Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques
Nous vous recommandons de suivre les meilleures pratiques techniques et de stockage. Ces bonnes pratiques peuvent vous aider à tirer le meilleur parti de votre architecture centrée sur les données.
Bonnes pratiques de stockage pour les mégadonnées
Le tableau suivant décrit une bonne pratique courante pour stocker des fichiers destinés à une charge de traitement de données volumineuses sur Amazon S3. La dernière colonne est un exemple de politique de cycle de vie que vous pouvez définir. Si Amazon S3 Intelligent-Tiering
Nom de la couche de données | Description | Exemple de stratégie de politique de cycle de vie |
Raw | Contient des données brutes non traitées Remarque : pour une source de données externe, la couche de données brutes est généralement une copie 1:1 des données, mais sur AWS, les données peuvent être partitionnées par clés en fonction de la région AWS ou de la date pendant le processus d'ingestion. | Au bout d'un an, déplacez les fichiers vers la classe de stockage S3 Standard-IA. Après deux ans passés dans S3 Standard-IA, archivez les fichiers dans Amazon Simple Storage Service Glacier (Amazon S3 Glacier). |
Étape | Contient des données traitées intermédiaires optimisées pour la consommation Exemple : fichiers bruts convertis de CSV vers Apache Parquet ou transformations de données | Vous pouvez supprimer des données après une période définie ou selon les exigences de votre organisation. Vous pouvez supprimer certains dérivés de données (par exemple, une transformation Apache Avro d'un format JSON original) du lac de données après une période plus courte (par exemple, après 90 jours). |
Analyse | Contient les données agrégées pour vos cas d'utilisation spécifiques dans un format prêt à être consommé Exemple : Apache Parquet | Vous pouvez déplacer les données vers S3 Standard-IA, puis les supprimer après une période définie ou selon les exigences de votre organisation. |
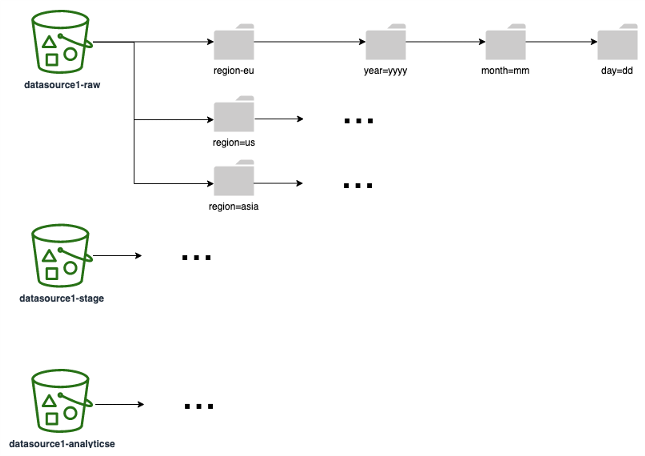
Le schéma suivant montre un exemple de stratégie de partitionnement (correspondant à un dossier/préfixe S3) que vous pouvez utiliser sur toutes les couches de données. Nous vous recommandons de choisir une stratégie de partitionnement en fonction de la manière dont vos données sont utilisées en aval. Par exemple, si les rapports sont créés à partir de vos données (les requêtes les plus courantes du rapport filtrent les résultats en fonction de la région et des dates), veillez à inclure les régions et les dates sous forme de partitions afin d'améliorer les performances et l'exécution des requêtes.
Bonnes pratiques techniques
Les meilleures pratiques techniques dépendent des services AWS et des technologies de traitement spécifiques que vous utilisez pour concevoir votre architecture centrée sur les données. Cependant, nous vous recommandons de garder à l'esprit les meilleures pratiques suivantes. Ces meilleures pratiques s'appliquent aux cas d'utilisation typiques du traitement des données.
Area | Bonne pratique |
SQL | Réduisez le volume de données à interroger en projetant des attributs sur vos données. Au lieu d'analyser la table entière, vous pouvez utiliser la projection de données pour scanner et renvoyer uniquement certaines colonnes requises dans la table. Évitez les jointures volumineuses si possible, car les jointures entre plusieurs tables peuvent avoir un impact significatif sur les performances en raison de leurs demandes gourmandes en ressources. |
Apache Spark | Optimisez les applications Spark Optimisez la gestion de la mémoire |
Conception de base de données | Suivez les bonnes pratiques en matière d'architecture pour les bases de données |
Élagage des données | Utilisez l'élagage des partitions côté serveur avec le. |
Mise à l'échelle | Comprenez et implémentez la mise à l'échelle horizontale |
