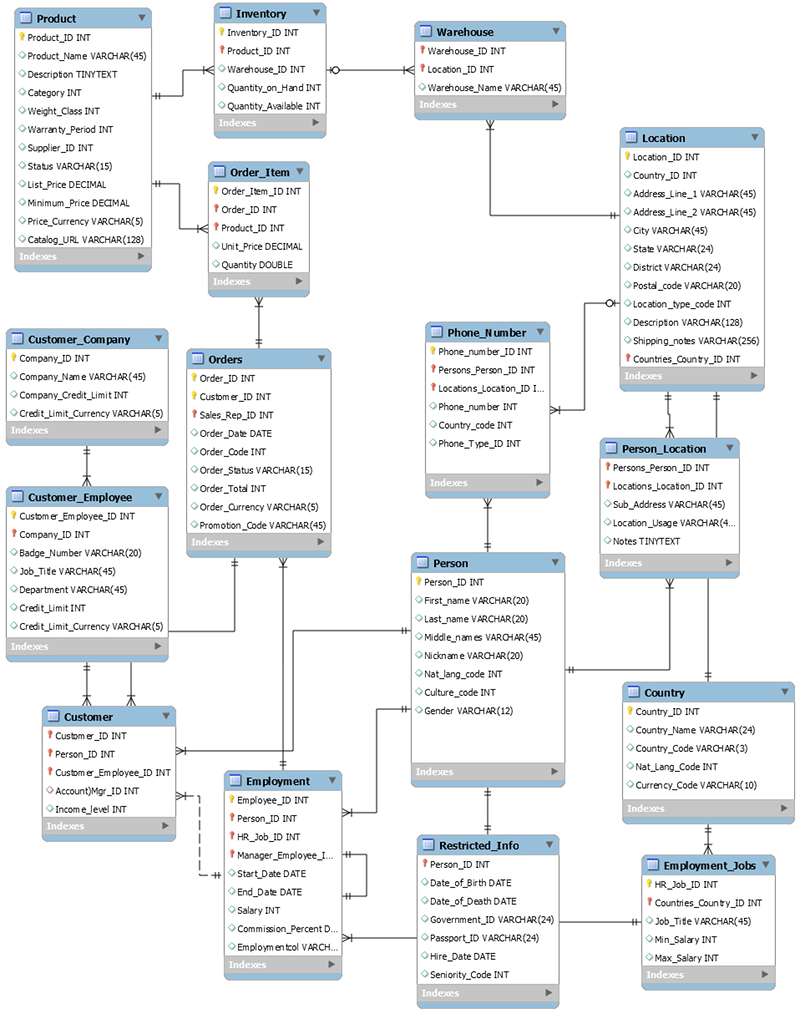
En tant que service de base de données non relationnelle, DynamoDB offre de nombreux avantages par rapport aux systèmes de gestion de base de données relationnelle traditionnels.
Comment DynamoDB élimine le besoin d'opérations JOIN
Un SGBDR utilise un langage SQL (Structure Query Language) pour renvoyer les données à l'application. Du fait de la normalisation du modèle de données, les requêtes de ce type nécessitent généralement l'utilisation de l'opérateur JOIN pour associer les données d'une ou plusieurs tables.
Par exemple, pour générer une liste d'articles de bon de commande triés selon la quantité en stock dans tous les entrepôts pouvant livrer chacun d'entre eux, vous pouvez exécuter la requête SQL suivante sur le schéma précédent.
SELECT * FROM Orders
INNER JOIN Order_Items ON Orders.Order_ID = Order_Items.Order_ID
INNER JOIN Products ON Products.Product_ID = Order_Items.Product_ID
INNER JOIN Inventories ON Products.Product_ID = Inventories.Product_ID
ORDER BY Quantity_on_Hand DESCLes requêtes SQL de ce type peuvent fournir une API flexible pour accéder aux données, mais elles nécessitent un volume de traitement important. Chaque jointure contenue dans la requête accentue la complexité d'exécution de la requête, car les données de chaque table doivent être préparées, puis assemblées pour renvoyer le jeu de résultats.
La taille des tables et la présence d'index dans les colonnes jointes sont d'autres facteurs qui peuvent avoir une incidence sur le temps d'exécution des requêtes. La requête précédente initie des requêtes complexes sur plusieurs tables, puis trie le jeu de résultats.
L'élimination du besoin de JOINs est au cœur de la modélisation des données NoSQL. C'est pourquoi nous avons conçu DynamoDB pour qu'il soit compatible avec Amazon.com, et c'est pourquoi DynamoDB peut fournir des performances constantes à n'importe quelle échelle. Compte tenu de la complexité d'exécution des requêtes SQL et des JOINs, les performances d'un SGBDR ne sont pas constantes à grande échelle. Cela entraîne des problèmes de performances à mesure que les applications des clients se développent.
Bien que la normalisation des données réduise la quantité de données stockées sur le disque, les ressources les plus limitées qui ont un impact sur les performances sont souvent le temps processeur et la latence du réseau.
DynamoDB est conçu pour minimiser ces deux contraintes en éliminant JOINs (et en encourageant la dénormalisation des données) et en optimisant l'architecture de la base de données afin de répondre entièrement à une requête d'application avec une seule requête pour un élément. Ces qualités permettent à DynamoDB d'offrir des performances en millisecondes à un chiffre à n'importe quelle échelle. Cela s'explique par le fait que la complexité d'exécution des opérations DynamoDB est constante, quelle que soit la taille des données, pour les modèles d'accès courants.
Comment les transactions DynamoDB éliminent la surcharge pour le processus d'écriture
L'utilisation de transactions pour écrire dans un schéma normalisé est un autre facteur de ralentissement d'un SGBDR. Comme indiqué dans l'exemple, les structures de données relationnelles utilisées par la plupart des applications de traitement de transaction en ligne (OLTP) doivent être décomposées et réparties dans plusieurs tables logiques lorsqu'elles sont stockées dans un SGBDR.
Par conséquent, une infrastructure de transaction conforme à ACID est nécessaire pour éviter les conditions de concurrence et les problèmes d'intégrité des données pouvant avoir lieu si une application tente de lire un objet qui est en cours d'écriture. Une telle structure de transaction, lorsqu'elle est associée à un schéma relationnel, peut surcharger considérablement le processus d'écriture.
L'implémentation des transactions dans DynamoDB permet d'éviter les problèmes de mise à l'échelle qui sont souvent constatés avec un SGBDR. Pour ce faire, DynamoDB émet une transaction sous la forme d'un appel d'API unique et limite le nombre d'éléments accessibles dans cette même transaction. Les transactions de longue durée peuvent entraîner des problèmes opérationnels en bloquant les données de manière prolongée, voire perpétuelle, car la transaction n'est jamais clôturée.
Pour éviter de tels problèmes dans DynamoDB, les transactions ont été implémentées avec deux opérations d'API distinctes : TransactWriteItems et TransactGetItems. La sémantique de début et de fin de ces opérations d'API n'est pas commune dans un SGBDR. De plus, DynamoDB impose une limite d'accès à 100 éléments dans une même transaction dans une optique similaire qui est d'empêcher les transactions de longue durée. Pour en savoir plus sur les transactions DynamoDB, consultez Utilisation de transactions.
Ce sont les raisons pour lesquelles, lorsque votre activité exige une réponse à faible latence pour des requêtes à fort trafic, il est généralement judicieux, d'un point de vue technique et économique, de tirer parti des avantages d'un système NoSQL. Amazon DynamoDB aide à résoudre les problèmes qui restreignent la capacité de mise à l'échelle d'un système relationnel en les évitant.
Les performances d'un SGBDR peinent généralement à évoluer pour les raisons suivantes :
-
Elle utilise des jointures coûteuses pour reconstituer les vues de résultats de requête requises.
-
Elle normalise les données et les stocke dans plusieurs tables qui nécessitent plusieurs requêtes pour l'écriture sur disque.
-
Elle entraîne généralement les coûts de performances d'un système de transaction conforme à ACID.
DynamoDB se met à l'échelle coorectement pour les raisons suivantes :
-
Grâce à la flexibilité de son schéma, DynamoDB peut stocker des données hiérarchiques complexes au sein d'un seul élément.
-
Une conception de clé composite permet à ce service de stocker les éléments liés proches les uns des autres dans la même table.
-
Les transactions sont effectuées dans une même opération. Le nombre d'éléments accessibles est limité à 100 pour éviter les opérations de longue durée.
Les requêtes sur le magasin de données deviennent beaucoup plus simples, en prenant souvent la forme suivante :
SELECT * FROM Table_X WHERE Attribute_Y = "somevalue"
DynamoDB exécute beaucoup moins de tâches pour renvoyer les données demandées, comparé au SGBDR de l'exemple précédent.
