Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Intégration au registre de schémas AWS Glue
Ces sections décrivent les intégrations avec le registre des AWS Glue schémas. Les exemples présentés dans cette section montrent un schéma au format de données AVRO. Pour d'autres exemples, notamment des schémas au format de données JSON, consultez les tests d'intégration et les ReadMe informations dans le référentiel open source du registre des AWS Glue schémas
Rubriques
Cas d'utilisation : connexion du registre de schémas à Amazon MSK ou à Apache Kafka
Supposons que vous écrivez des données sur une rubrique Apache Kafka, et que vous pouvez suivre ces étapes pour commencer.
Créez un cluster Amazon Managed Streaming for Apache Kafka (Amazon MSK) ou Apache Kafka avec au moins un sujet. Si vous créez un cluster Amazon MSK, vous pouvez utiliser la AWS Management Console. Suivez les instructions ci-après : Mise en route avec Amazon MSK dans le Guide du développeur Amazon Managed Streaming for Apache Kafka.
Suivez l'étape Installation de SerDe bibliothèques ci-dessus.
Pour créer des registres de schéma, des schémas ou des versions de schéma, suivez les instructions sous la section Commencer à utiliser le registre des schémas de ce document.
Faites en sorte que vos producteurs et consommateurs utilisent le registre des schémas pour écrire et lire des enregistrements sur to/from le sujet Amazon MSK ou Apache Kafka. Des exemples de code producteur et consommateur se trouvent dans le ReadMe fichier
des bibliothèques Serde. La bibliothèque du registre de schémas du producteur sérialisera automatiquement l'enregistrement et décorera l'enregistrement avec un ID de version de schéma. Si le schéma de cet enregistrement a été saisi, ou si l'enregistrement automatique est activé, le schéma aura été enregistré dans le registre de schémas.
La lecture de l'application consommateur à partir de la rubrique Amazon MSK ou Apache Kafka, à l'aide de la bibliothèque du registre de schémas AWS Glue, recherche automatiquement le schéma à partir du registre de schémas.
Cas d'utilisation : intégration d'Amazon Kinesis Data Streams au registre de schémas AWS Glue
Cette intégration nécessite que vous ayez un flux de données Amazon Kinesis existant. Pour plus d'informations, veuillez consulter Présentation des Amazon Kinesis Data Streams dans le Guide du développeur Amazon Kinesis Data Streams.
Il existe deux façons d'interagir avec les données d'un flux de données Kinesis.
Via les bibliothèques Kinesis Producer Library (KPL) et Kinesis Client Library (KCL) en Java. La prise en charge multilingue n'est pas fournie.
Grâce au
PutRecordsPutRecord, et auxGetRecordsKinesis Data APIs Streams disponibles dans le AWS SDK pour Java.
Si vous utilisez actuellement les KPL/KCL bibliothèques, nous vous recommandons de continuer à utiliser cette méthode. Il existe des versions KCL et KPL mises à jour avec le registre de schémas intégré, comme illustré dans les exemples. Sinon, vous pouvez utiliser l'exemple de code pour tirer parti du registre des AWS Glue schémas si vous utilisez APIs directement le KDS.
L'intégration du registre de schémas n'est disponible qu'avec KPL version 0.14.2 ou ultérieure et avec KCL version 2.3 ou ultérieure. L'intégration du registre de schémas avec le format de données JSON est disponible avec KPL version 0.14.8 ou ultérieure et avec KCL version 2.3.6 ou ultérieure.
Interagir avec les données à l'aide du kit SDK Kinesis V2
Cette section décrit l'interaction avec Kinesis à l'aide du kit SDK Kinesis V2
// Example JSON Record, you can construct a AVRO record also private static final JsonDataWithSchema record = JsonDataWithSchema.builder(schemaString, payloadString); private static final DataFormat dataFormat = DataFormat.JSON; //Configurations for Schema Registry GlueSchemaRegistryConfiguration gsrConfig = new GlueSchemaRegistryConfiguration("us-east-1"); GlueSchemaRegistrySerializer glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatSerializer dataFormatSerializer = new GlueSchemaRegistrySerializerFactory().getInstance(dataFormat, gsrConfig); Schema gsrSchema = new Schema(dataFormatSerializer.getSchemaDefinition(record), dataFormat.name(), "MySchema"); byte[] serializedBytes = dataFormatSerializer.serialize(record); byte[] gsrEncodedBytes = glueSchemaRegistrySerializer.encode(streamName, gsrSchema, serializedBytes); PutRecordRequest putRecordRequest = PutRecordRequest.builder() .streamName(streamName) .partitionKey("partitionKey") .data(SdkBytes.fromByteArray(gsrEncodedBytes)) .build(); shardId = kinesisClient.putRecord(putRecordRequest) .get() .shardId(); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(awsCredentialsProvider, gsrConfig); GlueSchemaRegistryDataFormatDeserializer gsrDataFormatDeserializer = glueSchemaRegistryDeserializerFactory.getInstance(dataFormat, gsrConfig); GetShardIteratorRequest getShardIteratorRequest = GetShardIteratorRequest.builder() .streamName(streamName) .shardId(shardId) .shardIteratorType(ShardIteratorType.TRIM_HORIZON) .build(); String shardIterator = kinesisClient.getShardIterator(getShardIteratorRequest) .get() .shardIterator(); GetRecordsRequest getRecordRequest = GetRecordsRequest.builder() .shardIterator(shardIterator) .build(); GetRecordsResponse recordsResponse = kinesisClient.getRecords(getRecordRequest) .get(); List<Object> consumerRecords = new ArrayList<>(); List<Record> recordsFromKinesis = recordsResponse.records(); for (int i = 0; i < recordsFromKinesis.size(); i++) { byte[] consumedBytes = recordsFromKinesis.get(i) .data() .asByteArray(); Schema gsrSchema = glueSchemaRegistryDeserializer.getSchema(consumedBytes); Object decodedRecord = gsrDataFormatDeserializer.deserialize(ByteBuffer.wrap(consumedBytes), gsrSchema.getSchemaDefinition()); consumerRecords.add(decodedRecord); }
Interaction avec les données à l'aide KPL/KCL des bibliothèques
Cette section décrit l'intégration de Kinesis Data Streams à Schema Registry à KPL/KCL l'aide des bibliothèques. Pour en savoir plus sur l'utilisation de KPL/KPC, veuillez consulter Développement d'applications producteur à l'aide de la bibliothèque producteur Amazon Kinesis dans le Guide du développeur Amazon Kinesis Data Streams..
Configuration du registre de schémas dans KPL
Définissez la définition de schéma pour les données, le format de données et le nom de schéma créés dans le registre de schémas AWS Glue.
Le cas échéant, configurez l'objet
GlueSchemaRegistryConfiguration.Transmettez l'objet du schéma à
addUserRecord API.private static final String SCHEMA_DEFINITION = "{"namespace": "example.avro",\n" + " "type": "record",\n" + " "name": "User",\n" + " "fields": [\n" + " {"name": "name", "type": "string"},\n" + " {"name": "favorite_number", "type": ["int", "null"]},\n" + " {"name": "favorite_color", "type": ["string", "null"]}\n" + " ]\n" + "}"; KinesisProducerConfiguration config = new KinesisProducerConfiguration(); config.setRegion("us-west-1") //[Optional] configuration for Schema Registry. GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration("us-west-1"); schemaRegistryConfig.setCompression(true); config.setGlueSchemaRegistryConfiguration(schemaRegistryConfig); ///Optional configuration ends. final KinesisProducer producer = new KinesisProducer(config); final ByteBuffer data = getDataToSend(); com.amazonaws.services.schemaregistry.common.Schema gsrSchema = new Schema(SCHEMA_DEFINITION, DataFormat.AVRO.toString(), "demoSchema"); ListenableFuture<UserRecordResult> f = producer.addUserRecord( config.getStreamName(), TIMESTAMP, Utils.randomExplicitHashKey(), data, gsrSchema); private static ByteBuffer getDataToSend() { org.apache.avro.Schema avroSchema = new org.apache.avro.Schema.Parser().parse(SCHEMA_DEFINITION); GenericRecord user = new GenericData.Record(avroSchema); user.put("name", "Emily"); user.put("favorite_number", 32); user.put("favorite_color", "green"); ByteArrayOutputStream outBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(outBytes, null); new GenericDatumWriter<>(avroSchema).write(user, encoder); encoder.flush(); return ByteBuffer.wrap(outBytes.toByteArray()); }
Configuration de la bibliothèque client Kinesis
Vous allez développer votre application consommateur de la bibliothèque client Kinesis en Java. Pour de plus amples informations, veuillez consulter Développement d'une application consommateur de la bibliothèque client Kinesis en Java dans le Guide du développeur Amazon Kinesis Data Streams.
Créez une instance de
GlueSchemaRegistryDeserializeren transmettant un objetGlueSchemaRegistryConfiguration.Transmettez le
GlueSchemaRegistryDeserializeràretrievalConfig.glueSchemaRegistryDeserializer.Accédez au schéma des messages entrants en appelant
kinesisClientRecord.getSchema().GlueSchemaRegistryConfiguration schemaRegistryConfig = new GlueSchemaRegistryConfiguration(this.region.toString()); GlueSchemaRegistryDeserializer glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), schemaRegistryConfig); RetrievalConfig retrievalConfig = configsBuilder.retrievalConfig().retrievalSpecificConfig(new PollingConfig(streamName, kinesisClient)); retrievalConfig.glueSchemaRegistryDeserializer(glueSchemaRegistryDeserializer); Scheduler scheduler = new Scheduler( configsBuilder.checkpointConfig(), configsBuilder.coordinatorConfig(), configsBuilder.leaseManagementConfig(), configsBuilder.lifecycleConfig(), configsBuilder.metricsConfig(), configsBuilder.processorConfig(), retrievalConfig ); public void processRecords(ProcessRecordsInput processRecordsInput) { MDC.put(SHARD_ID_MDC_KEY, shardId); try { log.info("Processing {} record(s)", processRecordsInput.records().size()); processRecordsInput.records() .forEach( r -> log.info("Processed record pk: {} -- Seq: {} : data {} with schema: {}", r.partitionKey(), r.sequenceNumber(), recordToAvroObj(r).toString(), r.getSchema())); } catch (Throwable t) { log.error("Caught throwable while processing records. Aborting."); Runtime.getRuntime().halt(1); } finally { MDC.remove(SHARD_ID_MDC_KEY); } } private GenericRecord recordToAvroObj(KinesisClientRecord r) { byte[] data = new byte[r.data().remaining()]; r.data().get(data, 0, data.length); org.apache.avro.Schema schema = new org.apache.avro.Schema.Parser().parse(r.schema().getSchemaDefinition()); DatumReader datumReader = new GenericDatumReader<>(schema); BinaryDecoder binaryDecoder = DecoderFactory.get().binaryDecoder(data, 0, data.length, null); return (GenericRecord) datumReader.read(null, binaryDecoder); }
Interaction avec les données à l'aide des Kinesis Data Streams APIs
Cette section décrit l'intégration de Kinesis Data Streams à Schema Registry à l'aide des Kinesis Data Streams. APIs
Mettez à jour ces dépendances Maven :
<dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-bom</artifactId> <version>1.11.884</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-kinesis</artifactId> </dependency> <dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-serde</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-cbor</artifactId> <version>2.11.3</version> </dependency> </dependencies>Dans l'application producteur, ajoutez des informations d'en-tête de schéma à l'aide de l'API
PutRecordsouPutRecorddans Kinesis Data Streams.//The following lines add a Schema Header to the record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(getConfigs())); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes);Dans l'application producteur, utilisez l'API
PutRecordsouPutRecordpour placer l'enregistrement dans le flux de données.Dans l'application consommateur, supprimez l'enregistrement de schéma de l'en-tête et sérialisez un enregistrement de schéma Avro.
//The following lines remove Schema Header from record GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), getConfigs()); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); }
Interaction avec les données à l'aide des Kinesis Data Streams APIs
Voici un exemple de code pour utiliser le PutRecords et GetRecords APIs.
//Full sample code import com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryDeserializerImpl; import com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistrySerializerImpl; import com.amazonaws.services.schemaregistry.utils.AVROUtils; import com.amazonaws.services.schemaregistry.utils.AWSSchemaRegistryConstants; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericDatumReader; import org.apache.avro.generic.GenericDatumWriter; import org.apache.avro.generic.GenericRecord; import org.apache.avro.io.Decoder; import org.apache.avro.io.DecoderFactory; import org.apache.avro.io.Encoder; import org.apache.avro.io.EncoderFactory; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; import software.amazon.awssdk.services.glue.model.DataFormat; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.IOException; import java.nio.ByteBuffer; import java.util.Collections; import java.util.HashMap; import java.util.Map; public class PutAndGetExampleWithEncodedData { static final String regionName = "us-east-2"; static final String streamName = "testStream1"; static final String schemaName = "User-Topic"; static final String AVRO_USER_SCHEMA_FILE = "src/main/resources/user.avsc"; KinesisApi kinesisApi = new KinesisApi(); void runSampleForPutRecord() throws IOException { Object testRecord = getTestRecord(); byte[] recordAsBytes = convertRecordToBytes(testRecord); String schemaDefinition = AVROUtils.getInstance().getSchemaDefinition(testRecord); //The following lines add a Schema Header to a record com.amazonaws.services.schemaregistry.common.Schema awsSchema = new com.amazonaws.services.schemaregistry.common.Schema(schemaDefinition, DataFormat.AVRO.name(), schemaName); GlueSchemaRegistrySerializerImpl glueSchemaRegistrySerializer = new GlueSchemaRegistrySerializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeader = glueSchemaRegistrySerializer.encode(streamName, awsSchema, recordAsBytes); //Use PutRecords api to pass a list of records kinesisApi.putRecords(Collections.singletonList(recordWithSchemaHeader), streamName, regionName); //OR //Use PutRecord api to pass single record //kinesisApi.putRecord(recordWithSchemaHeader, streamName, regionName); } byte[] runSampleForGetRecord() throws IOException { ByteBuffer recordWithSchemaHeader = kinesisApi.getRecords(streamName, regionName); //The following lines remove the schema registry header GlueSchemaRegistryDeserializerImpl glueSchemaRegistryDeserializer = new GlueSchemaRegistryDeserializerImpl(DefaultCredentialsProvider.builder().build(), new GlueSchemaRegistryConfiguration(regionName)); byte[] recordWithSchemaHeaderBytes = new byte[recordWithSchemaHeader.remaining()]; recordWithSchemaHeader.get(recordWithSchemaHeaderBytes, 0, recordWithSchemaHeaderBytes.length); com.amazonaws.services.schemaregistry.common.Schema awsSchema = glueSchemaRegistryDeserializer.getSchema(recordWithSchemaHeaderBytes); byte[] record = glueSchemaRegistryDeserializer.getData(recordWithSchemaHeaderBytes); //The following lines serialize an AVRO schema record if (DataFormat.AVRO.name().equals(awsSchema.getDataFormat())) { Schema avroSchema = new org.apache.avro.Schema.Parser().parse(awsSchema.getSchemaDefinition()); Object genericRecord = convertBytesToRecord(avroSchema, record); System.out.println(genericRecord); } return record; } private byte[] convertRecordToBytes(final Object record) throws IOException { ByteArrayOutputStream recordAsBytes = new ByteArrayOutputStream(); Encoder encoder = EncoderFactory.get().directBinaryEncoder(recordAsBytes, null); GenericDatumWriter datumWriter = new GenericDatumWriter<>(AVROUtils.getInstance().getSchema(record)); datumWriter.write(record, encoder); encoder.flush(); return recordAsBytes.toByteArray(); } private GenericRecord convertBytesToRecord(Schema avroSchema, byte[] record) throws IOException { final GenericDatumReader<GenericRecord> datumReader = new GenericDatumReader<>(avroSchema); Decoder decoder = DecoderFactory.get().binaryDecoder(record, null); GenericRecord genericRecord = datumReader.read(null, decoder); return genericRecord; } private Map<String, String> getMetadata() { Map<String, String> metadata = new HashMap<>(); metadata.put("event-source-1", "topic1"); metadata.put("event-source-2", "topic2"); metadata.put("event-source-3", "topic3"); metadata.put("event-source-4", "topic4"); metadata.put("event-source-5", "topic5"); return metadata; } private GlueSchemaRegistryConfiguration getConfigs() { GlueSchemaRegistryConfiguration configs = new GlueSchemaRegistryConfiguration(regionName); configs.setSchemaName(schemaName); configs.setAutoRegistration(true); configs.setMetadata(getMetadata()); return configs; } private Object getTestRecord() throws IOException { GenericRecord genericRecord; Schema.Parser parser = new Schema.Parser(); Schema avroSchema = parser.parse(new File(AVRO_USER_SCHEMA_FILE)); genericRecord = new GenericData.Record(avroSchema); genericRecord.put("name", "testName"); genericRecord.put("favorite_number", 99); genericRecord.put("favorite_color", "red"); return genericRecord; } }
Cas d'utilisation : Amazon Managed Service pour Apache Flink
Apache Flink est un cadre open source populaire et un moteur de traitement distribué pour les calculs avec état sur des flux de données sans limite et limités. Amazon Managed Service pour Apache Flink est un AWS service entièrement géré qui vous permet de créer et de gérer des applications Apache Flink pour traiter des données de streaming.
Apache Flink open source fournit un certain nombre de sources et de récepteurs. Par exemple, les sources de données prédéfinies incluent la lecture à partir de fichiers, de répertoires et de sockets, ainsi que l'ingestion de données à partir de collections et d'itérateurs. DataStream Les connecteurs Apache Flink fournissent du code permettant à Apache Flink de s'interfacer avec divers systèmes tiers, tels qu'Apache Kafka ou Kinesis, en tant que récepteurs de sources. and/or
Pour plus d'informations, veuillez consulter le Guide du développeur Amazon Kinesis Data Analytics.
Connecteur Kafka Apache Flink
Apache Flink fournit un connecteur de flux de données Apache Kafka pour lire et écrire des données sur des sujets Kafka avec des garanties en une seule fois. L'application consommateur Kafka de Flink, FlinkKafkaConsumer, permet d'accéder à la lecture d'une ou de plusieurs rubriques Kafka. L'application producteur kafka d'Apache Flink, FlinkKafkaProducer, permet d'écrire un flux d'enregistrements à une ou plusieurs rubriques Kafka. Pour de plus amples informations, veuillez consulter Apache Kafka Connector
Connecteur de flux Kinesis Apache Flink
Le connecteur de flux de données Kinesis vous permet d'accéder à Amazon Kinesis Data Streams. FlinkKinesisConsumerIl s'agit d'une source de données de streaming parallèle qui s'abonne à plusieurs flux Kinesis au sein d'une même région de AWS service et qui peut gérer de manière transparente le repartitionnement des flux pendant l'exécution de la tâche. Chaque sous-tâche de l'application consommateur est responsable de la récupération des enregistrements de données à partir de plusieurs partitions Kinesis. Le nombre de partitions récupérées par chaque sous-tâche change au fur et à mesure que les partitions sont fermées et créées par Kinesis. Le FlinkKinesisProducer utilise Kinesis Producer Library (KPL) pour placer les données d'un flux Apache Flink dans un flux Kinesis. Pour plus d'informations, veuillez consulter Amazon Kinesis Streams Connector
Pour plus d'informations, veuillez consulter le Référentiel GitHub de schémas AWS Glue
Intégration à Apache Flink
La SerDes bibliothèque fournie avec Schema Registry s'intègre à Apache Flink. Pour travailler avec Apache Flink, vous devez implémenter des interfaces SerializationSchemaDeserializationSchemaGlueSchemaRegistryAvroSerializationSchema et GlueSchemaRegistryAvroDeserializationSchema, que vous pouvez brancher sur des connecteurs Apache Flink.
Ajout d'une dépendance du registre de schémas AWS Glue dans l'application Apache Flink
Pour configurer les dépendances d'intégration sur le registre de schémas AWS Glue dans l'application Apache Flink :
Ajoutez la dépendance au fichier
pom.xml.<dependency> <groupId>software.amazon.glue</groupId> <artifactId>schema-registry-flink-serde</artifactId> <version>1.0.0</version> </dependency>
Intégration de Kafka ou Amazon MSK à Apache Flink
Vous pouvez utiliser Service géré pour Apache Flink pour Apache Flink, avec Kafka comme source ou Kafka comme collecteur.
Kafka en tant que source
Le diagramme suivant illustre l'intégration de Kinesis Data Streams Kinesis à Service géré pour Apache Flink pour Apache Flink, avec Kafka en tant que source.
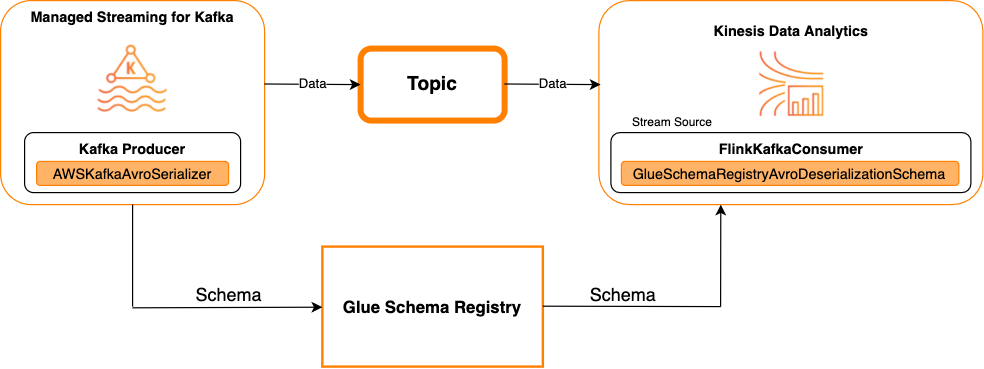
Kafka en tant que récepteur
Le diagramme suivant illustre l'intégration de Kinesis Data Streams Kinesis à Service géré pour Apache Flink pour Apache Flink, avec Kafka en tant que collecteur.
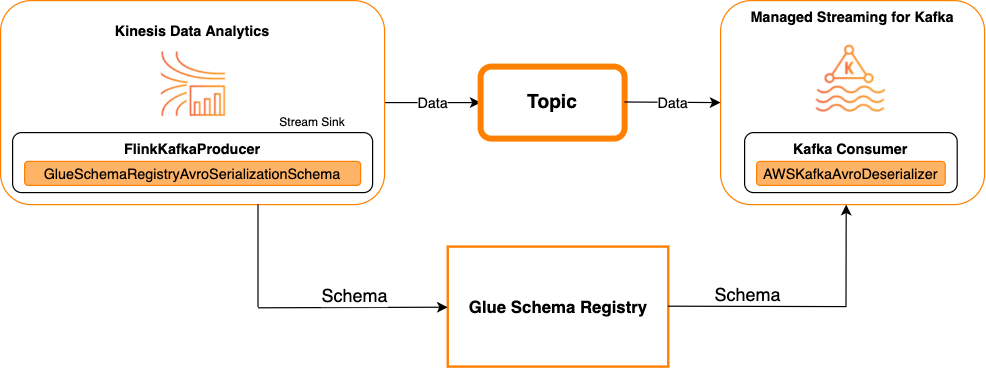
Pour intégrer Kafka (ou Amazon MSK) à Service géré pour Apache Flink pour Apache Flink, avec Kafka comme source ou Kafka comme collecteur, apportez les modifications de code ci-dessous. Ajoutez les blocs de code en gras à votre code respectif dans les sections analogues.
Si Kafka est la source, utilisez le code de désérialiseur (bloc 2). Si Kafka est le récepteur, utilisez le code de sérialiseur (bloc 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String topic = "topic"; Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "test"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKafkaConsumer<GenericRecord> consumer = new FlinkKafkaConsumer<>( topic, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKafkaProducer<GenericRecord> producer = new FlinkKafkaProducer<>( topic, // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Intégration de Kinesis Data Streams à Apache Flink
Vous pouvez utiliser Service géré pour Apache Flink pour Apache Flink, avec Data Streams comme source ou comme collecteur.
Kinesis Data Streams en tant que source
Le diagramme suivant illustre l'intégration de Kinesis Data Streams Kinesis à Service géré pour Apache Flink pour Apache Flink, avec Kinesis Data Streams en tant que source.
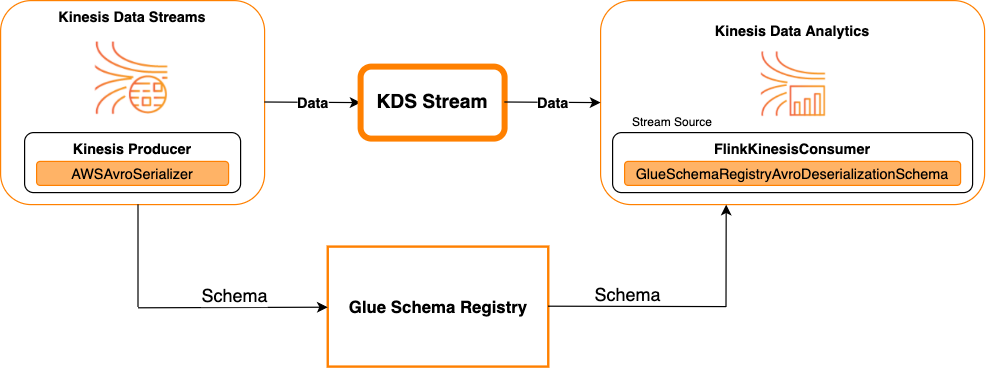
Kinesis Data Streams en tant que récepteur
Le diagramme suivant illustre l'intégration de Kinesis Data Streams Kinesis à Service géré pour Apache Flink pour Apache Flink, avec Kinesis Data Streams en tant que collecteur.
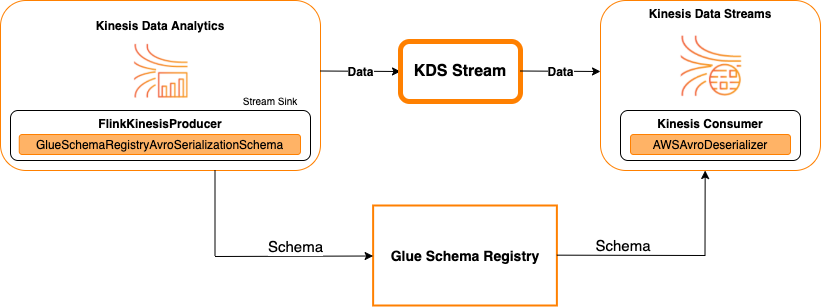
Pour intégrer Kinesis Data Streams à Service géré pour Apache Flink pour Apache Flink, avec Kinesis Data Streams en tant que source ou Kinesis Data Streams en tant que collecteur, apportez les modifications de code ci-dessous. Ajoutez les blocs de code en gras à votre code respectif dans les sections analogues.
Si Kinesis Data Streams est la source, utilisez le code de désérialiseur (bloc 2). Si Kinesis Data Streams est le récepteur, utilisez le code de sérialiseur (bloc 3).
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); String streamName = "stream"; Properties consumerConfig = new Properties(); consumerConfig.put(AWSConfigConstants.AWS_REGION, "aws-region"); consumerConfig.put(AWSConfigConstants.AWS_ACCESS_KEY_ID, "aws_access_key_id"); consumerConfig.put(AWSConfigConstants.AWS_SECRET_ACCESS_KEY, "aws_secret_access_key"); consumerConfig.put(ConsumerConfigConstants.STREAM_INITIAL_POSITION, "LATEST"); // block 1 Map<String, Object> configs = new HashMap<>(); configs.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); configs.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); configs.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); FlinkKinesisConsumer<GenericRecord> consumer = new FlinkKinesisConsumer<>( streamName, // block 2 GlueSchemaRegistryAvroDeserializationSchema.forGeneric(schema, configs), properties); FlinkKinesisProducer<GenericRecord> producer = new FlinkKinesisProducer<>( // block 3 GlueSchemaRegistryAvroSerializationSchema.forGeneric(schema, topic, configs), properties); producer.setDefaultStream(streamName); producer.setDefaultPartition("0"); DataStream<GenericRecord> stream = env.addSource(consumer); stream.addSink(producer); env.execute();
Cas d'utilisation : intégration avec AWS Lambda
Cas d'utilisation : AWS Glue Data Catalog
Les tables AWS Glue prennent en charge des schémas que vous pouvez spécifier manuellement ou par référence au registre de schémas AWS Glue. Le registre de schéma s'intègre au catalogue de données pour vous permettre d'utiliser en option des schémas stockés dans le registre de schémas lors de la création ou de la mise à jour de tables AWS Glue ou partitions dans le catalogue de données. Pour identifier une définition de schéma dans le registre de schémas, vous devez au minimum connaître l'ARN du schéma dont il fait partie. Une version de schéma d'un schéma, qui contient une définition de schéma, peut être référencée par son UUID ou son numéro de version. Il y a toujours une version de schéma, la « dernière » version, qui peut être recherchée sans connaître son numéro de version ou son UUID.
Lors de l'appel des opérations CreateTable ou UpdateTable, vous transmettrez une structure TableInput qui contient un StorageDescriptor, qui peut avoir une SchemaReference à un schéma existant dans le registre de schémas. De même, lorsque vous appelez le GetTable ou GetPartition APIs, la réponse peut contenir le schéma et leSchemaReference. Lorsqu'une table ou une partition a été créée à l'aide de références de schéma, le catalogue de données tente d'extraire le schéma pour cette référence de schéma. Dans le cas où il ne parvient pas à trouver le schéma dans le registre de schémas, il renvoie un schéma vide dans la réponse GetTable ; sinon la réponse aura à la fois le schéma et la référence du schéma.
Vous pouvez aussi effectuer les actions depuis la console AWS Glue.
Pour effectuer ces opérations et créer, mettre à jour ou afficher les informations de schéma, vous devez accorder un rôle IAM à l'appelant qui fournit les autorisations pour l'API GetSchemaVersion.
Ajout d'une table ou mise à jour du schéma pour une table
L'ajout d'une nouvelle table à partir d'un schéma existant lie la table à une version de schéma spécifique. Une fois que les nouvelles versions de schéma sont enregistrées, vous pouvez mettre à jour cette définition de table à partir de la page Affichage de la table dans la console AWS Glue ou à l'aide de l'API UpdateTable action (Python : update_table).
Ajout d'une table à partir d'un schéma existant
Vous pouvez créer une table AWS Glue à partir d'une version de schéma dans le registre à l'aide de la console AWS Glue ou de l'API CreateTable.
API AWS Glue
Lors de l'appel de l'API CreateTable, vous transmettrez une TableInput qui contient un StorageDescriptor, qui a une SchemaReference à un schéma existant dans le registre de schémas.
Console AWS Glue
Pour créer une table à partir de la console AWS Glue :
-
Connectez-vous à la AWS Glue console AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/glue/
. Dans le panneau de navigation, sous Data catalog (Catalogue de données), choisissez Tables.
Dans le menu Add tables (Ajouter des tables), choisissez Add table from existing schema (Ajouter une table à partir d'un schéma existant).
Configurez les propriétés de la table et le magasin de données selon le Guide du développeur AWS Glue.
Sur la page Choisir un schéma de Glue, sélectionnez le registre où réside le schéma.
Choisissez le nom du schéma et sélectionnez la version du schéma à appliquer.
Passez en revue la prévisualisation du schéma, puis choisissez Next (Suivant).
Vérifiez et créez la table.
Le schéma et la version appliqués à la table s'affichent dans la colonne Glue schema (Schéma Glue) dans la liste des tables. Vous pouvez afficher le tableau pour voir plus de détails.
Mise à jour du schéma pour une table
Lorsqu'une nouvelle version de schéma devient disponible, vous pouvez mettre à jour le schéma d'une table à l'aide de l'API UpdateTable action (Python : update_table) ou de la console AWS Glue.
Important
Lors de la mise à jour du schéma d'une table existante dotée d'un schéma AWS Glue spécifié manuellement, le nouveau schéma référencé dans le registre de schémas peut être incompatible. Cela peut entraîner l'échec de vos tâches.
API AWS Glue
Lors de l'appel de l'API UpdateTable, vous transmettrez une TableInput qui contient un StorageDescriptor, qui a une SchemaReference à un schéma existant dans le registre de schémas.
Console AWS Glue
Pour mettre à jour le schéma pour une table à partir de la console AWS Glue :
-
Connectez-vous à la AWS Glue console AWS Management Console et ouvrez-la à l'adresse https://console.aws.amazon.com/glue/
. Dans le panneau de navigation, sous Data catalog (Catalogue de données), choisissez Tables.
Affichez la table à partir de la liste des tables.
Cliquez sur Update schema (Mettre à jour le schéma) dans la zone qui vous informe d'une nouvelle version.
Examinez les différences entre le schéma actuel et le nouveau.
Choisissez Show all schema differences (Afficher toutes les différences du schéma) pour plus de détails.
Choisissez Save table (Enregistrer la table) pour accepter la nouvelle version.
Cas d'utilisation : streaming AWS Glue
Le streaming AWS Glue consomme des données provenant de sources de streaming et effectue des opérations d'ETL avant d'écrire dans un récepteur de sortie. La source de streaming d'entrée peut être spécifiée à l'aide d'une table de données ou directement en spécifiant la configuration de la source.
Le streaming AWS Glue prend en charge une table de catalogue de données pour la source de streaming créée avec le schéma présent dans le registre de schémas AWS Glue. Vous pouvez créer un schéma dans le registre de schémas AWS Glue et créer une table AWS Glue avec une source de streaming utilisant ce schéma. Cette table AWS Glue peut être utilisée comme entrée dans une tâche de streaming AWS Glue pour désérialiser les données dans le flux d'entrée.
Remarque : lorsque le schéma du registre de schémas AWS Glue change, vous devez redémarrer la tâche de streaming AWS Glue afin de refléter les modifications dans le schéma.
Cas d'utilisation : Apache Kafka Streams
L'API Apache Kafka Streams est une bibliothèque client pour le traitement et l'analyse des données stockées dans Apache Kafka. Cette section décrit l'intégration d'Apache Kafka Streams au registre de schémas AWS Glue, qui vous permet de gérer et d'appliquer des schémas sur vos applications de streaming de données. Pour de plus amples informations sur Apache Kafka Streams, veuillez consulter Apache Kafka Streams
Intégration aux SerDes bibliothèques
Il existe une classe GlueSchemaRegistryKafkaStreamsSerde avec laquelle vous pouvez configurer une application Streams.
Exemple de code d'application Kafka Streams
Pour utiliser le registre de schémas AWS Glue dans une application Apache Kafka Streams :
Configurez l'application Kafka Streams.
final Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "avro-streams"); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, AWSKafkaAvroSerDe.class.getName()); props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); props.put(AWSSchemaRegistryConstants.AWS_REGION, "aws-region"); props.put(AWSSchemaRegistryConstants.SCHEMA_AUTO_REGISTRATION_SETTING, true); props.put(AWSSchemaRegistryConstants.AVRO_RECORD_TYPE, AvroRecordType.GENERIC_RECORD.getName()); props.put(AWSSchemaRegistryConstants.DATA_FORMAT, DataFormat.AVRO.name());Créez un flux à partir de la rubrique avro-input.
StreamsBuilder builder = new StreamsBuilder(); final KStream<String, GenericRecord> source = builder.stream("avro-input");Traitez les enregistrements de données (l'exemple filtre les enregistrements dont la valeur de favorite_color (couleur favorite) est pink (rose) ou dont la valeur de amount (montant) est 15).
final KStream<String, GenericRecord> result = source .filter((key, value) -> !"pink".equals(String.valueOf(value.get("favorite_color")))); .filter((key, value) -> !"15.0".equals(String.valueOf(value.get("amount"))));Réécrivez les résultats dans la rubrique avro-output.
result.to("avro-output");Démarrez l'application Apache Kafka Streams.
KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
Résultats de l'implémentation
Ces résultats montrent le processus de filtrage des enregistrements qui ont été filtrés à l'étape 3 sous la forme d'une valeur favorite_color (couleur favorite) « pink » (rose) ou d'une valeur de « 15.0 ».
Enregistrements avant le filtrage :
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"name": "Jay", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105} {"id": "commute_1","amount": 15}
Enregistrements après filtrage :
{"name": "Sansa", "favorite_number": 99, "favorite_color": "white"} {"name": "Harry", "favorite_number": 10, "favorite_color": "black"} {"name": "Hermione", "favorite_number": 1, "favorite_color": "red"} {"name": "Ron", "favorite_number": 0, "favorite_color": "pink"} {"id": "commute_1","amount": 3.5} {"id": "grocery_1","amount": 25.5} {"id": "entertainment_1","amount": 19.2} {"id": "entertainment_2","amount": 105}
Cas d'utilisation : Apache Kafka Connect
L'intégration d'Apache Kafka Connect au registre de schémas AWS Glue vous permet d'obtenir des informations de schéma à partir des connecteurs. Les convertisseurs Apache Kafka spécifient le format des données dans Apache Kafka et comment les traduire en données Apache Kafka Connect. Chaque utilisateur d'Apache Kafka Connect devra configurer ces convertisseurs en fonction du format souhaité pour leurs données lorsqu'elles sont chargées depuis ou stockés dans Apache Kafka. De cette façon, vous pouvez définir vos propres convertisseurs pour traduire les données Apache Kafka Connect dans le type utilisé dans le registre de schémas AWS Glue (par exemple : Avro) et utiliser notre sérialiseur pour enregistrer son schéma et effectuer la sérialisation. Ensuite, les convertisseurs peuvent également utiliser notre désérialiseur pour désérialiser les données reçues d'Apache Kafka et les convertir en données Apache Kafka Connect. Un exemple de diagramme de flux de travail est présenté ci-dessous.
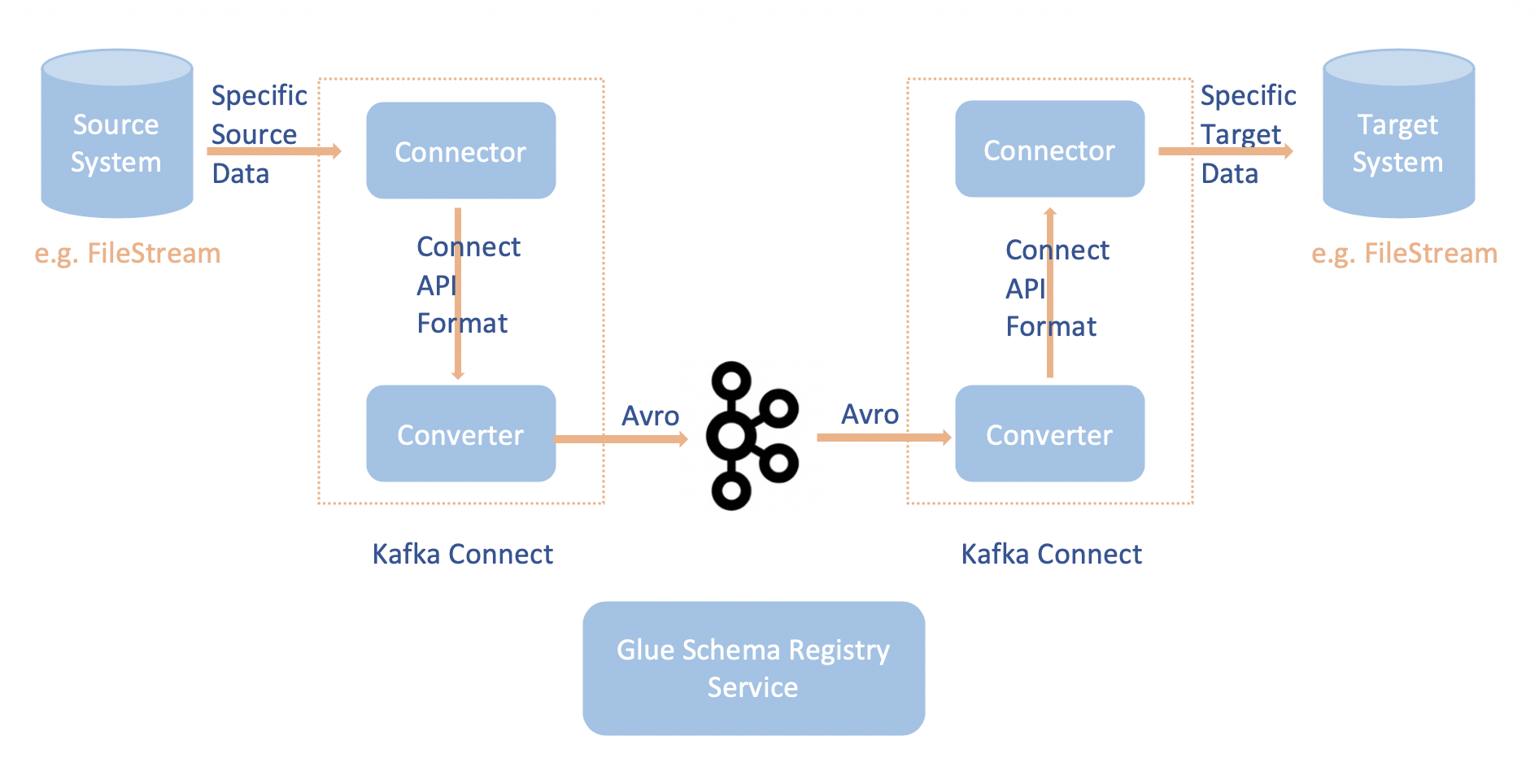
Installez le projet
aws-glue-schema-registryen clonant le référentiel Github pour le registre de schémas AWS Glue. git clone git@github.com:awslabs/aws-glue-schema-registry.git cd aws-glue-schema-registry mvn clean install mvn dependency:copy-dependenciesSi vous prévoyez d'utiliser Apache Kafka Connect en mode autonome, mettez à jour connect-standalone.properties à l'aide des instructions suivantes pour cette étape. Si vous prévoyez d'utiliser Apache Kafka Connect en mode distribué, mettez à jour le connect-avro-distributedfichier .properties en suivant les mêmes instructions.
Ajoutez également ces propriétés au fichier de propriétés de connexion Apache Kafka :
key.converter.region=aws-regionvalue.converter.region=aws-regionkey.converter.schemaAutoRegistrationEnabled=true value.converter.schemaAutoRegistrationEnabled=true key.converter.avroRecordType=GENERIC_RECORD value.converter.avroRecordType=GENERIC_RECORDAjoutez la commande ci-dessous à la section Mode de lancement sous kafka-run-class.sh :
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"
Ajoutez la commande ci-dessous à la section Mode de lancement sous kafka-run-class.sh
-cp $CLASSPATH:"<your AWS GlueSchema Registry base directory>/target/dependency/*"Elle doit ressembler à ce qui suit :
# Launch mode if [ "x$DAEMON_MODE" = "xtrue" ]; then nohup "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" 2>&1 < /dev/null & else exec "$JAVA" $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH:"/Users/johndoe/aws-glue-schema-registry/target/dependency/*" $KAFKA_OPTS "$@" fiSi vous utilisez bash, exécutez les commandes ci-dessous pour configurer votre CLASSPATH dans votre bash_profile. Pour tout autre shell, mettez à jour l'environnement en conséquence.
echo 'export GSR_LIB_BASE_DIR=<>' >>~/.bash_profile echo 'export GSR_LIB_VERSION=1.0.0' >>~/.bash_profile echo 'export KAFKA_HOME=<your Apache Kafka installation directory>' >>~/.bash_profile echo 'export CLASSPATH=$CLASSPATH:$GSR_LIB_BASE_DIR/avro-kafkaconnect-converter/target/schema-registry-kafkaconnect-converter-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/common/target/schema-registry-common-$GSR_LIB_VERSION.jar:$GSR_LIB_BASE_DIR/avro-serializer-deserializer/target/schema-registry-serde-$GSR_LIB_VERSION.jar' >>~/.bash_profile source ~/.bash_profile(Facultatif) Si vous souhaitez tester avec une source de fichier simple, clonez le connecteur de source de fichier.
git clone https://github.com/mmolimar/kafka-connect-fs.git cd kafka-connect-fs/Sous la configuration du connecteur source, modifiez le format de données sur Avro, le lecteur de fichiers sur
AvroFileReaderet mettez à jour un exemple d'objet Avro à partir du chemin d'accès du fichier à partir duquel vous lisez. Par exemple :vim config/kafka-connect-fs.propertiesfs.uris=<path to a sample avro object> policy.regexp=^.*\.avro$ file_reader.class=com.github.mmolimar.kafka.connect.fs.file.reader.AvroFileReaderInstallez le connecteur source.
mvn clean package echo "export CLASSPATH=\$CLASSPATH:\"\$(find target/ -type f -name '*.jar'| grep '\-package' | tr '\n' ':')\"" >>~/.bash_profile source ~/.bash_profileMettez à jour les propriétés du récepteur sous
<your Apache Kafka installation directory>/config/connect-file-sink.propertiesfile=<output file full path> topics=<my topic>
Démarrez le connecteur source (dans cet exemple, il s'agit d'un connecteur source de fichier).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties config/kafka-connect-fs.propertiesExécutez le connecteur du récepteur (dans cet exemple, il s'agit d'un connecteur de récepteur de fichiers).
$KAFKA_HOME/bin/connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-sink.propertiesPour un exemple d'utilisation de Kafka Connect, regardez le script run-local-tests .sh situé dans le dossier integration-tests du référentiel Github
pour le registre des schémas. AWS Glue
