Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Formez votre premier DeepRacer modèle AWS
Cette présentation explique comment entraîner votre premier modèle à l'aide de la DeepRacer console AWS.
Formez un modèle d'apprentissage par renforcement à l'aide de la DeepRacer console AWS
Découvrez où se trouve le bouton Créer un modèle dans la DeepRacer console AWS pour commencer votre parcours de formation aux modèles.
Pour former un modèle d'apprentissage par renforcement
-
Si c'est la première fois que vous utilisez AWS DeepRacer, choisissez Create model sur la page d'accueil du service ou sélectionnez Get started sous le titre Reinforcement learning dans le volet de navigation principal.
-
Sur la page Commencer l'apprentissage par renforcement, sous Étape 2 : créer un modèle, choisissez Créer un modèle.
Vous pouvez également choisir Vos modèles sous le titre Apprentissage par renforcement dans le volet de navigation principal. Sur la page Vos modèles, choisissez Créer un modèle.
Spécifiez le nom du modèle et l'environnement
Donnez un nom à votre modèle et apprenez à choisir la piste de simulation qui vous convient.
Pour spécifier le nom du modèle et l'environnement
-
Sur la page Créer un modèle, sous Détails de la formation, entrez le nom de votre modèle.
-
Ajoutez éventuellement une description du poste de formation.
-
Pour en savoir plus sur l'ajout de balises facultatives, consultezIdentification.
-
Sous Simulation d'environnement, choisissez une piste qui servira d'environnement de formation à votre DeepRacer agent AWS. Sous Direction de la piste, choisissez dans le sens des aiguilles d'une montre ou dans le sens antihoraire. Ensuite, choisissez Suivant.
Pour votre première course, choisissez une piste avec une forme simple et des virages lisses. Dans les itérations ultérieures, vous pourrez choisir des pistes plus complexes afin d'améliorer progressivement vos modèles. Pour former un modèle pour une course particulière, choisissez la piste qui s'en rapproche le plus.
-
Choisissez Next au bas de la page.
Choisissez un type de course et un algorithme d'entraînement
La DeepRacer console AWS propose trois types de courses et deux algorithmes d'entraînement parmi lesquels choisir. Découvrez ceux qui conviennent à votre niveau de compétence et à vos objectifs d'entraînement.
Pour choisir un type de course et un algorithme d'entraînement
-
Sur la page Créer un modèle, sous Type de course, sélectionnez Contre-la-montre, Évitement d'objets ou ead-to-botH.
Pour votre première course, nous vous recommandons de choisir Time Trial. Pour obtenir des conseils sur l'optimisation de la configuration des capteurs de votre agent pour ce type de course, consultezPersonnalisez la DeepRacer formation AWS pour les contre-la-montre.
-
Éventuellement, lors des courses ultérieures, choisissez l'option Évitement d'objets pour contourner les obstacles fixes placés à des endroits fixes ou aléatoires le long de la piste choisie. Pour de plus amples informations, veuillez consulter Personnalisez la DeepRacer formation AWS pour les courses d'évitement d'objets.
-
Choisissez Emplacement fixe pour générer des cases à des emplacements fixes désignés par l'utilisateur sur les deux voies de la piste ou sélectionnez Emplacement aléatoire pour générer des objets répartis aléatoirement sur les deux voies au début de chaque épisode de votre simulation d'entraînement.
-
Choisissez ensuite une valeur pour le nombre d'objets sur une piste.
-
Si vous avez choisi Position fixe, vous pouvez ajuster le placement de chaque objet sur la piste. Pour le placement des voies, choisissez entre la voie intérieure et la voie extérieure. Par défaut, les objets sont répartis uniformément sur la piste. Pour modifier la distance entre la ligne de départ et la ligne d'arrivée d'un objet, entrez un pourcentage de cette distance entre 7 et 90 dans le champ Emplacement (%) entre le début et la fin.
-
-
En option, pour les courses plus ambitieuses, choisissez la Head-to-bot course pour affronter jusqu'à quatre véhicules robots se déplaçant à vitesse constante. Pour en savoir plus, consultez Personnalisez l' DeepRacer entraînement AWS pour les head-to-bot courses.
-
Sous Choisissez le nombre de véhicules de robots, sélectionnez le nombre de véhicules de robots que vous souhaitez que votre agent entraîne.
-
Ensuite, choisissez la vitesse en millimètres par seconde à laquelle vous souhaitez que les robots circulent sur la piste.
-
Cochez éventuellement la case Activer les changements de voie pour permettre aux véhicules du bot de changer de voie de manière aléatoire toutes les 1 à 5 secondes.
-
-
Sous Algorithme d'entraînement et hyperparamètres, choisissez l'algorithme Soft Actor Critic (SAC) ou Proximal Policy Optimization (PPO). Dans la DeepRacer console AWS, les modèles SAC doivent être entraînés dans des espaces d'action continue. Les modèles PPO peuvent être entraînés dans des espaces d'action continus ou discrets.
-
Sous Algorithme d'apprentissage et hyperparamètres, utilisez les valeurs d'hyperparamètres par défaut telles quelles.
Par la suite, pour améliorer les performances de la formation, développez Hyperparameters (Hyperparamètres) et modifiez les valeurs d'hyperparamètre par défaut comme suit :
-
Pour Gradient descent batch size (Taille de lot pour la descente de gradient), choisissez parmi les options disponibles.
-
Pour Number of epochs (Nombre d'époques), définissez une valeur valide.
-
Pour Learning rate (Taux d'apprentissage), définissez une valeur valide.
-
Pour la valeur alpha du SAC (algorithme SAC uniquement), définissez une valeur valide.
-
Pour Entropy (Entropie), définissez une valeur valide.
-
Pour Discount factor (Facteur d'actualisation), définissez une valeur valide.
-
Pour Loss type (Type de perte), choisissez parmi les options disponibles.
-
Pour Number of experience episodes between each policy-updating iteration (Nombre d'épisodes d'expérience entre chaque itération de mise à jour de politique), définissez une valeur valide.
Pour de amples informations sur les hyperparamètres, veuillez consulter Régler systématiquement les hyperparamètres.
-
-
Choisissez Suivant.
Définissez l'espace d'action
Sur la page Définir un espace d'action, si vous avez choisi de vous entraîner avec l'algorithme Soft Actor Critic (SAC), votre espace d'action par défaut est l'espace d'action continu. Si vous avez choisi de vous entraîner avec l'algorithme d'optimisation des politiques proximales (PPO), choisissez entre un espace d'action continu et un espace d'action discret. Pour en savoir plus sur la façon dont chaque espace d'action et chaque algorithme façonnent l'expérience d'entraînement de l'agent, voirEspace DeepRacer d'action AWS et fonction de récompense.
-
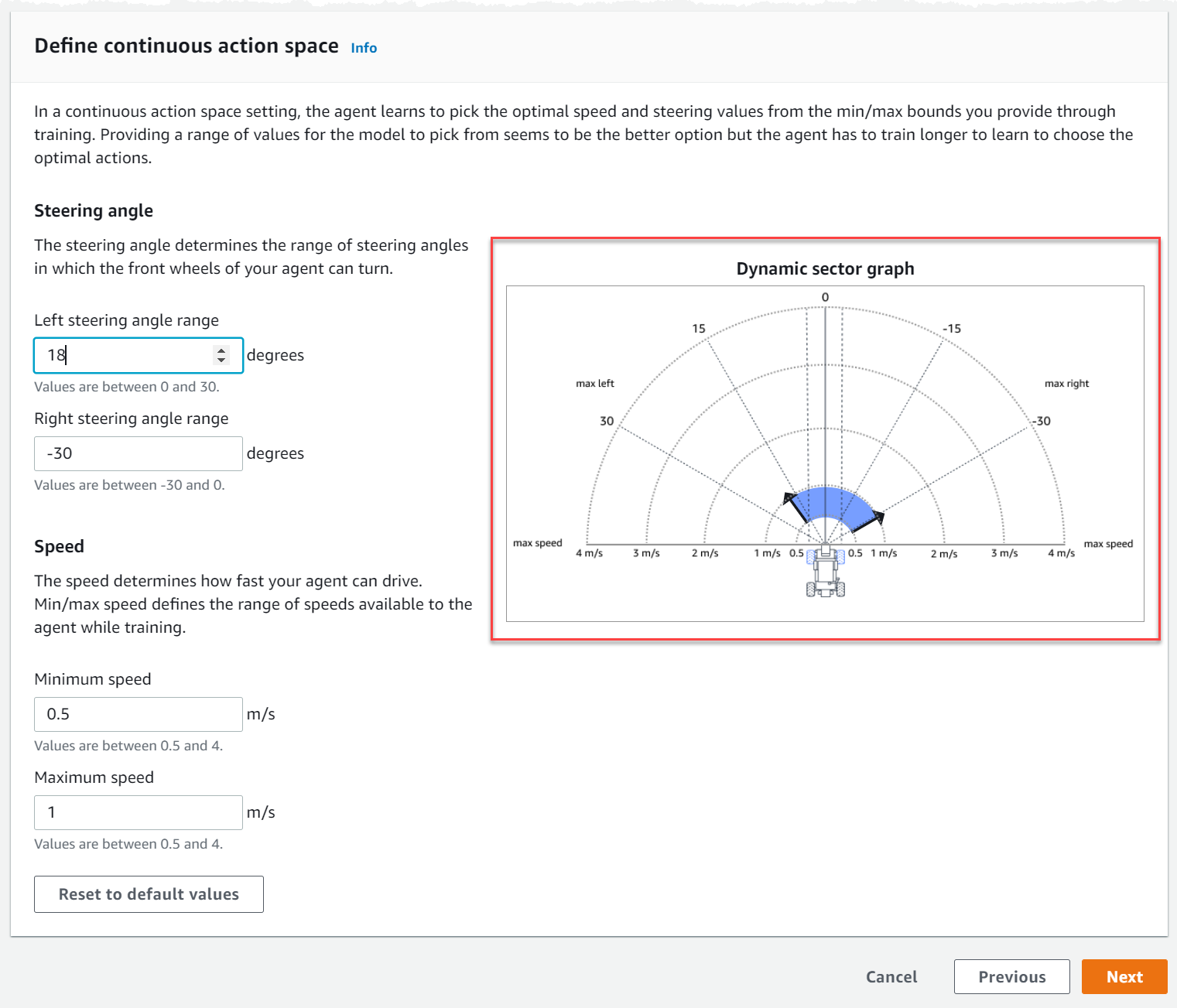
Sous Définir un espace d'action continu, choisissez les degrés de votre plage d'angle de braquage gauche et de votre plage d'angle de braquage droit.
Essayez de saisir différents degrés pour chaque plage d'angles de braquage et observez la visualisation de l'évolution de votre plage pour représenter vos choix sur le graphique sectoriel dynamique.
-
Sous Vitesse, entrez la vitesse minimale et maximale de votre agent en millimètres par seconde.
Remarquez comment vos modifications sont reflétées sur le graphique sectoriel dynamique.
-
Vous pouvez éventuellement choisir Rétablir les valeurs par défaut pour supprimer les valeurs indésirables. Nous vous encourageons à essayer différentes valeurs sur le graphique pour expérimenter et apprendre.
-
Choisissez Suivant.
-
Choisissez une valeur pour la granularité de l'angle de braquage dans la liste déroulante.
-
Choisissez une valeur en degrés comprise entre 1 et 30 pour l'angle de braquage maximal de votre agent.
-
Choisissez une valeur pour la granularité de la vitesse dans la liste déroulante.
-
Choisissez une valeur en millimètres par seconde comprise entre 0,1 et 4 pour la vitesse maximale de votre agent.
-
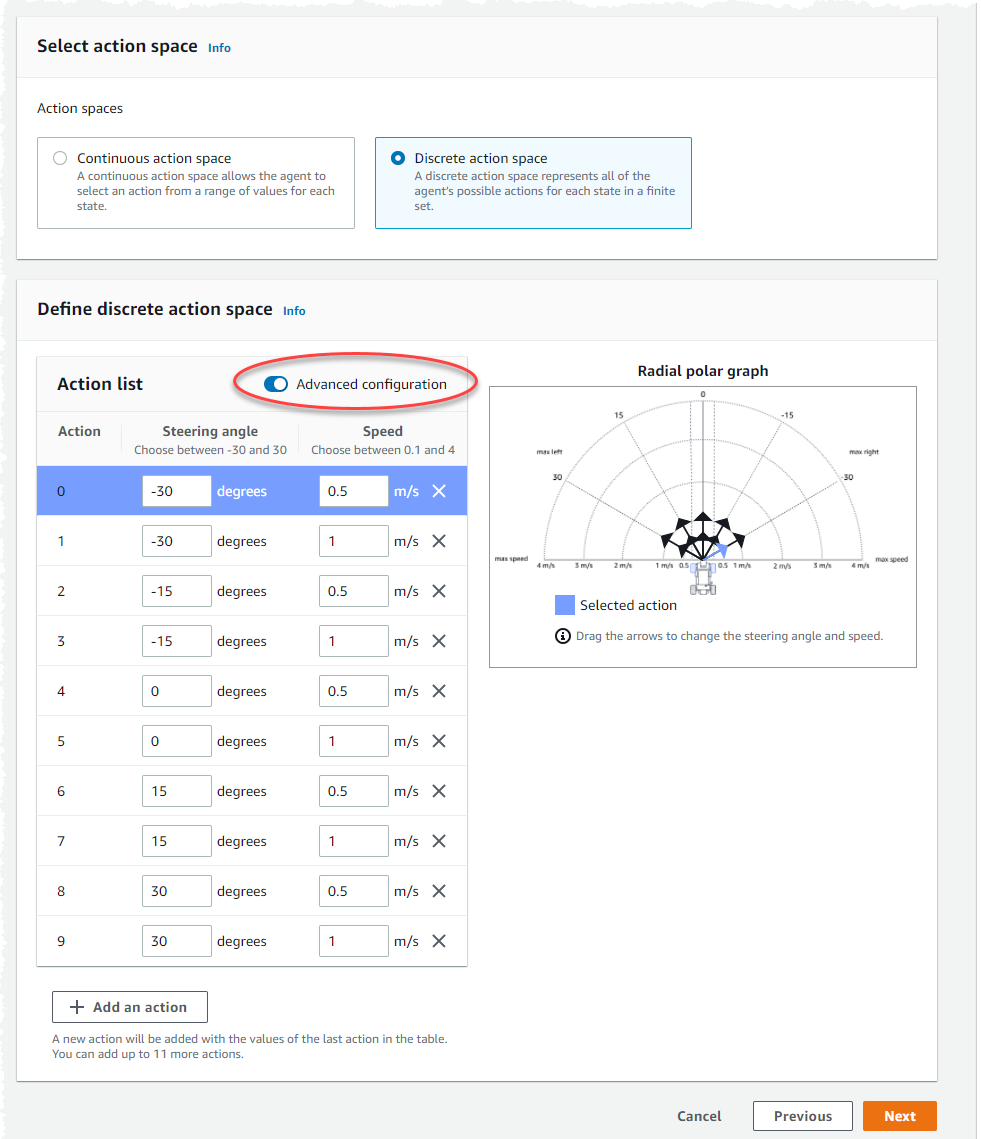
Utilisez les paramètres d'action par défaut de la liste d'actions ou, éventuellement, activez la configuration avancée pour affiner vos paramètres. Si vous choisissez Précédent ou si vous désactivez la configuration avancée après avoir ajusté les valeurs, vous perdez vos modifications.
-
Entrez une valeur en degrés comprise entre -30 et 30 dans la colonne Angle de braquage.
-
Entrez une valeur comprise entre 0,1 et 4 en millimètres par seconde pour un maximum de neuf actions dans la colonne Vitesse.
-
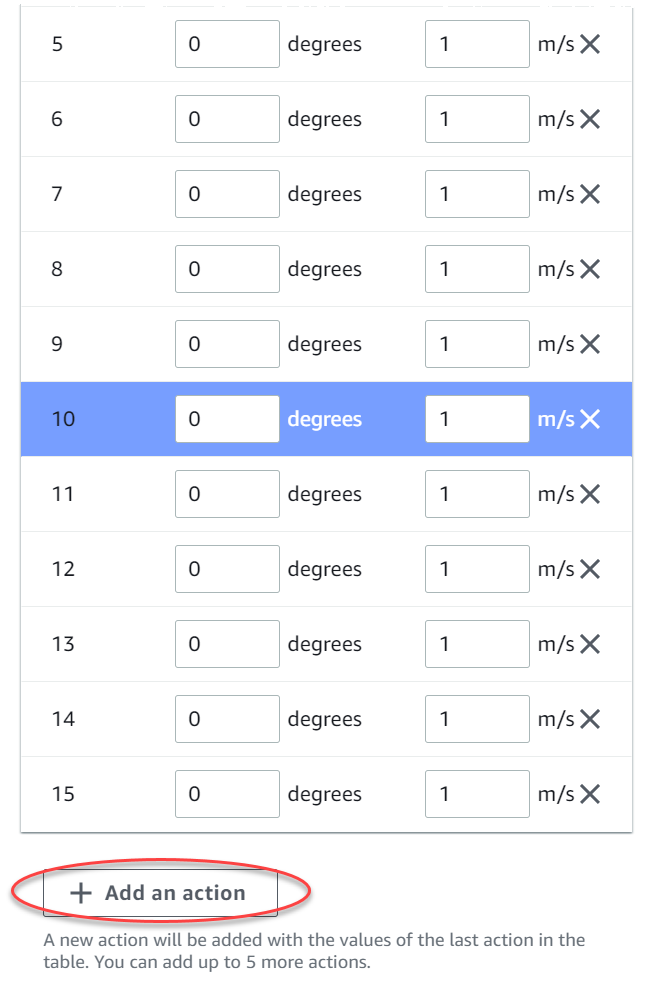
Vous pouvez éventuellement sélectionner Ajouter une action pour augmenter le nombre de lignes de la liste d'actions.
-
Vous pouvez éventuellement sélectionner X sur une ligne pour la supprimer.
-
-
Choisissez Suivant.
Choisissez une voiture virtuelle
Découvrez comment démarrer avec les voitures virtuelles. Gagnez de nouvelles voitures personnalisées, des travaux de peinture et des modifications en participant à l'Open Division chaque mois.
Pour choisir une voiture virtuelle
-
Sur la page de configuration de la coque et du capteur du véhicule, choisissez une coque compatible avec votre type de course et votre espace d'action. Si vous n'avez pas de voiture correspondant dans votre garage, rendez-vous dans Votre garage sous la rubrique Apprentissage par renforcement du volet de navigation principal pour en créer une.
Pour l'entraînement contre la montre, vous DeepRacer n'avez besoin que de la configuration par défaut du capteur et de l'appareil photo à objectif unique de The Original, mais toutes les autres configurations de coques et de capteurs fonctionnent tant que l'espace d'action correspond. Pour de plus amples informations, veuillez consulter Personnalisez la DeepRacer formation AWS pour les contre-la-montre.
Pour l'entraînement à l'évitement d'objets, les caméras stéréo sont utiles, mais une seule caméra peut également être utilisée pour éviter les obstacles stationnaires dans des endroits fixes. Un capteur LiDAR est optionnel. Consultez Espace DeepRacer d'action AWS et fonction de récompense.
Pour l'ead-to-botentraînement H, en plus d'une caméra unique ou d'une caméra stéréo, une unité LiDAR est idéale pour détecter et éviter les angles morts lorsque vous dépassez d'autres véhicules en mouvement. Pour en savoir plus, consultez Personnalisez l' DeepRacer entraînement AWS pour les head-to-bot courses.
-
Choisissez Suivant.
Personnalisez votre fonction de récompense
La fonction de récompense est au cœur de l'apprentissage par renforcement. Apprenez à l'utiliser pour inciter votre voiture (agent) à prendre des mesures spécifiques lorsqu'elle explore la piste (environnement). Tout comme encourager ou décourager certains comportements chez un animal de compagnie, vous pouvez utiliser cet outil pour encourager votre voiture à terminer un tour le plus vite possible et la dissuader de sortir de la piste ou d'entrer en collision avec des objets.
Pour personnaliser votre fonction de récompense
-
Sur la page Create model (Créer un modèle) sous Reward function (Fonction de récompense), utilisez l'exemple de fonction de récompense par défaut tel quel pour votre premier modèle.
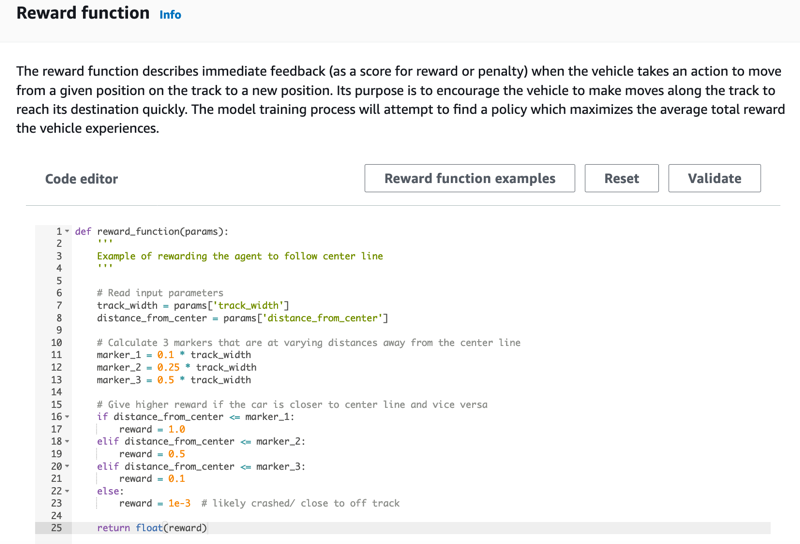
Ultérieurement, vous pourrez choisir Reward function examples (Exemples de fonction de récompense) pour sélectionner un autre exemple de fonction, puis choisir Use code (Utiliser le code) pour accepter la fonction de récompense sélectionnée.
Il existe quatre exemples de fonctions avec lesquels vous pouvez commencer. Ils montrent comment suivre le centre de la piste (par défaut), comment maintenir l'agent à l'intérieur des limites de la piste, comment empêcher la conduite en zigzag et comment éviter de percuter des obstacles immobiles ou d'autres véhicules en mouvement.
Pour en savoir plus sur la fonction de récompense, consultez Référence de la fonction de DeepRacer récompense AWS.
-
Dans Conditions d'arrêt, laissez la valeur de durée maximale par défaut telle quelle, ou définissez une nouvelle valeur pour mettre fin à la tâche de formation, afin d'éviter des tâches de formation de longue durée (et éventuellement des interruptions).
Lorsque vous expérimentez lors de la phase initiale de la formation, vous devez commencer avec une valeur faible pour ce paramètre, puis laisser progressivement une tâche de formation durer plus longtemps.
-
Dans Soumettre automatiquement à l'AWS DeepRacer, la case Soumettre DeepRacer automatiquement ce modèle à l'AWS une fois la formation terminée et avoir une chance de gagner des prix est cochée par défaut. Vous pouvez éventuellement choisir de ne pas saisir votre modèle en cochant la case.
-
Selon les exigences de la Ligue, sélectionnez votre pays de résidence et acceptez les termes et conditions en cochant la case.
-
Choisissez Create model pour commencer à créer le modèle et à provisionner l'instance de tâche de formation.
-
Après la soumission, surveillez l'initialisation de votre tâche de formation, puis exécutez-la.
Le processus d'initialisation prend quelques minutes pour passer de Initialisation à En cours.
-
Regardez le graphique de récompense et le flux vidéo Simulation pour observer l'avancement de votre tâche de formation. Vous pouvez cliquer périodiquement sur le bouton d'actualisation en regard du Reward graph (Graphe de récompense) pour actualiser le Reward graph (Graphe de récompense) jusqu'à ce que la tâche de formation soit terminée.
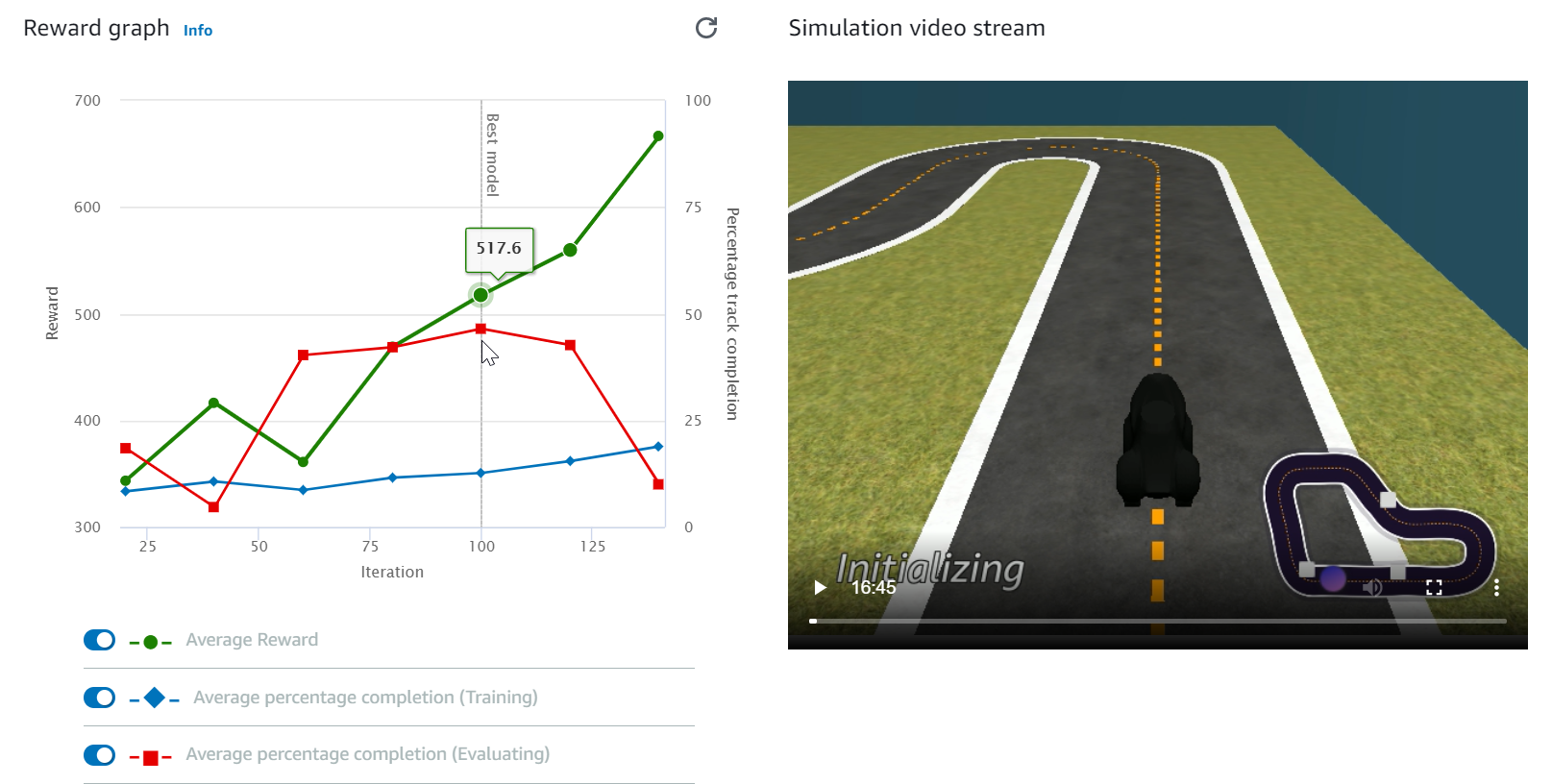
La tâche de formation s'exécute AWS dans le cloud, il n'est donc pas nécessaire de garder la DeepRacer console AWS ouverte. Vous pouvez toujours revenir sur la console pour vérifier l'état de votre modèle à tout moment pendant que le travail est en cours.
Si la fenêtre du flux vidéo de simulation ou l'affichage du graphique des récompenses ne répondent plus, actualisez la page du navigateur pour mettre à jour la progression de l'entraînement.
