Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'un flux de travail
Avant de commencer, assurez-vous d'avoir accordé au rôle les autorisations de données et les autorisations de localisation des données requisesLakeFormationWorkflowRole. Le flux de travail peut ainsi créer des tables de métadonnées dans le catalogue de données et écrire des données vers des emplacements cibles dans Amazon S3. Pour plus d’informations, consultez (Facultatif) Créez un rôle IAM pour les flux de travail et Vue d'ensemble des autorisations relatives à Lake Formation .
Note
Lake Formation utilise GetTemplateInstanceGetTemplateInstances, et effectue des InstantiateTemplate opérations pour créer des flux de travail à partir de plans. Ces opérations ne sont pas accessibles au public et ne sont utilisées qu'en interne pour créer des ressources en votre nom. Vous recevez des CloudTrail événements pour créer des flux de travail.
Pour créer un flux de travail à partir d'un plan
-
Ouvrez la AWS Lake Formation console à l'adresse https://console.aws.amazon.com/lakeformation/
. Connectez-vous en tant qu'administrateur du lac de données ou en tant qu'utilisateur disposant d'autorisations d'ingénieur de données. Pour de plus amples informations, veuillez consulter Référence des personnalités de Lake Formation et des autorisations IAM. -
Dans le volet de navigation, choisissez Blueprints, puis choisissez Use Blueprint.
-
Sur la page Utiliser un plan, choisissez une vignette pour sélectionner le type de plan.
-
Sous Source d'importation, spécifiez la source de données.
Si vous effectuez une importation à partir d'une source JDBC, spécifiez les éléments suivants :
-
Connexion à la base de données —Choisissez une connexion dans la liste. Créez des connexions supplémentaires à l'aide de la AWS Glue console. Le nom d'utilisateur et le mot de passe JDBC de la connexion déterminent les objets de base de données auxquels le flux de travail a accès.
-
Chemin des données source : entrez
<database>/<schema>/<table>ou<database>/<table>, selon le produit de base de données. Oracle Database et MySQL ne prennent pas en charge le schéma dans le chemin. Vous pouvez remplacer le pourcentage (%) par<schema>ou<table>. Par exemple, pour une base de données Oracle dont l'identifiant système (SID) est égalorcl/%àorcl, entrez pour importer toutes les tables auxquelles l'utilisateur nommé dans la connexion a accès.Important
Ce champ distingue les majuscules et minuscules. Le flux de travail échouera s'il existe une incompatibilité majuscules/minuscules pour l'un des composants.
Si vous spécifiez une base de données MySQL, AWS Glue ETL utilise le pilote JDBC Mysql5 par défaut, donc My SQL8 n'est pas pris en charge nativement. Vous pouvez modifier le script de tâche ETL pour utiliser un
customJdbcDriverS3Pathparamètre tel que décrit dans la section JDBC ConnectionType Values du manuel du AWS Glue développeur afin d'utiliser un autre pilote JDBC compatible avec My. SQL8
Si vous effectuez une importation à partir d'un fichier journal, assurez-vous que le rôle que vous spécifiez pour le flux de travail (le « rôle de flux de travail ») dispose des autorisations IAM requises pour accéder à la source de données. Par exemple, pour importer AWS CloudTrail des journaux, l'utilisateur doit disposer des
cloudtrail:LookupEventsautorisationscloudtrail:DescribeTrailset pour consulter la liste des CloudTrail journaux lors de la création du flux de travail, et le rôle du flux de travail doit disposer d'autorisations sur l' CloudTrail emplacement dans Amazon S3. -
-
Effectuez l’une des actions suivantes :
-
Pour le type de plan instantané de base de données, identifiez éventuellement un sous-ensemble de données à importer en spécifiant un ou plusieurs modèles d'exclusion. Ces modèles d'exclusion sont des modèles de style Unix.
globIls sont stockés en tant que propriété des tables créées par le flux de travail.Pour plus de détails sur les modèles d'exclusion disponibles, consultez la section Include et d'exclusion des modèles dans le manuel du AWS Glue développeur.
-
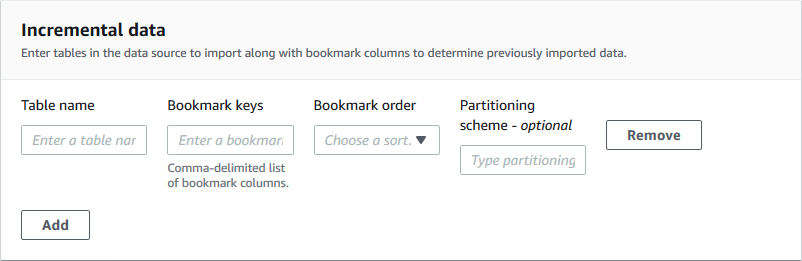
Pour le type de plan de base de données incrémentiel, spécifiez les champs suivants. Ajoutez une ligne pour chaque table à importer.
- Nom de la table
-
Tableau à importer. Tout doit être en minuscules.
- Clés de signet
-
Liste de noms de colonnes séparés par des virgules qui définissent les clés des signets. Si ce champ est vide, la clé primaire est utilisée pour déterminer les nouvelles données. Le cas de chaque colonne doit correspondre au cas défini dans la source de données.
Note
La clé primaire est considérée comme la clé de signet par défaut uniquement si elle augmente ou diminue de manière séquentielle (sans interruption). Si vous souhaitez utiliser la clé primaire comme clé de signet et qu'elle comporte des lacunes, vous devez nommer la colonne de clé primaire comme clé de signet.
- Marquer la commande
-
Lorsque vous choisissez Ascending, les lignes dont les valeurs sont supérieures aux valeurs enregistrées dans les favoris sont identifiées comme de nouvelles lignes. Lorsque vous choisissez Décroissant, les lignes dont les valeurs sont inférieures aux valeurs enregistrées dans les favoris sont identifiées comme de nouvelles lignes.
- Schéma de partitionnement
-
(Facultatif) Liste des colonnes clés de partitionnement, délimitées par des barres obliques (/). Exemple :
year/month/day.
Pour plus d'informations, consultez la section Suivi des données traitées à l'aide des signets de tâches dans le Guide du AWS Glue développeur.
-
-
Sous Cible d'importation, spécifiez la base de données cible, l'emplacement Amazon S3 cible et le format des données.
Assurez-vous que le rôle de flux de travail dispose des autorisations Lake Formation requises sur la base de données et sur l'emplacement cible Amazon S3.
Note
À l'heure actuelle, les plans ne prennent pas en charge le chiffrement des données sur la cible.
-
Choisissez une fréquence d'importation.
Vous pouvez spécifier une
cronexpression à l'aide de l'option Personnalisée. -
Sous Options d'importation :
-
Entrez un nom de flux de travail.
-
Pour rôle, choisissez le rôle
LakeFormationWorkflowRoleque vous avez créé dans(Facultatif) Créez un rôle IAM pour les flux de travail. -
Spécifiez éventuellement un préfixe de table. Le préfixe est ajouté aux noms des tables du catalogue de données créées par le flux de travail.
-
-
Choisissez Créer et attendez que la console indique que le flux de travail a été créé avec succès.
Astuce
Avez-vous reçu le message d'erreur suivant ?
User: arn:aws:iam::<account-id>:user/<username>is not authorized to perform: iam:PassRole on resource:arn:aws:iam::<account-id>:role/<rolename>...Si tel est le cas, vérifiez que vous l'avez
<account-id>remplacé par un numéro de AWS compte valide dans toutes les polices.
Voir aussi :
