Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Cas d'utilisation : gestion et renforcement des compétences de votre personnel de santé
La mise en œuvre de stratégies de transformation des talents et de renforcement des compétences aide les travailleurs à rester aptes à utiliser les nouvelles technologies et pratiques dans les services médicaux et de santé. Les initiatives proactives de renforcement des compétences permettent aux professionnels de santé de fournir des soins de haute qualité aux patients, d'optimiser l'efficacité opérationnelle et de respecter les normes réglementaires. De plus, la transformation des talents favorise une culture d'apprentissage continu. Cela est essentiel pour s'adapter à l'évolution du paysage des soins de santé et relever les nouveaux défis de santé publique. Les approches de formation traditionnelles, telles que la formation en classe et les modules d'apprentissage statiques, offrent un contenu uniforme à un large public. Ils ne disposent souvent pas de parcours d'apprentissage personnalisés, essentiels pour répondre aux besoins spécifiques et aux niveaux de compétence de chaque praticien. Cette one-size-fits-all stratégie peut entraîner un désengagement et une rétention des connaissances sous-optimale.
Par conséquent, les établissements de santé doivent adopter des solutions innovantes, évolutives et axées sur la technologie qui peuvent déterminer l'écart entre la situation actuelle et la situation future de chacun de leurs employés. Ces solutions devraient recommander des parcours d'apprentissage hyperpersonnalisés et le bon ensemble de contenus d'apprentissage. Cela prépare efficacement le personnel au futur des soins de santé.
Dans le secteur de la santé, vous pouvez appliquer l'IA générative pour vous aider à comprendre et à améliorer les compétences de votre personnel. En connectant de grands modèles linguistiques (LLMs) et des outils de recherche avancés, les organisations peuvent comprendre les compétences dont elles disposent actuellement et identifier les compétences clés qui pourraient être nécessaires à l'avenir. Ces informations vous aident à combler le fossé en recrutant de nouveaux travailleurs et en améliorant les compétences de la main-d'œuvre actuelle. À l'aide d'Amazon Bedrock et des graphes de connaissances, les établissements de santé peuvent développer des applications spécifiques à un domaine qui facilitent l'apprentissage continu et le développement des compétences.
Les connaissances fournies par cette solution vous aident à gérer efficacement les talents, à optimiser les performances du personnel, à favoriser le succès de l'organisation, à identifier les compétences existantes et à élaborer une stratégie de gestion des talents. Cette solution peut vous aider à effectuer ces tâches en quelques semaines au lieu de plusieurs mois.
Présentation de la solution
Cette solution est un cadre de transformation des talents du secteur de la santé qui comprend les éléments suivants :
-
Analyseur de CV intelligent — Ce composant peut lire le CV d'un candidat et extraire avec précision les informations relatives au candidat, y compris ses compétences. Solution intelligente d'extraction d'informations conçue à l'aide du modèle Llama 2 affiné d'Amazon Bedrock sur un ensemble de données de formation exclusif couvrant les CV et les profils de talents de plus de 19 secteurs d'activité. Ce processus basé sur le LLM permet d'économiser des centaines d'heures en automatisant le processus de révision manuelle des CV et en faisant correspondre les meilleurs candidats aux postes vacants.
-
Graphe de connaissances : graphe de connaissances basé sur Amazon Neptune, un référentiel unifié d'informations sur les talents, y compris la taxonomie des rôles et des compétences de l'organisation et du secteur, qui capture la sémantique des talents du secteur de la santé à l'aide de définitions des compétences, des rôles et de leurs propriétés, des relations et des contraintes logiques.
-
Ontologie des compétences — La découverte de la proximité des compétences entre les compétences des candidats et les compétences de l'état actuel ou futur idéales (récupérées à l'aide d'un graphe de connaissances) est réalisée grâce à des algorithmes d'ontologie qui mesurent la similitude sémantique entre les compétences des candidats et les compétences de l'état cible.
-
Parcours et contenu d'apprentissage — Ce composant est un moteur de recommandation pédagogique capable de recommander le bon contenu d'apprentissage à partir d'un catalogue de supports d'apprentissage de n'importe quel fournisseur en fonction des lacunes de compétences identifiées. Identifier les parcours de perfectionnement les plus optimaux pour chaque candidat en analysant les lacunes en matière de compétences et en recommandant des contenus d'apprentissage prioritaires, afin de permettre un développement professionnel continu et fluide pour chaque candidat pendant la transition vers un nouveau poste.
Cette solution automatisée basée sur le cloud est alimentée par des services d'apprentissage automatique LLMs, des graphes de connaissances et la génération augmentée de récupération (RAG). Il peut évoluer pour traiter des dizaines ou des milliers de CV en un minimum de temps, créer des profils de candidats instantanés, identifier les lacunes dans leur état actuel ou futur potentiel, puis recommander efficacement le contenu de formation approprié pour combler ces lacunes.
L'image suivante montre le end-to-end flux du framework. La solution est basée sur Amazon Bedrock affiné LLMs . Ils LLMs extraient des données de la base de connaissances sur les talents du secteur de la santé d'Amazon Neptune. Les algorithmes basés sur les données fournissent des recommandations pour des parcours d'apprentissage optimaux pour chaque candidat.
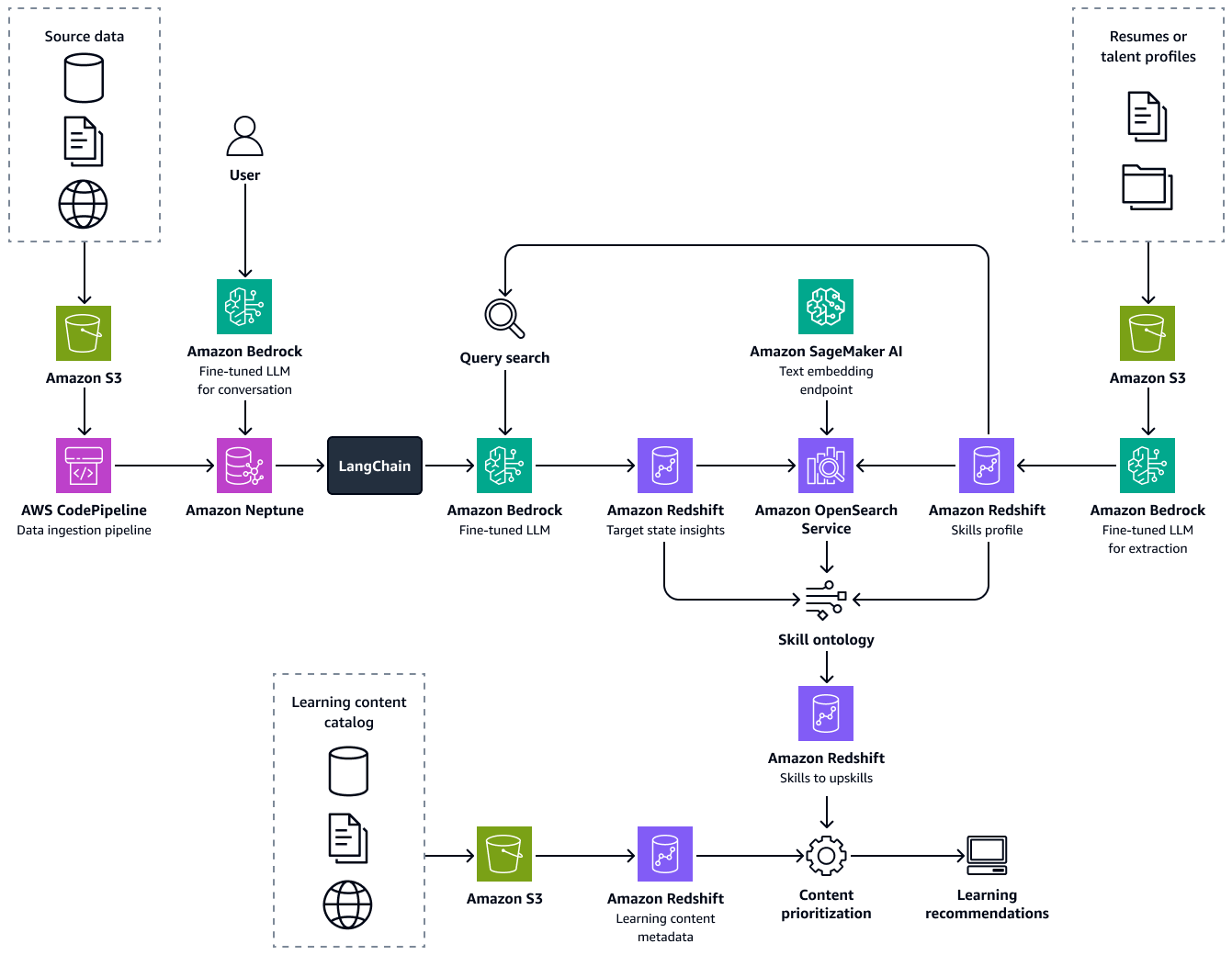
La création de cette solution comprend les étapes suivantes :
Étape 1 : Extraction des informations sur les talents et établissement d'un profil de compétences
Tout d'abord, vous peaufinez un grand modèle de langage, tel que Llama 2, dans Amazon Bedrock à l'aide d'un ensemble de données personnalisé. Cela adapte le LLM au cas d'utilisation. Au cours de la formation, vous extrayez de manière précise et cohérente les principaux attributs des talents des CV des candidats ou de profils de talents similaires. Ces attributs de talent incluent les compétences, le titre du poste actuel, les titres d'expérience avec dates, la formation et les certifications. Pour plus d'informations, consultez la section Personnaliser votre modèle afin d'améliorer ses performances pour votre cas d'utilisation dans la documentation Amazon Bedrock.
L'image suivante montre le processus permettant de peaufiner un modèle d'analyse de CV à l'aide d'Amazon Bedrock. Les CV réels et synthétiques sont transmis à un LLM afin d'en extraire des informations clés. Un groupe de data scientists valide les informations extraites par rapport au texte brut d'origine. Les informations extraites sont ensuite concaténées à l'aide d'chain-of-thought
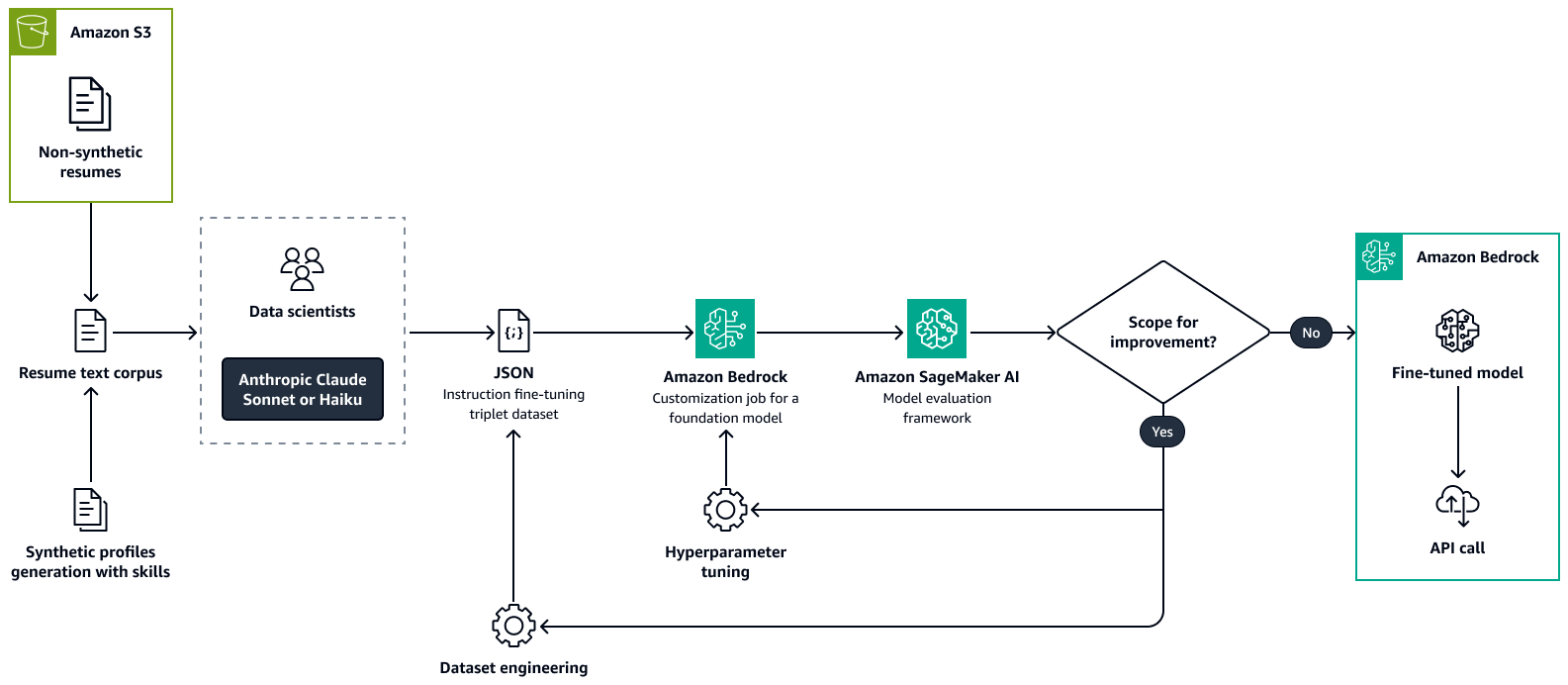
Étape 2 : Découverte de la role-to-skill pertinence à partir d'un graphe de connaissances
Ensuite, vous créez un graphe de connaissances qui résume les compétences et la taxonomie des rôles de votre organisation et des autres organisations du secteur de la santé. Cette base de connaissances enrichie provient de données agrégées sur les talents et les organisations dans Amazon Redshift. Vous pouvez recueillir des données sur les talents auprès de divers fournisseurs de données sur le marché du travail et de sources de données structurées et non structurées spécifiques à l'organisation, telles que les systèmes de planification des ressources d'entreprise (ERP), les systèmes d'information sur les ressources humaines (HRIS), les CV des employés, les descriptions de poste et les documents relatifs à l'architecture des talents.
Créez le graphe de connaissances sur Amazon Neptune. Les nœuds représentent les compétences et les rôles, tandis que les arêtes représentent les relations entre eux. Enrichissez ce graphique avec des métadonnées pour inclure des détails tels que le nom de l'organisation, le secteur d'activité, la famille d'emplois, le type de compétence, le type de rôle et les tags sectoriels.
Ensuite, vous développez une application Graph Retrieval Augmented Generation (Graph RAG). Graph RAG est une approche RAG qui récupère les données d'une base de données de graphes. Les composants de l'application Graph RAG sont les suivants :
-
Intégration avec un LLM dans Amazon Bedrock — L'application utilise un LLM dans Amazon Bedrock pour comprendre le langage naturel et générer des requêtes. Les utilisateurs peuvent interagir avec le système en utilisant le langage naturel. Cela le rend accessible aux parties prenantes non techniques.
-
Orchestration et récupération d'informations — Utilisation ou LlamaIndex
LangChain des orchestrateurs pour faciliter l'intégration entre le LLM et le graphe de connaissances Neptune. Ils gèrent le processus de conversion des requêtes en langage naturel en requêtes OpenCypher . Ils exécutent ensuite les requêtes sur le graphe de connaissances. Utilisez une ingénierie rapide pour informer le LLM des meilleures pratiques pour créer des requêtes OpenCypher. Cela permet d'optimiser les requêtes pour récupérer le sous-graphe pertinent, qui contient toutes les entités et relations pertinentes concernant les rôles et les compétences demandés. -
Génération d'informations — Le LLM d'Amazon Bedrock traite les données graphiques récupérées. Il génère des informations détaillées sur l'état actuel et projette les états futurs pour le rôle demandé et les compétences associées.
L'image suivante montre les étapes à suivre pour créer un graphe de connaissances à partir des données sources. Vous transmettez les données sources structurées et non structurées au pipeline d'ingestion de données. Le pipeline extrait et transforme les informations en une formation de chargement groupé CSV compatible avec Amazon Neptune. L'API Bulk Loader télécharge les fichiers CSV stockés dans un compartiment Amazon S3 vers le graphe de connaissances Neptune. Pour les requêtes des utilisateurs relatives aux talents, à l'état futur, aux rôles pertinents ou aux compétences, le LLM affiné d'Amazon Bedrock interagit avec le graphe de connaissances via un LangChain orchestrateur. L'orchestrateur extrait le contexte pertinent à partir du graphe de connaissances et transmet les réponses au tableau d'informations d'Amazon Redshift. Le LangChain Un orchestrateur, comme Graph QAChain

Étape 3 : Identifier les lacunes en matière de compétences et recommander une formation
Au cours de cette étape, vous calculez avec précision la proximité entre l'état actuel d'un professionnel de santé et les futurs rôles gouvernementaux potentiels. Pour ce faire, vous effectuez une analyse d'affinité des compétences en comparant les compétences de l'individu avec le rôle professionnel. Dans une base de données vectorielle Amazon OpenSearch Service, vous stockez les informations de taxonomie des compétences et les métadonnées des compétences, telles que la description des compétences, le type de compétence et les groupes de compétences. Utilisez un modèle d'intégration Amazon Bedrock, tel que les modèles Amazon Titan Text Embeddings, pour intégrer la compétence clé identifiée dans des vecteurs. Grâce à une recherche vectorielle, vous pouvez récupérer les descriptions des compétences de l'état actuel et des compétences de l'état cible et effectuer une analyse ontologique. L'analyse fournit des scores de proximité entre les paires de compétences de l'État actuel et de l'État cible. Pour chaque paire, vous utilisez les scores ontologiques calculés pour identifier les écarts dans les affinités de compétences. Ensuite, vous recommandez la voie optimale pour le renforcement des compétences, que le candidat peut envisager lors des transitions de rôle.
Pour chaque rôle, la recommandation du contenu d'apprentissage approprié à des fins de perfectionnement ou de requalification implique une approche systématique qui commence par la création d'un catalogue complet de contenus d'apprentissage. Ce catalogue, que vous stockez dans une base de données Amazon Redshift, regroupe le contenu de différents fournisseurs et inclut des métadonnées, telles que la durée du contenu, le niveau de difficulté et le mode d'apprentissage. L'étape suivante consiste à extraire les compétences clés proposées par chaque élément de contenu, puis à les associer aux compétences individuelles requises pour le rôle cible. Vous réalisez cette cartographie en analysant la couverture fournie par le contenu grâce à une analyse de proximité des compétences. Cette analyse évalue dans quelle mesure les compétences enseignées par le contenu correspondent aux compétences souhaitées pour le poste. Les métadonnées jouent un rôle essentiel dans la sélection du contenu le plus approprié pour chaque compétence, en veillant à ce que les apprenants reçoivent des recommandations personnalisées adaptées à leurs besoins d'apprentissage. LLMs Utilisez-le dans Amazon Bedrock pour extraire des compétences des métadonnées du contenu, effectuer l'ingénierie des fonctionnalités et valider les recommandations de contenu. Cela améliore la précision et la pertinence du processus de mise à niveau ou de requalification.
Alignement sur le framework AWS Well-Architected
La solution s'aligne sur les six piliers du AWS Well-Architected
-
Excellence opérationnelle — Un pipeline modulaire et automatisé améliore l'excellence opérationnelle. Les composants clés du pipeline sont découplés et automatisés, ce qui permet d'accélérer les mises à jour des modèles et de faciliter la surveillance. De plus, les pipelines de formation automatisés permettent de publier plus rapidement des modèles affinés.
-
Sécurité — Cette solution traite les informations sensibles et personnellement identifiables (PII), telles que les données figurant dans les CV et les profils de talents. Dans AWS Identity and Access Management (IAM), mettez en œuvre des politiques de contrôle d'accès précises et assurez-vous que seul le personnel autorisé a accès à ces données.
-
Fiabilité — La solution utilise des Services AWS outils tels que Neptune, Amazon Bedrock et OpenSearch Service, qui offrent une tolérance aux pannes, une haute disponibilité et un accès ininterrompu aux informations, même en cas de forte demande.
-
Efficacité des performances : optimisées LLMs dans Amazon Bedrock et OpenSearch Service, les bases de données vectorielles sont conçues pour traiter rapidement et avec précision de grands ensembles de données afin de fournir des recommandations d'apprentissage personnalisées en temps opportun.
-
Optimisation des coûts — Cette solution utilise une approche RAG, qui réduit le besoin de pré-entraînement continu des modèles. Au lieu de peaufiner l'ensemble du modèle à plusieurs reprises, le système ne peaufine que des processus spécifiques, tels que l'extraction d'informations à partir de CV et la structuration des résultats. Cela se traduit par des économies de coûts importantes. En minimisant la fréquence et l'ampleur de la formation des modèles gourmands en ressources et en utilisant les services pay-per-use cloud, les établissements de santé peuvent optimiser leurs coûts opérationnels tout en maintenant des performances élevées.
-
Durabilité — Cette solution utilise des services évolutifs et natifs du cloud qui allouent les ressources informatiques de manière dynamique. Cela permet de réduire la consommation d'énergie et l'impact environnemental tout en soutenant les initiatives de transformation des talents à grande échelle et gourmandes en données.
