Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Commencer à utiliser les tables Apache Iceberg dans Amazon Athena SQL
Amazon Athena fournit un support intégré pour Apache Iceberg. Vous pouvez utiliser Iceberg sans étapes ni configuration supplémentaires, à l'exception de la configuration des prérequis de service détaillés dans la section Mise en route de la documentation Athena. Cette section fournit une brève introduction à la création de tables dans Athena. Pour plus d'informations, consultez la section Utilisation des tables Apache Iceberg à l'aide d'Athena SQL plus loin dans ce guide.
Vous pouvez créer des tables Iceberg à l'aide AWS de différents moteurs. Ces tables fonctionnent parfaitement d'un bout à l'autre Services AWS. Pour créer vos premières tables Iceberg avec Athena SQL, vous pouvez utiliser le code standard suivant.
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Les sections suivantes fournissent des exemples de création de tables Iceberg partitionnées et non partitionnées dans Athena. Pour plus d'informations, consultez la syntaxe Iceberg détaillée dans la documentation d'Athena.
Création d'une table non partitionnée
L'exemple d'instruction suivant personnalise le code SQL standard pour créer une table Iceberg non partitionnée dans Athena. Vous pouvez ajouter cette instruction à l'éditeur de requêtes de l'Athenaconsole
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Pour step-by-step obtenir des instructions sur l'utilisation de l'éditeur de requêtes, voir Getting started dans la documentation d'Athena.
Création d'une table partitionnée
L'instruction suivante crée une table partitionnée basée sur la date en utilisant le concept de partitionnement cachéday() transformation pour dériver des partitions quotidiennes, en utilisant le dd-mm-yyyy format, à partir d'une colonne d'horodatage. Iceberg ne stocke pas cette valeur sous forme de nouvelle colonne dans le jeu de données. Au lieu de cela, la valeur est dérivée à la volée lorsque vous écrivez ou interrogez des données.
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Création d'une table et chargement de données avec une seule instruction CTAS
Dans les exemples partitionnés et non partitionnés des sections précédentes, les tables Iceberg sont créées sous forme de tables vides. Vous pouvez charger des données dans les tables à l'aide de l'MERGEinstruction INSERT or. Vous pouvez également utiliser une CREATE TABLE AS SELECT (CTAS) instruction pour créer et charger des données dans une table Iceberg en une seule étape.
Le CTAS est le meilleur moyen dans Athena de créer une table et de charger des données dans une seule instruction. L'exemple suivant montre comment utiliser le CTAS pour créer une table Iceberg (iceberg_ctas_table) à partir d'une table Hive/Parquet () existante dans Athena. hive_table
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
Pour en savoir plus sur le CTAS, consultez la documentation d'Athena CTAS.
Insertion, mise à jour et suppression de données
Athena prend en charge différentes manières d'écrire des données dans une table Iceberg en utilisant les INSERT INTO instructions, UPDATEMERGE INTO, et M. DELETE FRO
Remarque : UPDATEMERGE INTO, et DELETE FROM utilisez l' merge-on-read approche avec les suppressions positionnelles. L' copy-on-write approche n'est actuellement pas prise en charge dans Athena SQL.
Par exemple, l'instruction suivante permet INSERT INTO d'ajouter des données à une table Iceberg :
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
Exemple de sortie :

Pour plus d'informations, consultez la documentation d'Athena.
Interrogation des tables Iceberg
Vous pouvez exécuter des requêtes SQL régulières sur vos tables Iceberg à l'aide d'Athena SQL, comme illustré dans l'exemple précédent.
Outre les requêtes habituelles, Athena prend également en charge les requêtes de voyage dans le temps pour les tables Iceberg. Comme indiqué précédemment, vous pouvez modifier des enregistrements existants par le biais de mises à jour ou de suppressions dans une table Iceberg. Il est donc pratique d'utiliser des requêtes de voyage dans le temps pour consulter les anciennes versions de votre table sur la base d'un horodatage ou d'un identifiant d'instantané.
Par exemple, l'instruction suivante met à jour une valeur de couleur pourPerson5, puis affiche une valeur antérieure datant du 4 janvier 2023 :
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
Exemple de sortie :
Pour la syntaxe et d'autres exemples de requêtes de voyage dans le temps, consultez la documentation d'Athena.
Anatomie de la table Iceberg
Maintenant que nous avons abordé les étapes de base de l'utilisation des tables Iceberg, examinons plus en détail les détails complexes et le design d'une table Iceberg.
Pour activer les fonctionnalités décrites précédemment dans ce guide, Iceberg est conçu avec des couches hiérarchiques de données et de fichiers de métadonnées. Ces couches gèrent les métadonnées de manière intelligente afin d'optimiser la planification et l'exécution des requêtes.
Le schéma suivant décrit l'organisation d'une table Iceberg selon deux perspectives : celle Services AWS utilisée pour stocker la table et le placement des fichiers dans Amazon S3.
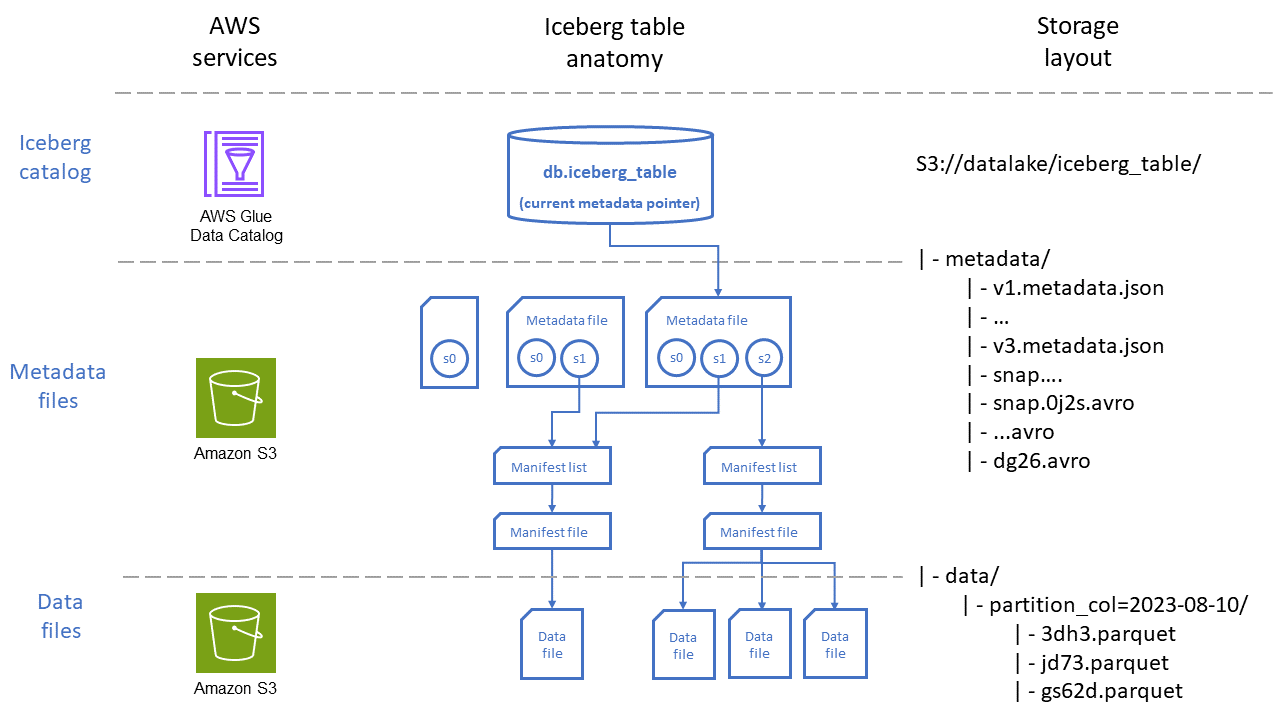
Comme le montre le schéma, une table Iceberg se compose de trois couches principales :
-
Catalogue Iceberg : AWS Glue Data Catalog s'intègre nativement à Iceberg et constitue, dans la plupart des cas d'utilisation, la meilleure option pour les charges de travail qui s'exécutent sur. AWS Les services qui interagissent avec les tables Iceberg (par exemple, Athena) utilisent le catalogue pour trouver la version instantanée actuelle de la table, soit pour lire soit pour écrire des données.
-
Couche de métadonnées : les fichiers de métadonnées, à savoir les fichiers manifestes et les fichiers de listes de manifestes, gardent une trace des informations telles que le schéma des tables, la stratégie de partition et l'emplacement des fichiers de données, ainsi que des statistiques au niveau des colonnes telles que les plages minimale et maximale pour les enregistrements stockés dans chaque fichier de données. Ces fichiers de métadonnées sont stockés dans Amazon S3 dans le chemin de la table.
-
Les fichiers manifestes contiennent un enregistrement pour chaque fichier de données, y compris son emplacement, son format, sa taille, sa somme de contrôle et d'autres informations pertinentes.
-
Les listes de manifestes fournissent un index des fichiers manifestes. À mesure que le nombre de fichiers manifestes augmente dans une table, la division de ces informations en sous-sections plus petites permet de réduire le nombre de fichiers manifestes devant être analysés par des requêtes.
-
Les fichiers de métadonnées contiennent des informations sur l'ensemble de la table Iceberg, notamment les listes de manifestes, les schémas, les métadonnées de partition, les fichiers d'instantanés et les autres fichiers utilisés pour gérer les métadonnées de la table.
-
-
Couche de données : cette couche contient les fichiers contenant les enregistrements de données sur lesquels les requêtes seront exécutées. Ces fichiers peuvent être stockés dans différents formats, notamment Apache Parquet
, Apache Avro et Apache ORC . -
Les fichiers de données contiennent les enregistrements de données d'une table.
-
Les fichiers de suppression encodent les opérations de suppression et de mise à jour au niveau des lignes dans une table Iceberg. Iceberg propose deux types de fichiers de suppression, comme décrit dans la documentation d'Iceberg
. Ces fichiers sont créés par des opérations en utilisant le merge-on-read mode.
-
