Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture de prévision de la demande de fret
L'image suivante montre le flux de travail de la solution, y compris l'ingestion des données, la préparation des données, la création de modèles, le résultat final et la surveillance.
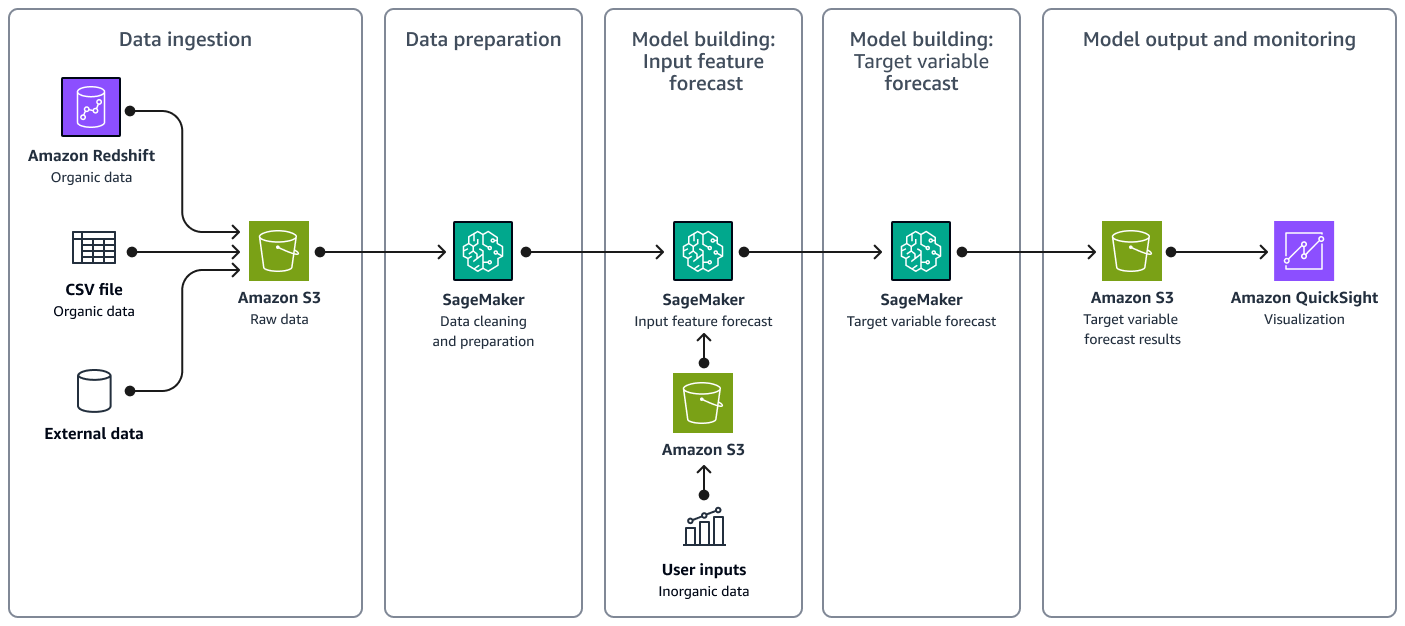
L'architecture de la solution inclut les principaux composants suivants :
-
Ingestion de données — Vous stockez à la fois des données organiques et des données externes dans Amazon Simple Storage Service (Amazon S3).
-
Préparation des données — Amazon SageMaker AI nettoie les données et les prépare pour la formation du modèle ML. Pour plus d'informations, consultez la section Préparation des données dans la documentation de l' SageMaker IA.
-
Création de modèles : prévision des fonctionnalités d'entrée — Utilisations de SageMaker l'IA Prophet
pour générer une prévision de série chronologique pour chaque entité en entrée. Vous examinez les résultats des prévisions. Si nécessaire, vous fournissez des entrées utilisateur pour remplacer les prévisions de la fonctionnalité. -
Création de modèles : prévision des variables cibles — SageMaker L'IA crée un modèle de régression pour l'inférence en utilisant les fonctionnalités d'entrée modifiées.
-
Sortie et surveillance du modèle : le modèle de régression envoie les résultats des prévisions à Amazon S3. Vous pouvez visualiser les prévisions sur Amazon QuickSight. Les analystes peuvent surveiller les résultats des prévisions et évaluer leur précision en comparant les prévisions avec le volume de demande réel.
L'ensemble du pipeline de traitement, de l'ingestion des données à la sortie finale du modèle, peut être orchestré pour s'exécuter automatiquement. Par exemple, vous pouvez le configurer pour qu'il s'exécute automatiquement tous les mois pour une prévision mensuelle de la demande. Si vous avez besoin de prévisions pour plusieurs produits, vous pouvez exécuter le pipeline en parallèle pour plusieurs produits. Pour plus d'informations, consultez la section MLOpsImplémentation dans la documentation de l' SageMaker IA.
