Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cycle de vie des incidents dans Incident Manager
AWS Systems Manager Incident Manager fournit un step-by-step cadre basé sur les meilleures pratiques pour identifier et réagir aux incidents, tels que les pannes de service ou les menaces de sécurité. L'objectif principal d'Incident Manager est d'aider à rétablir les services ou applications concernés à la normale le plus rapidement possible grâce à une solution complète de gestion du cycle de vie des incidents.
Comme illustré dans l'illustration suivante, Incident Manager fournit des outils et des meilleures pratiques pour chaque phase du cycle de vie des incidents :
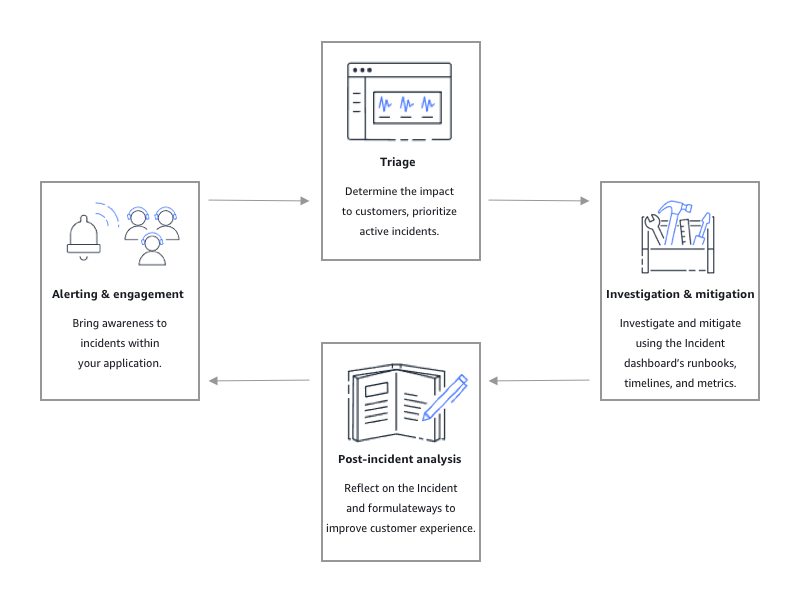
Alertes et engagement
La phase d'alerte et d'engagement du cycle de vie des incidents vise à sensibiliser vos applications et services aux incidents. Cette phase commence avant qu'un incident ne soit détecté et nécessite une compréhension approfondie de vos applications. Vous pouvez utiliser CloudWatchles métriques Amazon pour surveiller les données relatives aux performances de vos applications, ou utiliser Amazon EventBridge pour agréger les alertes provenant de différentes sources, applications et services. Une fois que vous avez configuré la surveillance de vos applications, vous pouvez commencer à émettre des alertes sur les indicateurs qui s'écartent de la norme historique. Pour en savoir plus sur les meilleures pratiques en matière de surveillance, voirSurveillance.
Pour aider les intervenants à diagnostiquer les incidents, vous pouvez activer la fonctionnalité Résultats dans Incident Manager. Les résultats sont des informations sur AWS CodeDeploy les déploiements et les mises à jour de AWS CloudFormation stack survenus au moment d'un incident. Le fait de disposer de ces informations réduit le temps nécessaire pour évaluer les causes potentielles, ce qui peut réduire le temps moyen de rétablissement (MTTR) après un incident.
Maintenant que vous surveillez les incidents dans vos applications, vous pouvez définir un plan de réponse aux incidents à utiliser lors d'un incident. Pour en savoir plus sur la création de plans d'intervention, voirCréation et configuration de plans de réponse dans Incident Manager. Amazon EventBridge Events or CloudWatch Alarms peut créer automatiquement un incident en utilisant des plans de réponse comme modèle. Pour en savoir plus sur la création d'incidents, voirCréation d'incidents automatiquement ou manuellement dans Incident Manager.
Les plans d'intervention lancent des plans d'escalade et des plans d'engagement connexes pour impliquer les premiers intervenants dans l'incident. Pour plus d'informations sur la configuration de plans d'escalade, consultezCréation d'un plan d'escalade. Simultanément, Amazon Q Developer dans les applications de chat avertit les intervenants via un canal de discussion les dirigeant vers la page détaillée de l'incident. À l'aide du canal de discussion et des détails de l'incident, l'équipe peut communiquer et trier un incident. Pour plus d'informations sur la configuration des canaux de discussion dans Incident Manager, consultezTâche 2 : créer un canal de discussion dans Amazon Q Developer dans les applications de chat.
Tri
Le triage est le moment où les premiers intervenants tentent de déterminer l'impact sur les clients. La vue détaillée de l'incident dans la console Incident Manager fournit aux intervenants des chronologies et des mesures pour les aider à évaluer l'incident. L'évaluation de l'impact d'un incident jette également les bases du temps de réponse, de résolution et de communication en cas d'incident. Les intervenants hiérarchisent les incidents en utilisant des cotes d'impact comprises entre 1 (critique) et 5 (aucun impact).
Votre organisation peut définir la portée exacte de chaque évaluation d'impact comme bon vous semble. Le tableau suivant fournit des exemples de la manière dont chaque niveau d'impact peut généralement être défini.
| Code d'impact | Nom de l'impact | Exemple de portée définie |
|---|---|---|
1 |
Critical |
Défaillance complète de l'application qui a un impact sur la plupart des clients. |
2 |
High |
Défaillance complète de l'application ayant un impact sur un sous-ensemble de clients. |
3 |
Medium |
Défaillance partielle de l'application ayant un impact sur le client. |
4 |
Low |
Pannes intermittentes ayant un impact limité sur les clients. |
5 |
No Impact |
Les clients ne sont actuellement pas concernés, mais des mesures urgentes sont nécessaires pour éviter tout impact. |
Enquête et atténuation
La vue détaillée de l'incident fournit à votre équipe des runbooks, des chronologies et des indicateurs. Pour savoir comment gérer un incident, consultez leAfficher les détails de l'incident dans la console.
Les runbooks fournissent généralement des étapes d'investigation et peuvent automatiquement extraire des données ou essayer des solutions couramment utilisées. Les Runbooks fournissent également des étapes claires et répétables que votre équipe a jugées utiles pour atténuer les incidents. L'onglet runbook se concentre sur l'étape actuelle du runbook et affiche les étapes passées et futures.
Incident Manager s'intègre à Systems Manager Automation pour créer des runbooks. Utilisez runbooks pour effectuer l'une des opérations suivantes :
-
Gérer les instances et les AWS ressources
-
Exécuter automatiquement des scripts
-
Gérez les AWS CloudFormation ressources
Pour plus d'informations sur les types d'actions pris en charge, consultez la référence des actions d'automatisation de Systems Manager dans le guide de AWS Systems Manager l'utilisateur.
L'onglet Chronologie indique les actions entreprises. La chronologie enregistre chacune avec un horodatage et des détails créés automatiquement. Pour ajouter des événements personnalisés à la chronologie, consultez la Chronologie section de la page de détails de l'incident de ce guide de l'utilisateur.
L'onglet Diagnostic affiche les métriques renseignées automatiquement et les métriques ajoutées manuellement. Cette vue fournit des informations précieuses sur les activités de votre application lors d'un incident.
L'onglet Engagements vous permet d'ajouter des contacts supplémentaires à l'incident et de fournir les ressources nécessaires pour que le contact engagé soit rapidement mis au courant une fois impliqué dans l'incident. Les contacts sont engagés par le biais de plans d'escalade définis ou de plans d'engagement personnels.
À l'aide d'un canal de discussion, vous pouvez interagir directement avec votre incident et avec les autres intervenants de votre équipe. En utilisant Amazon Q Developer dans les applications de chat, vous pouvez configurer des canaux de discussion dans. Slack, Microsoft Teams, et Amazon Chime. Entrée Slack and Microsoft Teams canaux, les intervenants peuvent interagir avec les incidents directement depuis le canal de discussion à l'aide d'un certain nombre de ssm-incidents commandes. Pour de plus amples informations, veuillez consulter Interaction via le canal de discussion.
Analyse post-incident
Incident Manager fournit un cadre permettant de réfléchir à un incident, de prendre les mesures nécessaires pour empêcher que l'incident ne se reproduise à l'avenir et d'améliorer les activités de réponse aux incidents dans leur ensemble. Les améliorations peuvent inclure :
-
Modifications apportées aux applications impliquées dans un incident. Votre équipe peut utiliser ce temps pour améliorer le système et le rendre plus tolérant aux pannes.
-
Modifications apportées à un plan de réponse aux incidents. Prenez le temps d'intégrer les leçons apprises.
-
Modifications apportées aux runbooks. Votre équipe peut étudier en profondeur les étapes nécessaires à la résolution et les étapes que vous pouvez automatiser.
-
Modifications apportées aux alertes. Après un incident, votre équipe a peut-être remarqué des points critiques dans les indicateurs que vous pouvez utiliser pour alerter l'équipe plus rapidement en cas d'incident.
Incident Manager facilite ces améliorations potentielles en utilisant un ensemble de questions d'analyse post-incident et d'éléments d'action associés à la chronologie de l'incident. Pour en savoir plus sur l'amélioration par l'analyse, voirPerforming a post-incident analysis in Incident Manager.
