Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Plan de contrôle EKS
Amazon Elastic Kubernetes Service (EKS) est un service Kubernetes géré qui vous permet d'exécuter facilement Kubernetes sur AWS sans avoir à installer, exploiter et gérer votre propre plan de contrôle Kubernetes ou vos propres nœuds de travail. Il fonctionne en amont avec Kubernetes et est certifié conforme à Kubernetes. Cette conformité garantit qu'EKS prend en charge KubernetesAPIs, tout comme la version communautaire open source que vous pouvez installer sur ou sur site. EC2 Les applications existantes exécutées sur Kubernetes en amont sont compatibles avec Amazon EKS.
EKS gère automatiquement la disponibilité et l'évolutivité des nœuds du plan de contrôle Kubernetes et remplace automatiquement les nœuds du plan de contrôle défaillants.
Architecture EKS
L'architecture EKS est conçue pour éliminer tous les points de défaillance susceptibles de compromettre la disponibilité et la durabilité du plan de contrôle Kubernetes.
Le plan de contrôle Kubernetes géré par EKS s'exécute dans un VPC géré par EKS. Le plan de contrôle EKS comprend les nœuds du serveur d'API Kubernetes, le cluster, etc. Des nœuds de serveur d'API Kubernetes qui exécutent des composants tels que le serveur d'API, le planificateur et s'exécutent kube-controller-manager dans un groupe d'auto-scaling. EKS exécute au moins deux nœuds de serveur d'API dans des zones de disponibilité distinctes (AZs) au sein de la région AWS. De même, pour des raisons de durabilité, les nœuds du serveur etcd s'exécutent également dans un groupe d'auto-scaling composé de trois nœuds. AZs EKS exécute une passerelle NAT dans chaque AZ, et les serveurs d'API et les serveurs etcd s'exécutent dans un sous-réseau privé. Cette architecture garantit qu'un événement dans une seule zone de disponibilité n'affecte pas la disponibilité du cluster EKS.
Lorsque vous créez un nouveau cluster, Amazon EKS crée un point de terminaison hautement disponible pour le serveur d'API Kubernetes géré que vous utilisez pour communiquer avec votre cluster (à l'aide d'outils tels que). kubectl Le point de terminaison géré utilise le NLB pour équilibrer la charge des serveurs d'API Kubernetes. EKS fournit également deux ENI différentes AZs pour faciliter la communication avec vos nœuds de travail.
Connectivité réseau EKS Data Plane
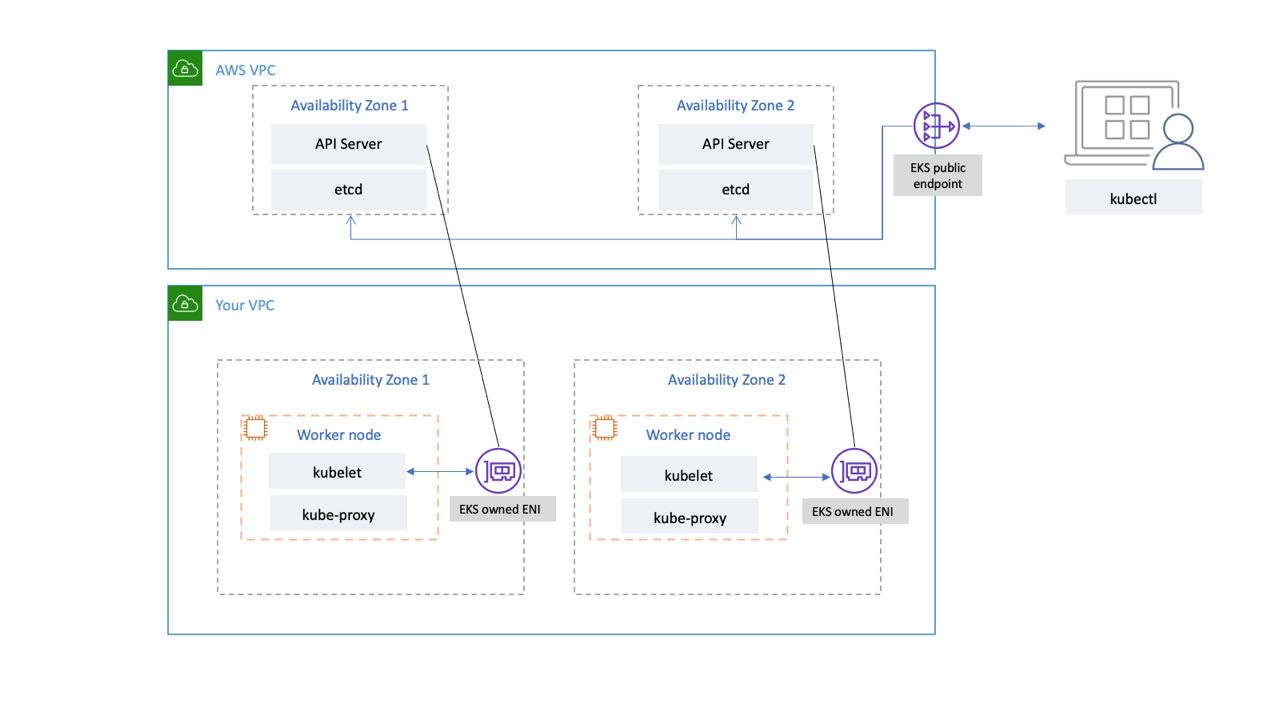
Vous pouvez configurer si le serveur d'API de votre cluster Kubernetes est accessible depuis l'Internet public (via le point de terminaison public) ou via votre VPC (en utilisant le serveur géré par EKS) ou les deux. ENIs
Que les utilisateurs et les nœuds de travail se connectent au serveur API via le point de terminaison public ou l'ENI géré par EKS, il existe des chemins de connexion redondants.
Recommandations
Passez en revue les recommandations suivantes.
Surveiller les métriques du plan de contrôle
La surveillance des métriques de l'API Kubernetes peut vous donner un aperçu des performances du plan de contrôle et identifier les problèmes. Un plan de contrôle défaillant peut compromettre la disponibilité des charges de travail exécutées au sein du cluster. Par exemple, des contrôleurs mal écrits peuvent surcharger les serveurs d'API, affectant ainsi la disponibilité de votre application.
Kubernetes expose les métriques du plan de contrôle au point de terminaison. /metrics
Vous pouvez consulter les métriques exposées à l'aide de kubectl :
kubectl get --raw /metrics
Ces statistiques sont représentées dans un format texte Prometheus
Vous pouvez utiliser Prometheus pour collecter et stocker ces statistiques. En mai 2020, CloudWatch ajout de la prise en charge de la surveillance des métriques CloudWatch de Prometheus dans Container Insights. Vous pouvez donc également utiliser Amazon CloudWatch pour surveiller le plan de contrôle EKS. Vous pouvez utiliser le didacticiel pour ajouter une nouvelle cible Prometheus Scrape : Prometheus KPI Server Metrics pour collecter des métriques CloudWatch et créer un tableau de bord pour surveiller le plan de contrôle de votre cluster.
Vous trouverez les statistiques du serveur d'API Kubernetes ici.apiserver_request_duration_seconds peut indiquer le temps d'exécution des demandes d'API.
Envisagez de surveiller les métriques du plan de contrôle suivantes :
Serveur d'API
| Métrique | Description |
|---|---|
|
|
Le compteur de requêtes apiserver est ventilé pour chaque verbe, valeur d'exécution à sec, groupe, version, ressource, étendue, composant et code de réponse HTTP. |
|
|
Histogramme de latence de réponse en secondes pour chaque verbe, valeur d'essai, groupe, version, ressource, sous-ressource, portée et composant. |
|
|
Histogramme de latence du contrôleur d'admission en secondes, identifié par son nom et ventilé pour chaque opération, ressource d'API et type (validation ou admission). |
|
|
Nombre de refus de webbooks d'admission. Identifié par nom, opération, code de rejet, type (validation ou admission), type d'erreur (calling_webhook_error, apiserver_internal_error, no_error) |
|
|
Histogramme de latence des demandes en secondes. Décomposé par verbe et par URL. |
|
|
Nombre de requêtes HTTP, partitionnées par code d'état, méthode et hôte. |
-
Les métriques de l'histogramme incluent les suffixes _bucket, _sum et _count.
etcd
| Métrique | Description |
|---|---|
|
|
Histogramme de latence des demandes Etcd en secondes pour chaque opération et type d'objet. |
|
|
Taille de la base de données Etcd. |
-
Les métriques de l'histogramme incluent les suffixes _bucket, _sum et _count.
Envisagez d'utiliser le tableau de bord de vue d'ensemble de la surveillance de Kubernetes
Important
Lorsque la limite de taille de base de données est dépassée, etcd émet une alarme d'absence d'espace et arrête de prendre d'autres demandes d'écriture. En d'autres termes, le cluster passe en lecture seule et toutes les demandes de mutation d'objets, telles que la création de nouveaux pods, le dimensionnement des déploiements, etc., seront rejetées par le serveur API du cluster.
Authentification par cluster
EKS prend actuellement en charge deux types d'authentification : les jetons de compte porteur/de service
L'utilisateur ou le rôle IAM qui crée le cluster EKS obtient automatiquement un accès complet au cluster. Vous pouvez gérer l'accès au cluster EKS en modifiant le fichier de configuration aws-auth.
Si vous configurez mal le aws-auth configmap et perdez l'accès au cluster, vous pouvez toujours utiliser l'utilisateur ou le rôle du créateur du cluster pour accéder à votre cluster EKS.
Dans le cas peu probable où vous ne pourriez pas utiliser le service IAM dans la région AWS, vous pouvez également utiliser le jeton porteur du compte de service Kubernetes pour gérer le cluster.
Créez un super-admin compte autorisé à effectuer toutes les actions du cluster :
kubectl -n kube-system create serviceaccount super-admin
Créez une liaison de rôle qui donne le rôle super-admin cluster-admin :
kubectl create clusterrolebinding super-admin-rb --clusterrole=cluster-admin --serviceaccount=kube-system:super-admin
Obtenez le secret du compte de service :
SECRET_NAME=`kubectl -n kube-system get serviceaccount/super-admin -o jsonpath='{.secrets[0].name}'`
Obtenez le jeton associé au secret :
TOKEN=`kubectl -n kube-system get secret $SECRET_NAME -o jsonpath='{.data.token}'| base64 --decode`
Ajoutez un compte de service et un jeton à kubeconfig :
kubectl config set-credentials super-admin --token=$TOKEN
Définissez le contexte actuel kubeconfig pour utiliser le compte super-administrateur :
kubectl config set-context --current --user=super-admin
La finale kubeconfig devrait ressembler à ceci :
apiVersion: v1 clusters: - cluster: certificate-authority-data:<REDACTED> server: https://<CLUSTER>.gr7.us-west-2.eks.amazonaws.com name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> contexts: - context: cluster: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> user: super-admin name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> current-context: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> kind: Config preferences: {} users: #- name: arn:aws:eks:us-west-2:<account number>:cluster/<cluster name> # user: # exec: # apiVersion: client.authentication.k8s.io/v1beta1 # args: # - --region # - us-west-2 # - eks # - get-token # - --cluster-name # - <<cluster name>> # command: aws # env: null - name: super-admin user: token: <<super-admin sa's secret>>
Webhooks d'admission
Kubernetes propose deux types de webhooks d'admission : les webhooks d'admission validants et les webhooks d'admission mutants
Pour éviter d'avoir un impact sur les opérations critiques du cluster, évitez de définir des webhooks « fourre-tout » comme suit :
- name: "pod-policy.example.com" rules: - apiGroups: ["*"] apiVersions: ["*"] operations: ["*"] resources: ["*"] scope: "*"
Ou assurez-vous que le webhook dispose d'une politique d'ouverture en cas d'échec avec un délai d'expiration inférieur à 30 secondes afin de garantir que si votre webhook n'est pas disponible, cela n'affectera pas les charges de travail critiques du cluster.
Bloquez les pods en cas de danger sysctls
Sysctlest un utilitaire Linux qui permet aux utilisateurs de modifier les paramètres du noyau pendant l'exécution. Ces paramètres du noyau contrôlent différents aspects du comportement du système d'exploitation, tels que le réseau, le système de fichiers, la mémoire virtuelle et la gestion des processus.
Kubernetes permet d'attribuer sysctl des profils aux pods. Kubernetes est classé systcls comme sûr et dangereux. Les espaces de noms sécurisés sysctls sont placés dans le conteneur ou le pod, et leur configuration n'a aucun impact sur les autres pods du nœud ou sur le nœud lui-même. En revanche, les sysctls non sécurisés sont désactivés par défaut car ils peuvent potentiellement perturber les autres pods ou rendre le nœud instable.
Comme sysctls les éléments non sécurisés sont désactivés par défaut, le kubelet ne créera pas de Pod avec un profil dangereuxsysctl. Si vous créez un tel pod, le planificateur attribuera à plusieurs reprises de tels pods aux nœuds, alors que le nœud ne le lance pas. Cette boucle infinie finit par mettre à rude épreuve le plan de contrôle du cluster, le rendant instable.
Envisagez d'utiliser OPA Gatekeepersysctls
Gestion des mises à niveau de clusters
Depuis avril 2021, le cycle de publication de Kubernetes est passé de quatre versions par an (une fois par trimestre) à trois versions par an. Une nouvelle version mineure (comme 1. 21 ou 1. 22) est publié environ toutes les quinze semaines
Connectivité des terminaux du cluster
Lorsque vous travaillez avec Amazon EKS (Elastic Kubernetes Service), vous pouvez rencontrer des interruptions de connexion ou des erreurs lors d'événements tels que le dimensionnement ou l'application de correctifs au plan de contrôle Kubernetes. Ces événements peuvent entraîner le remplacement des instances de kube-apiserver, ce qui peut entraîner le renvoi d'adresses IP différentes lors de la résolution du FQDN. Ce document décrit les meilleures pratiques permettant aux utilisateurs d'API Kubernetes de maintenir une connectivité fiable.
Note
La mise en œuvre de ces meilleures pratiques peut nécessiter des mises à jour des configurations client ou des scripts afin de gérer efficacement les nouvelles stratégies de résolution DNS et de réessayer.
Le principal problème provient de la mise en cache côté client du DNS et du risque d'adresses IP périmées du point de terminaison EKS (NLB public pour point de terminaison public ou X-ENI pour point de terminaison privé). Lorsque les instances de kube-apiserver sont remplacées, le nom de domaine complet (FQDN) peut être converti en de nouvelles adresses IP. Cependant, en raison des paramètres TTL (DNS Time to Live), qui sont définis sur 60 secondes dans la zone Route 53 gérée par AWS, les clients peuvent continuer à utiliser des adresses IP obsolètes pendant une courte période.
Pour atténuer ces problèmes, les utilisateurs d'API Kubernetes (tels que kubectl, les CI/CD pipelines et les applications personnalisées) doivent mettre en œuvre les meilleures pratiques suivantes :
-
Implémenter la rerésolution du DNS
-
Implémentez les nouvelles tentatives avec Backoff et Jitter. Par exemple, consultez cet article intitulé Failures Happen
-
Implémentez les délais d'attente des clients. Définissez des délais d'expiration appropriés pour éviter que les demandes de longue durée ne bloquent votre application. Sachez que certaines bibliothèques clientes Kubernetes, en particulier celles générées par les générateurs OpenAPI, peuvent ne pas permettre de définir facilement des délais d'expiration personnalisés.
-
Exemple 1 avec kubectl :
kubectl get pods --request-timeout 10s # default: no timeout
-
Exemple 2 avec Python : le client Kubernetes fournit
un paramètre _request_timeout
-
En mettant en œuvre ces meilleures pratiques, vous pouvez améliorer de manière significative la fiabilité et la résilience de vos applications lorsque vous interagissez avec l'API Kubernetes. N'oubliez pas de tester ces implémentations de manière approfondie, en particulier dans des conditions de défaillance simulées, afin de vous assurer qu'elles se comportent comme prévu lors des événements de dimensionnement ou d'application de correctifs.
Gestion de grands clusters
EKS surveille activement la charge sur les instances du plan de contrôle et les adapte automatiquement pour garantir des performances élevées. Toutefois, vous devez tenir compte des problèmes et des limites de performances potentiels au sein de Kubernetes ainsi que des quotas dans les services AWS lorsque vous exécutez de grands clusters.
-
Les clusters comportant plus de 1 000 services peuvent subir une latence réseau lors de l'utilisation
kube-proxyeniptablesmode in, selon les tests effectués par l' ProjectCalico équipe. La solution consiste à passer kube-proxyen ipvs mode exécution. -
Vous pouvez également être confronté à une limitation des demandes d'EC2API si le CNI doit demander des adresses IP pour les pods ou si vous devez créer fréquemment de nouvelles EC2 instances. Vous pouvez réduire EC2 l'API des appels en configurant le CNI pour mettre en cache les adresses IP. Vous pouvez utiliser des types d' EC2 instances plus grands pour réduire les événements de EC2 dimensionnement.
Ressources supplémentaires :
