Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Ajout d'une connexion JDBC à l'aide de vos propres pilotes JDBC
Vous pouvez utiliser votre propre pilote JDBC lorsque vous utilisez une connexion JDBC. Lorsque le pilote par défaut utilisé par le AWS Glue robot d'exploration ne parvient pas à se connecter à une base de données, vous pouvez utiliser votre propre pilote JDBC. Par exemple, si vous souhaitez utiliser SHA-256 avec votre base de données Postgres et que les anciens pilotes Postgres ne le prennent pas en charge, vous pouvez utiliser votre propre pilote JDBC.
Sources de données prises en charge
| Sources de données prises en charge | Sources de données non prises en charge |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
* Pris en charge si le pilote JDBC natif est utilisé. Toutes les fonctionnalités du pilote ne peuvent pas être exploitées.
Ajout d'un pilote JDBC à une connexion JDBC
Note
Si vous choisissez d'utiliser vos propres versions de pilote JDBC, les robots d' AWS Glue exploration consommeront des ressources dans les AWS Glue tâches et les compartiments Amazon S3 pour s'assurer que le pilote que vous avez fourni est exécuté dans votre environnement. L'utilisation supplémentaire des ressources sera reflétée sur votre compte. Le coût des AWS Glue robots d'exploration et des tâches figure dans la AWS Glue catégorie indiquée dans la facturation. De plus, le fait de fournir votre propre pilote JDBC ne signifie pas que le Crawler est capable de tirer parti de toutes les fonctionnalités du pilote.
Pour ajouter votre propre pilote JDBC à une connexion JDBC :
-
Ajoutez le fichier du pilote JDBC à un emplacement Amazon S3. Vous pouvez créer un and/or dossier de bucket ou utiliser un and/or dossier de bucket existant.
-
Dans la AWS Glue console, choisissez Connexions dans le menu de gauche sous Catalogue de données, puis créez une nouvelle connexion.
-
Complétez les champs pour Propriétés de connexion et choisissez JDBC pour Type de connexion.
-
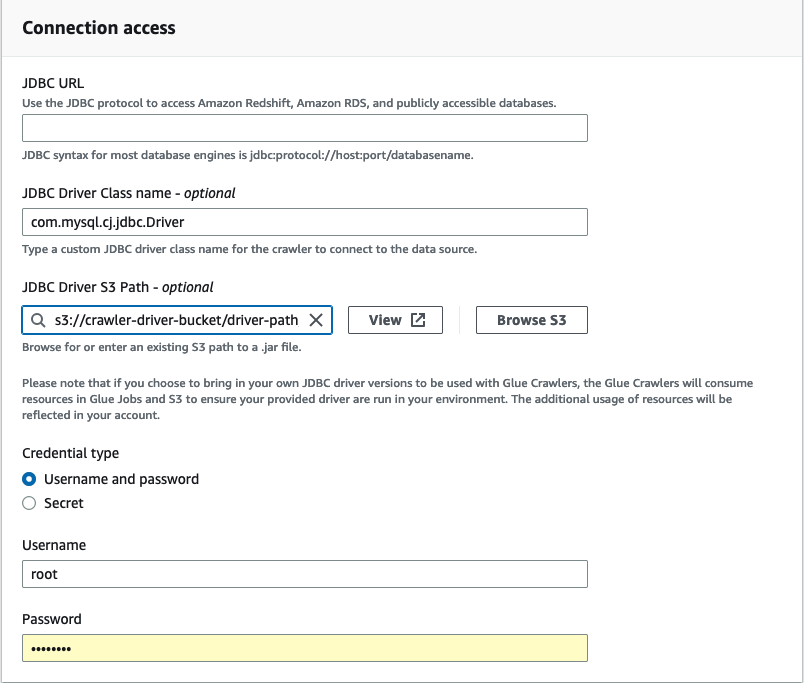
Dans Accès à la connexion, entrez l'URL JDBC et le nom de la classe de pilote JDBC (facultatif). Le nom de classe du pilote doit être celui d'une source de données prise en charge par les robots d' AWS Glue exploration.
-
Choisissez le chemin Amazon S3 où se trouve le pilote JDBC dans chemin Amazon S3 du pilote JDBC : champ (facultatif).
-
Complétez les champs du type d'informations d'identification si vous saisissez un nom d'utilisateur et un mot de passe ou un code secret. Lorsque vous avez terminé, choisissez Créer une connexion.
Note
Le test de connexion n'est pas pris en charge pour le moment. Lorsque vous effectuez une indexation de site web de la source de données à l'aide d'un pilote JDBC que vous avez fourni, le Crawler ignore cette étape.
-
Ajoutez la connexion nouvellement créée à un Crawler. Dans la AWS Glue console, choisissez Crawlers dans le menu de gauche sous Data Catalog, puis créez un nouveau crawler.
-
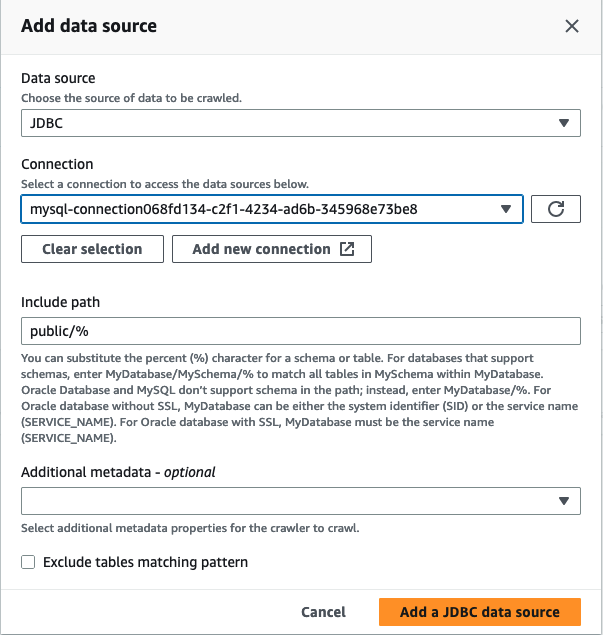
Dans l'assistant Ajouter un Crawler, à l'étape 2, choisissez Ajouter une source de données.
-
Choisissez JDBC comme source de données et choisissez la connexion créée lors des étapes précédentes. Complet
-
Pour utiliser votre propre pilote JDBC avec un AWS Glue robot d'exploration, ajoutez les autorisations suivantes au rôle utilisé par le robot d'exploration :
-
Accordez des autorisations pour les actions de tâches suivantes :
CreateJob,DeleteJob,GetJob,GetJobRun,StartJobRun. -
Accordez des autorisations pour les actions IAM :
iam:PassRole -
Accordez des autorisations pour les actions Amazon S3 :
s3:DeleteObjects,s3:GetObject,s3:ListBucket,s3:PutObject. -
Accordez l'accès principal au service bucket/folder dans la politique IAM.
Exemple de politique IAM :
Le AWS Glue robot crée deux dossiers : _glue_job_crawler et _crawler.
Si le fichier JAR du pilote se trouve dans le
s3://amzn-s3-demo-bucket/driver.jar"dossier, ajoutez les ressources suivantes :"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]Si le fichier JAR du pilote se trouve dans le
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar"dossier, ajoutez les ressources suivantes :"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
Si vous utilisez un VPC, vous devez autoriser l'accès au point de AWS Glue terminaison en créant le point de terminaison de l'interface et en l'ajoutant à votre table de routage. Pour plus d'informations, consultez Création d'un point de terminaison VPC d'interface pour AWS Glue
-
Si vous utilisez le chiffrement dans votre catalogue de données, créez le point de terminaison de l' AWS KMS interface et ajoutez-le à votre table de routage. Pour de plus amples informations, consultez Creating a VPC endpoint for AWS KMS.
