Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Premiers pas avec Amazon Neptune
Amazon Neptune est un service de base de données orientée graphe entièrement géré qui évolue pour gérer des milliards de relations et vous permet de les interroger avec une latence de quelques millisecondes, à un faible coût pour ce type de capacité.
Si vous recherchez des informations plus détaillées sur Neptune, consultez Présentation des fonctionnalités Amazon Neptune.
Si les graphes vous sont déjà familiers, passez directement à Utilisation de Neptune avec des carnets graphiques. Ou, si vous souhaitez créer immédiatement une base de données Neptune, consultez Création d'un cluster Amazon Neptune à l'aide de AWS CloudFormation.
Dans le cas contraire, peut-être souhaitez-vous vous familiariser avec les bases de données orientées graphe avant de commencer.
Concepts clés des bases de données graphiques
Les bases de données orientée graphe sont optimisées pour stocker et interroger les relations entre des éléments de données.
Elles stockent les éléments de données sous forme de sommets du graphe, et les relations entre eux sous forme d'arêtes. Chaque arête a un type spécifique et se dirige d'un sommet (le début) à un autre (la fin). Les relations peuvent être appelées prédicats ou arêtes, tandis que les sommets sont également parfois appelés nœuds. Dans ce que l'on appelle les graphes de propriétés, les sommets et les arêtes peuvent également être associés à des propriétés supplémentaires.
Voici un petit graphe représentant les amis et les loisirs d'un réseau social :
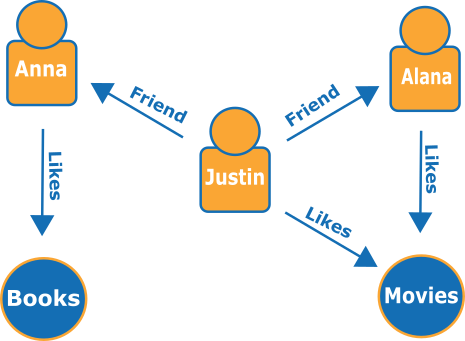
Les arêtes sont représentées par des flèches nommées, et les sommets représentent des personnes et des loisirs spécifiques qu'ils relient.
Un parcours simple de ce graphique peut vous renseigner sur ce qu'aiment les amis de Justin.
Pourquoi utiliser une base de données orientée graphe ?
Dès lors que les connexions ou les relations entre les entités constituent le cœur des données que vous essayez de modéliser, le choix doit naturellement se porter sur une base de données orientée graphe.
D'une part, il est facile de modéliser les interconnexions de données sous forme de graphe, puis d'écrire des requêtes complexes qui extraient des informations réelles du graphe.
Pour créer une application équivalente à l'aide d'une base de données relationnelle, vous devez créer de nombreuses tables avec plusieurs clés étrangères, puis écrire des requêtes SQL imbriquées et des jointures complexes. Non seulement cette approche gagne rapidement en complexité du point de vue du codage, mais ses performances se dégradent rapidement à mesure que la quantité de données augmente.
En revanche, une base de données orientée graphe telle que Neptune peut interroger les relations entre des milliards de sommets sans perte de performances.
Que peut-on faire avec une base de données orientée graphe ?
Les graphes peuvent représenter les interrelations entre des entités du monde réel de nombreuses manières, en termes d'actions, de propriété, de filiation, de choix d'achat, de liens personnels, de liens familiaux, etc.
Voici quelques-uns des domaines les plus courants dans lesquels les bases de données orientées graphe sont utilisées :
-
Graphes de connaissances : les graphes de connaissances vous permettent d'organiser et d'interroger toutes sortes d'informations connectées pour répondre à des questions générales. À l'aide d'un graphe de connaissances, vous pouvez ajouter des informations thématiques à des catalogues de produits et modéliser diverses informations telles que celles qui se trouvent dans Wikidata
. Pour en savoir plus sur le fonctionnement des graphes de connaissances et sur leurs champs d'application, consultez la section Graphes de connaissances sur AWS
. -
Graphes d'identité : dans une base de données orientée graphe, vous pouvez enregistrer les relations entre des catégories d'informations telles que les centres d'intérêt des clients, les amis et l'historique des achats, puis interroger ces données pour formuler des recommandations personnalisées et pertinentes.
Par exemple, vous pouvez utiliser une base de données orientée graphe pour recommander des produits à un utilisateur en fonction de ceux achetés par les autres utilisateurs adeptes du même sport et dont l'historique d'achat est similaire. Vous pouvez aussi identifier les personnes ayant un ami en commun, mais qui ne se connaissent pas encore, et émettre une recommandation de mise en relation.
Les graphes de ce type sont connus sous le nom de graphes d'identité et sont largement utilisés pour personnaliser les interactions avec les utilisateurs. Pour en savoir plus, consultez Graphes d'identité sur AWS
. Pour créer votre propre graphe d'identité, vous pouvez commencer par l'exemple Graphe d'identité avec Amazon Neptune . -
Graphes de détection de fraude : il s'agit d'une utilisation courante des bases de données orientées graphe. Ces graphes peuvent vous aider à suivre les achats par carte de crédit et les points de vente afin de détecter toute utilisation inhabituelle ou de détecter les situations où un acheteur essaie d'utiliser la même adresse e-mail et la même carte de crédit que celles utilisées dans un cas de fraude connu. Ils permettent de rechercher plusieurs personnes associées à une adresse e-mail privée ou plusieurs personnes partageant la même adresse IP dans différents lieux physiques.
Prenons le graphe suivant. Il illustre la relation entre trois personnes et les informations relatives à leur identité. Chaque personne possède une adresse, un compte bancaire et un numéro de sécurité sociale. Cependant, nous pouvons voir que Matt et Justin partagent le même numéro de sécurité sociale, ce qui est interdit et indique une fraude possible de l'un d'eux. Une requête sur un graphe de détection de fraude peut révéler les liens de ce type afin qu'ils puissent être examinés.
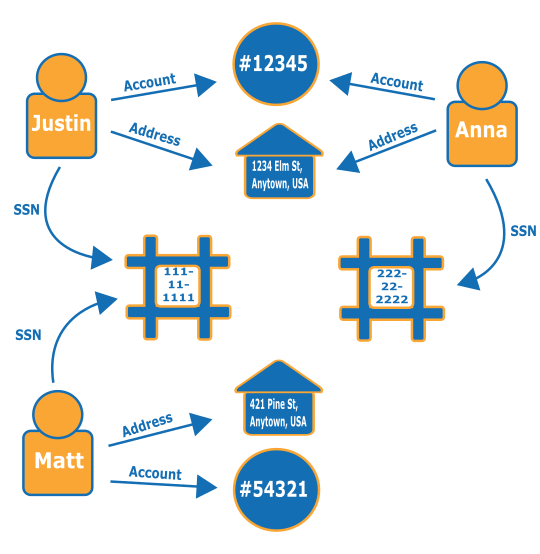
Pour en savoir plus sur les graphes de détection de fraude et sur leurs champs d'applications, consultez Graphes de détection de fraude sur AWS
. -
Réseaux sociaux : les applications de réseaux sociaux sont l'un des champs d'application principaux et les plus courants des bases de données orientées graphe.
Par exemple, supposons que vous souhaitiez intégrer un flux social à un site web. Vous pouvez facilement utiliser une base de données orientées graphe sur le back-end pour fournir aux utilisateurs des résultats qui reflètent les dernières mises à jour publiées par leur famille, leurs amis, les personnes dont ils « aiment » les mises à jour et les personnes vivant à proximité.
Indications routières : un graphe peut aider à trouver le meilleur itinéraire entre un point de départ et une destination, compte tenu du trafic actuel et des modèles de trafic habituels.
Logistique : les graphes peuvent aider à identifier le moyen le plus efficace d'utiliser les ressources de livraison et de distribution disponibles pour répondre aux exigences des clients.
Diagnostic : les graphes peuvent représenter des arbres de diagnostic complexes qui peuvent être interrogés pour identifier la source des problèmes et des défaillances observés.
Recherche scientifique : avec une base de données orientée graphe, vous pouvez créer des applications qui stockent et consultent des données scientifiques, voire des informations médicales sensibles, à l'aide du chiffrement au repos. Par exemple, vous pouvez stocker des modèles des maladies et d'interactions géniques. Vous pouvez rechercher des modèles de graphiques dans les interactions protéiques afin de trouver d’autres gènes susceptibles d’être associés à une maladie. Vous pouvez modéliser les composés chimiques sous forme de graphe et les interroger afin d'identifier les redondances dans les structures moléculaires. Vous pouvez corréler les données des patients à partir des dossiers médicaux de différents systèmes. Vous pouvez organiser par thèmes les publications de recherche afin de trouver rapidement des informations pertinentes.
Règles réglementaires : vous pouvez enregistrer des exigences réglementaires complexes sous forme de graphiques et les interroger pour détecter les situations dans lesquelles elles pourraient s'appliquer à vos activités day-to-day commerciales.
-
Topologie et événements du réseau : une base de données orientée graphe peut vous aider à gérer et à protéger un réseau informatique. Lorsque vous stockez la topologie du réseau sous forme de graphe, vous pouvez également stocker et traiter de nombreux types d'événements sur le réseau. Vous pouvez répondre à des questions telles que le nombre d'hôtes exécutant une application donnée. Vous pouvez y rechercher des modèles susceptibles d'indiquer qu'un hôte spécifique a été compromis par un programme malveillant et identifier les données de connexion permettant de retracer le programme jusqu'à l'hôte d'origine qui l'a téléchargé.
Comment interroge-t-on un graphe ?
Neptune prend en charge trois langages de requête spécifiques conçus pour interroger des données de graphe de différents types. Vous pouvez utiliser les langages suivants pour ajouter, modifier, supprimer et interroger des données dans une base de données orientée graphe Neptune :
-
Gremlin est un langage de parcours de graphe pour les graphes de propriétés. Dans Gremlin, une requête est une traversée composée d'étapes distinctes, chacune suivant une arête jusqu'à un nœud. Pour plus d'informations, consultez la documentation de Gremlin sur Apache TinkerPop 3
. L'implémentation Neptune de Gremlin présente quelques différences par rapport aux autres implémentations, surtout lorsque vous utilisez Gremlin-Groovy (requêtes Gremlin envoyées sous la forme d'un texte sérialisé). Pour de plus amples informations, veuillez consulter Conformité d'Amazon Neptune avec les normes Gremlin.
-
openCypher : openCypher est un langage de requête déclaratif pour les graphes de propriétés initialement développé par Neo4j, puis rendu open source en 2015. Il a contribué au projet openCypher
sous une licence open source Apache 2. Consultez Cypher Query Language Reference (version 9) pour en savoir plus sur la spécification de ce langage, ainsi que le guide de style Cypher pour plus d'informations. -
SPARQL est un langage de requête déclaratif pour les données RDF
. Il repose sur la mise en correspondance de modèles de graphe, qui est normalisée par le World Wide Web Consortium (W3C) et décrite dans la présentation de SPARQL 1.1 ainsi que dans la spécification SPARQL 1.1 Query Language . Consultez Conformité d'Amazon Neptune avec les normes SPARQL pour plus d'informations sur l'implémentation Neptune de SPARQL.
Exemples de correspondance de requêtes Gremlin et SPARQL
Étant donné le graphe suivant de personnes (nœuds) et de leurs relations (arêtes), vous pouvez découvrir qui sont les « amis d'amis » d'une personne donnée, tels que les amis des amis de Howard.
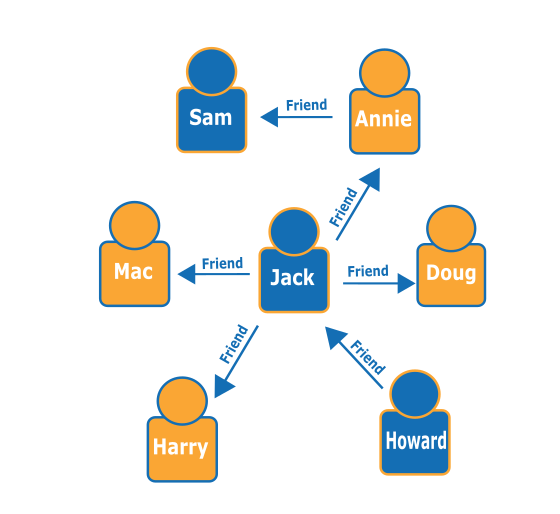
Si vous regardez le graphe, vous pouvez voir que Howard a un ami, Jack, et que Jack a quatre amis : Annie, Harry, Doug et Mac. Il s'agit d'un exemple de graphe simple, mais ces types de requêtes peuvent évoluer en complexité, dimension de l'ensemble de donnés et taille du résultat.
Voici une requête de traversée Gremlin qui renvoie le nom des amis des amis de Howard.
g.V().has('name', 'Howard').out('friend').out('friend').values('name')
Voici une requête SPARQL qui renvoie le nom des amis des amis de Howard.
prefix : <#> select ?names where { ?howard :name "Howard" . ?howard :friend/:friend/:name ?names . }
Note
Chaque partie d'un triplet RDF (Resource Description Framework) possède un URI qui lui est associé. Dans l'exemple ci-dessus, le préfixe de l'URI est volontairement court.
Suivre un cours en ligne sur l'utilisation d'Amazon Neptune
Si vous aimez apprendre par le biais de vidéos, AWS propose des cours en ligne dans le AWS cadre des Online Tech Talks
Approfondissement de l'architecture de référence des graphes
Lorsque vous réfléchissez aux problèmes qu'une base de données de graphes pourrait résoudre pour vous et à la manière de les aborder, l'un des meilleurs points de départ est le projet d'architectures GitHub de référence de graphes Neptune
Vous y trouverez des descriptions détaillées des types de charge de travail spécifiques aux graphes, ainsi que trois sections qui vous aideront à concevoir une base de données orientée graphe efficace :
Modèles de données et langages de requête
: cette section explique les différences entre Gremlin et SPARQL et décrit comment choisir entre ces deux langages. Modélisation des données de graphe
: il s'agit d'une discussion approfondie sur la façon de prendre des décisions en matière de modélisation de données de graphe, y compris des présentations détaillées de la modélisation de graphes de propriétés à l'aide de Gremlin et de la modélisation RDF à l'aide de SPARQL. Conversion d'autres modèles de données en modèle de graphe
: découvrez ici comment convertir un modèle de données relationnel en modèle orienté graphe.
Trois sections vous indiquent également les étapes spécifiques à suivre pour utiliser Neptune :
Connexion à Amazon Neptune à partir de clients extérieurs au VPC Neptune
: cette section présente plusieurs options de connexion à Neptune à partir de l'extérieur du VPC où se trouve votre cluster de bases de données. Accès à Amazon Neptune depuis les fonctions AWS Lambda
: vous découvrirez ici comment vous connecter de manière fiable à Neptune à partir des fonctions Lambda. Écriture sur Amazon Neptune à partir d'un flux de données Amazon Kinesis
: cette section explique comment gérer les scénarios à haut débit d'écriture avec Neptune.
