Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Phase de traitement
Amazon Textract extrait le contenu des fichiers PDF sous forme de chaînes qui ne peuvent pas être directement utilisées par les applications en aval (par exemple, pour générer des statistiques en agrégeant des nombres). Des valeurs de données correctement identifiées et transformées sont nécessaires car elles peuvent être plus facilement utilisées par vos applications en aval (par exemple, pour tracer les tendances des coûts sous forme de séries chronologiques). Pour implémenter le traitement des fichiers PDF, un fichier PDF de chaque nouveau type de fichier PDF doit être traité une seule fois via Amazon Textract, qui génère ensuite un fichier au format JSONTemplate.
Une fois la AWS Lambda fonction lancée dans lePhase d'ingestion, elle exécute les étapes indiquées dans le schéma suivant.
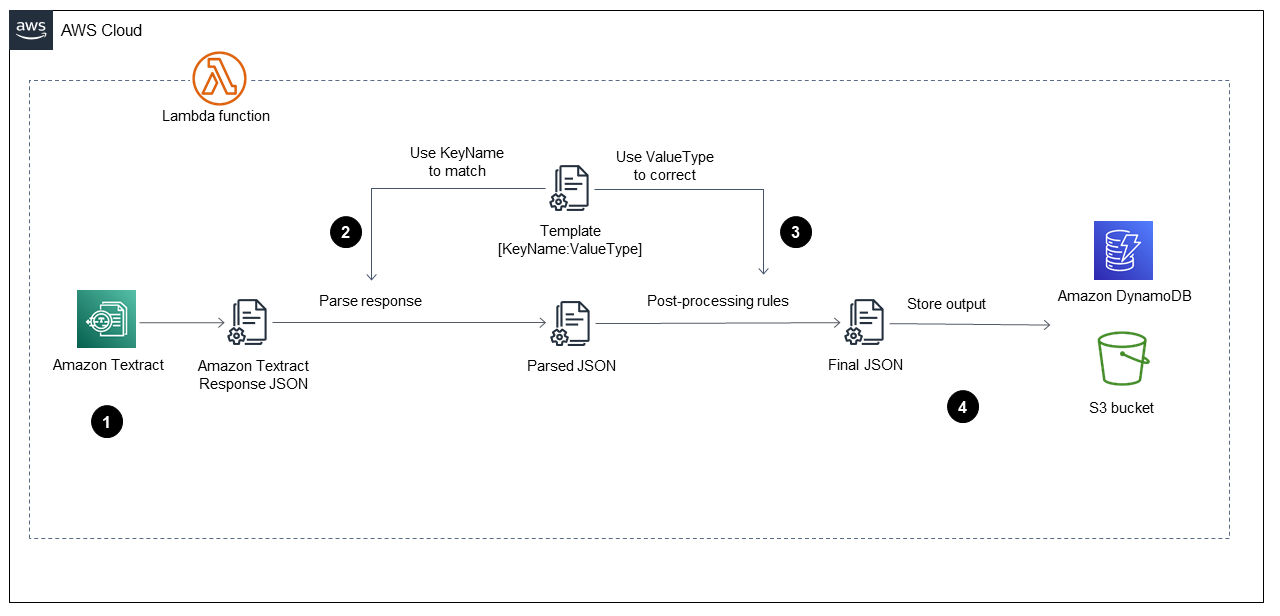
Le schéma montre la fonction Lambda implémentant les étapes suivantes :
-
Appelle Amazon Textract pour traiter le fichier PDF, en extraire le contenu et renvoyer un fichier au format JSON.
-
Prend le fichier JSON et analyse les formulaires et les tables à l'aide d'un fichier
TemplateJSON prédéfini dont le nom de clé et le type de valeur sont corrects pour chaque champ. Ce processus fournit un fichier JSON analysé. -
Applique les règles de post-traitement et utilise le fichier
TemplateJSON pour corriger chaque valeur du fichier JSON analysé. Cela produit le fichierFinalJSON. Le fichierTemplateJSON prédéfini peut être stocké dans le compartiment S3. -
Stocke le fichier
FinalJSON dans Amazon DynamoDB sous la forme d'un enregistrement pour chaque fichier PDF, en plus d'un fichier JSON pour chaque fichier PDF dans un compartiment de sortie S3.
Pour un step-by-step flux de travail qui utilise Amazon Textract pour extraire automatiquement le contenu des fichiers PDF et le transformer en un résultat propre, consultez le modèle Extraire automatiquement le contenu des fichiers PDF à l'aide d'Amazon Textract sur AWS le site Web de Prescriptive Guidance. Le modèle utilise une technique de correspondance de modèles pour identifier correctement le champ, le nom de clé et les tables requis, puis applique des corrections de post-traitement à chaque type de données.
Bonnes pratiques pour la phase de traitement
Utilisez les quatre meilleures pratiques suivantes pour garantir le succès de la phase de traitement :
-
Créez un modèle de fichier JSON pour chaque type de fichier PDF que vous souhaitez traiter. Vous pouvez stocker ces différents modèles de fichiers JSON dans un compartiment S3 appelé par la fonction Lambda. Si vous souhaitez traiter différents types de fichiers PDF dans une seule fonction Lambda, vous devez utiliser un identifiant unique pour chaque type de fichier PDF (par exemple, le nom de dossier du type de fichier PDF dans le compartiment S3). Une fois que la fonction Lambda est invoquée, elle extrait le fichier JSON modèle approprié et le traite.
-
Configurez un mécanisme pour suivre avec précision l'état de chaque étape de la fonction Lambda. Par exemple, vous pouvez ajouter
Successdes statuts après l'appel Amazon Textract, lorsque le fichier JSON final est enregistré dans une table Amazon DynamoDB ou lorsque les fichiers PDF sont enregistrés dans un compartiment S3. Vous pouvez également créer un tableau DynamoDB distinct pour suivre l'état de chaque fichier PDF au cours des différentes étapes, ce qui permet de mieux comprendre le processus. -
Gérez les ralentissements et les interruptions de connexion en réessayant automatiquement les opérations qui ont échoué lorsque vous traitez par lots de nombreux fichiers PDF. Un ralentissement peut se produire dans Amazon Textract si votre connexion est interrompue ou si vous dépassez le nombre maximum de transactions par seconde (TPS). Pour plus d'informations et pour connaître les étapes permettant de réessayer automatiquement les opérations ayant échoué, consultez la section Gestion des appels limités et des interruptions de connexion dans la documentation Amazon Textract.
-
Si vous avez des fichiers PDF de plusieurs pages, vous pouvez soit utiliser une opération asynchrone pour traiter l'intégralité du fichier, soit diviser le fichier PDF en une page individuelle, utiliser une opération synchrone pour traiter chaque page, puis combiner les résultats de chaque page. Pour une implémentation complète du code d'une opération asynchrone, consultez la section Détection et analyse de texte dans des documents de plusieurs pages dans la documentation Amazon Textract. Pour plus d'informations sur l'utilisation d'une opération synchrone, consultez la section Détection et analyse du texte dans des documents d'une seule page dans la documentation Amazon Textract.
