Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création de pipelines ML prêts pour la production sur AWS
Josiah Davis, Verdi March, Yin Song, Baichuan Sun, Chen Wu et Wei Yih Yap, Amazon Web Services ()AWS
Janvier 2021 (historique du document)
Les projets d'apprentissage automatique (ML) nécessitent un effort important en plusieurs étapes comprenant la modélisation, la mise en œuvre et la production pour apporter de la valeur commerciale et résoudre des problèmes concrets. De nombreuses alternatives et options de personnalisation sont disponibles à chaque étape, ce qui complique de plus en plus la préparation d'un modèle de machine learning pour la production dans les limites de vos ressources et de votre budget. Au cours des dernières années, chez Amazon Web Services (AWS), notre équipe de science des données a travaillé avec différents secteurs industriels sur des initiatives de machine learning. Nous avons identifié les problèmes communs à de nombreux AWS clients, liés à la fois à des problèmes organisationnels et à des défis techniques, et nous avons développé une approche optimale pour fournir des solutions de machine learning prêtes pour la production.
Ce guide s'adresse aux data scientists et aux ingénieurs ML impliqués dans la mise en œuvre de pipelines ML. Il décrit notre approche pour fournir des pipelines de machine learning prêts pour la production. Le guide explique comment passer de l'exécution interactive de modèles de ML (pendant le développement) à leur déploiement dans le cadre d'un pipeline (pendant la production) pour votre cas d'utilisation du ML. À cette fin, nous avons également développé un ensemble d'exemples de modèles (voir le projet ML Max
Présentation
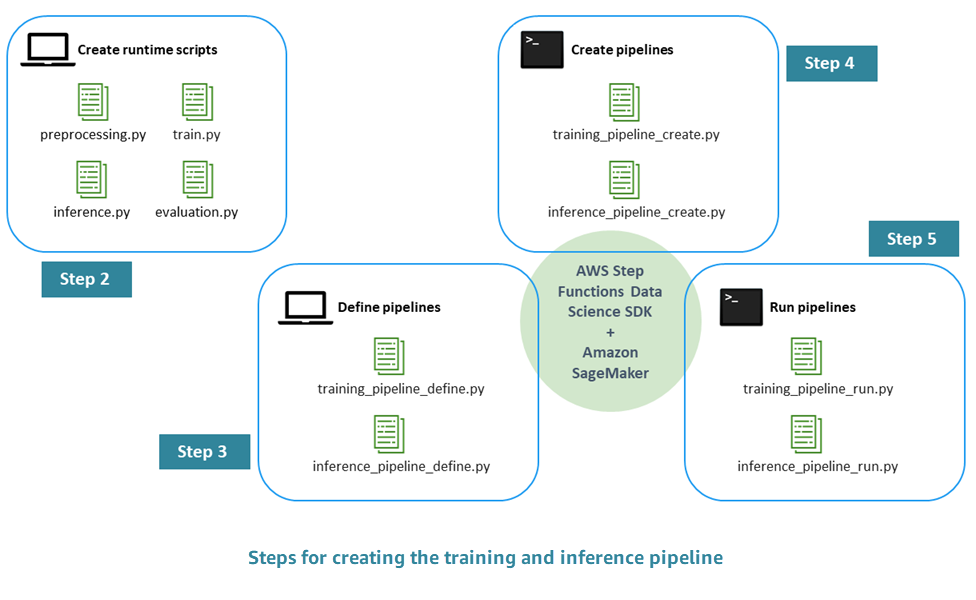
Le processus de création d'un pipeline ML prêt pour la production comprend les étapes suivantes :
-
Étape 1. Réaliser l'EDA et développer le modèle initial — Les data scientists mettent les données brutes à disposition dans Amazon Simple Storage Service (Amazon S3), effectuent une analyse exploratoire des données (EDA), développent le modèle ML initial et évaluent ses performances d'inférence. Vous pouvez effectuer ces activités de manière interactive via les blocs-notes Jupyter.
-
Étape 2. Création des scripts d'exécution : vous intégrez le modèle aux scripts Python d'exécution afin qu'il puisse être géré et provisionné par un framework ML (dans notre cas, Amazon SageMaker AI). Il s'agit de la première étape pour passer du développement interactif d'un modèle autonome à la production. Plus précisément, vous définissez séparément la logique du prétraitement, de l'évaluation, de l'entraînement et de l'inférence.
-
Étape 3. Définir le pipeline : vous définissez les espaces réservés d'entrée et de sortie pour chaque étape du pipeline. Les valeurs concrètes correspondantes seront fournies ultérieurement, pendant l'exécution (étape 5). Vous vous concentrez sur les pipelines de formation, d'inférence, de validation croisée et de backtesting.
-
Étape 4. Création du pipeline : vous créez l'infrastructure sous-jacente, y compris l'instance de machine à AWS Step Functions états de manière automatisée (presque en un clic), en utilisant AWS CloudFormation.
-
Étape 5. Exécuter le pipeline : vous exécutez le pipeline défini à l'étape 4. Vous préparez également des métadonnées et des données ou des emplacements de données pour renseigner des valeurs concrètes pour les espaces réservés d'entrée/sortie que vous avez définis à l'étape 3. Cela inclut les scripts d'exécution définis à l'étape 2 ainsi que les hyperparamètres du modèle.
-
Étape 6. Élargissez le pipeline : vous implémentez des processus d'intégration continue et de déploiement continu (CI/CD), une reconversion automatique, une inférence planifiée et des extensions similaires du pipeline.
Le schéma suivant illustre les principales étapes de ce processus.