Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Clonage de bases de données dans Neptune
Le clonage de base de données vous permet de créer de façon rapide et économique des clones de toutes vos bases de données dans Amazon Neptune. Les bases de données clone n'ont besoin que d'un espace supplémentaire minime au moment où elles sont créées. Le clonage de base de données utilise un protocole de copie sur écriture. Les données sont copiées au moment où elles sont modifiées, que ce soit dans les bases de données source ou les bases de données clone. Vous pouvez créer plusieurs clones du même cluster de base de données. Vous pouvez également créer des clones supplémentaires à partir d'autres clones. Pour plus d'informations sur le fonctionnement du protocole de copie sur écriture dans le contexte du stockage Neptune, consultez Protocole de copie sur écriture.
Vous pouvez utiliser le clonage de base de données dans divers cas d'utilisation, notamment lorsque vous ne voulez pas affecter votre environnement de production, comme dans les exemples suivants :
Expérimentation et évaluation de l'impact de modifications, telles que des modifications du schéma ou des modifications du groupe de paramètres.
Réalisation d'opérations imposant une charge de travail élevée, telles que l'exportation de données ou l'exécution de requêtes analytiques.
Création d'une copie d'un cluster de base de données de production dans un environnement autre que de production pour le développement ou les tests.
Pour créer un clone d'un cluster de bases de données à l'aide d'AWS Management Console
Connectez-vous à la console de gestion AWS et ouvrez la console Amazon Neptune à l'adresse https://console.aws.amazon.com/neptune/home
. Dans le panneau de navigation, choisissez Instances. Choisissez l'instance principale pour le cluster de base de données dont vous voulez créer un clone.
Choisissez Instance actions (Actions d'instance), puis Create clone (Créer un clone).
-
Dans la page Create Clone (Créer un clone), entrez un nom pour l'instance principale du cluster de base de données clone dans le champ DB instance identifier (Identifiant d'instance DB).
Configurez éventuellement d'autres paramètres pour le cluster de base de données clone. Pour plus d'informations sur les différents paramètres de cluster de base de données, consultez Lancement à l'aide de la console.
Choisissez Create Clone (Créer un clone) pour lancer le cluster de base de données clone.
Pour créer un clone d'un cluster de bases de données à l'aide d'AWS CLI
-
Appelez la commande restore-db-cluster-to-point-in-time de l'AWS CLI et fournissez les valeurs suivantes :
--source-db-cluster-identifier: nom du cluster de bases de données source à partir duquel un clone doit être créé.--db-cluster-identifier: nom du cluster de bases de données clone.--restore-type copy-on-write: la valeurcopy-on-writeindique qu'un cluster de bases de données clone doit être créé.--use-latest-restorable-time: précise que la dernière heure de sauvegarde restaurable doit être utilisée.
Note
La commande restore-db-cluster-to-point-in-time de l'AWS CLI clone uniquement le cluster de base de données, et non les instances de base de données de ce cluster.
L'exemple Linux/UNIX suivant crée un clone à partir du cluster de base de données
source-db-cluster-idet le nommedb-clone-cluster-id.aws neptune restore-db-cluster-to-point-in-time \ --region us-east-1 \ --source-db-cluster-identifier source-db-cluster-id \ --db-cluster-identifier db-clone-cluster-id \ --restore-type copy-on-write \ --use-latest-restorable-timeLe même exemple fonctionne sur Windows si le caractère d'échappement de fin de ligne
\est remplacé par l'équivalent Windows^:aws neptune restore-db-cluster-to-point-in-time ^ --region us-east-1 ^ --source-db-cluster-identifier source-db-cluster-id ^ --db-cluster-identifier db-clone-cluster-id ^ --restore-type copy-on-write ^ --use-latest-restorable-time
Limites
Le clonage de base de données dans Neptune présente les limites suivantes :
Vous ne pouvez pas créer de bases de données clonées d'une région AWS à une autre. Les bases de données clone doivent être créées dans la même région que les bases de données source.
Une base de données clonée utilise toujours le correctif le plus récent de la version du moteur Neptune utilisée par la base de données à partir de laquelle elle a été clonée. Ceci est vrai même si la base de données source n'a pas encore été mise à niveau vers cette version de correctif. Cependant, la version du moteur elle-même ne change pas.
Actuellement, vous êtes limité à 15 clones par copie du cluster de bases de données Neptune, ce qui comprend les clones basés sur d'autres clones. Une fois cette limite atteinte, vous devez effectuer une autre copie de votre base de données plutôt que de la cloner. Cependant, si vous créez une autre copie, elle peut aussi avoir jusqu'à 15 clones.
Le clonage de base de données entre comptes n'est pas pris en charge actuellement.
Vous pouvez fournir un réseau Virtual Private Cloud (VPC) différent pour votre clone. Cependant, les sous-réseaux de ces VPC doivent correspondre au même ensemble de zones de disponibilité.
Protocole de copie sur écriture pour le clonage de base de données
Les scénarios suivants illustrent le fonctionnement du protocole de copie sur écriture.
Base de données Neptune avant le clonage
Les données figurant dans une base de données source sont stockées dans des pages. Dans le schéma ci-dessous, la base de données source comporte quatre pages.

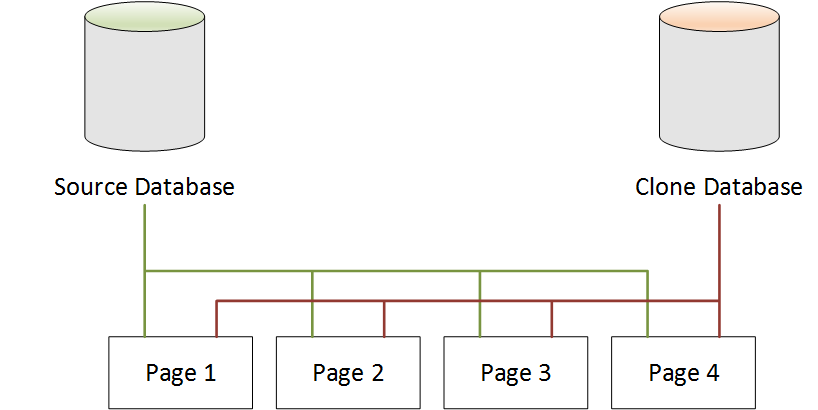
Base de données Neptune après le clonage
Comme le montre le schéma suivant, aucune modification n'a été apportée à la base de données source après le clonage de base de données. La base de données source et la base de données clone pointent toutes les deux sur les quatre mêmes pages. Aucune page n'a été copiée physiquement et aucun stockage supplémentaire n'est nécessaire.
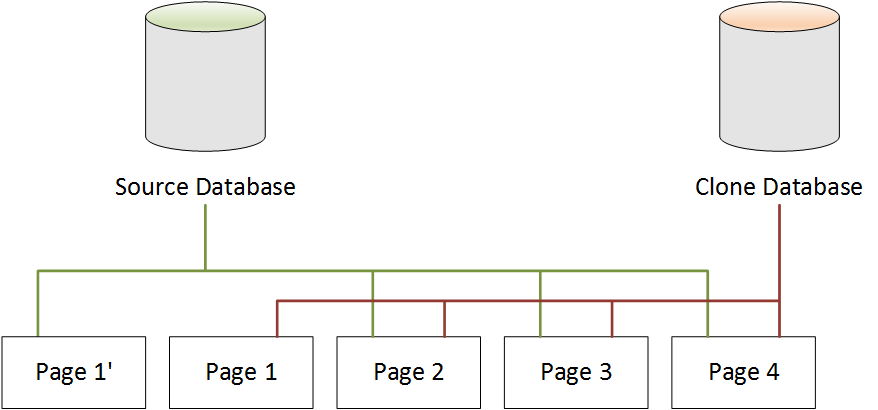
Lorsqu'une modification est apportée à la base de données source
Dans l'exemple suivant, la base de données source apporte une modification aux données de la Page
1. Au lieu d'écrire dans la Page 1 d'origine, il utilise un stockage supplémentaire pour créer une nouvelle page, appelée Page 1'. La base de données source pointe maintenant sur la nouvelle Page 1', ainsi que sur la Page 2, la Page 3 et la Page 4. La base de données clone continue de pointer sur les Page 1 à Page 4.
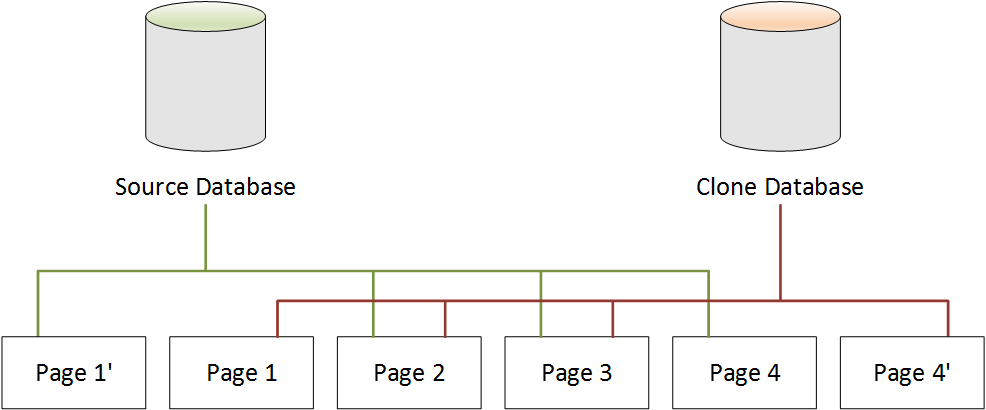
Lorsqu'une modification est apportée à la base de données clone
Dans le schéma ci-dessous, la base de données clone a également été modifiée, cette fois au niveau de la Page 4. Au lieu d'écrire dans la page Page 4 d’origine, un stockage supplémentaire est utilisé pour créer une nouvelle page, appelée Page 4'. La base de données source continue à pointer vers la Page 1', ainsi que vers les pages Page 2 à Page 4, mais la base de données clone pointe maintenant vers les pages Page 1 à Page 3, ainsi que vers la Page 4'.
Comme le montre le deuxième scénario, après le clonage de base de données, aucun stockage supplémentaire n'est nécessaire au stade de la création du clone. Toutefois, lorsque des modifications interviennent dans la base de données source et la base de données clone, comme le montrent les troisième et quatrième scénarios, seules les pages modifiées sont créées. Lorsque des modifications supplémentaires interviennent au fil du temps dans la base de données source et la base de données clone, vous avez besoin de plus de stockage pour capturer et stocker ces modifications.
Suppression d'une base de données source
La suppression d'une base de données source n'affecte pas les bases de données clone qui lui sont associées. Les bases de données clones continuent de pointer sur les pages qui étaient précédemment la propriété de la base de données source.
