Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Optimisation du stockage
La mise à jour ou la suppression de données dans une table Iceberg augmente le nombre de copies de vos données, comme illustré dans le schéma suivant. Il en va de même pour l'exécution du compactage : il augmente le nombre de copies de données dans Amazon S3. C'est parce qu'Iceberg considère les fichiers sous-jacents à toutes les tables comme immuables.
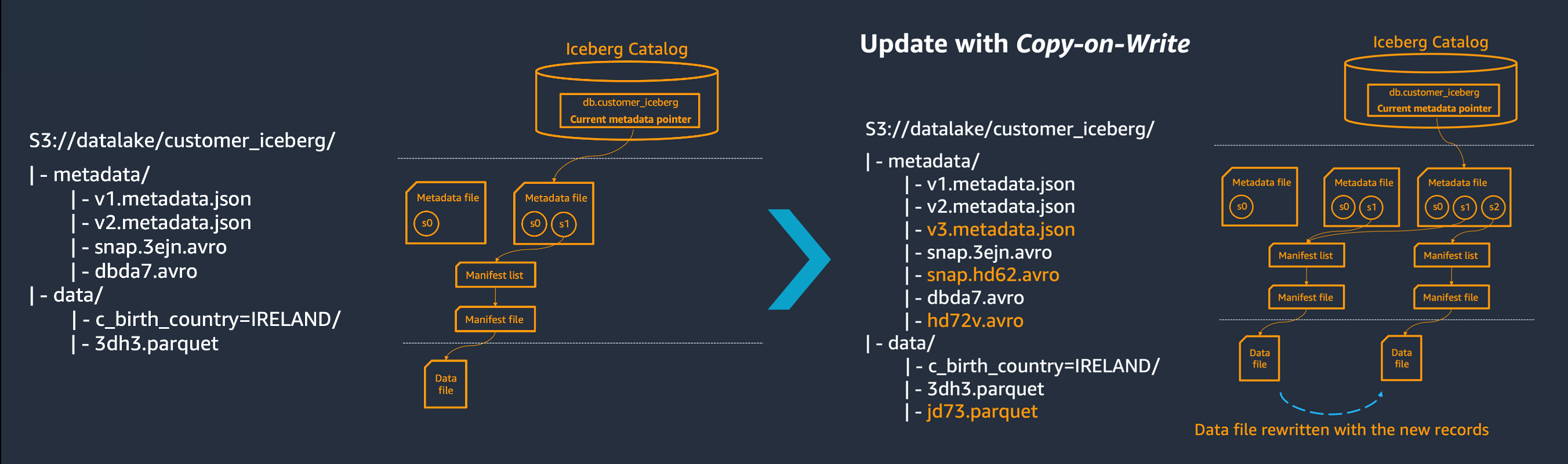
Suivez les meilleures pratiques décrites dans cette section pour gérer les coûts de stockage.
Activer la hiérarchisation intelligente S3
Utilisez la classe de stockage Amazon S3 Intelligent-Tiering pour déplacer automatiquement les données vers le niveau d'accès le plus rentable lorsque les modèles d'accès changent. Cette option n'entraîne aucune surcharge opérationnelle ni aucun impact sur les performances.
Remarque : n'utilisez pas les niveaux facultatifs (tels que Archive Access et Deep Archive Access) dans S3 Intelligent-Tiering with Iceberg tables. Pour archiver des données, consultez les instructions de la section suivante.
Vous pouvez également utiliser les règles du cycle de vie d'Amazon S3 pour définir vos propres règles de déplacement d'objets vers une autre classe de stockage Amazon S3, telle que S3 Standard-IA ou S3 One Zone-IA (voir Transitions prises en charge et contraintes associées dans la documentation Amazon S3).
Archiver ou supprimer des instantanés historiques
Pour chaque transaction validée (insertion, mise à jour, fusion dans, compactage) dans une table Iceberg, une nouvelle version ou un instantané de la table est créé. Au fil du temps, le nombre de versions et le nombre de fichiers de métadonnées s'accumulent dans Amazon S3.
La conservation des instantanés d'une table est nécessaire pour des fonctionnalités telles que l'isolation des instantanés, la restauration des tables et les requêtes de voyage dans le temps. Toutefois, les coûts de stockage augmentent en fonction du nombre de versions que vous conservez.
Le tableau suivant décrit les modèles de conception que vous pouvez mettre en œuvre pour gérer les coûts en fonction de vos exigences en matière de conservation des données.
Motif de design |
Solution |
Cas d’utilisation |
|---|---|---|
Supprimer les anciens instantanés |
|
Cette approche supprime les instantanés qui ne sont plus nécessaires pour réduire les coûts de stockage. Vous pouvez configurer le nombre d'instantanés à conserver ou pendant combien de temps, en fonction de vos exigences en matière de conservation des données. Cette option effectue une suppression définitive des instantanés. Vous ne pouvez pas revenir en arrière ou voyager dans le temps pour retrouver des instantanés expirés. |
Définissez des règles de conservation pour des instantanés spécifiques |
|
Ce modèle est utile pour vous conformer aux exigences commerciales ou légales qui vous obligent à montrer l'état d'un tableau à un moment donné dans le passé. En appliquant des règles de conservation à des instantanés balisés spécifiques, vous pouvez supprimer d'autres instantanés (non balisés) créés. Ainsi, vous pouvez répondre aux exigences de conservation des données sans conserver chaque instantané créé. |
Archiver les anciens instantanés |
Pour obtenir des instructions détaillées, consultez le billet de AWS blog Améliorez l'efficacité opérationnelle des tables Apache Iceberg basées sur les lacs de données Amazon S3
|
Ce modèle vous permet de conserver toutes les versions des tables et les instantanés à moindre coût. Vous ne pouvez pas voyager dans le temps ou revenir à des instantanés archivés sans avoir d'abord restauré ces versions sous forme de nouvelles tables. Cela est généralement acceptable à des fins d'audit. Vous pouvez combiner cette approche avec le modèle de conception précédent, en définissant des politiques de conservation pour des instantanés spécifiques. |
Supprimer les fichiers orphelins
Dans certaines situations, les applications Iceberg peuvent échouer avant que vous n'ayez validé vos transactions. Cela laisse les fichiers de données dans Amazon S3. Comme il n'y a pas eu de validation, ces fichiers ne seront associés à aucune table. Vous devrez peut-être les nettoyer de manière asynchrone.
Pour gérer ces suppressions, vous pouvez utiliser l'instruction VACUUM dans Amazon Athena. Cette instruction supprime les instantanés et supprime également les fichiers orphelins. C'est très rentable, car Athena ne facture pas le coût de calcul de cette opération. De plus, il n'est pas nécessaire de planifier d'opérations supplémentaires lorsque vous utilisez l'VACUUMinstruction.
Vous pouvez également utiliser Spark sur Amazon EMR ou AWS Glue exécuter la remove_orphan_files procédure. Cette opération a un coût de calcul et doit être planifiée indépendamment. Pour plus d'informations, consultez la documentation d'Iceberg
