Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Optimisation des coûts - Mise en réseau
L'architecture des systèmes pour une haute disponibilité (HA) est une bonne pratique pour garantir la résilience et la tolérance aux pannes. Dans la pratique, cela signifie répartir vos charges de travail et l'infrastructure sous-jacente sur plusieurs zones de disponibilité (AZs) dans une région AWS donnée. La mise en place de ces caractéristiques pour votre environnement Amazon EKS améliorera la fiabilité globale de votre système. Parallèlement à cela, vos environnements EKS seront probablement également composés d'une variété de constructions (c'est-à-dire VPCs), de composants (c'est-à-dire) et d'intégrations (par exemple, ECR et autres registres de conteneurs ELBs).
La combinaison de systèmes à haute disponibilité et d'autres composants spécifiques à des cas d'utilisation peut jouer un rôle important dans la manière dont les données sont transférées et traitées. Cela aura à son tour un impact sur les coûts liés au transfert et au traitement des données.
Les pratiques détaillées ci-dessous vous aideront à concevoir et à optimiser vos environnements EKS afin d'atteindre un meilleur rapport coût-efficacité pour différents domaines et cas d'utilisation.
Communication d'un pod à un autre
En fonction de votre configuration, la communication réseau et le transfert de données entre les pods peuvent avoir un impact significatif sur le coût global d'exécution des charges de travail Amazon EKS. Cette section abordera différents concepts et approches visant à atténuer les coûts liés à la communication entre les pods, tout en tenant compte des architectures à haute disponibilité (HA), des performances des applications et de la résilience.
Limiter le trafic à une zone de disponibilité
Le projet Kubernetes a commencé très tôt à développer des constructions sensibles à la topologie, notamment des étiquettes telles que kubernetes. io/hostname, topology.kubernetes.io/region, and topology.kubernetes.io/zoneattribué aux nœuds pour activer des fonctionnalités telles que la répartition de la charge de travail entre les domaines de défaillance et les approvisionneurs de volumes sensibles à la topologie. Après avoir obtenu leur diplôme dans Kubernetes 1.17, les étiquettes ont également été utilisées pour permettre des fonctionnalités de routage adaptées à la topologie pour la communication entre pods.
Vous trouverez ci-dessous quelques stratégies permettant de contrôler le volume de trafic cross-AZ entre les pods de votre cluster EKS afin de réduire les coûts et de minimiser la latence.
Si vous souhaitez obtenir une visibilité précise de la quantité de trafic cross-AZ entre les pods de votre cluster (par exemple, la quantité de données transférées en octets), consultez cet article
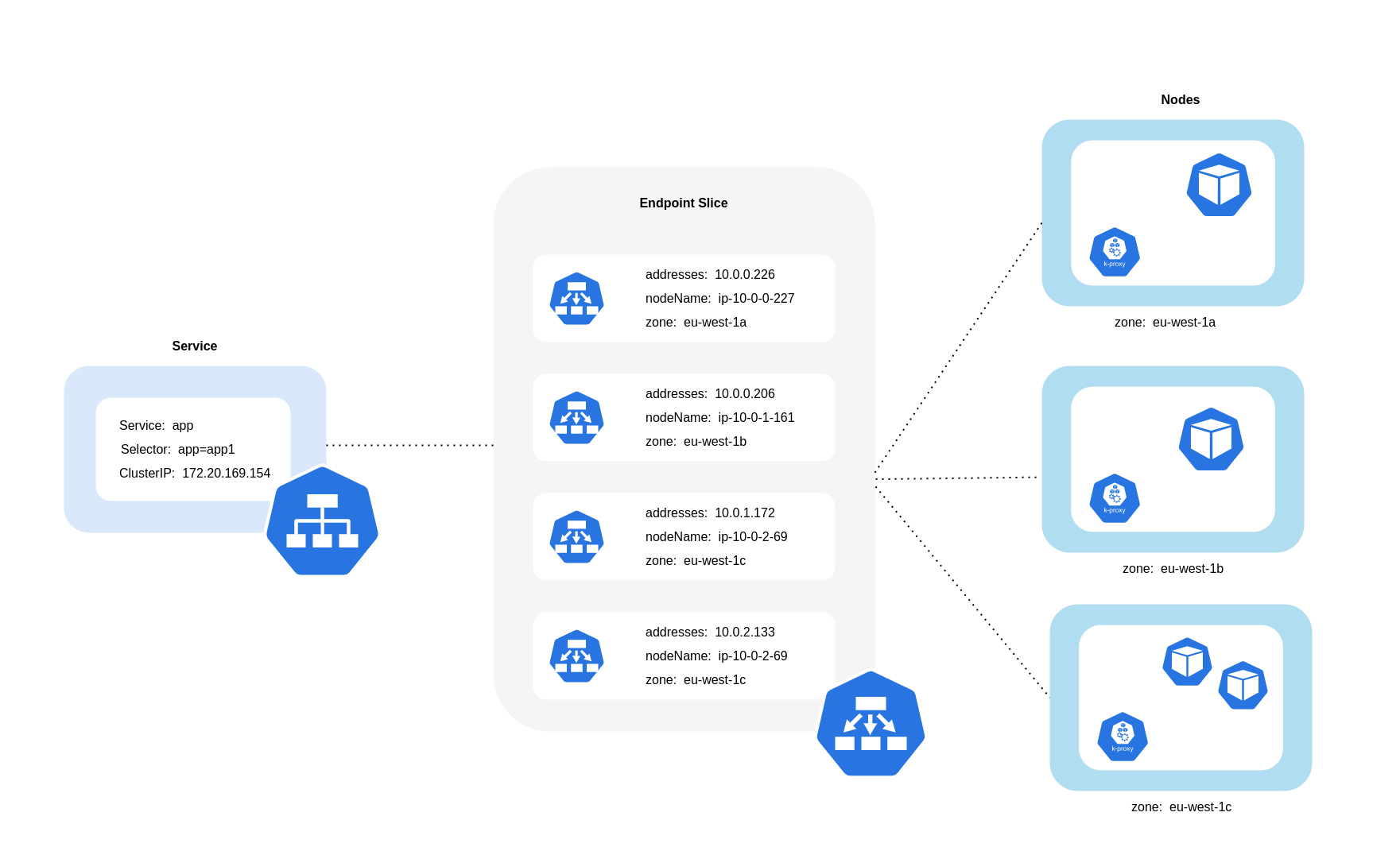
Comme le montre le schéma ci-dessus, les services sont la couche d'abstraction réseau stable qui reçoit le trafic destiné à vos pods. Lorsqu'un service est créé, plusieurs EndpointSlices sont créés. Chacun EndpointSlice possède une liste de points de terminaison contenant un sous-ensemble d'adresses Pod ainsi que les nœuds sur lesquels ils s'exécutent et toute information topologique supplémentaire. Lors de l'utilisation de l'Amazon VPC CNI, kube-proxy, un daemonset exécuté sur chaque nœud, maintient les règles réseau pour permettre la communication avec le pod et la découverte de services (une alternative basée sur eBPF CNIs peut ne pas utiliser kube-proxy mais fournir un comportement équivalent). Il joue le rôle de routage interne, mais il le fait en fonction de ce qu'il consomme du produit créé EndpointSlices.
Sur EKS, kube-proxy utilise principalement les règles NAT iptables (ou IPVS, NFTables
Utilisation du routage adapté à la topologie (anciennement connu sous le nom de topologie sensible à la topologie)
Lorsque le routage tenant compte de la topologiekube-proxyacheminera ensuite le trafic d'une zone vers un point de terminaison en fonction des indications appliquées.
Le schéma ci-dessous montre comment EndpointSlices les indices sont organisés de manière à savoir vers quelle destination ils doivent se rendre en fonction de leur point d'origine zonal. kube-proxy Sans indications, il n'existe pas d'allocation ou d'organisation de ce type et le trafic sera acheminé par proxy vers différentes destinations zonales, quelle que soit sa provenance.
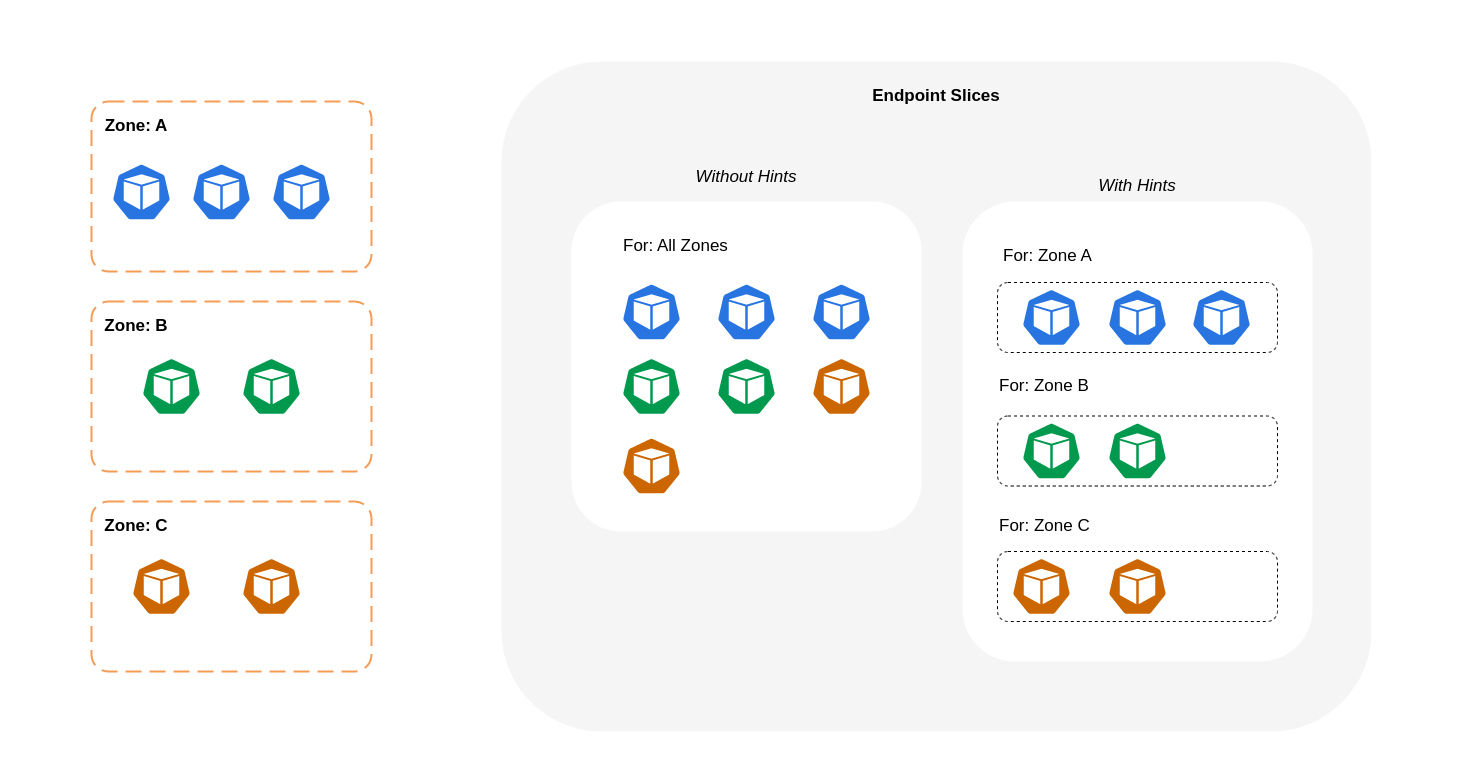
Dans certains cas, le EndpointSlice contrôleur peut appliquer un indice pour une zone différente, ce qui signifie que le point de terminaison peut finir par desservir le trafic provenant d'une autre zone. La raison en est d'essayer de maintenir une répartition uniforme du trafic entre les points de terminaison situés dans différentes zones.
Vous trouverez ci-dessous un extrait de code expliquant comment activer le routage adapté à la topologie pour un service.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
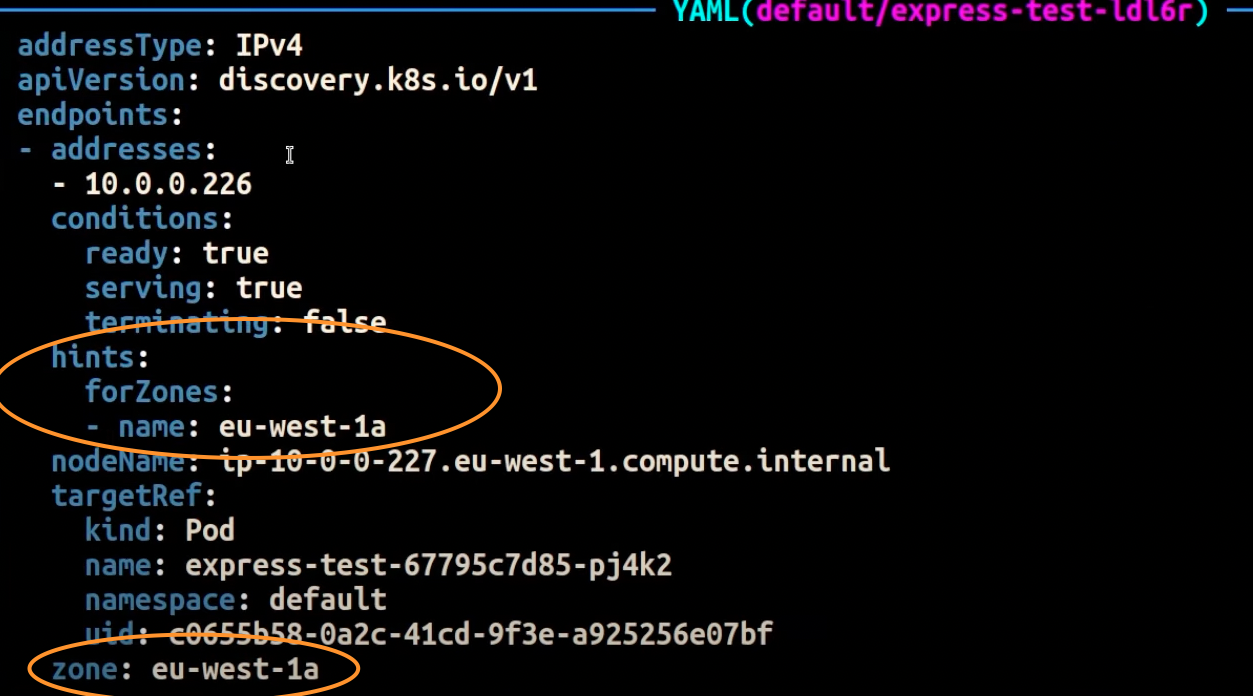
La capture d'écran ci-dessous montre le résultat obtenu lorsque le EndpointSlice contrôleur a correctement appliqué un indice à un point de terminaison pour une réplique de Pod exécutée dans l'Arizonaeu-west-1a.
Note
Il est important de noter que le routage tenant compte de la topologie est toujours en version bêta. Cette fonctionnalité fonctionne de manière plus prévisible avec des charges de travail réparties uniformément dans la topologie du cluster, car le contrôleur alloue les points de terminaison de manière proportionnelle entre les zones, mais peut ignorer les assignations d'indices lorsque les ressources des nœuds d'une zone sont trop déséquilibrées pour éviter une surcharge excessive. Par conséquent, il est fortement recommandé de l'utiliser en conjonction avec des contraintes de planification qui augmentent la disponibilité d'une application, telles que les contraintes de propagation de la topologie des pods
Utilisation de la distribution du trafic
Introduite dans Kubernetes 1.30 et rendue généralement disponible dans la version 1.33, la distribution du trafic
Vous trouverez ci-dessous un extrait de code expliquant comment activer la distribution du trafic pour un service.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
Lors de l'activation de la distribution du trafic, un défi courant se pose : les points de terminaison d'une même zone de zone peuvent être surchargés si la majeure partie du trafic provient de cette même zone. Cette surcharge peut créer des problèmes importants :
-
Un seul HPA (Horizontal Pod Autoscaler) gérant un déploiement multi-AZ peut réagir en répartissant les pods entre différents. AZs Cependant, cette action ne permet pas de remédier efficacement à l'augmentation de la charge dans la zone affectée.
-
Cette situation peut à son tour entraîner une inefficacité des ressources. Lorsque des autoscalers de clusters tels que Karpenter détectent le scale-out entre différents modules AZs, ils peuvent approvisionner des nœuds supplémentaires dans les nœuds non affectés AZs, ce qui entraîne une allocation de ressources inutile.
Pour relever ce défi :
-
Créez des déploiements distincts par zone, qui auraient leur propre capacité HPAs à évoluer indépendamment les uns des autres.
-
Tirez parti des contraintes de répartition topologique pour garantir la répartition de la charge de travail au sein du cluster, ce qui permet d'éviter la surcharge des terminaux dans les zones à fort trafic.
Utilisation d'autoscalers : provisionner des nœuds vers une zone de disponibilité spécifique
Nous vous recommandons vivement d'exécuter vos charges de travail dans des environnements à haute disponibilité répartis sur plusieurs AZs environnements. Cela améliore la fiabilité de vos applications, en particulier en cas d'incident lié à un problème avec un AZ. Si vous êtes prêt à sacrifier la fiabilité pour réduire les coûts liés au réseau, vous pouvez limiter vos nœuds à une seule AZ.
Pour exécuter tous vos pods dans la même zone de zone, configurez les nœuds de travail dans la même zone ou planifiez les pods sur les nœuds de travail exécutés sur la même zone de zone. Pour approvisionner des nœuds au sein d'une seule AZ, définissez un groupe de nœuds avec des sous-réseaux appartenant à la même AZ avec Cluster Autoscaler (CA)topology.kubernetes.io/zone et spécifiez l'AZ dans laquelle vous souhaitez créer les nœuds de travail. Par exemple, l'extrait de code Karpenter Provisioner ci-dessous approvisionne les nœuds de l'AZ us-west-2a.
Charpentier
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
Cluster Autoscaler (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
Utilisation de l'attribution des pods et de l'affinité des nœuds
Sinon, si vous avez plusieurs nœuds de travail exécutés en plusieurs AZs, chaque nœud portera l'étiquette topology.kubernetes.io/zonenodeSelector ou nodeAffinity planifier des pods pour les nœuds dans une seule zone de disponibilité. Par exemple, le fichier manifeste suivant planifiera le Pod dans un nœud exécuté dans AZ us-west-2a.
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
Restreindre le trafic vers un nœud
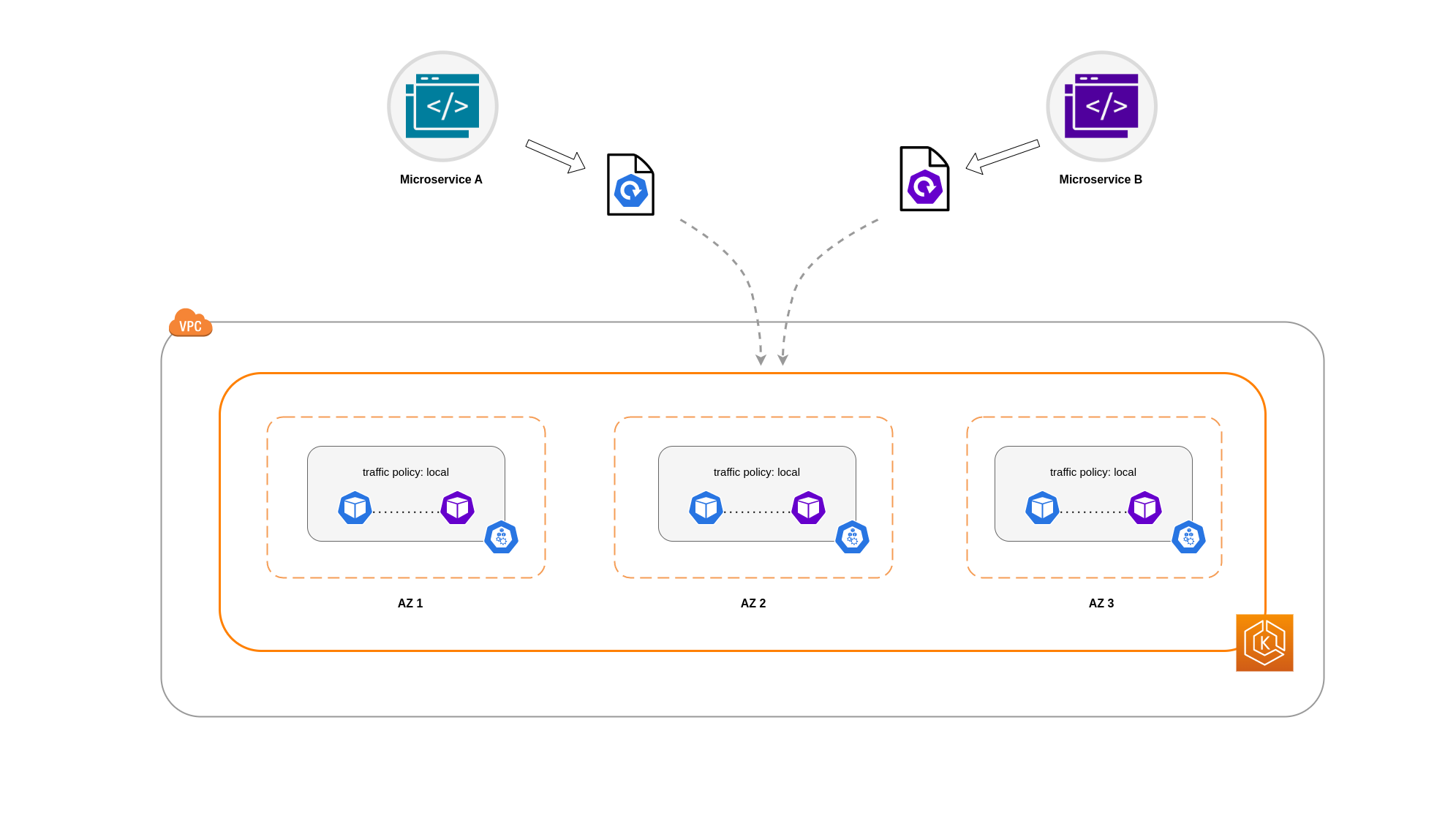
Dans certains cas, il ne suffit pas de restreindre le trafic au niveau d'une zone. Outre la réduction des coûts, vous devrez peut-être également réduire la latence du réseau entre certaines applications qui communiquent fréquemment entre elles. Afin d'optimiser les performances du réseau et de réduire les coûts, vous devez trouver un moyen de limiter le trafic vers un nœud spécifique. Par exemple, le microservice A doit toujours communiquer avec le microservice B sur le nœud 1, même dans les configurations à haute disponibilité (HA). Le fait que le microservice A sur le nœud 1 communique avec le microservice B sur le nœud 2 peut avoir un impact négatif sur les performances souhaitées pour les applications de cette nature, en particulier si le nœud 2 se trouve dans une zone de disponibilité complètement distincte.
Utilisation de la politique de trafic interne du service
Afin de limiter le trafic réseau du Pod à un nœud, vous pouvez utiliser la politique de trafic interne du serviceLocal, le trafic sera limité aux points de terminaison situés sur le nœud d'où provient le trafic. Cette politique impose l'utilisation exclusive de points de terminaison locaux aux nœuds. Par conséquent, les coûts liés au trafic réseau pour cette charge de travail seront inférieurs à ceux d'une distribution à l'échelle du cluster. De plus, la latence sera plus faible, ce qui rendra votre application plus performante.
Note
Il est important de noter que cette fonctionnalité ne peut pas être combinée avec le routage tenant compte de la topologie dans Kubernetes.
Vous trouverez ci-dessous un extrait de code expliquant comment définir la politique de trafic interne pour un service.
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
Pour éviter que votre application ne se comporte de manière inattendue en raison d'une baisse de trafic, vous devez envisager les approches suivantes :
-
Exécutez suffisamment de répliques pour chacun des pods communicants
-
Disposez d'une répartition relativement uniforme des pods en utilisant les contraintes de propagation topologique
-
Utiliser les règles d'affinité des pods
pour la colocalisation des pods communicants
Dans cet exemple, vous avez 2 répliques du microservice A et 3 répliques du microservice B. Si les répliques du microservice A sont réparties entre les nœuds 1 et 2 et que le microservice B possède ses 3 répliques sur le nœud 3, il ne sera pas en mesure de communiquer en raison de la politique de trafic interne. Local Lorsqu'aucun point de terminaison local n'est disponible, le trafic est supprimé.
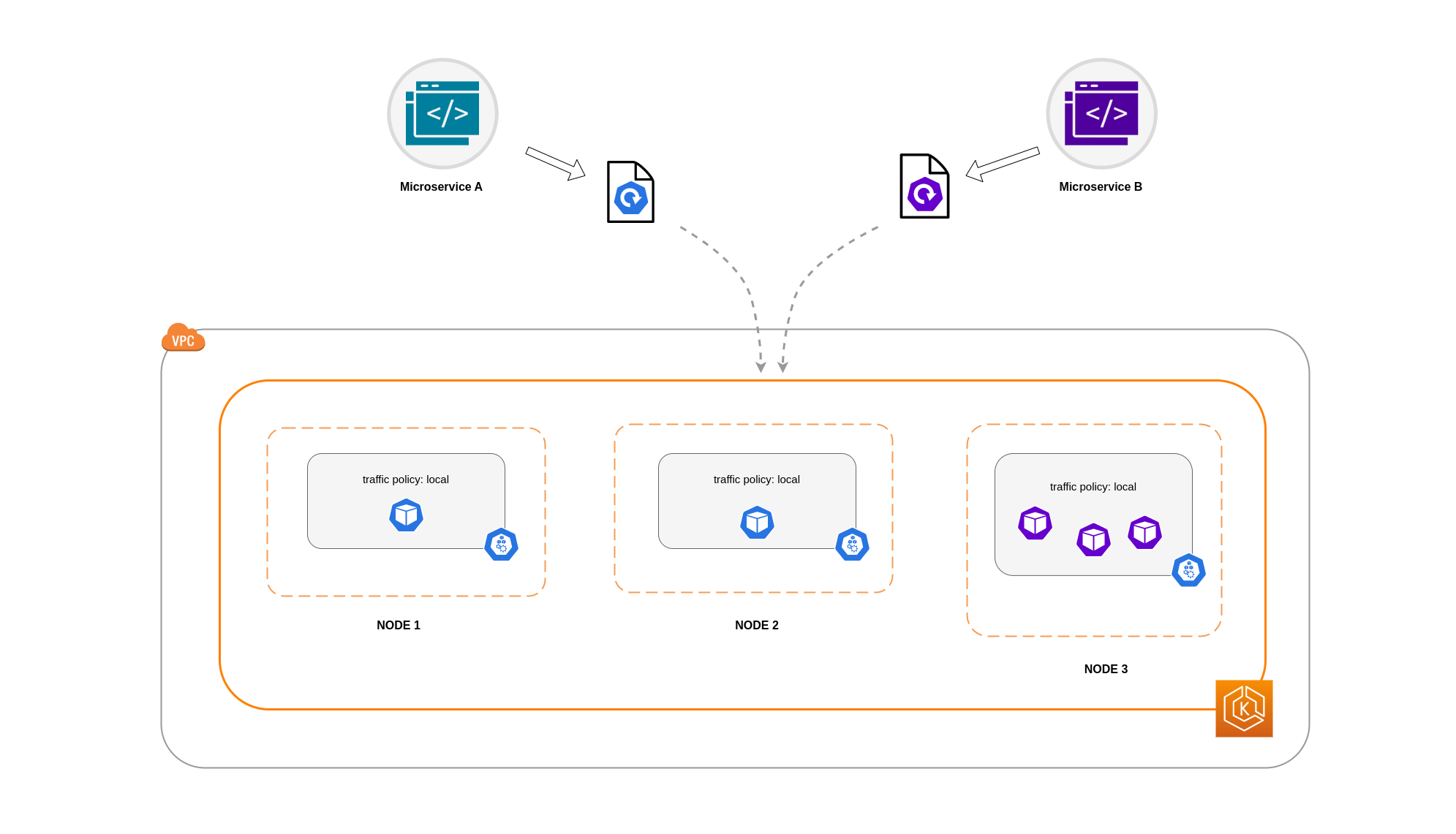
Si le microservice B possède 2 de ses 3 répliques sur les nœuds 1 et 2, il y aura une communication entre les applications homologues. Mais vous auriez toujours une réplique isolée de Microservice B sans aucune réplique homologue avec laquelle communiquer.
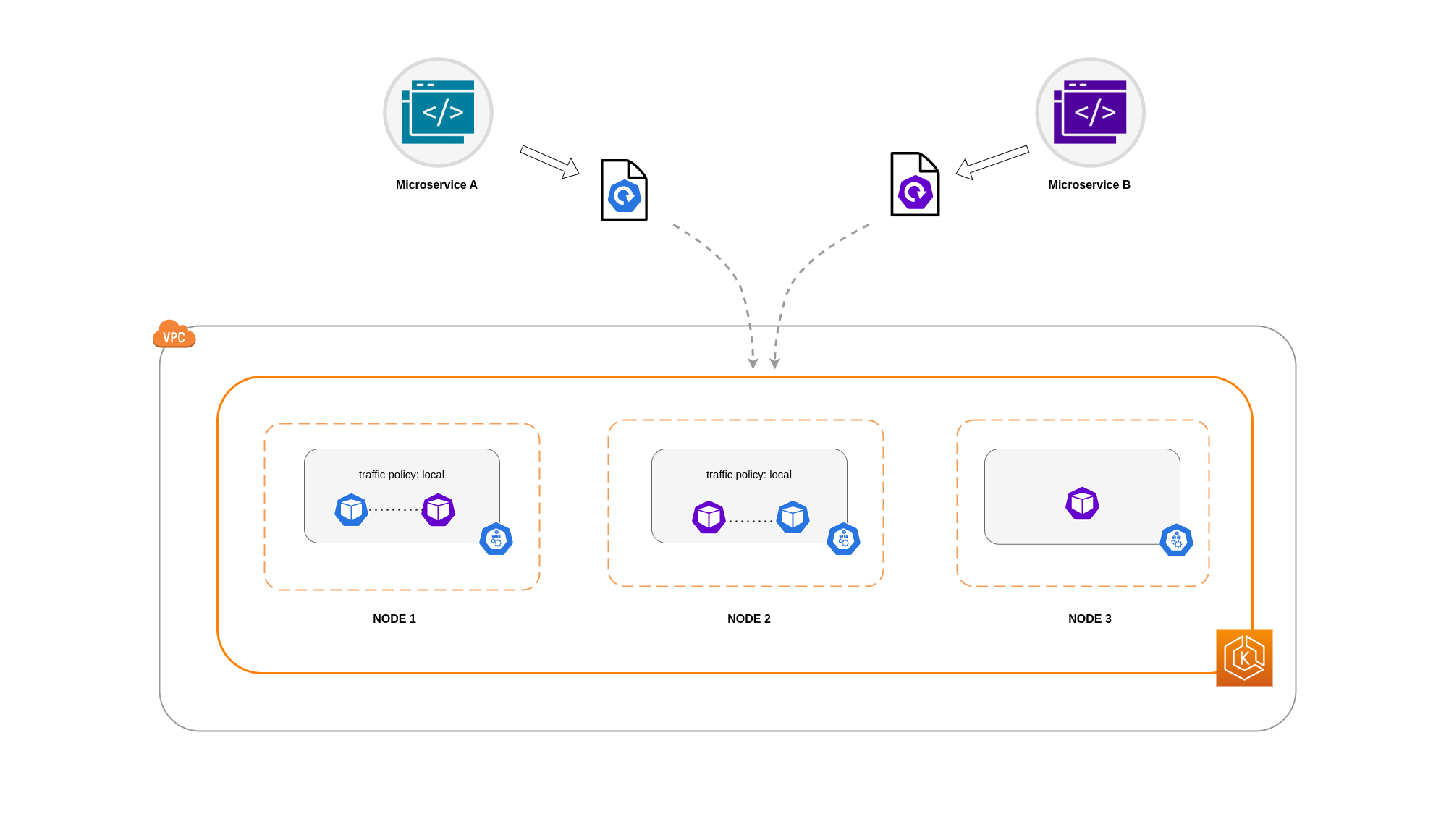
Note
Dans certains scénarios, une réplique isolée telle que celle illustrée dans le schéma ci-dessus peut ne pas être préoccupante si elle répond toujours à un objectif (par exemple, répondre aux demandes provenant du trafic entrant externe).
Utilisation de la politique de trafic interne du service avec des contraintes de dispersion topologique
L'utilisation de la politique de trafic interne associée aux contraintes de dispersion topologique peut être utile pour garantir que vous disposez du nombre approprié de répliques pour communiquer des microservices sur différents nœuds.
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
Utilisation de la politique de trafic interne du service avec les règles d'affinité des pods
Une autre approche consiste à utiliser les règles d'affinité des pods lors de l'utilisation de la politique de trafic interne du service. Grâce à l'affinité des pods, vous pouvez influencer le planificateur pour qu'il colocalise certains pods en raison de leurs communications fréquentes. En appliquant des contraintes de planification strictes (requiredDuringSchedulingIgnoredDuringExecution) à certains pods, vous obtiendrez de meilleurs résultats en matière de colocation de pods lorsque le planificateur place des pods sur des nœuds.
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Communication entre le Load Balancer et le Pod
Les charges de travail EKS sont généralement dirigées par un équilibreur de charge qui distribue le trafic aux pods concernés de votre cluster EKS. Votre architecture peut comprendre des équilibreurs de charge internes orientés vers l' and/or extérieur. En fonction de votre architecture et de la configuration du trafic réseau, la communication entre les équilibreurs de charge et les pods peut contribuer de manière significative aux frais de transfert de données.
Vous pouvez utiliser le AWS Load Balancer Controller
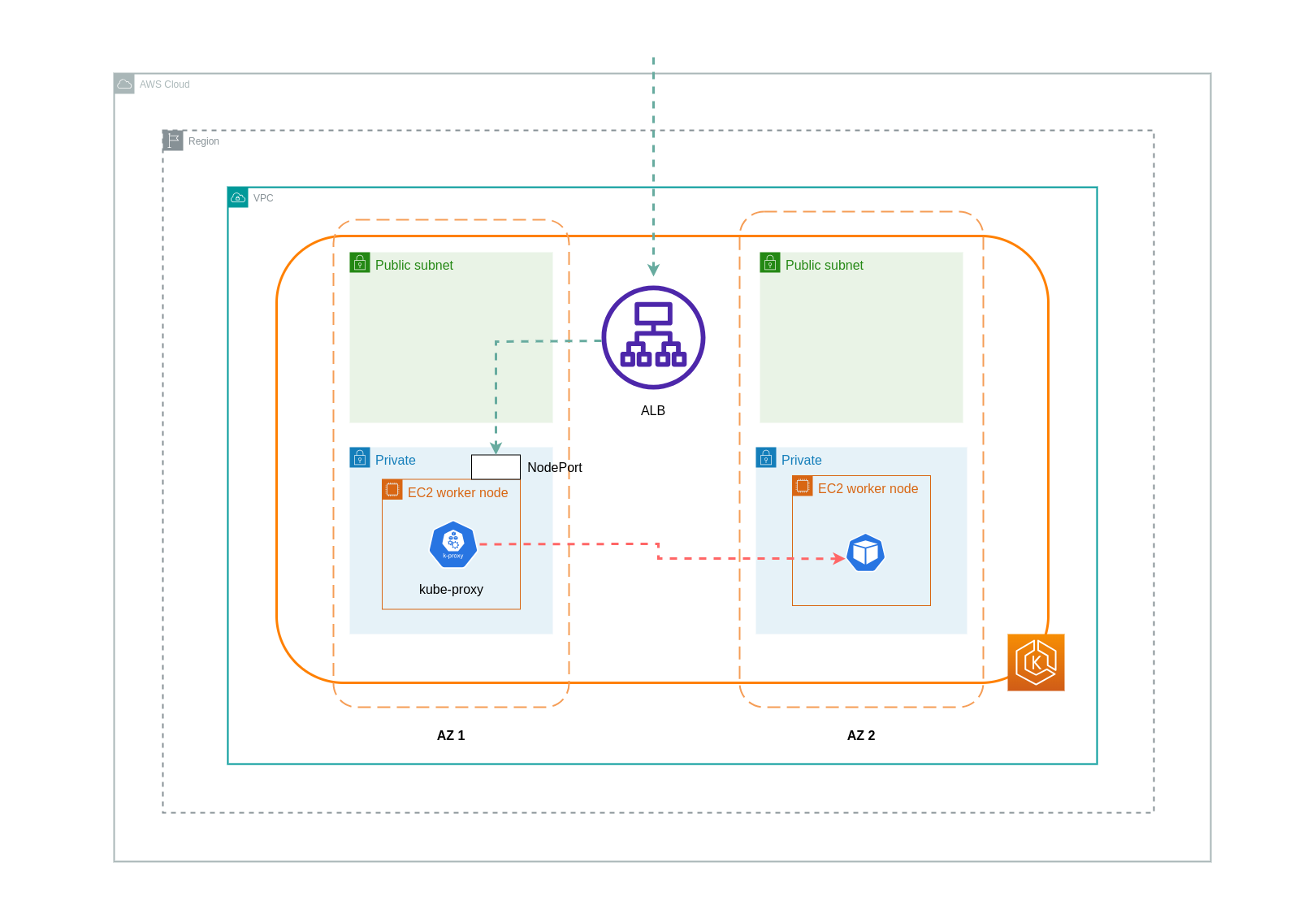
Lorsque vous utilisez le mode instance, un nœud NodePort sera ouvert sur chaque nœud de votre cluster EKS. L'équilibreur de charge transfère ensuite le trafic de manière uniforme sur les nœuds. Si le Pod de destination est exécuté sur un nœud, aucun frais de transfert de données ne sera encouru. Toutefois, si le pod de destination se trouve sur un nœud distinct et dans une zone de zone différente de celle NodePort où le trafic est reçu, il y aura un saut réseau supplémentaire entre le kube-proxy et le pod de destination. Dans un tel scénario, des frais de transfert de données inter-AZ seront facturés. En raison de la répartition uniforme du trafic entre les nœuds, il est fort probable que des frais de transfert de données supplémentaires soient associés aux sauts de trafic réseau entre zones des kube-proxies vers les pods de destination concernés.
Le schéma ci-dessous représente un chemin réseau pour le trafic circulant de l'équilibreur de charge vers le Pod de destination NodePort, puis depuis celui-ci kube-proxy vers le Pod de destination sur un nœud distinct dans une autre zone de disponibilité. Il s'agit d'un exemple du paramètre du mode instance.
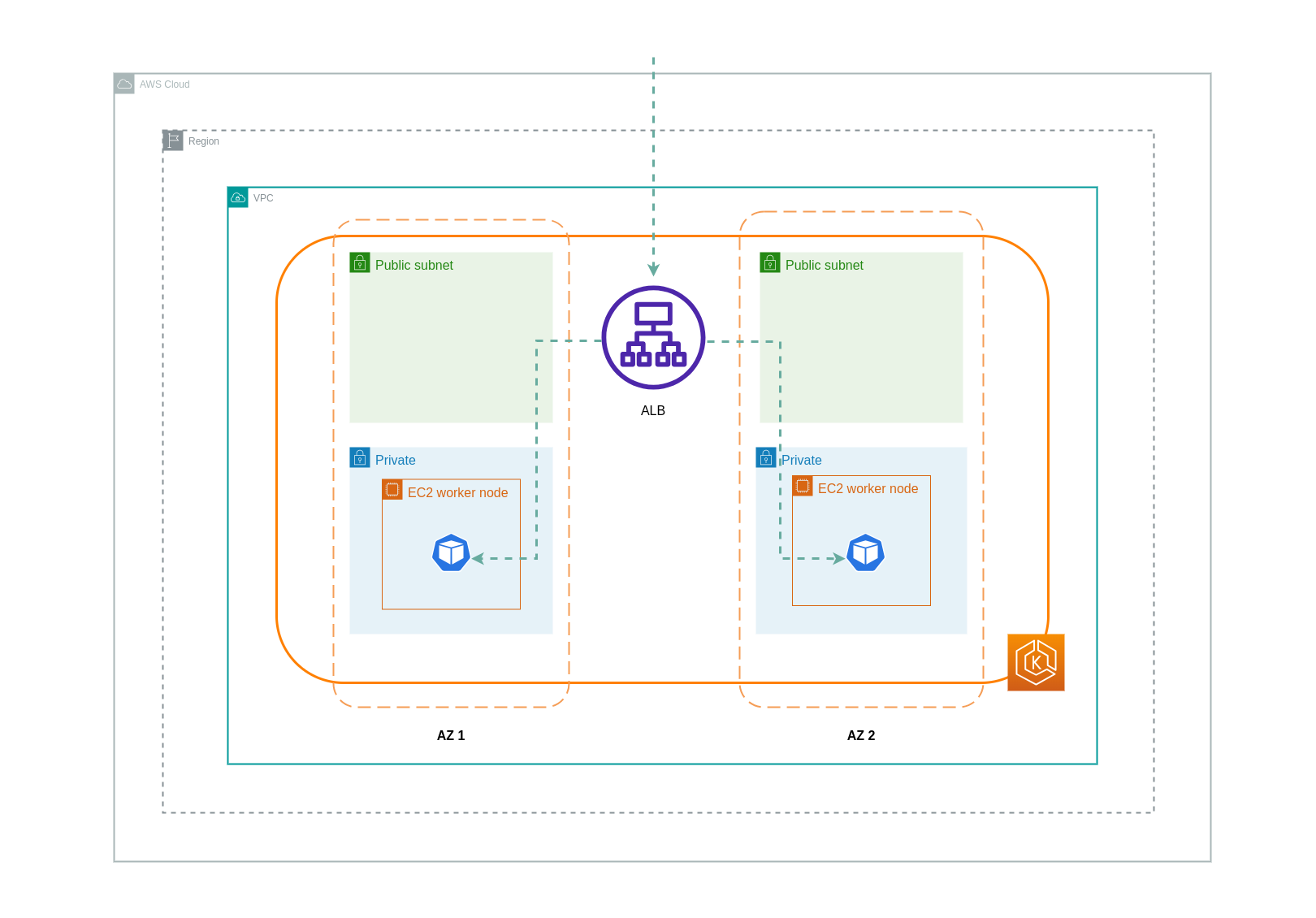
Lorsque le mode IP est utilisé, le trafic réseau est transmis par proxy depuis l'équilibreur de charge directement vers le Pod de destination. Par conséquent, cette approche n'entraîne aucun frais de transfert de données.
Note
Il est recommandé de configurer votre équilibreur de charge en mode trafic IP afin de réduire les frais de transfert de données. Pour cette configuration, il est également important de vous assurer que votre équilibreur de charge est déployé sur tous les sous-réseaux de votre VPC.
Le schéma ci-dessous décrit les chemins réseau pour le trafic circulant entre l'équilibreur de charge et les Pods en mode IP du réseau.
Transfert de données depuis le registre des conteneurs
Amazon ECR
Le transfert de données vers le registre privé Amazon ECR est gratuit. Le transfert de données à l'intérieur de la région est gratuit, mais le transfert de données vers Internet et entre les régions sera facturé aux tarifs de transfert de données Internet des deux côtés du transfert.
Vous devez utiliser la fonction de réplication d'image ECRs intégrée pour répliquer les images de conteneur pertinentes dans la même région que vos charges de travail. De cette façon, la réplication serait facturée une seule fois, et toutes les extractions d'images de la même région (intra-région) seraient gratuites.
Vous pouvez réduire davantage les coûts de transfert de données associés à l'extraction d'images depuis l'ECR (transfert de données sortant) en utilisant les points de terminaison VPC d'interface pour vous connecter aux référentiels ECR de la région. L'approche alternative consistant à se connecter au point de terminaison AWS public d'ECR (via une passerelle NAT et une passerelle Internet) entraînera des coûts de traitement et de transfert de données plus élevés. La section suivante abordera plus en détail la réduction des coûts de transfert de données entre vos charges de travail et les services AWS.
Si vous exécutez des charges de travail avec des images particulièrement volumineuses, vous pouvez créer vos propres Amazon Machine Images (AMIs) personnalisées à partir d'images de conteneur prémises en cache. Cela peut réduire le temps d'extraction initial de l'image et les coûts potentiels de transfert de données d'un registre de conteneurs vers les nœuds de travail EKS.
Transfert de données vers Internet et les services AWS
Il est courant d'intégrer les charges de travail Kubernetes à d'autres services AWS ou à des outils et plateformes tiers via Internet. L'infrastructure réseau sous-jacente utilisée pour acheminer le trafic vers et depuis la destination concernée peut avoir un impact sur les coûts engagés dans le processus de transfert de données.
Utilisation de passerelles NAT
Les passerelles NAT sont des composants réseau qui effectuent la traduction d'adresses réseau (NAT). Le schéma ci-dessous décrit les pods d'un cluster EKS communiquant avec d'autres services AWS (Amazon ECR, DynamoDB et S3) et des plateformes tierces. Dans cet exemple, les Pods s'exécutent séparément AZs dans des sous-réseaux privés. Pour envoyer et recevoir du trafic depuis Internet, une passerelle NAT est déployée sur le sous-réseau public d'une AZ, permettant à toutes les ressources possédant des adresses IP privées de partager une seule adresse IP publique pour accéder à Internet. Cette passerelle NAT communique à son tour avec le composant Internet Gateway, permettant aux paquets d'être envoyés à leur destination finale.
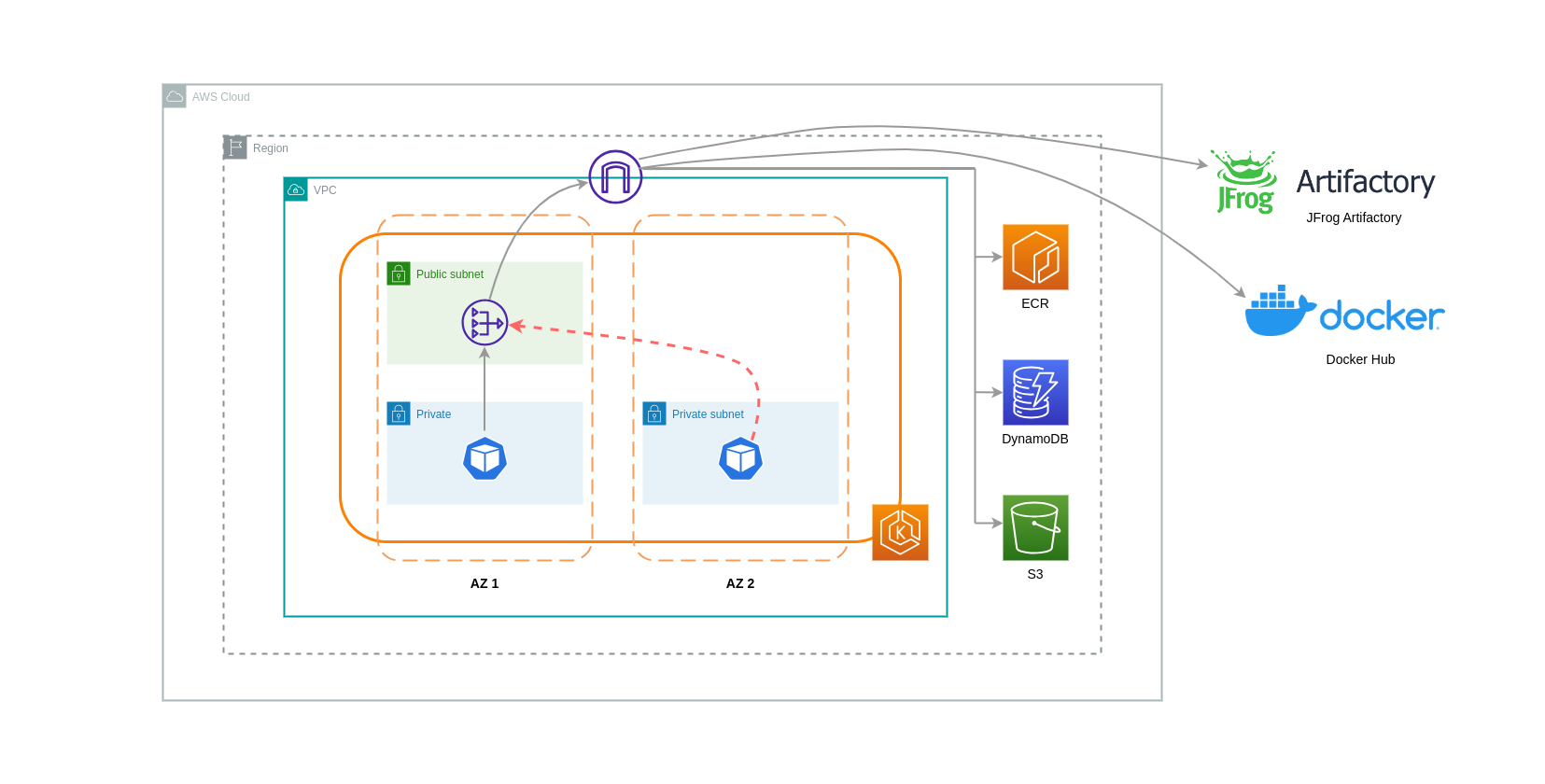
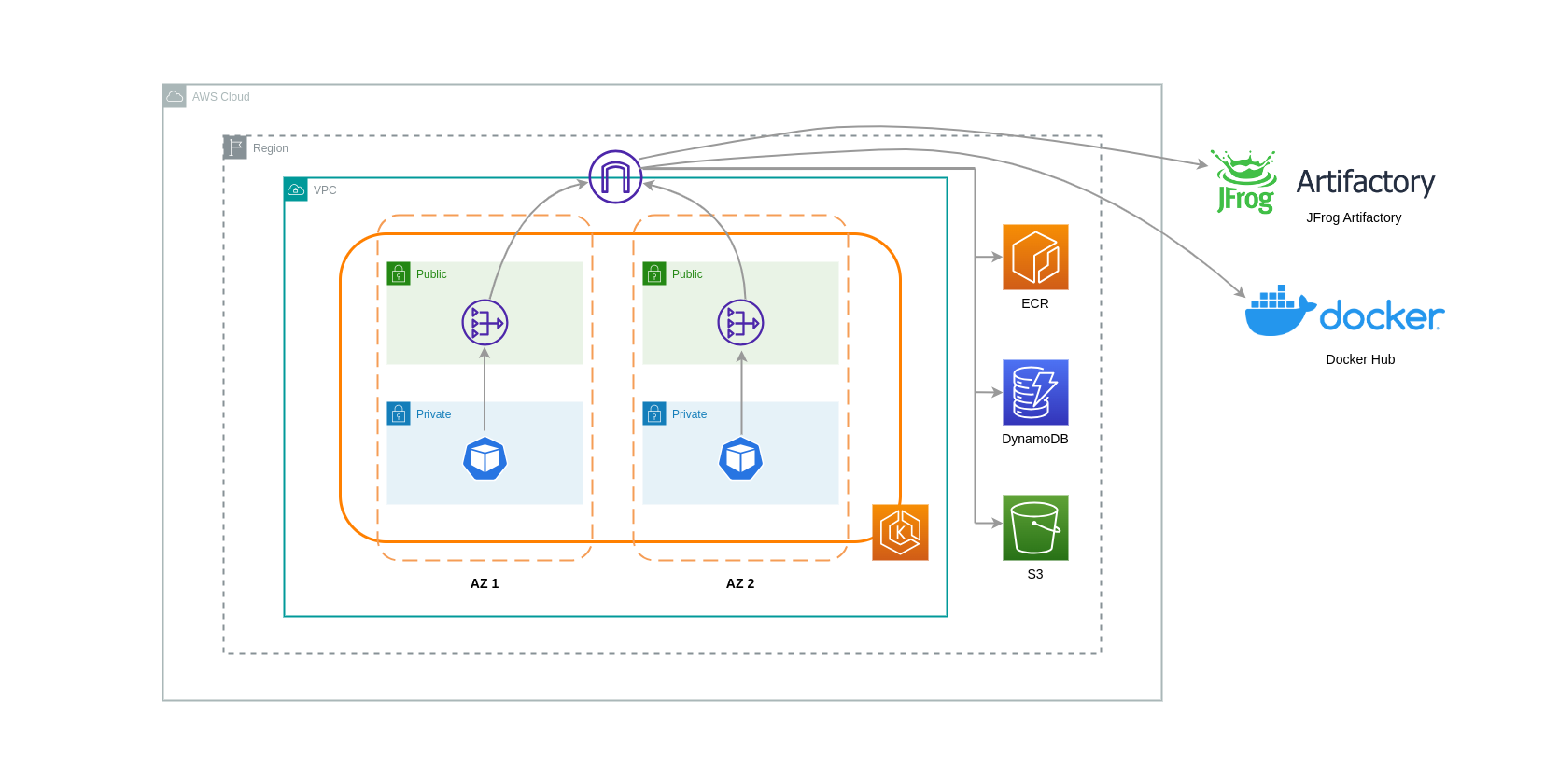
Lorsque vous utilisez des passerelles NAT pour de tels cas d'utilisation, vous pouvez minimiser les coûts de transfert de données en déployant une passerelle NAT dans chaque zone de disponibilité. De cette façon, le trafic acheminé vers Internet passera par la passerelle NAT dans la même zone de zone, évitant ainsi le transfert de données inter-zones. Cependant, même si vous économiserez sur le coût du transfert de données inter-AZ, cette configuration implique le coût d'une passerelle NAT supplémentaire dans votre architecture.
Cette approche recommandée est illustrée dans le schéma ci-dessous.
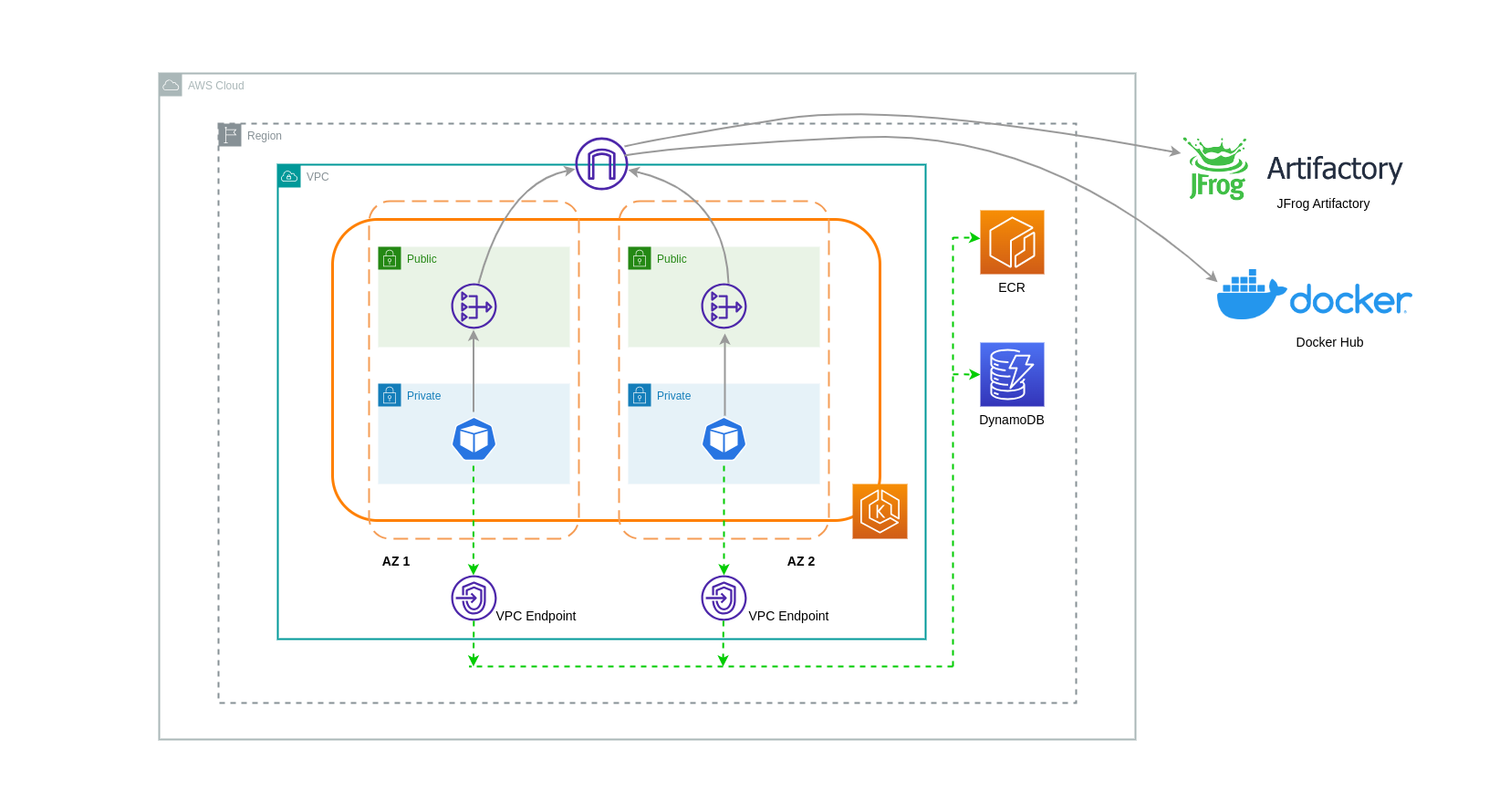
Utilisation de points de terminaison de VPC
Pour réduire davantage les coûts dans de telles architectures, vous devez utiliser des points de terminaison VPC pour établir la connectivité entre vos charges de travail et les services AWS. Les points de terminaison VPC vous permettent d'accéder aux services AWS depuis un VPC sans data/network que les paquets ne transitent par Internet. L'ensemble du trafic est interne et reste au sein du réseau AWS. Il existe deux types de points de terminaison VPC : les points de terminaison VPC d'interface (pris en charge par de nombreux services AWS) et les points de terminaison VPC Gateway (uniquement pris en charge par S3 et DynamoDB).
Points de terminaison VPC Gateway
Aucun coût horaire ou de transfert de données n'est associé aux points de terminaison VPC Gateway. Lorsque vous utilisez des points de terminaison VPC Gateway, il est important de noter qu'ils ne sont pas extensibles au-delà des limites des VPC. Ils ne peuvent pas être utilisés dans le peering VPC, les réseaux VPN ou via Direct Connect.
Points de terminaison VPC d'interface
Les points de terminaison VPC sont facturés à l'heure
Le schéma ci-dessous montre les pods communiquant avec les services AWS via des points de terminaison VPC.
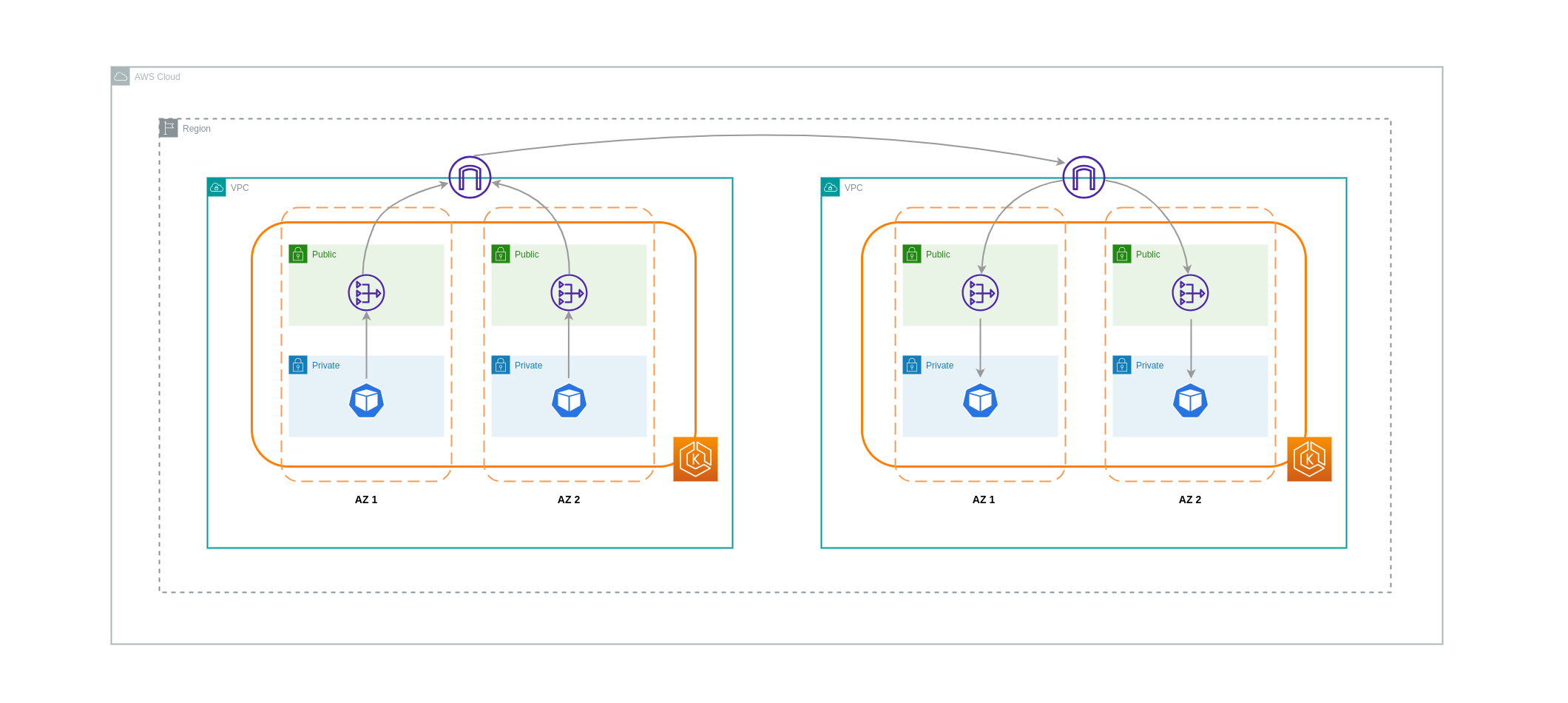
Transfert de données entre VPCs
Dans certains cas, vous pouvez avoir des charges de travail distinctes VPCs (au sein de la même région AWS) qui doivent communiquer entre elles. Cela peut être accompli en permettant au trafic de traverser l'Internet public via des passerelles Internet connectées à l'Internet correspondant VPCs. Une telle communication peut être activée en déployant des composants d'infrastructure tels que des EC2 instances, des passerelles NAT ou des instances NAT dans des sous-réseaux publics. Cependant, une configuration incluant ces composants entraînera des frais pour les processing/transferring données entrantes et sortantes du VPCs. Si le trafic à destination et en provenance de la ligne séparée VPCs se déplace AZs, le transfert de données sera soumis à des frais supplémentaires. Le schéma ci-dessous décrit une configuration qui utilise des passerelles NAT et des passerelles Internet pour établir une communication entre des charges de travail de différents types. VPCs
Connexions d'appairage de VPC
Pour réduire les coûts liés à de tels cas d'utilisation, vous pouvez utiliser le peering VPC. Avec une connexion d'appairage VPC, aucun frais de transfert de données n'est facturé pour le trafic réseau qui reste dans la même zone de distribution. Si le trafic se croise AZs, des frais seront encourus. Néanmoins, l'approche de peering VPC est recommandée pour une communication rentable entre des charges de travail distinctes au sein d'une même VPCs région AWS. Cependant, il est important de noter que le peering VPC est principalement efficace pour la connectivité VPC 1:1, car il ne permet pas la mise en réseau transitive.
Le schéma ci-dessous est une représentation de haut niveau de la communication des charges de travail via une connexion d'appairage VPC.
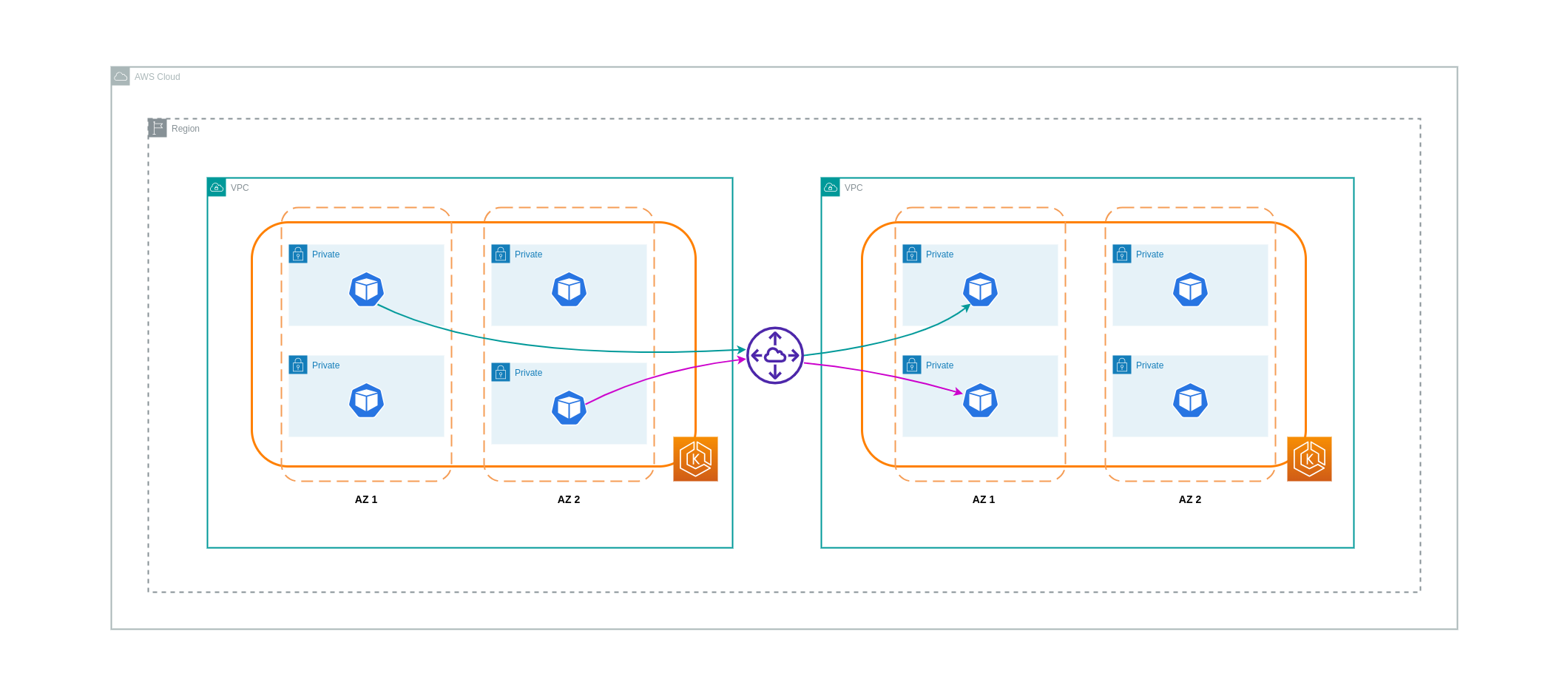
Connexions réseau transitives
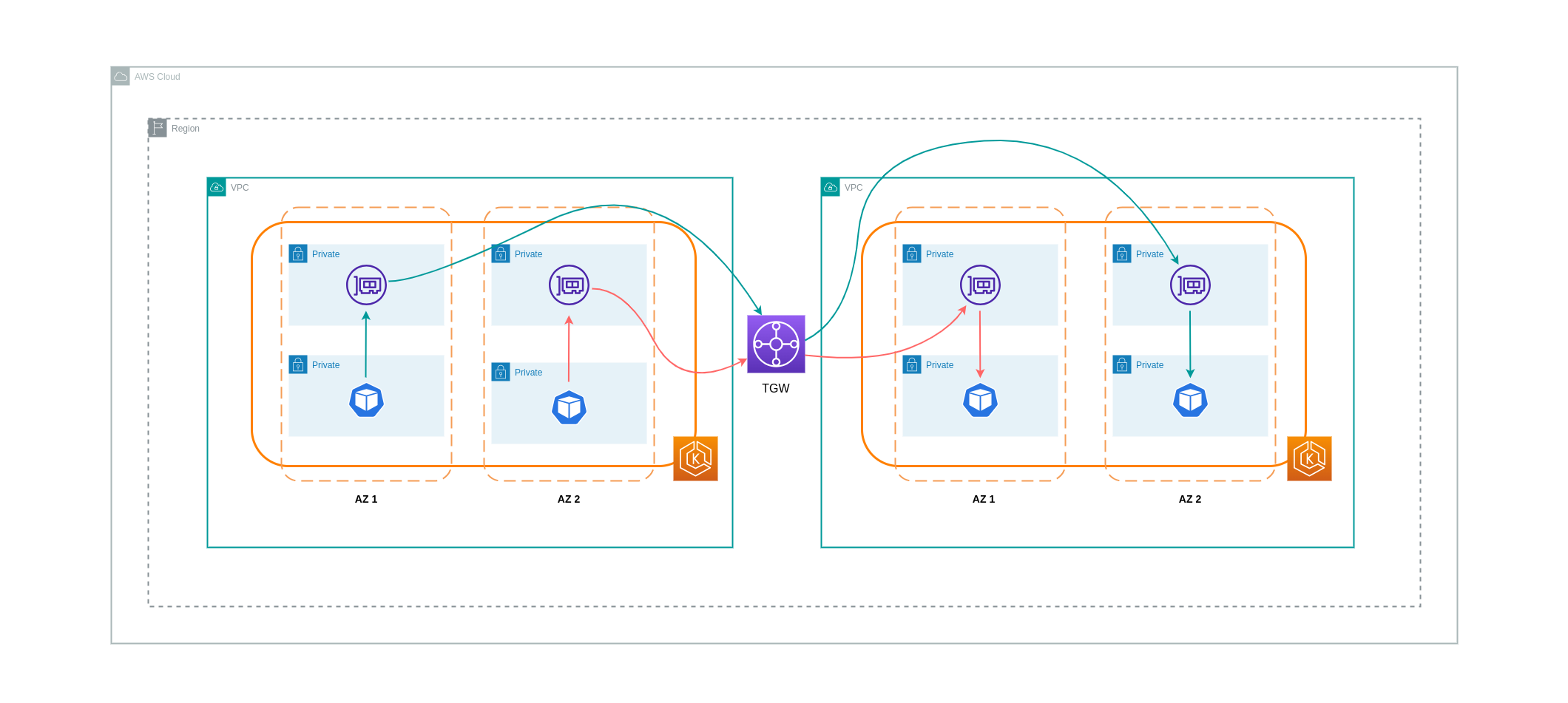
Comme indiqué dans la section précédente, les connexions d'appairage VPC ne permettent pas la connectivité réseau transitive. Si vous souhaitez en connecter 3 ou plus VPCs avec des exigences de réseau transitives, vous devez utiliser un Transit Gateway (TGW). Cela vous permettra de surmonter les limites de l'appairage VPC ou de surmonter toute surcharge opérationnelle associée à la présence de plusieurs connexions d'appairage VPC entre plusieurs. VPCs Vous êtes facturé sur une base horaire
Le schéma ci-dessous montre le trafic inter-AZ passant par un TGW entre des charges de travail situées dans des régions AWS différentes VPCs mais au sein de la même région AWS.
Utilisation d'un Service Mesh
Les maillages de service offrent de puissantes fonctionnalités réseau qui peuvent être utilisées pour réduire les coûts liés au réseau dans vos environnements de clusters EKS. Cependant, vous devez examiner attentivement les tâches opérationnelles et la complexité qu'un maillage de services introduira dans votre environnement si vous en adoptez un.
Limiter le trafic aux zones de disponibilité
Utilisation de la distribution pondérée par localité d'Istio
Istio vous permet d'appliquer des politiques réseau au trafic après le routage. Cela se fait à l'aide de règles de destination
Note
Avant d'implémenter la distribution pondérée par localité, vous devez commencer par comprendre les modèles de trafic de votre réseau et les implications que la politique des règles de destination peut avoir sur le comportement de votre application. Il est donc important de mettre en place des mécanismes de suivi distribués avec des outils tels qu'AWS X-Ray
Les règles de destination Istio détaillées ci-dessus peuvent également être appliquées pour gérer le trafic entre un équilibreur de charge et les pods de votre cluster EKS. Les règles de distribution pondérées par localité peuvent être appliquées à un service qui reçoit du trafic provenant d'un équilibreur de charge à haute disponibilité (en particulier la passerelle d'entrée). Ces règles vous permettent de contrôler la quantité de trafic à destination en fonction de son origine zonale, c'est-à-dire l'équilibreur de charge dans ce cas. S'il est configuré correctement, le trafic de sortie entre zones sera réduit par rapport à un équilibreur de charge qui répartit le trafic de manière uniforme ou aléatoire entre les répliques de Pod de différentes manières. AZs
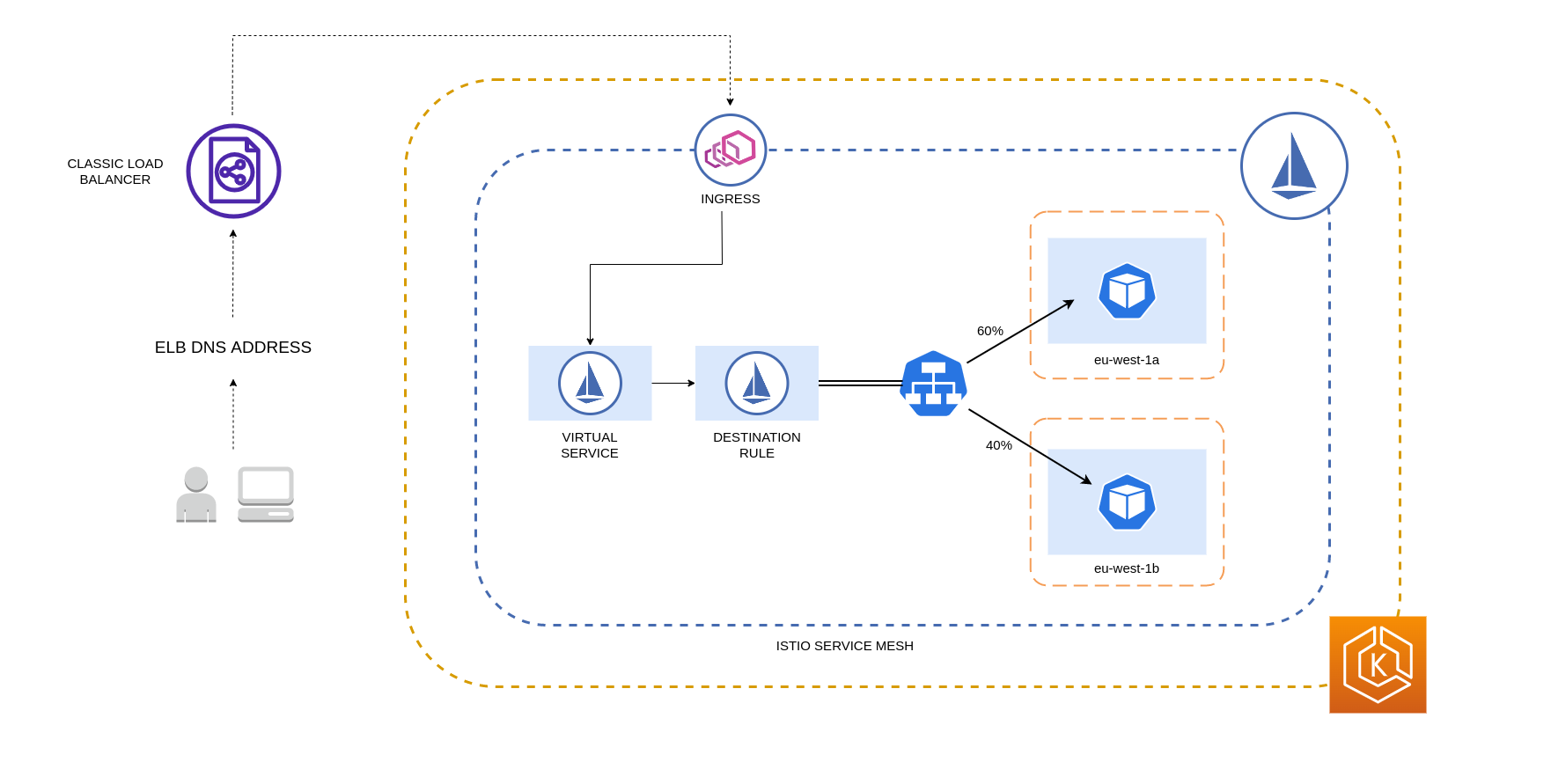
Vous trouverez ci-dessous un exemple de bloc de code d'une ressource Destination Rule dans Istio. Comme on peut le voir ci-dessous, cette ressource spécifie des configurations pondérées pour le trafic entrant provenant de 3 pays différents AZs de la eu-west-1 région. Ces configurations indiquent que la majorité du trafic entrant (70 % dans ce cas) en provenance d'une AZ donnée doit être transmise par proxy à une destination située dans la même AZ d'où il provient.
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
Note
Le poids minimum pouvant être distribué à la destination est de 1 %. La raison en est de conserver les régions et zones de basculement au cas où les terminaux de la destination principale deviendraient défectueux ou indisponibles.
Le schéma ci-dessous décrit un scénario dans lequel il existe un équilibreur de charge hautement disponible dans la région eu-west-1 et une distribution pondérée par localité est appliquée. La politique de règle de destination de ce diagramme est configurée pour envoyer 60 % du trafic en provenance d'eu-west-1a vers des pods situés dans la même zone, tandis que 40 % du trafic en provenance d'eu-west-1a doit être dirigé vers des pods situés dans eu-west-1b.
Limiter le trafic aux zones de disponibilité et aux nœuds
Utilisation de la politique de trafic interne du service avec Istio
Pour atténuer les coûts réseau associés au trafic entrant externe et au trafic interne entre les pods, vous pouvez combiner les règles de destination d'Istio et la politique de trafic interne du service Kubernetes. La manière de combiner les règles de destination d'Istio avec la politique de trafic interne du service dépendra largement de 3 éléments :
-
Le rôle des microservices
-
Schémas du trafic réseau sur les microservices
-
Comment les microservices doivent être déployés dans la topologie du cluster Kubernetes
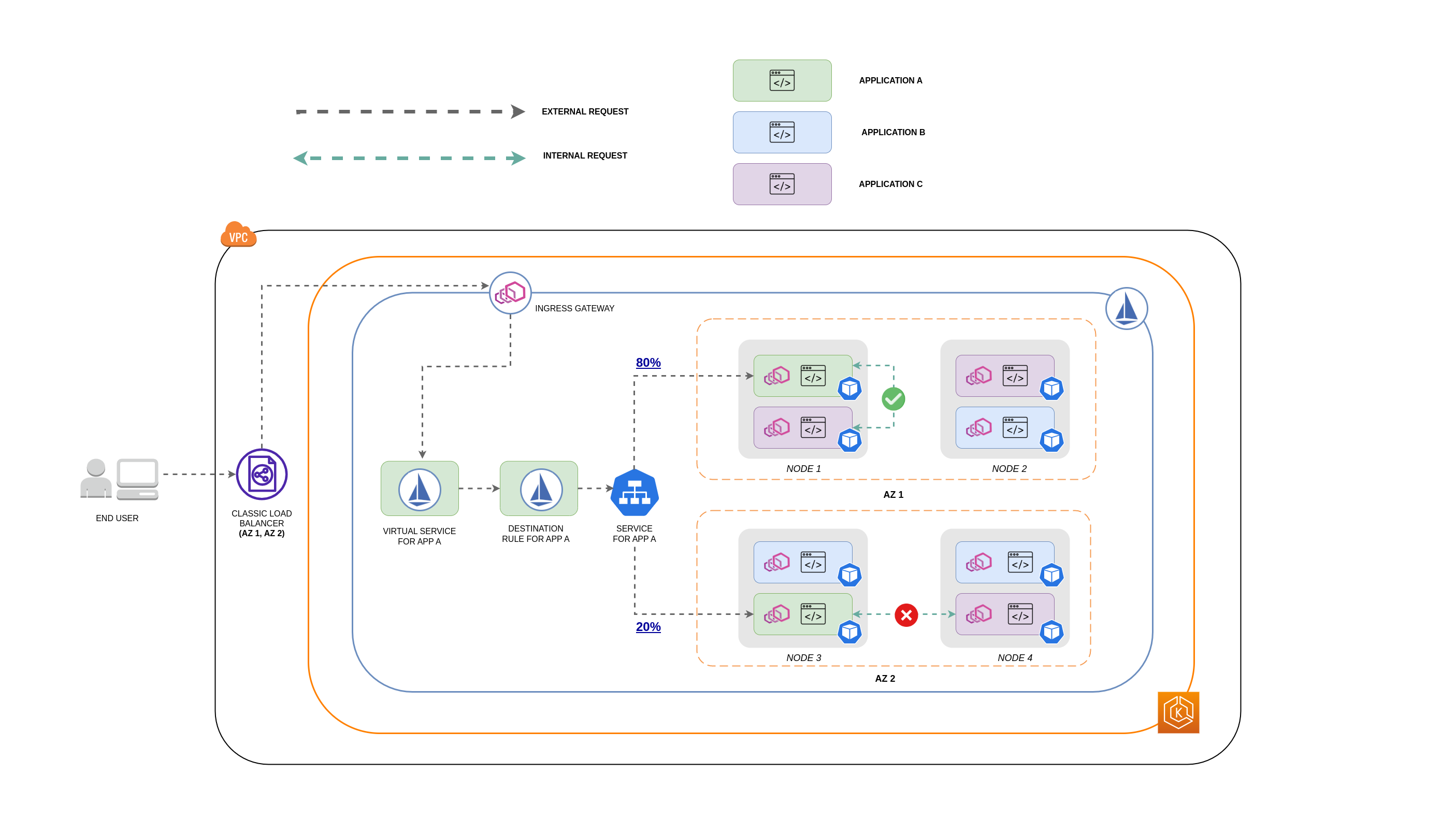
Le schéma ci-dessous montre à quoi ressemblerait le flux réseau dans le cas d'une demande imbriquée et comment les politiques susmentionnées contrôleraient le trafic.
-
L'utilisateur final fait une demande à APP A, qui à son tour envoie une demande imbriquée à APP C. Cette demande est d'abord envoyée à un équilibreur de charge hautement disponible, qui possède des instances dans AZ 1 et AZ 2, comme le montre le schéma ci-dessus.
-
La demande entrante externe est ensuite acheminée vers la bonne destination par le service virtuel Istio.
-
Une fois la demande acheminée, la règle de destination Istio contrôle le volume de trafic destiné à la demande en AZs fonction de son origine (AZ 1 ou AZ 2).
-
Le trafic est ensuite dirigé vers le service pour l'APP A, puis est transmis par proxy aux points de terminaison du Pod respectifs. Comme le montre le schéma, 80 % du trafic entrant est envoyé aux points de terminaison Pod dans l'AZ 1, et 20 % du trafic entrant est envoyé à l'AZ 2.
-
L'APP A envoie ensuite une demande interne à l'APP C. Le service APP C dispose d'une politique de trafic interne activée (
internalTrafficPolicy`: Local`). -
La demande interne de l'APP A (sur le NŒUD 1) à l'APP C est réussie en raison du point de terminaison local disponible pour l'APP C.
-
La demande interne de l'APP A (sur le NŒUD 3) à l'APP C échoue car aucun point de terminaison local au nœud n'est disponible pour l'APP C. Comme le montre le schéma, APP C n'a pas de répliques sur NODE 3. * *
Les captures d'écran ci-dessous ont été capturées à partir d'un exemple réel de cette approche. La première série de captures d'écran montre une demande externe réussie adressée à un graphql et une demande imbriquée envoyée avec succès graphql à une orders réplique colocalisée sur le nœud. ip-10-0-0-151.af-south-1.compute.internal
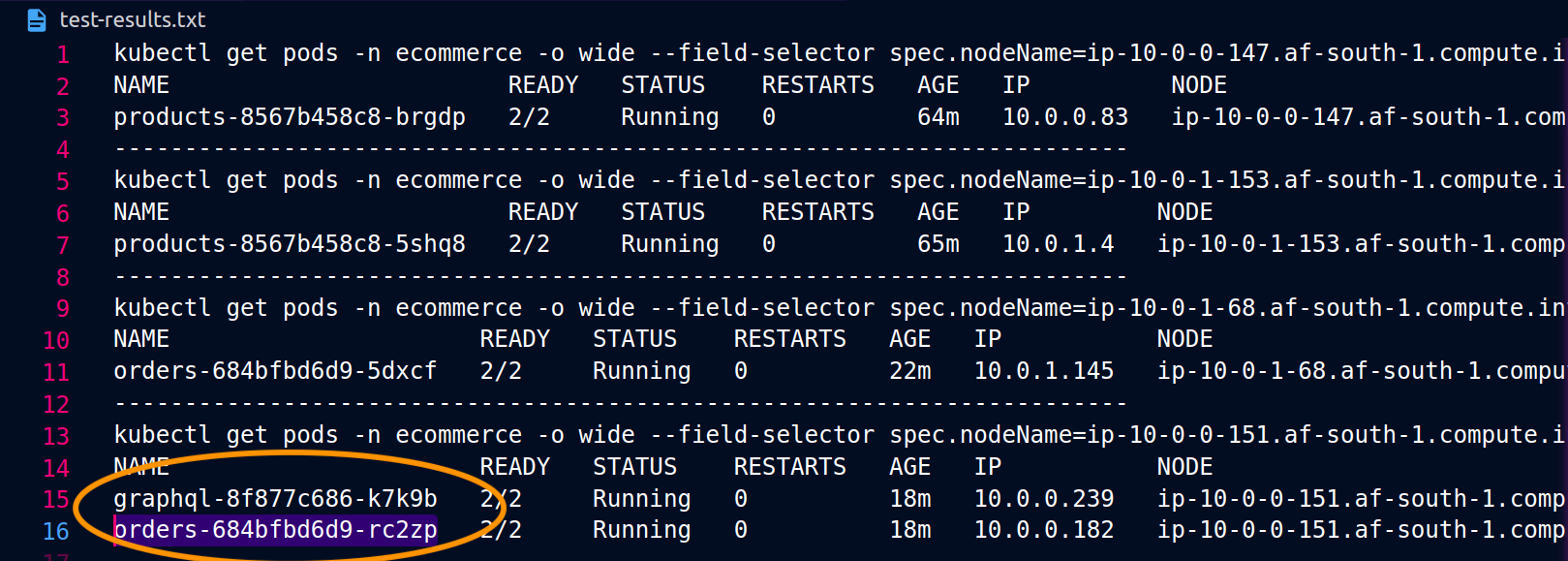
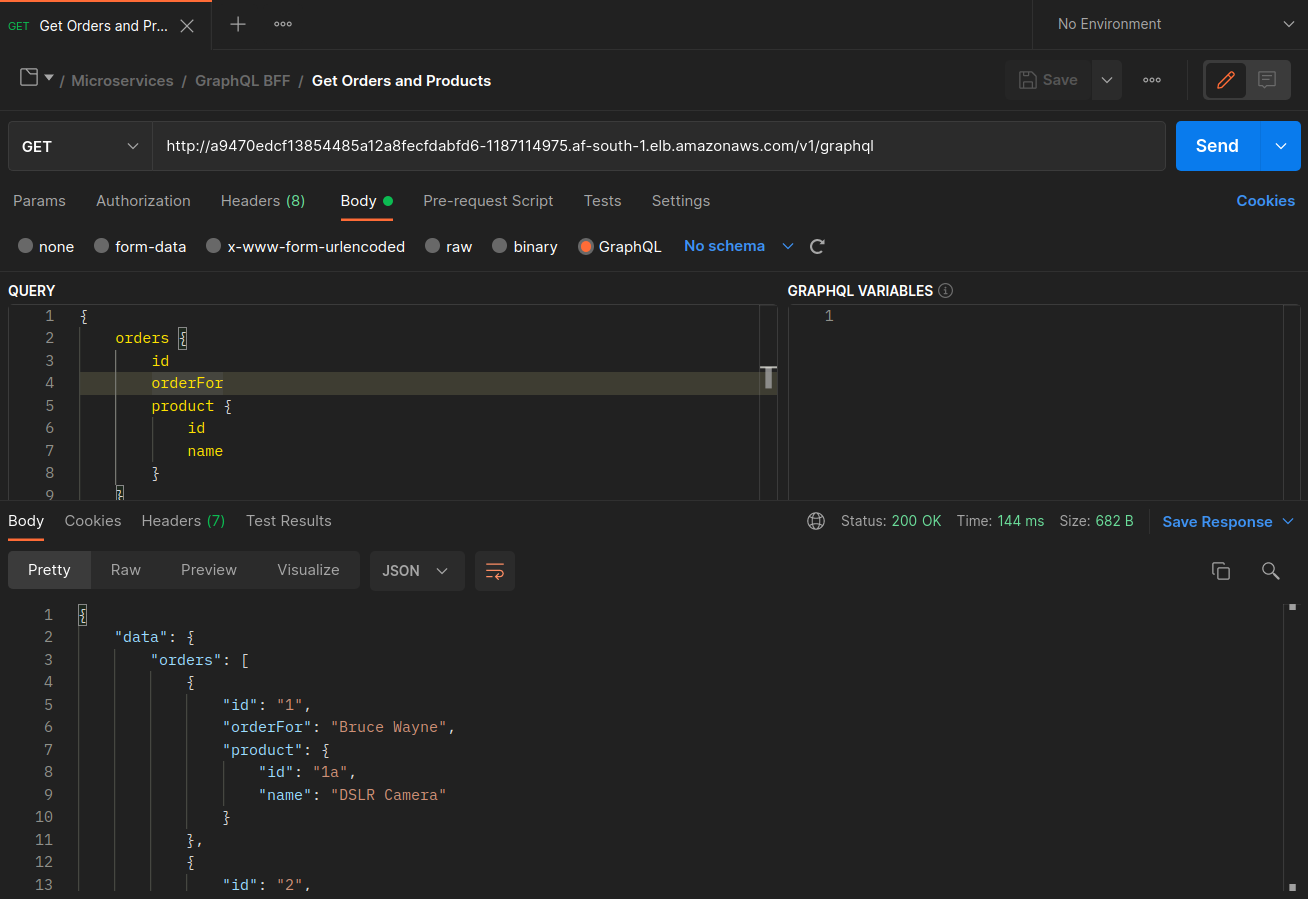
Avec Istio, vous pouvez vérifier et exporter les statistiques de n'importe quel [cluster en amont] (https://www.envoyproxy. io/docs/envoy/latest/intro/arch_overview/intro/terminologyorders points de terminaison connus du graphql proxy peuvent être obtenus à l'aide de la commande suivante :
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
Dans ce cas, le graphql proxy ne connaît que le orders point de terminaison de la réplique avec laquelle il partage un nœud. Si vous supprimez le internalTrafficPolicy: Local paramètre du service des commandes et que vous réexécutez une commande comme celle ci-dessus, les résultats renverront tous les points de terminaison des répliques répartis sur les différents nœuds. De plus, en examinant rq_total les points de terminaison respectifs, vous remarquerez une part relativement uniforme de la distribution réseau. Par conséquent, si les points de terminaison sont associés à des services en amont exécutés dans des AZs environnements différents, cette distribution du réseau entre les zones entraînera des coûts plus élevés.
Comme indiqué dans une section précédente ci-dessus, vous pouvez co-localiser des pods qui communiquent fréquemment en utilisant l'affinité des pods.
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
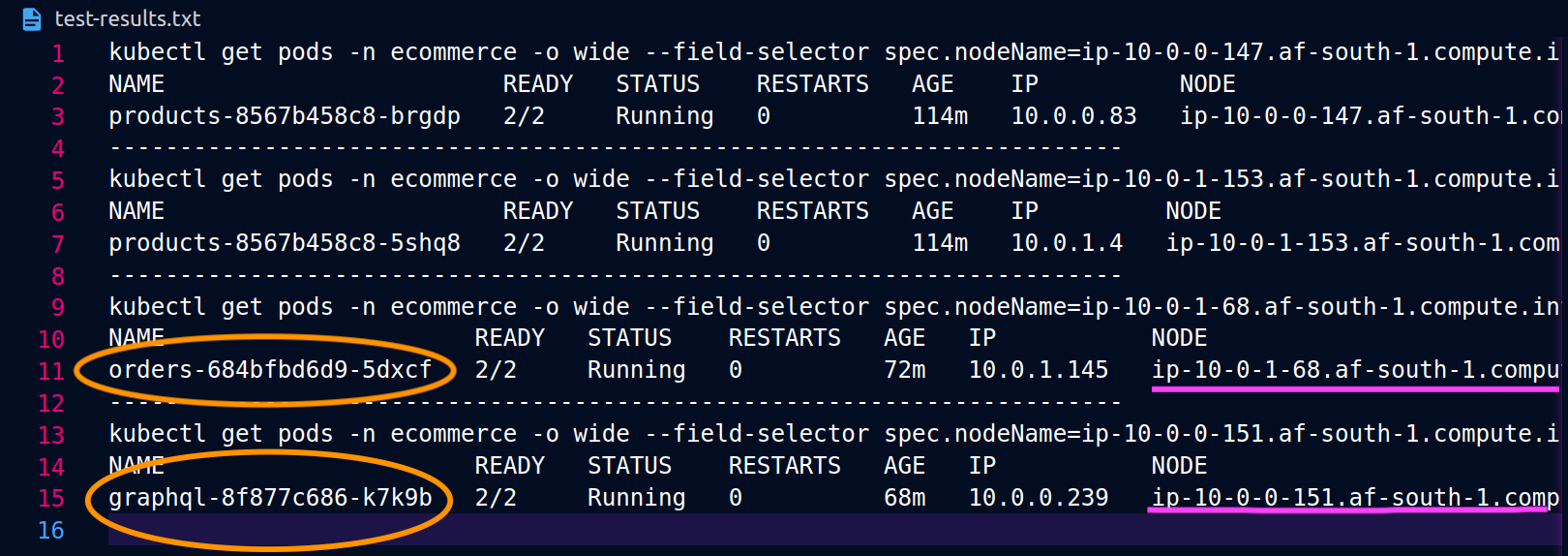
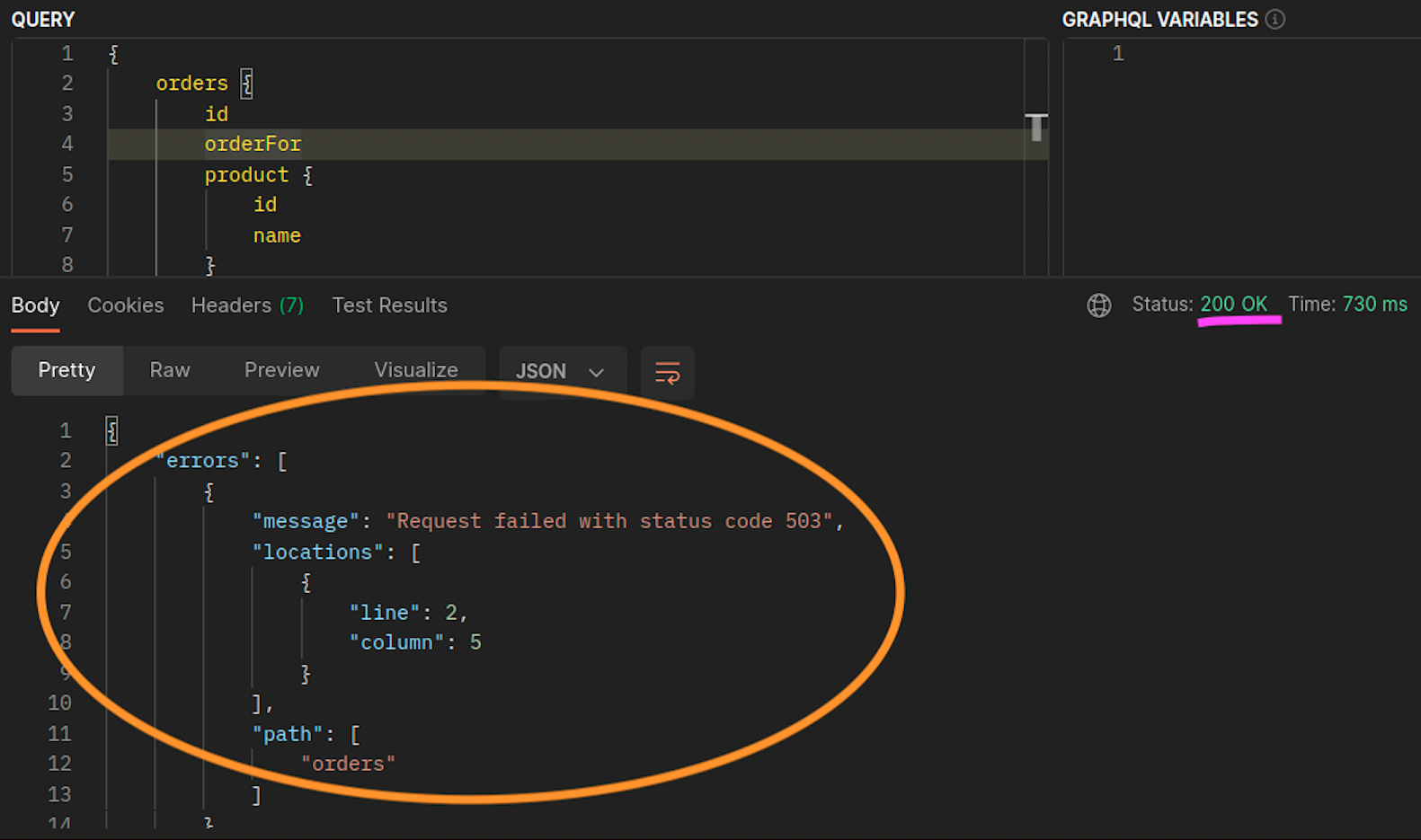
Lorsque les orders répliques graphql et ne coexistent pas sur le même nœud (ip-10-0-0-151.af-south-1.compute.internal), la première demande graphql est réussie, comme indiqué 200 response code dans la capture d'écran de Postman ci-dessous, tandis que la deuxième demande imbriquée de graphql à orders échoue avec un. 503 response code
Ressources supplémentaires
-
Gestion de la latence et des coûts de transfert de données sur EKS à l'aide d'Istio
-
Obtenir de la visibilité sur les octets réseau de votre Amazon EKS Cross-AZ d'un point à l'autre
-
Optimisez le trafic AZ avec un routage tenant compte de la topologie
-
Présentation des coûts de transfert des données pour les architectures courantes
-
Comprendre les coûts de transfert de données pour les services de conteneurs AWS
