Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Recherche en texte intégral dans Amazon Neptune à l'aide d'Amazon Service OpenSearch
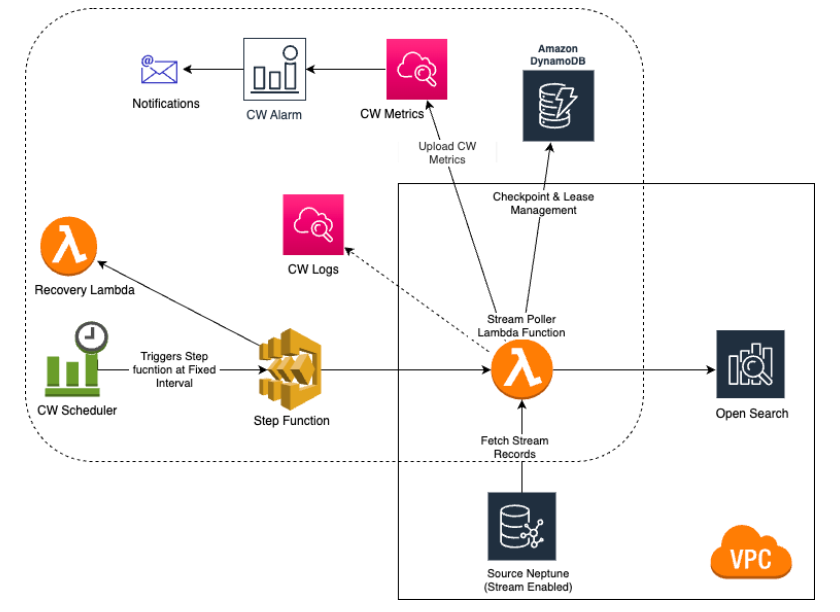
Neptune s'intègre à Amazon OpenSearch Service (OpenSearch Service) pour prendre en charge la recherche en texte intégral dans les requêtes Gremlin et SPARQL. Cette fonctionnalité est disponible à partir de la version 1.0.2.1 du moteur Neptune, mais nous vous recommandons de l'utiliser avec la version du moteur 1.0.4.2 ou une version ultérieure afin de tirer parti des derniers correctifs.
À partir de la version 1.3.0.0 du moteur, Amazon Neptune prend en charge l'utilisation d' OpenSearch Amazon Service Serverless pour la recherche en texte intégral dans les requêtes Gremlin et SPARQL.
Note
Lors de l'intégration à Amazon OpenSearch Service, Neptune nécessite la version 7.1 ou supérieure d'Elasticsearch et fonctionne avec les versions OpenSearch 2.3, 2.5 et supérieures. Neptune fonctionne également avec OpenSearch Serverless.
Vous pouvez utiliser Neptune avec un cluster de OpenSearch services existant qui a été renseigné conformément au. Modèle de données Neptune pour les données OpenSearch Vous pouvez également créer un domaine de OpenSearch service lié à Neptune à l'aide d'une AWS CloudFormation pile.
Important
Le processus de OpenSearch réplication Neptune décrit ici ne réplique pas les nœuds vides. Il s'agit d'une limite importante à noter.
En outre, si vous activez le contrôle d'accès détaillé sur votre OpenSearch cluster, vous devez également activer l'authentification IAM dans votre base de données Neptune.
Rubriques
Interrogation depuis un OpenSearch cluster sur lequel le contrôle d'accès détaillé (FGAC) est activé
Exemples de requêtes SPARQL utilisant la recherche en texte intégral dans Neptune
Utilisation de la recherche en texte intégral Neptune dans des requêtes Gremlin
Résolution des problèmes liés à la recherche Neptune en texte intégral
