Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur Amazon Athena pour Neptune
Amazon Neptune est un service de base de données orientée graphe entièrement géré et fiable, qui facilite la création et l'exécution d'applications fonctionnant avec des jeux de données hautement connectés. Neptune conçu spécialement, haute performance, le moteur de base de données graphique stocke des milliards de relations de manière optimale et des requêtes sur les graphiques avec une latence de seulement quelques millisecondes. Pour plus d'informations, consultez Neptune Guide de l'utilisateur.
Le connecteur Amazon Athena Neptune permet à Athena de communiquer avec votre instance de base de données orientée graphe Neptune, rendant vos données de graphe Neptune accessibles par des requêtes SQL.
Ce connecteur n'utilise pas Glue Connections pour centraliser les propriétés de configuration dans Glue. La configuration de la connexion s'effectue via Lambda.
Si Lake Formation est activé sur votre compte, le rôle IAM de votre connecteur Lambda fédéré Athena que vous avez déployé dans AWS Serverless Application Repository le doit avoir un accès en lecture dans Lake Formation au. AWS Glue Data Catalog
Prérequis
L’utilisation du connecteur Neptune nécessite les trois étapes suivantes.
-
Configuration d’un cluster Neptune
-
Configuration d'un AWS Glue Data Catalog
-
Déploiement du connecteur sur votre Compte AWS. Pour plus d’informations, consultez Création d'une connexion à une source de données ou Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données. Pour plus d'informations spécifiques au déploiement du connecteur Neptune, consultez la section Déployer le connecteur Amazon Athena Neptune
sur .com. GitHub
Limites
Actuellement, le connecteur Neptune présente les limites suivantes.
-
La projection de colonnes, y compris la clé primaire (ID), n'est pas prise en charge.
Configuration d’un cluster Neptune
Si vous ne disposez pas d’un cluster Amazon Neptune et d’un jeu de données de graphes de propriétés que vous souhaitez utiliser, vous devez en configurer un.
Assurez-vous de disposer d’une passerelle Internet et d’une passerelle NAT dans le VPC qui héberge votre cluster Neptune. Les sous-réseaux privés utilisés par la fonction Lambda du connecteur Neptune doivent avoir une route vers Internet via cette passerelle NAT. La fonction Lambda du connecteur Neptune utilise la passerelle NAT pour communiquer avec. AWS Glue
Pour obtenir des instructions sur la configuration d'un nouveau cluster Neptune et son chargement avec un exemple de jeu de données, consultez Sample Neptune Cluster
Configuration d’un AWS Glue Data Catalog
Contrairement aux magasins de données relatives traditionnels, les nœuds et les périphéries de base de données de graphe Neptune n’utilisent pas de schéma défini. Chaque entrée peut comporter des champs et des types de données différents. Toutefois, étant donné que le connecteur Neptune extrait les métadonnées du AWS Glue Data Catalog, vous devez créer une AWS Glue base de données contenant des tables avec le schéma requis. Après avoir créé la base de données et les tables AWS Glue , le connecteur peut fournir la liste des tables disponibles pour effectuer des requêtes auprès d’Athena.
Activation de la mise en correspondance non sensible à la casse des colonnes
Pour résoudre les noms de colonnes de votre table Neptune avec le boitier correct, même si les noms de colonnes sont tous en minuscules AWS Glue, vous pouvez configurer le connecteur Neptune pour une correspondance insensible aux majuscules et minuscules.
Pour activer cette fonctionnalité, définissez la variable d'environnement de la fonction Lambda du connecteur Neptune de enable_caseinsensitivematch à true.
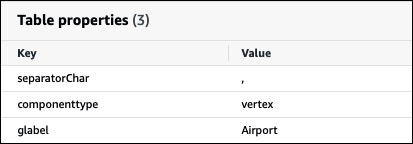
Spécification du paramètre de table AWS Glue glabel pour les noms de table en majuscules
Étant donné que seuls AWS Glue les noms de table en minuscules sont pris en charge, il est important de spécifier le paramètre de glabel AWS Glue table lorsque vous créez une AWS Glue table pour Neptune et que le nom de votre table Neptune inclut le boîtier.
Dans la définition de votre AWS Glue table, incluez le glabel paramètre et attribuez à sa valeur le nom de votre table avec son boîtier d'origine. Cela garantit que le boîtier correct est préservé lors de AWS Glue l'interaction avec votre table Neptune. L'exemple suivant définit la valeur de glabel sur le nom de la table Airport.
glabel = Airport
Pour plus d'informations sur la configuration d'un AWS Glue Data Catalog pour qu'il fonctionne avec Neptune, voir Configurer le AWS Glue catalogue sur GitHub .com
Performances
Le connecteur Athena Neptune effectue une poussée vers le bas des prédicats pour réduire les données analysées par la requête. Cependant, les prédicats utilisant la clé primaire entraînent l'échec de la requête. LIMITles clauses réduisent la quantité de données numérisées, mais si vous ne fournissez pas de prédicat, vous devez vous attendre à ce que les SELECT requêtes contenant une LIMIT clause analysent au moins 16 Mo de données. Le connecteur Neptune résiste à la limitation due à la simultanéité.
Requêtes passthrough
Le connecteur Neptune prend en charge les requêtes directes. Vous pouvez utiliser cette fonctionnalité pour exécuter des requêtes Gremlin sur des graphes de propriétés et pour exécuter des requêtes SPARQL sur des données RDF.
Pour créer des requêtes directes avec Neptune, utilisez la syntaxe suivante :
SELECT * FROM TABLE( system.query( DATABASE => 'database_name', COLLECTION => 'collection_name', QUERY => 'query_string' ))
L'exemple suivant donne un exemple de filtre de requête Neptune passthrough pour les aéroports utilisant le code. ATL Les guillemets simples doublés servent à s'échapper.
SELECT * FROM TABLE( system.query( DATABASE => 'graph-database', COLLECTION => 'airport', QUERY => 'g.V().has(''airport'', ''code'', ''ATL'').valueMap()' ))
Ressources supplémentaires
Pour plus d'informations sur ce connecteur, rendez-vous sur le site correspondant
