Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Tutoriel : Écrire un script ETL AWS Glue pour Ray
Ray vous permet d'écrire et de dimensionner des tâches distribuées de manière native en Python. AWS Glue for Ray propose des environnements Ray sans serveur auxquels vous pouvez accéder à la fois à partir de tâches et de sessions interactives (les sessions interactives Ray sont en version préliminaire). Le système de AWS Glue tâches fournit un moyen cohérent de gérer et d'exécuter vos tâches, selon un calendrier, à partir d'un déclencheur ou depuis la console. AWS Glue
La combinaison de ces AWS Glue outils crée une puissante chaîne d'outils que vous pouvez utiliser pour les charges de travail d'extraction, de transformation et de chargement (ETL), un cas d'utilisation populaire. AWS Glue Dans ce didacticiel, vous apprendrez les bases de la mise en place de cette solution.
Nous prenons également en charge l'utilisation AWS Glue de Spark pour vos charges de travail ETL. Pour un didacticiel sur l'écriture d'un script AWS Glue pour Spark, consultezTutoriel : Écrire un script AWS Glue for Spark. Pour plus d'informations sur les moteurs disponibles, consultez AWS Glue pour Spark et AWS Glue pour Ray. Ray est capable de traiter de nombreux types de tâches dans les domaines de l'analyse, du machine learning (ML) et du développement d'applications.
Dans ce didacticiel, vous allez extraire, transformer et charger un jeu de données CSV hébergé dans Amazon Simple Storage Service (Amazon S3). Vous allez commencer par le jeu de données d'enregistrement de voyages de l’agence New York City Taxi and Limousine Commission (TLC), qui est stocké dans un compartiment Amazon S3 public. Pour plus d'informations sur ce jeu de données, consultez le Registre des données ouvertes sur AWS
Vous transformerez vos données à l'aide de transformations prédéfinies disponibles dans la bibliothèque Ray Data. Ray Data est une bibliothèque de préparation de jeux de données conçue par Ray et incluse par défaut dans AWS Glue les environnements for Ray. Pour plus d'informations sur les bibliothèques incluses par défaut, consultez Modules fournis avec les tâches Ray. Vous écrirez ensuite vos données transformées dans un compartiment Amazon S3 que vous contrôlez.
Conditions préalables — Pour ce didacticiel, vous avez besoin d'un AWS compte avec accès à Amazon S3 AWS Glue et à Amazon S3.
Étape 1 : créer un compartiment dans Amazon S3 pour stocker vos données de sortie
Vous aurez besoin d'un compartiment Amazon S3 que vous contrôlez pour servir de récepteur pour les données créées dans ce didacticiel. Vous pouvez créer ce compartiment en procédant comme suit.
Note
Si vous souhaitez écrire vos données dans un compartiment existant que vous contrôlez, vous pouvez ignorer cette étape. Prenez note du yourBucketName nom du compartiment existant, à utiliser ultérieurement.
Pour créer un compartiment pour la sortie de votre tâche Ray
-
Créez un compartiment en suivant les étapes décrites dans la section Créer un compartiment du Guide de l'utilisateur Amazon S3.
-
Lorsque vous choisissez un nom de bucket, prenez-en note
yourBucketName, auquel vous vous référerez dans les étapes suivantes. -
Pour les autres configurations, les paramètres suggérés fournis dans la console Amazon S3 devraient fonctionner correctement dans ce didacticiel.
Par exemple, la boîte de dialogue de création de compartiments peut ressembler à ceci dans la console Amazon S3.
-
Étape 2 : créer un rôle IAM pour votre politique pour votre tâche Ray
Votre travail nécessitera un rôle AWS Identity and Access Management (IAM) présentant les caractéristiques suivantes :
-
Autorisations accordées par la politique gérée
AWSGlueServiceRole. Il s'agit des autorisations de base nécessaires pour exécuter une AWS Glue tâche. -
Autorisations du niveau d'accès
Readpour la ressource Amazon S3nyc-tlc/*. -
Autorisations du niveau d'accès
Writepour la ressource Amazon S3yourBucketName/* -
Une relation de confiance qui permet au principal
glue.amazonaws.comd'assumer le rôle.
Vous pouvez créer ce rôle en procédant comme suit.
Pour créer un rôle IAM pour votre job AWS Glue for Ray
Note
Vous pouvez créer un rôle IAM en suivant de nombreuses procédures différentes. Pour plus d'informations ou d'options sur le provisionnement des ressources IAM, consultez la documentation AWS Identity and Access Management.
-
Créez une politique qui définit les autorisations Amazon S3 décrites précédemment en suivant les étapes décrites dans la section Création de politiques avec l'éditeur visuel du Guide de l'utilisateur IAM.
-
Lorsque vous sélectionnez un service, choisissez Amazon S3.
-
Lorsque vous sélectionnez des autorisations pour votre politique, associez les ensembles d'actions suivants pour les ressources suivantes (mentionnées précédemment) :
-
Autorisations du niveau d'accès de lecture pour la ressource Amazon S3
nyc-tlc/*. -
Autorisations du niveau d'accès d'écriture pour la ressource Amazon S3
yourBucketName/*
-
-
Lorsque vous sélectionnez le nom de la politique
YourPolicyName, prenez-en note, auquel vous vous référerez ultérieurement.
-
-
Créez un rôle pour votre tâche AWS Glue for Ray en suivant les étapes décrites dans la section Création d'un rôle pour un AWS service (console) dans le guide de l'utilisateur IAM.
-
Lorsque vous sélectionnez une entité AWS de service fiable, choisissez
Glue. Cela renseignera automatiquement la relation de confiance nécessaire pour votre tâche. -
Lorsque vous sélectionnez des politiques pour la politique d'autorisations, joignez les politiques suivantes :
-
AWSGlueServiceRole -
YourPolicyName
-
-
Lorsque vous sélectionnez le nom du rôle, prenez-en note
YourRoleName, auquel vous vous référerez dans les étapes ultérieures.
-
Étape 3 : créer et exécuter une tâche AWS Glue pour Ray
Au cours de cette étape, vous créez une AWS Glue tâche à l'aide du AWS Management Console, vous lui fournissez un exemple de script et vous exécutez la tâche. Lorsque vous créez une tâche, elle crée un emplacement dans la console où vous pouvez stocker, configurer et modifier votre script Ray. Pour plus d'informations sur la création de tâches, consultez Gestion des AWS Glue tâches dans la AWS console.
Dans ce didacticiel, nous abordons le scénario ETL suivant : vous souhaitez lire les enregistrements de janvier 2022 du jeu de données New York City TLC Trip Record, ajouter une nouvelle colonne (tip_rate) au jeu de données en combinant les données dans des colonnes existantes, puis supprimer un certain nombre de colonnes qui ne sont pas pertinentes pour votre analyse actuelle, puis vous souhaitez y écrire les résultats. yourBucketName Le script Ray suivant exécute les étapes suivantes :
import ray import pandas from ray import data ray.init('auto') ds = ray.data.read_csv("s3://nyc-tlc/opendata_repo/opendata_webconvert/yellow/yellow_tripdata_2022-01.csv") # Add the given new column to the dataset and show the sample record after adding a new column ds = ds.add_column( "tip_rate", lambda df: df["tip_amount"] / df["total_amount"]) # Dropping few columns from the underlying Dataset ds = ds.drop_columns(["payment_type", "fare_amount", "extra", "tolls_amount", "improvement_surcharge"]) ds.write_parquet("s3://yourBucketName/ray/tutorial/output/")
Pour créer et exécuter une tâche AWS Glue pour Ray
-
Dans le AWS Management Console, accédez à la page de AWS Glue destination.
-
Dans le volet de navigation latéral, choisissez Tâches ETL.
-
Dans Créer une tâche, choisissez Éditeur de script Ray, puis choisissez Créer, comme dans l'illustration suivante.
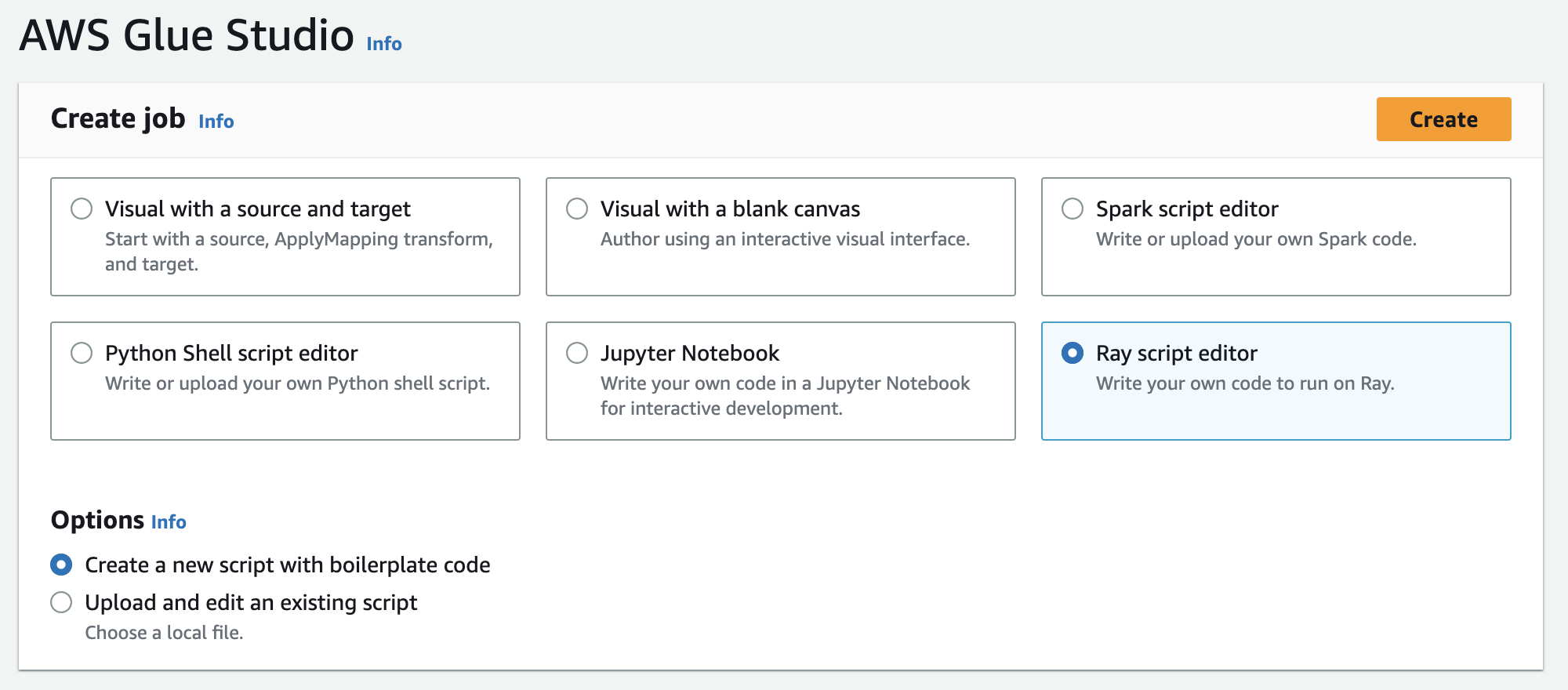
-
Collez le texte complet du script dans le volet Script et remplacez le texte existant.
-
Accédez aux détails du Job et définissez la propriété IAM Role sur
YourRoleName. -
Choisissez Enregistrer, puis Exécuter.
Étape 4 : inspecter votre sortie
Après avoir exécuté votre AWS Glue tâche, vous devez vérifier que le résultat correspond aux attentes de ce scénario. Pour ce faire, suivez la procédure suivante.
Pour valider si votre tâche Ray a été exécutée correctement
-
Sur la page des détails de la tâche, accédez à Exécutions.
-
Au bout de quelques minutes, vous devriez voir une exécution dont le statut d'exécution est Réussi.
-
Accédez à la console Amazon S3 à l'adresse https://console.aws.amazon.com/s3/
et inspectez-la yourBucketName. Vous devez voir des fichiers écrits dans votre compartiment de sortie. -
Lisez les fichiers Parquet et vérifiez leur contenu. Vous pouvez le faire avec vos outils existants. Si vous n'avez pas de processus de validation des fichiers Parquet, vous pouvez le faire dans la AWS Glue console avec une session AWS Glue interactive, en utilisant Spark ou Ray (en version préliminaire).
Dans une session interactive, vous avez accès aux bibliothèques Ray Data, Spark ou Pandas, qui sont fournies par défaut (en fonction du moteur que vous avez choisi). Pour vérifier le contenu de votre fichier, vous pouvez utiliser les méthodes d'inspection courantes disponibles dans ces bibliothèques (des méthodes comme
count,schemaetshow). Pour plus d'informations sur les sessions interactives dans la console, consultez la section Utilisation de blocs-notes avec AWS Glue Studio et AWS Glue.Comme vous avez confirmé que les fichiers ont été écrits dans le compartiment, vous pouvez affirmer avec une relative certitude que si votre sortie présente des problèmes, ils ne sont pas liés à la configuration IAM. Configurez votre session
yourRoleNamepour avoir accès aux fichiers concernés.
Si vous n'obtenez pas les résultats escomptés, consultez le contenu de dépannage de ce guide pour identifier la source de l'erreur et y remédier. Vous trouverez le contenu de dépannage dans le chapitre Résolution des problèmes de AWS Glue. Pour les erreurs spécifiques liées aux tâches Ray, consultez Résolution AWS Glue des erreurs Ray liées aux journaux au chapitre de dépannage.
Étapes suivantes
Vous avez maintenant vu et exécuté un processus ETL utilisant AWS Glue for Ray de bout en bout. Vous pouvez utiliser les ressources suivantes pour comprendre AWS Glue les outils fournis par Ray pour transformer et interpréter vos données à grande échelle.
-
Pour plus d'informations sur le modèle de tâche de Ray, consultez Utiliser Ray Core et Ray Data AWS Glue pour Ray. Pour plus d'expérience dans l'utilisation des tâches Ray, suivez les exemples de la documentation Ray Core. Consultez Ray Core: Ray Tutorials and Examples (2.4.0)
dans la documentation Ray. -
Pour obtenir des conseils sur les bibliothèques de gestion de données disponibles dans AWS Glue for Ray, consultezConnexion aux données dans les tâches Ray. Pour en savoir plus sur l'utilisation de Ray Data pour transformer et écrire des jeux de données, suivez les exemples de la documentation Ray Data. Consultez Ray Data: Examples (2.4.0)
. -
Pour plus d'informations sur la configuration AWS Glue des tâches Ray, consultezTravailler avec Ray Jobs dans AWS Glue.
-
Pour plus d'informations sur l'écriture de scripts AWS Glue pour Ray, continuez à lire la documentation de cette section.
