Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cas d'utilisation : prévision des résultats pour les patients et des taux de réadmission
Les analyses prédictives basées sur l'IA offrent d'autres avantages en prévoyant les résultats pour les patients et en permettant des plans de traitement personnalisés. Cela peut améliorer la satisfaction des patients et les résultats de santé. En intégrant ces capacités d'IA à Amazon Bedrock et à d'autres technologies, les prestataires de soins de santé peuvent réaliser des gains de productivité significatifs, réduire les coûts et améliorer la qualité globale des soins aux patients.
Vous pouvez stocker des données médicales, telles que les antécédents des patients, les notes cliniques, les médicaments et les traitements, dans un graphe de connaissances
Cette solution vous permet de prévoir la probabilité d'une réadmission. Ces prévisions peuvent améliorer les résultats pour les patients et réduire les coûts des soins de santé. Cette solution peut également aider les cliniciens et les administrateurs des hôpitaux à concentrer leur attention sur les patients présentant un risque élevé de réadmission. Cela les aide également à lancer des interventions proactives auprès de ces patients par le biais d'alertes, de libre-service et d'actions basées sur les données.
Présentation de la solution
Cette solution utilise un framework de génération augmentée de récupération multiple (RAG) pour analyser les données des patients. Il prédit la probabilité de réadmission à l'hôpital pour chaque patient et vous aide à calculer un score de propension à la réadmission au niveau de l'hôpital. Cette solution intègre les fonctionnalités suivantes :
-
Graphe de connaissances — Stocke des données structurées et chronologiques sur les patients, telles que les consultations à l'hôpital, les réadmissions précédentes, les symptômes, les résultats de laboratoire, les traitements prescrits et l'historique d'observance du traitement médicamenteux
-
Base de données vectorielle — Stocke des données cliniques non structurées, telles que les résumés des sorties, les notes du médecin et les enregistrements des rendez-vous manqués ou des effets secondaires signalés des médicaments
-
LLM affiné — Consomme à la fois les données structurées du graphe de connaissances et les données non structurées de la base de données vectorielles afin de générer des inférences sur le comportement du patient, l'observance du traitement et la probabilité de réadmission
Les modèles de notation des risques quantifient les inférences du LLM sous forme de scores numériques. Vous pouvez agréger les scores pour obtenir un score de propension à la réadmission au niveau de l'hôpital. Ce score définit l'exposition au risque de chaque patient, et vous pouvez le calculer périodiquement ou selon les besoins. Toutes les inférences et les scores de risque sont indexés et stockés dans Amazon OpenSearch Service afin que les responsables de soins et les cliniciens puissent les récupérer. En intégrant un agent d'intelligence artificielle conversationnel à cette base de données vectorielle, les cliniciens et les responsables de soins peuvent extraire facilement des informations au niveau du patient, de l'ensemble de l'établissement ou de la spécialité médicale. Vous pouvez également configurer des alertes automatisées en fonction des scores de risque, ce qui encourage les interventions proactives.
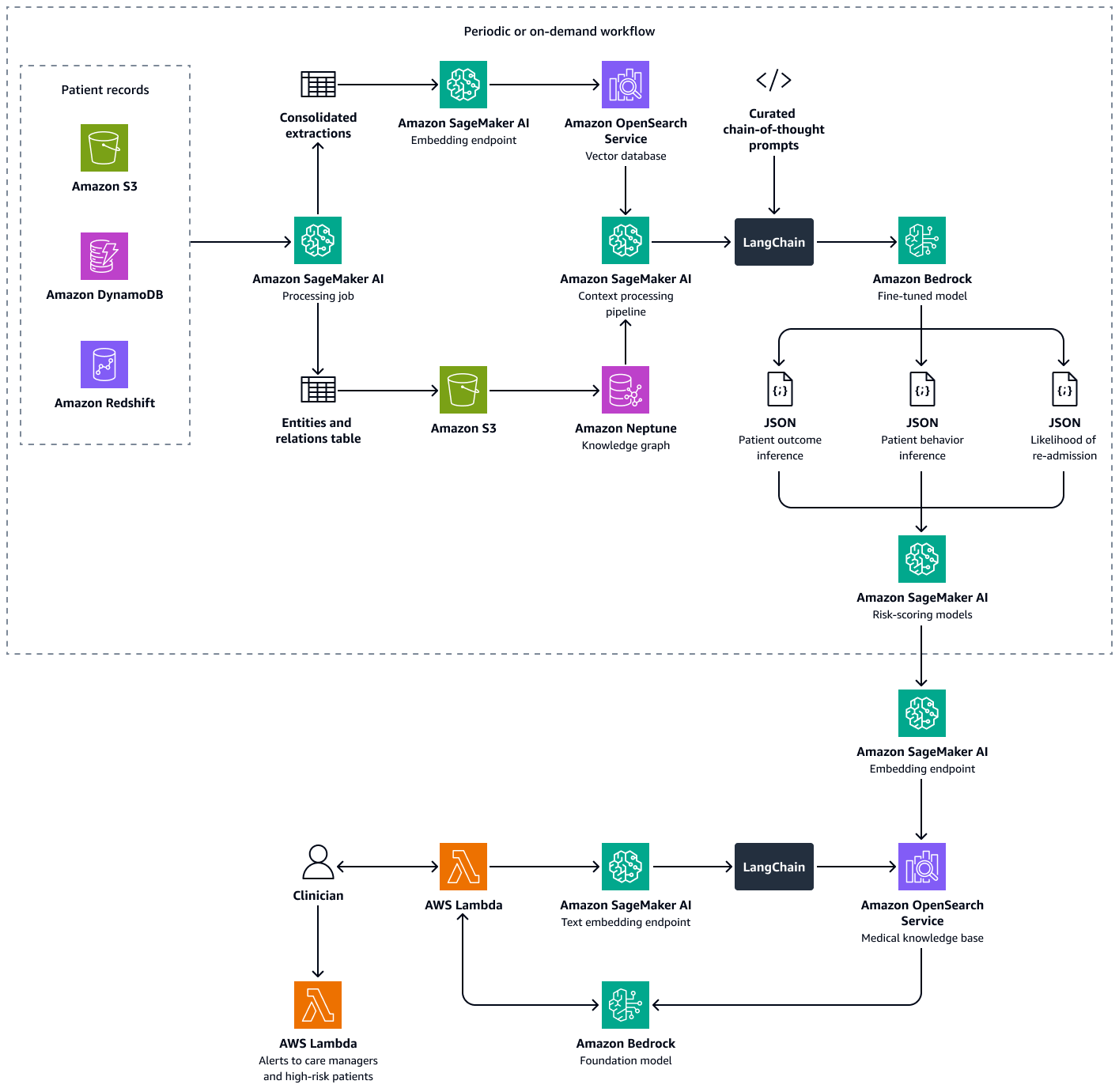
La création de cette solution comprend les étapes suivantes :
Étape 1 : Prédire les résultats des patients à l'aide d'un graphe de connaissances médicales
Dans Amazon Neptune, vous pouvez utiliser un graphe de connaissances pour stocker des informations temporelles sur les visites des patients et les résultats obtenus au fil du temps. Le moyen le plus efficace de créer et de stocker un graphe de connaissances consiste à utiliser un modèle de graphe et une base de données de graphes. Les bases de données de graphes sont spécialement conçues pour stocker et parcourir les relations. Les bases de données graphiques facilitent la modélisation et la gestion de données hautement connectées et disposent de schémas flexibles.
Le graphe de connaissances vous permet d'effectuer une analyse de séries chronologiques. Les éléments clés de la base de données de graphes utilisés pour la prédiction temporelle des résultats pour les patients sont les suivants :
-
Données historiques — Diagnostics antérieurs, traitement continu, médicaments déjà utilisés et résultats de laboratoire pour le patient
-
Visites des patients (chronologique) — Dates des visites, symptômes, allergies observées, notes cliniques, diagnostics, procédures, traitements, médicaments prescrits et résultats de laboratoire
-
Symptômes et paramètres cliniques — Informations cliniques et basées sur les symptômes, notamment la gravité, les schémas de progression et la réponse du patient au médicament
Vous pouvez utiliser les informations du graphique des connaissances médicales pour peaufiner un LLM dans Amazon Bedrock, tel que Llama 3. Vous affinez le LLM à l'aide de données séquentielles du patient concernant la réponse du patient à un ensemble de médicaments ou de traitements au fil du temps. Utilisez un ensemble de données étiqueté qui classe un ensemble de médicaments ou de traitements et de données d'interaction patient-clinique dans des catégories prédéfinies indiquant l'état de santé d'un patient. La détérioration de l'état de santé, l'amélioration ou la stabilité des progrès sont des exemples de ces catégories. Lorsque le clinicien saisit un nouveau contexte concernant le patient et ses symptômes, le LLM affiné peut utiliser les modèles de l'ensemble de données de formation afin de prédire l'issue potentielle du patient.
L'image suivante montre les étapes séquentielles nécessaires pour peaufiner un LLM dans Amazon Bedrock à l'aide d'un ensemble de données de formation spécifique au secteur de la santé. Ces données peuvent inclure l'état de santé des patients et les réponses aux traitements au fil du temps. Cet ensemble de données de formation aiderait le modèle à faire des prédictions généralisées sur les résultats pour les patients.
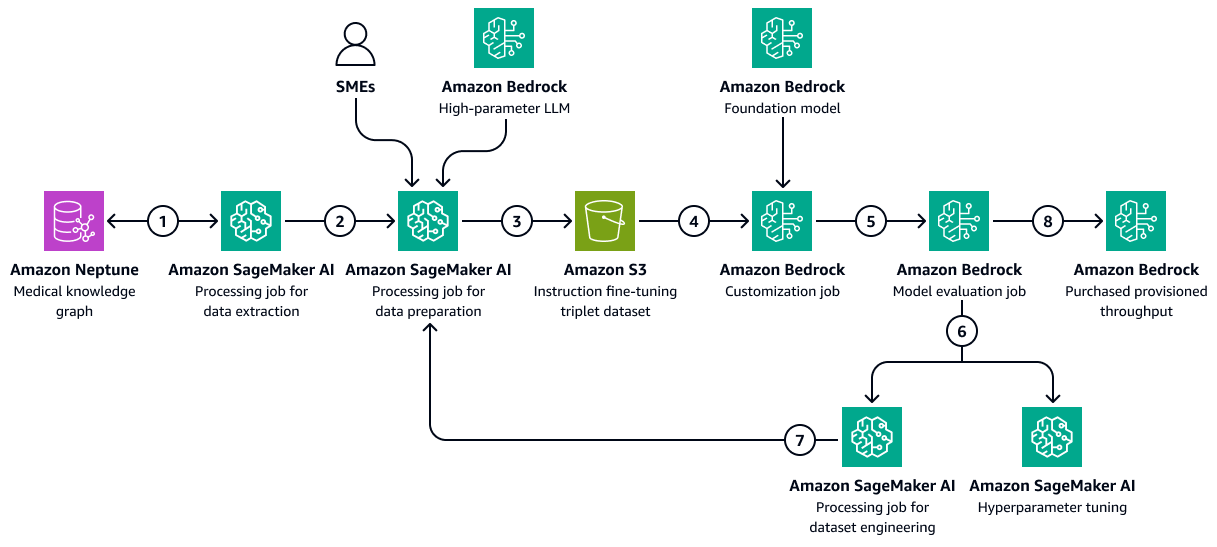
Le schéma suivant illustre le flux de travail suivant :
-
La tâche d'extraction de données Amazon SageMaker AI interroge le graphe de connaissances pour récupérer des données chronologiques sur les réponses des différents patients à un ensemble de médicaments ou de traitements au fil du temps.
-
Le travail de préparation des données basé sur l' SageMaker IA intègre un programme de maîtrise en droit d'Amazon Bedrock et des contributions d'experts en la matière ()SMEs. Le travail classe les données extraites du graphe de connaissances dans des catégories prédéfinies (telles que détérioration de l'état de santé, amélioration ou progrès stables) qui indiquent l'état de santé de chaque patient.
-
Le travail crée un ensemble de données de réglage précis qui inclut les informations extraites du graphe de connaissances, des chain-of-thought instructions et de la catégorie de résultats pour le patient. Il télécharge cet ensemble de données de formation dans un compartiment Amazon S3.
-
Une tâche de personnalisation d'Amazon Bedrock utilise cet ensemble de données de formation pour peaufiner un LLM.
-
Le travail de personnalisation d'Amazon Bedrock intègre le modèle fondamental de choix d'Amazon Bedrock dans l'environnement de formation. Il démarre le travail de réglage fin et utilise le jeu de données d'entraînement et les hyperparamètres d'entraînement que vous configurez.
-
Une tâche d'évaluation Amazon Bedrock évalue le modèle affiné à l'aide d'un cadre d'évaluation de modèle prédéfini.
-
Si le modèle doit être amélioré, la tâche de formation s'exécute à nouveau avec davantage de données après un examen attentif de l'ensemble de données d'apprentissage. Si le modèle ne montre pas d'amélioration progressive des performances, envisagez également de modifier les hyperparamètres d'entraînement.
-
Une fois que l'évaluation du modèle répond aux normes définies par les parties prenantes de l'entreprise, vous hébergez le modèle affiné sur le débit provisionné par Amazon Bedrock.
Étape 2 : Prédire le comportement du patient à l'égard des médicaments ou traitements prescrits
FineTuned LLMs peut traiter les notes cliniques, les résumés des sorties et d'autres documents spécifiques au patient à partir du graphe temporel des connaissances médicales. Ils peuvent évaluer si le patient est susceptible de suivre les médicaments ou traitements prescrits.
Cette étape utilise le graphe de connaissances créé dansÉtape 1 : Prédire les résultats des patients à l'aide d'un graphe de connaissances médicales. Le graphe de connaissances contient des données issues du profil du patient, y compris l'historique d'adhésion du patient en tant que nœud. Cela inclut également les cas de non-observance des médicaments ou des traitements, les effets secondaires des médicaments, le manque d'accès aux médicaments ou les obstacles liés au coût de ceux-ci, ou les schémas posologiques complexes comme caractéristiques de ces nœuds.
Finetuned LLMs peut utiliser les anciennes données d'exécution des ordonnances issues du graphe des connaissances médicales et les résumés descriptifs des notes cliniques provenant d'une base de données vectorielle Amazon OpenSearch Service. Ces notes cliniques peuvent mentionner des rendez-vous fréquemment manqués ou le non-respect des traitements. Le LLM peut utiliser ces notes pour prédire la probabilité d'une future non-conformité.
-
Préparez les données d'entrée comme suit :
-
Données structurées — Extrayez les données récentes des patients, telles que les trois dernières visites et les résultats de laboratoire, à partir du graphe des connaissances médicales.
-
Données non structurées : récupérez les notes cliniques récentes de la base de données vectorielle Amazon OpenSearch Service.
-
-
Créez une invite de saisie qui inclut les antécédents du patient et le contexte actuel. Voici un exemple d'invite :
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Passez l'invite au LLM peaufiné. Le LLM traite l'invite et prédit le résultat. Voici un exemple de réponse du LLM :
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
Analysez la réponse du modèle pour extraire la catégorie de résultats prédite. Par exemple, la catégorie de l'exemple de réponse de l'étape précédente peut être une forte probabilité de non-conformité.
-
(Facultatif) Utilisez des logits modèles ou des méthodes supplémentaires pour attribuer des scores de confiance. Les logits sont les probabilités non normalisées que l'objet appartienne à une certaine classe ou catégorie.
Étape 3 : Prédire la probabilité de réadmission du patient
Les réadmissions à l'hôpital sont une préoccupation majeure en raison du coût élevé de l'administration des soins de santé et de leur impact sur le bien-être du patient. Le calcul des taux de réadmission dans les hôpitaux est un moyen de mesurer la qualité des soins aux patients et les performances d'un professionnel de santé.
Pour calculer le taux de réadmission, vous avez défini un indicateur, tel qu'un taux de réadmission sur 7 jours. Cet indicateur est le pourcentage de patients admis qui retournent à l'hôpital pour une visite imprévue dans les sept jours suivant leur sortie. Pour prévoir les chances de réadmission d'un patient, un LLM affiné peut utiliser les données temporelles du graphe de connaissances médicales que vous avez créé dans. Étape 1 : Prédire les résultats des patients à l'aide d'un graphe de connaissances médicales Ce graphique de connaissances conserve des enregistrements chronologiques des rencontres avec les patients, des procédures, des médicaments et des symptômes. Ces enregistrements de données contiennent les éléments suivants :
-
Durée écoulée depuis la dernière sortie du patient
-
La réponse du patient aux traitements et médicaments antérieurs
-
L'évolution des symptômes ou des affections au fil du temps
Vous pouvez traiter ces événements chronologiques pour prédire la probabilité de réadmission d'un patient grâce à une invite du système organisée. L'invite transmet la logique de prédiction au LLM affiné.
-
Préparez les données d'entrée comme suit :
-
Historique d'observance — Extrayez les dates de prise des médicaments, les fréquences de renouvellement des médicaments, les détails du diagnostic et des médicaments, les antécédents médicaux chronologiques et d'autres informations du graphique des connaissances médicales.
-
Indicateurs comportementaux — Récupérez et incluez les notes cliniques concernant les rendez-vous manqués et les effets secondaires signalés par les patients.
-
-
Créez une invite de saisie qui inclut l'historique d'adhésion et les indicateurs comportementaux. Voici un exemple d'invite :
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Passez l'invite au LLM peaufiné. Le LLM traite l'invite et prédit la probabilité et les raisons de la réadmission. Voici un exemple de réponse du LLM :
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
Catégorisez la prédiction selon une échelle standardisée, telle que faible, moyenne ou élevée.
-
Passez en revue le raisonnement fourni par le LLM et identifiez les facteurs clés qui contribuent à la prédiction.
-
Associez les résultats qualitatifs aux scores quantitatifs. Par exemple, une probabilité très élevée peut être égale à 0,9.
-
Utilisez des ensembles de données de validation pour calibrer les résultats du modèle par rapport aux taux de réadmission réels.
Étape 4 : Calcul du score de propension à la réadmission à l'hôpital
Ensuite, vous calculez un score de propension à la réadmission à l'hôpital par patient. Ce score reflète l'impact net des trois analyses effectuées au cours des étapes précédentes : les résultats potentiels pour les patients, le comportement du patient à l'égard des médicaments et des traitements, et la probabilité de réadmission du patient. En agrégeant le score de propension à la réadmission du patient au niveau de la spécialité, puis au niveau de l'hôpital, vous pouvez obtenir des informations utiles aux cliniciens, aux responsables des soins et aux administrateurs. Le score de propension à la réadmission à l'hôpital vous permet d'évaluer le rendement global par établissement, par spécialité ou par affection. Vous pouvez ensuite utiliser ce score pour mettre en œuvre des interventions proactives.
-
Attribuez des poids à chacun des différents facteurs (prédiction des résultats, probabilité d'adhésion, réadmission). Voici des exemples de poids :
-
Poids de prédiction des résultats : 0,4
-
Poids prévisionnel d'adhérence : 0,3
-
Poids de la probabilité de réadmission : 0,3
-
-
Utilisez le calcul suivant pour calculer le score composite :
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
Assurez-vous que tous les scores individuels sont sur la même échelle, par exemple de 0 à 1.
-
Définissez les seuils d'action. Par exemple, les scores supérieurs à 0,7 déclenchent des alertes.
Sur la base des analyses ci-dessus et du score de propension à la réadmission d'un patient, les cliniciens ou les responsables de soins peuvent configurer des alertes pour surveiller leurs patients individuels sur la base du score calculé. S'il est supérieur à un seuil prédéfini, ils sont avertis lorsque ce seuil est atteint. Cela permet aux responsables des soins d'être proactifs plutôt que réactifs lorsqu'ils élaborent des plans de soins pour la sortie de leurs patients. Enregistrez les résultats, le comportement et les scores de propension des patients sous forme indexée dans une base de données vectorielle Amazon OpenSearch Service afin que les responsables de soins puissent les récupérer facilement à l'aide d'un agent d'intelligence artificielle conversationnel.
Le schéma suivant montre le flux de travail d'un agent d'IA conversationnel qu'un clinicien ou un responsable de soins peut utiliser pour obtenir des informations sur les résultats des patients, le comportement attendu et la propension à la réadmission. Les utilisateurs peuvent récupérer des informations au niveau du patient, du département ou de l'hôpital. L'agent AI récupère ces informations, qui sont stockées sous forme indexée dans une base de données vectorielle Amazon OpenSearch Service. L'agent utilise la requête pour récupérer les données pertinentes et fournit des réponses personnalisées, y compris des suggestions d'actions pour les patients présentant un risque élevé de réadmission. En fonction du niveau de risque, l'agent peut également configurer des rappels pour les patients et les soignants.
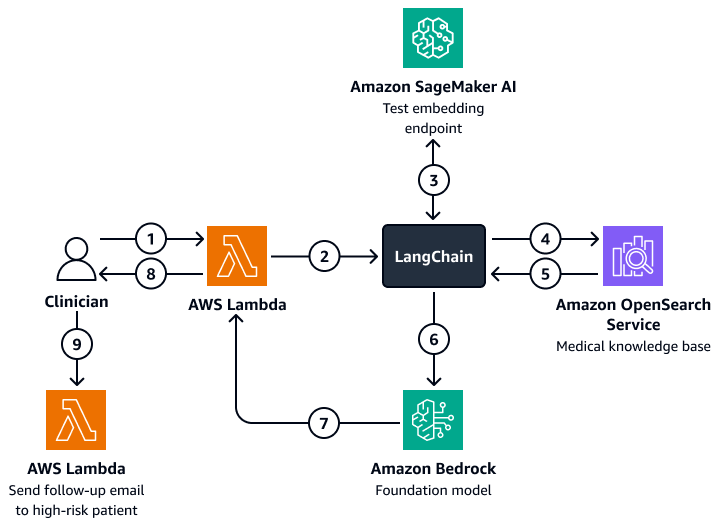
Le schéma suivant illustre le flux de travail suivant :
-
Le clinicien pose une question à un agent d'intelligence artificielle conversationnel qui héberge une AWS Lambda fonction.
-
La fonction Lambda lance un LangChain agent.
-
Le LangChain l'agent envoie la question de l'utilisateur à un point de terminaison d'intégration de texte Amazon SageMaker AI. Le point de terminaison intègre la question.
-
Le LangChain l'agent transmet la question intégrée à une base de connaissances médicales sur Amazon OpenSearch Service.
-
Amazon OpenSearch Service renvoie les informations spécifiques les plus pertinentes pour la requête de l'utilisateur au LangChain agent.
-
Le LangChain les agents envoient la requête et le contexte extrait de la base de connaissances à un modèle de base Amazon Bedrock.
-
Le modèle Amazon Bedrock Foundation génère une réponse et l'envoie à la fonction Lambda.
-
La fonction Lambda renvoie la réponse au clinicien.
-
Le clinicien lance une fonction Lambda qui envoie un e-mail de suivi à un patient présentant un risque élevé de réadmission.
Alignement sur le framework AWS Well-Architected
-
Excellence opérationnelle — La solution est un système découplé et automatisé qui utilise Amazon Bedrock et AWS Lambda fournit des alertes en temps réel.
-
Sécurité — Cette solution est conçue pour se conformer aux réglementations sanitaires, telles que la loi HIPAA. Vous pouvez également implémenter le chiffrement, un contrôle d'accès précis et des garde-corps Amazon Bedrock pour protéger les données des patients.
-
Fiabilité — L'architecture utilise un système sans serveur tolérant aux pannes. Services AWS
-
Efficacité des performances — Amazon OpenSearch Service et le service affiné LLMs peuvent fournir des prévisions rapides et précises.
-
Optimisation des coûts — Les technologies et les pay-per-inference modèles sans serveur permettent de minimiser les coûts. Bien qu'un LLM affiné puisse entraîner des frais supplémentaires, le modèle utilise une approche RAG qui réduit les données et le temps de calcul nécessaires au processus de réglage précis.
-
Durabilité — L'architecture minimise la consommation de ressources grâce à l'utilisation d'une infrastructure sans serveur. Il soutient également des opérations de santé efficaces et évolutives.
