Avis de fin de support : le 31 octobre 2025, le support d'Amazon Lookout for Vision AWS sera interrompu. Après le 31 octobre 2025, vous ne pourrez plus accéder à la console Lookout for Vision ni aux ressources Lookout for Vision. Pour plus d'informations, consultez ce billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comprendre Amazon Lookout for Vision
Vous pouvez utiliser Amazon Lookout for Vision pour détecter les défauts visuels des produits industriels, avec précision et à grande échelle, pour des tâches telles que :
-
Détection des pièces endommagées : repérez les dommages causés à la qualité de surface, à la couleur et à la forme d'un produit pendant le processus de fabrication et d'assemblage.
-
Identification des composants manquants : déterminez les composants manquants en fonction de l'absence, de la présence ou de l'emplacement des objets. Par exemple, un condensateur manquant sur une carte de circuit imprimé.
-
Découverte des problèmes liés au processus — Détectez les défauts présentant des motifs répétitifs, tels que des rayures répétées au même endroit sur une plaquette de silicone.
Lookout for Vision vous permet de créer un modèle de vision par ordinateur qui prédit la présence d'anomalies dans une image. Vous fournissez les images qu'Amazon Lookout for Vision utilise pour entraîner et tester votre modèle. Amazon Lookout for Vision fournit des indicateurs que vous pouvez utiliser pour évaluer et améliorer votre modèle entraîné. Vous pouvez héberger le modèle entraîné dans le AWS cloud ou le déployer sur un appareil périphérique. Une simple opération d'API renvoie les prédictions effectuées par votre modèle.
Le flux de travail général pour créer, évaluer et utiliser un modèle est le suivant :
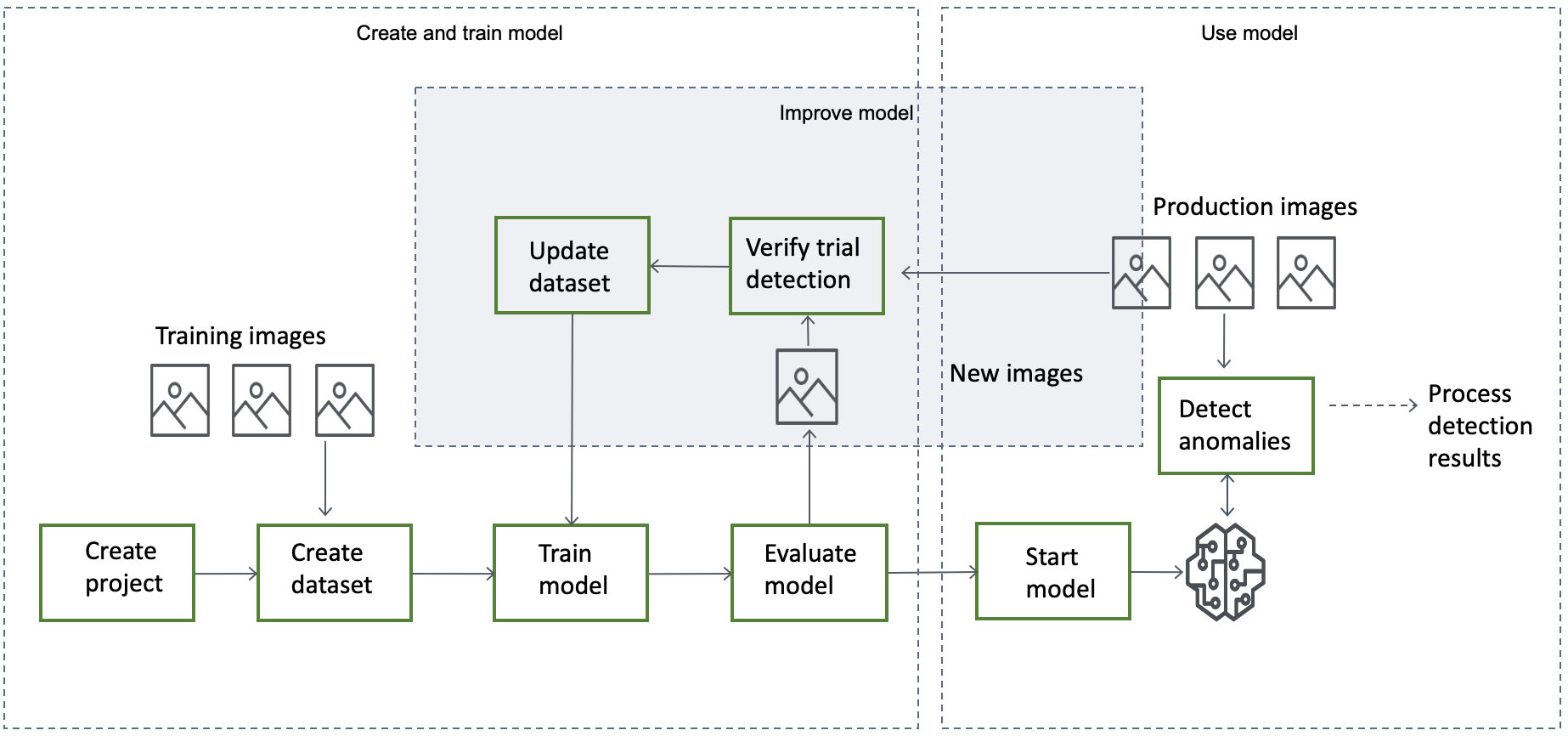
Rubriques
Choisissez votre type de modèle
Avant de créer un modèle, vous devez choisir le type de modèle que vous souhaitez. Vous pouvez créer deux types de modèles : la classification des images et la segmentation des images. Vous décidez du type de modèle à créer en fonction de votre cas d'utilisation.
Modèle de classification d'images
Si vous avez uniquement besoin de savoir si une image contient une anomalie, mais pas de connaître son emplacement, créez un modèle de classification d'images. Un modèle de classification d'images permet de prédire si une image contient une anomalie. La prédiction inclut la confiance du modèle dans la précision de la prédiction. Le modèle ne fournit aucune information sur l'emplacement des anomalies détectées sur l'image.
Modèle de segmentation d'image
Si vous avez besoin de connaître l'emplacement d'une anomalie, par exemple l'emplacement d'une rayure, créez un modèle de segmentation d'image. Les modèles Amazon Lookout for Vision utilisent la segmentation sémantique pour identifier les pixels d'une image présentant les types d'anomalies (comme une rayure ou une partie manquante).
Note
Un modèle de segmentation sémantique permet de localiser différents types d'anomalies. Il ne fournit pas d'informations d'instance pour les anomalies individuelles. Par exemple, si une image contient deux bosses, Lookout for Vision renvoie des informations sur les deux bosses dans une seule entité représentant le type d'anomalie de bosse.
Un modèle de segmentation Amazon Lookout for Vision prédit ce qui suit :
Classification
Le modèle renvoie une classification pour une image analysée (normale/anomalie), qui inclut la confiance du modèle dans la prédiction. Les informations de classification sont calculées séparément des informations de segmentation et vous ne devez pas supposer qu'il existe une relation entre elles.
Segmentation
Le modèle renvoie un masque d'image qui marque les pixels où des anomalies apparaissent sur l'image. Les différents types d'anomalies sont codés par couleur en fonction de la couleur attribuée à l'étiquette d'anomalie dans le jeu de données. Une étiquette d'anomalie représente le type d'anomalie. Par exemple, le masque bleu de l'image suivante indique l'emplacement d'une anomalie de rayure détectée sur une voiture.

Le modèle renvoie le code couleur pour chaque étiquette d'anomalie du masque. Le modèle renvoie également le pourcentage de couverture de l'image que possède une étiquette d'anomalie.
Avec un modèle de segmentation Lookout for Vision, vous pouvez utiliser différents critères pour analyser les résultats d'analyse du modèle. Par exemple :
-
Localisation des anomalies : si vous avez besoin de connaître l'emplacement des anomalies, utilisez les informations de segmentation pour voir les masques qui masquent les anomalies.
-
Types d'anomalies : utilisez les informations de segmentation pour déterminer si une image contient plus qu'un nombre acceptable de types d'anomalies.
-
Zone de couverture : utilisez les informations de segmentation pour déterminer si un type d'anomalie couvre plus qu'une zone acceptable d'une image.
-
Classification des images : si vous n'avez pas besoin de connaître l'emplacement des anomalies, utilisez les informations de classification pour déterminer si une image contient des anomalies.
Pour obtenir un exemple de code, consultez Détecter des anomalies dans une image.
Après avoir choisi le type de modèle que vous souhaitez, vous créez un projet et un jeu de données pour gérer votre modèle. À l'aide des étiquettes, vous pouvez classer les images comme normales ou comme anormales. Les étiquettes identifient également les informations de segmentation telles que les masques et les types d'anomalies. La façon dont vous étiquetez les images de votre jeu de données détermine le type de modèle que Lookout for Vision crée pour vous.
L'étiquetage d'un modèle de segmentation d'image est plus complexe que l'étiquetage d'un modèle de classification d'images. Pour entraîner un modèle de segmentation, vous devez classer les images d'entraînement comme normales ou anormales. Vous devez également définir des masques d'anomalies et des types d'anomalies pour chaque image anormale. Un modèle de classification vous oblige uniquement à identifier les images d'entraînement comme normales ou anormales.
Créez votre modèle
Les étapes de création d'un modèle, à savoir la création d'un projet, la création d'un jeu de données et l'entraînement du modèle, sont les suivantes :
Création d’un projet
Créez un projet pour gérer les ensembles de données et les modèles que vous créez. Un projet doit être utilisé pour un seul cas d'utilisation, tel que la détection d'anomalies dans un seul type de pièce de machine.
Vous pouvez utiliser le tableau de bord pour avoir une vue d'ensemble de vos projets. Pour de plus amples informations, veuillez consulter Utilisation du tableau de bord Amazon Lookout for Vision.
Pour plus d'informations : Créez votre projet.
Créer un jeu de données
Pour entraîner un modèle, Amazon Lookout for Vision a besoin d'images d'objets normaux et anormaux pour votre cas d'utilisation. Vous fournissez ces images dans un jeu de données.
Un jeu de données est un ensemble d’images et d’étiquettes qui décrivent ces images. Les images doivent représenter un seul type d'objet sur lequel des anomalies peuvent apparaître. Pour de plus amples informations, veuillez consulter Préparation d'images pour un jeu de données.
Avec Amazon Lookout for Vision, vous pouvez avoir un projet utilisant un seul ensemble de données ou un projet comportant des ensembles de données d'entraînement et de test distincts. Nous vous recommandons d'utiliser un seul projet de jeu de données, sauf si vous souhaitez mieux contrôler la formation, les tests et le réglage des performances.
Vous créez un jeu de données en important les images. Selon la manière dont vous importez les images, celles-ci peuvent également être étiquetées. Dans le cas contraire, utilisez la console pour étiqueter les images.
Importation d'images
Si vous créez le jeu de données à l'aide de la console Lookout for Vision, vous pouvez importer les images de l'une des manières suivantes :
-
Importez des images depuis votre ordinateur local. Les images ne sont pas étiquetées.
-
Importez des images depuis un compartiment S3. Amazon Lookout for Vision peut classer les images à l'aide des noms de dossiers qui les contiennent. À utiliser
normalpour des images normales. À utiliseranomalypour les images anormales. Vous ne pouvez pas attribuer automatiquement des étiquettes de segmentation. -
Importez un fichier manifeste Amazon SageMaker AI Ground Truth. Les images d'un fichier manifeste sont étiquetées. Vous pouvez créer et importer votre propre fichier manifeste. Si vous avez de nombreuses images, pensez à utiliser le service d'étiquetage SageMaker AI Ground Truth. Vous importez ensuite le fichier manifeste de sortie depuis le job Amazon SageMaker AI Ground Truth.
Étiquetage des images
Les étiquettes décrivent une image dans un ensemble de données. Les étiquettes indiquent si une image est normale ou anormale (classification). Les étiquettes décrivent également l'emplacement des anomalies sur une image (segmentation).
Si vos images ne sont pas étiquetées, vous pouvez utiliser la console pour les étiqueter.
Les étiquettes que vous attribuez aux images de votre jeu de données déterminent le type de modèle créé par Lookout for Vision :
Classification d’images
Pour créer un modèle de classification d'images, utilisez la console Lookout for Vision pour classer les images du jeu de données comme normales ou comme anormales.
Vous pouvez également utiliser cette CreateDataset opération pour créer un ensemble de données à partir d'un fichier manifeste contenant des informations de classification.
Segmentation d'images
Pour créer un modèle de segmentation d'images, utilisez la console Lookout for Vision pour classer les images du jeu de données comme normales ou comme anormales. Vous spécifiez également des masques de pixels pour les zones anormales de l'image (s'ils existent) ainsi qu'une étiquette d'anomalie pour les masques d'anomalie individuels.
Vous pouvez également utiliser cette CreateDataset opération pour créer un ensemble de données à partir d'un fichier manifeste contenant des informations de segmentation et de classification.
Si votre projet comporte des ensembles de données d'entraînement et de test distincts, Lookout for Vision utilise le jeu de données d'entraînement pour apprendre et déterminer le type de modèle. Vous devez étiqueter les images de votre jeu de données de test de la même manière.
Pour plus d'informations : Création de votre jeu de données.
Entraînement de votre modèle
L'entraînement crée un modèle et l'entraîne à prévoir la présence d'anomalies dans les images. Une nouvelle version de votre modèle est créée à chaque entraînement.
Au début de la formation, Amazon Lookout for Vision choisit l'algorithme le plus approprié pour entraîner votre modèle. Le modèle est entraîné puis testé. Dans le Commencer à utiliser Amazon Lookout for Vision cas où vous entraînez un seul projet de jeu de données, le jeu de données est divisé en interne pour créer un ensemble de données d'entraînement et un ensemble de données de test. Vous pouvez également créer un projet comportant des ensembles de données d'entraînement et de test distincts. Dans cette configuration, Amazon Lookout for Vision entraîne votre modèle avec le jeu de données d'entraînement et teste le modèle avec le jeu de données de test.
Important
Le temps nécessaire pour entraîner avec succès votre modèle vous est facturé.
Pour plus d'informations : Entraînez votre modèle.
Évaluation de votre modèle
Évaluez les performances de votre modèle à l’aide des indicateurs de performance créés lors du test.
Grâce aux indicateurs de performance, vous pouvez mieux comprendre les performances de votre modèle entraîné et décider si vous êtes prêt à l'utiliser en production.
Pour plus d'informations : Améliorer votre modèle.
Si les indicateurs de performance indiquent que des améliorations sont nécessaires, vous pouvez ajouter des données d'entraînement supplémentaires en exécutant une tâche de détection d'essai avec de nouvelles images. Une fois la tâche terminée, vous pouvez vérifier les résultats et ajouter les images vérifiées à votre jeu de données d'entraînement. Vous pouvez également ajouter de nouvelles images d'entraînement directement dans le jeu de données. Ensuite, vous réentraînez votre modèle et vous revérifiez les indicateurs de performance.
Informations supplémentaires : Vérification de votre modèle à l'aide d'une tâche de détection d'essai.
Utilisez votre modèle
Avant de pouvoir utiliser votre modèle dans le AWS cloud, vous devez démarrer le modèle avec l'StartModelopération. Vous pouvez obtenir la commande StartModel CLI pour votre modèle depuis la console.
Pour plus d'informations : Démarrez votre modèle.
Un modèle Amazon Lookout for Vision expérimenté prédit si une image d'entrée contient un contenu normal ou anormal. Si votre modèle est un modèle de segmentation, la prédiction inclut un masque d'anomalie qui marque les pixels où les anomalies sont détectées.
Pour faire une prédiction avec votre modèle, appelez l'DetectAnomaliesopération et transmettez une image d'entrée depuis votre ordinateur local. Vous pouvez obtenir la commande CLI qui appelle DetectAnomalies depuis la console.
Pour plus d'informations : Détecter les anomalies dans une image.
Important
La durée de fonctionnement de votre modèle vous est facturée.
Si vous n'utilisez plus votre modèle, utilisez l'StopModelopération pour arrêter le modèle. Vous pouvez obtenir la commande CLI depuis la console.
Pour plus d'informations : Arrêtez votre modèle.
Utiliser votre modèle sur un appareil Edge
Vous pouvez utiliser un modèle Lookout for Vision sur AWS IoT Greengrass Version 2 un appareil principal.
Pour plus d'informations : Utilisation de votre modèle Amazon Lookout for Vision sur un appareil périphérique.
Utilisez votre tableau de bord
Vous pouvez utiliser le tableau de bord pour obtenir une vue d'ensemble de tous vos projets et des informations générales pour des projets individuels.
Pour plus d'informations : Utilisez votre tableau de bord.
