Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Retrievers pour les flux de travail RAG
Cette section explique comment créer un retriever. Vous pouvez utiliser une solution de recherche sémantique entièrement gérée, telle qu'Amazon Kendra, ou créer une recherche sémantique personnalisée à l'aide AWS d'une base de données vectorielle.
Avant de passer en revue les options du récupérateur, assurez-vous de bien comprendre les trois étapes du processus de recherche vectorielle :
-
Vous séparez les documents qui doivent être indexés en parties plus petites. C'est ce qu'on appelle le découpage.
-
Vous utilisez un processus appelé incorporation
pour convertir chaque segment en un vecteur mathématique. Ensuite, vous indexez chaque vecteur dans une base de données vectorielle. L'approche que vous utilisez pour indexer les documents influence la rapidité et la précision de la recherche. L'approche d'indexation dépend de la base de données vectorielle et des options de configuration qu'elle fournit. -
Vous convertissez la requête utilisateur en vecteur en utilisant le même processus. Le récupérateur recherche dans la base de données vectorielle des vecteurs similaires au vecteur de requête de l'utilisateur. La similarité
est calculée à l'aide de mesures telles que la distance euclidienne, la distance en cosinus ou le produit ponctuel.
Ce guide explique comment utiliser les services suivants Services AWS ou des services tiers pour créer une couche de récupération personnalisée sur AWS :
Amazon Kendra
Amazon Kendra est un service de recherche intelligent entièrement géré qui utilise le traitement du langage naturel et des algorithmes d'apprentissage automatique avancés pour renvoyer des réponses spécifiques aux questions de recherche à partir de vos données. Amazon Kendra vous permet d'ingérer directement des documents provenant de sources multiples et d'interroger les documents une fois qu'ils ont été correctement synchronisés. Le processus de synchronisation crée l'infrastructure nécessaire pour créer une recherche vectorielle sur le document ingéré. Par conséquent, Amazon Kendra ne nécessite pas les trois étapes traditionnelles du processus de recherche vectorielle. Après la synchronisation initiale, vous pouvez utiliser un calendrier défini pour gérer l'ingestion continue.
Les avantages de l'utilisation d'Amazon Kendra pour RAG sont les suivants :
-
Il n'est pas nécessaire de gérer une base de données vectorielle car Amazon Kendra gère l'intégralité du processus de recherche vectorielle.
-
Amazon Kendra contient des connecteurs prédéfinis pour les sources de données les plus courantes, telles que les bases de données, les robots d'exploration de sites Web, les compartiments Amazon S3, Microsoft SharePoint les instances et les instances. Atlassian Confluence Des connecteurs développés par AWS des partenaires sont disponibles, tels que des connecteurs pour Box etGitLab.
-
Amazon Kendra fournit un filtrage par liste de contrôle d'accès (ACL) qui renvoie uniquement les documents auxquels l'utilisateur final a accès.
-
Amazon Kendra peut améliorer les réponses en fonction des métadonnées, telles que la date ou le référentiel des sources.
L'image suivante montre un exemple d'architecture qui utilise Amazon Kendra comme couche de récupération du système RAG. Pour plus d'informations, consultez Création rapide d'applications d'IA générative de haute précision sur des données d'entreprise à l'aide d'Amazon Kendra LangChain et de grands modèles linguistiques
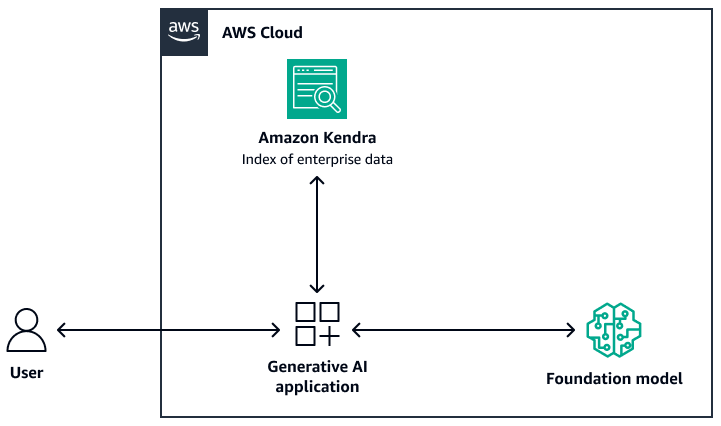
Pour le modèle de base, vous pouvez utiliser Amazon Bedrock ou un LLM déployé via Amazon SageMaker AI. JumpStart Vous pouvez utiliser AWS Lambda with LangChain
Amazon OpenSearch Service
Amazon OpenSearch Service fournit des algorithmes ML intégrés pour la recherche des voisins les plus proches (k-NN) afin d'effectuer une recherche
Les avantages de l'utilisation de OpenSearch Service pour la recherche vectorielle sont les suivants :
-
Il fournit un contrôle complet sur la base de données vectorielle, y compris la création d'une recherche vectorielle évolutive à l'aide de OpenSearch Serverless.
-
Il permet de contrôler la stratégie de segmentation.
-
Il utilise les algorithmes du voisin le plus proche (ANN) approximatifs issus des bibliothèques Non-Metric Space Library (NMSLIB)
, Faiss et Apache Lucene pour effectuer une recherche K-nn. Vous pouvez modifier l'algorithme en fonction du cas d'utilisation. Pour plus d'informations sur les options de personnalisation de la recherche vectorielle via OpenSearch Service, consultez les fonctionnalités de la base de données vectorielle Amazon OpenSearch Service expliquées (article de AWS blog). -
OpenSearch Serverless s'intègre aux bases de connaissances Amazon Bedrock sous forme d'index vectoriel.
Amazon Aurora, PostgreSQL et pgvector
Amazon Aurora PostgreSQL Compatible Edition est un moteur de base de données relationnelle entièrement géré qui vous aide à configurer, exploiter et dimensionner les déploiements PostgreSQL. pgvector
Les avantages de l'utilisation de pgvector et de la compatibilité avec Aurora PostgreSQL sont les suivants :
-
Il prend en charge la recherche exacte et approximative du voisin le plus proche. Il prend également en charge les métriques de similarité suivantes : distance L2, produit intérieur et distance en cosinus.
-
Il prend en charge les fichiers inversés avec compression plate (IVFFlat)
et l'indexation Hierarchical Navigable Small Worlds (HNSW ). -
Vous pouvez combiner la recherche vectorielle avec des requêtes portant sur des données spécifiques à un domaine disponibles dans la même instance de PostgreSQL.
-
La compatibilité avec Aurora PostgreSQL est optimisée I/O et fournit une mise en cache hiérarchisée. Pour les charges de travail qui dépassent la mémoire d'instance disponible, pgvector peut augmenter le nombre de requêtes par seconde pour la recherche vectorielle jusqu'à 8 fois.
Amazon Neptune Analytics
Amazon Neptune Analytics est un moteur de base de données graphique optimisé pour la mémoire à des fins d'analyse. Il prend en charge une bibliothèque d'algorithmes d'analyse de graphes optimisés, des requêtes graphiques à faible latence et des fonctionnalités de recherche vectorielle dans le cadre des traversées de graphes. Il dispose également d'une recherche de similarité vectorielle intégrée. Il fournit un point de terminaison pour créer un graphe, charger des données, invoquer des requêtes et effectuer une recherche de similarité vectorielle. Pour plus d'informations sur la création d'un système basé sur RAG qui utilise Neptune Analytics, consultez Utilisation de graphes de connaissances pour créer des applications GraphRag avec Amazon Bedrock et Amazon
Les avantages de l'utilisation de Neptune Analytics sont les suivants :
-
Vous pouvez stocker et rechercher des intégrations dans des requêtes graphiques.
-
Si vous intégrez Neptune AnalyticsLangChain, cette architecture prend en charge les requêtes graphiques en langage naturel.
-
Cette architecture stocke de grands ensembles de données graphiques en mémoire.
Amazon MemoryDB
Amazon MemoryDB est un service de base de données en mémoire durable qui fournit des performances ultrarapides. Toutes vos données sont stockées en mémoire, ce qui permet une lecture en microsecondes, une latence d'écriture d'un chiffre en millisecondes et un débit élevé. La recherche vectorielle pour MemoryDB étend les fonctionnalités de MemoryDB et peut être utilisée conjointement avec les fonctionnalités MemoryDB existantes. Pour plus d'informations, consultez le référentiel de réponses aux questions avec LLM et RAG
Le schéma suivant montre un exemple d'architecture qui utilise MemoryDB comme base de données vectorielle.
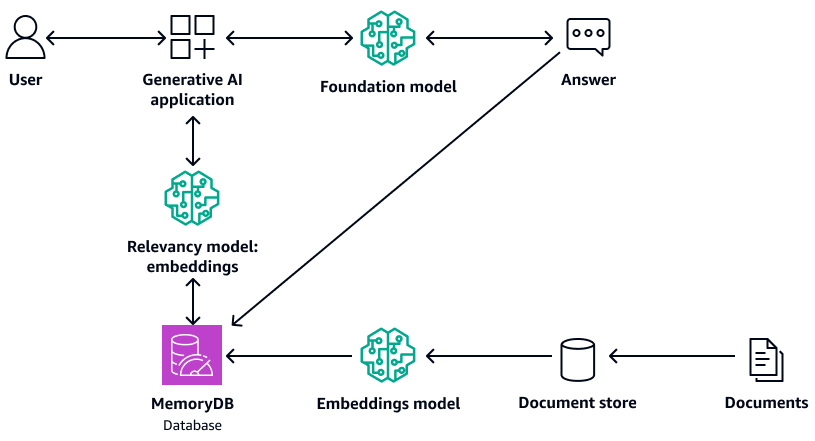
Les avantages de l'utilisation de MemoryDB sont les suivants :
-
Il prend en charge les algorithmes d'indexation Flat et HNSW. Pour plus d'informations, consultez la section La recherche vectorielle pour Amazon MemoryDB est désormais disponible pour tous
sur le AWS blog d'actualités -
Il peut également servir de mémoire tampon pour le modèle de base. Cela signifie que les questions auxquelles vous avez déjà répondu sont extraites de la mémoire tampon au lieu de recommencer le processus de récupération et de génération. Le schéma suivant illustre ce processus.
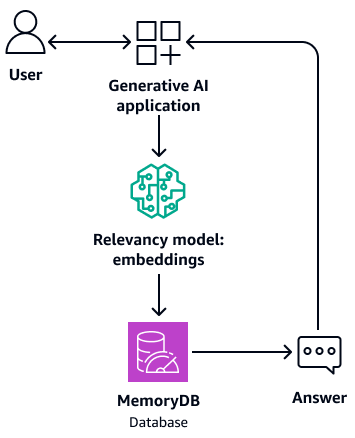
-
Comme elle utilise une base de données en mémoire, cette architecture fournit un temps de requête à un chiffre en millisecondes pour la recherche sémantique.
-
Il fournit jusqu'à 33 000 requêtes par seconde avec un taux de rappel de 95 à 99 % et 26 500 requêtes par seconde avec un taux de rappel supérieur à 99 %. Pour plus d'informations, consultez la vidéo AWS re:Invent 2023 - Recherche vectorielle à très faible latence pour Amazon MemoryDB sur
. YouTube
Amazon DocumentDB
Amazon DocumentDB (compatible avec MongoDB) est un service de base de données rapide, fiable et entièrement géré. Il facilite la configuration, l'exploitation et le dimensionnement de bases de données MongoDB compatibles dans le cloud. La recherche vectorielle pour Amazon DocumentDB associe la flexibilité et la riche capacité d'interrogation d'une base de données de documents basée sur JSON à la puissance de la recherche vectorielle. Pour plus d'informations, consultez le référentiel de réponses aux questions avec LLM et RAG
Le schéma suivant montre un exemple d'architecture qui utilise Amazon DocumentDB comme base de données vectorielle.
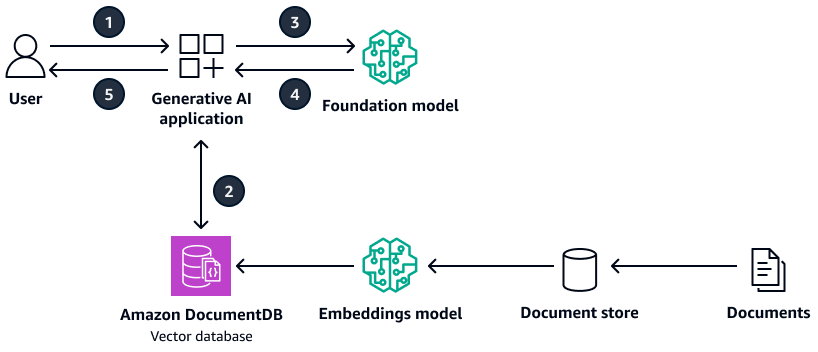
Le schéma suivant illustre le flux de travail suivant :
-
L'utilisateur soumet une requête à l'application d'IA générative.
-
L'application d'IA générative effectue une recherche de similarité dans la base de données vectorielle Amazon DocumentDB et extrait les extraits de documents pertinents.
-
L'application d'IA générative met à jour la requête de l'utilisateur avec le contexte extrait et soumet l'invite au modèle de base cible.
-
Le modèle de base utilise le contexte pour générer une réponse à la question de l'utilisateur et renvoie la réponse.
-
L'application d'IA générative renvoie la réponse à l'utilisateur.
Les avantages de l'utilisation d'Amazon DocumentDB sont les suivants :
-
Il prend en charge à la fois les méthodes HNSW et les IVFFlat méthodes d'indexation.
-
Il prend en charge jusqu'à 2 000 dimensions dans les données vectorielles et prend en charge les mesures de distance entre les produits euclidiens, cosinusoïdaux et points.
-
Il fournit des temps de réponse en millisecondes.
Pinecone
Pinecone
Le schéma suivant montre un exemple d'architecture utilisé Pinecone comme base de données vectorielle.

Le schéma suivant illustre le flux de travail suivant :
-
L'utilisateur soumet une requête à l'application d'IA générative.
-
L'application d'IA générative effectue une recherche de similarité dans la base de données Pinecone vectorielle et récupère les extraits de documents pertinents.
-
L'application d'IA générative met à jour la requête de l'utilisateur avec le contexte extrait et soumet l'invite au modèle de base cible.
-
Le modèle de base utilise le contexte pour générer une réponse à la question de l'utilisateur et renvoie la réponse.
-
L'application d'IA générative renvoie la réponse à l'utilisateur.
Les avantages de l'utilisation sont les Pinecone suivants :
-
Il s'agit d'une base de données vectorielle entièrement gérée qui vous évite de devoir gérer votre propre infrastructure.
-
Il fournit des fonctionnalités supplémentaires de filtrage, de mise à jour d'index en direct et de renforcement des mots clés (recherche hybride).
MongoDB Atlas
MongoDB
Atlas
Pour plus d'informations sur l'utilisation de la recherche MongoDB Atlas vectorielle pour RAG, consultez Retrieval-Augmented Generation with, LangChain Amazon SageMaker AI JumpStart et MongoDB Atlas Semantic Search
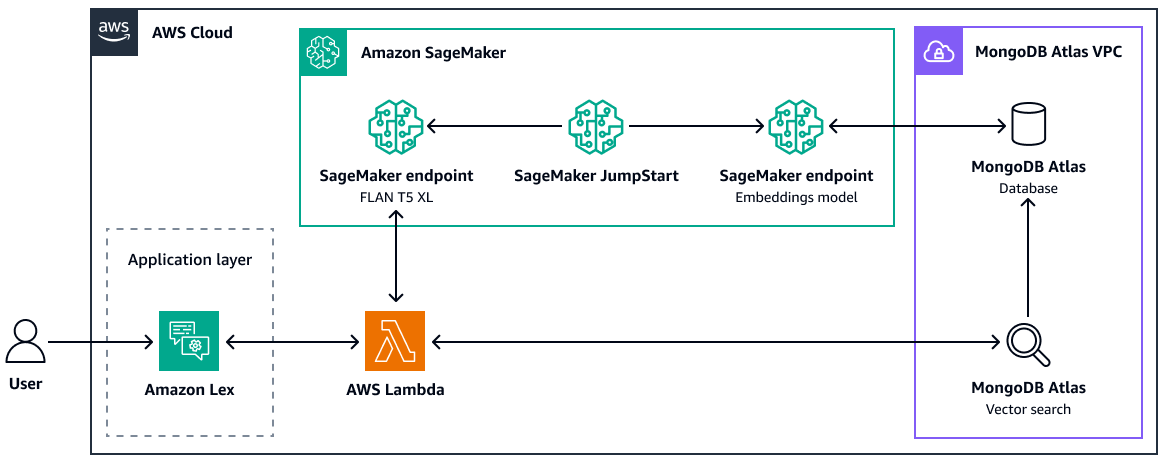
Les avantages de la recherche MongoDB Atlas vectorielle sont les suivants :
-
Vous pouvez utiliser votre implémentation existante MongoDB Atlas pour stocker et rechercher des intégrations vectorielles.
-
Vous pouvez utiliser l'API MongoDB Query
pour interroger les intégrations vectorielles. -
Vous pouvez redimensionner indépendamment la recherche vectorielle et la base de données.
-
Les intégrations vectorielles sont stockées à proximité des données sources (documents), ce qui améliore les performances d'indexation.
Weaviate
Weaviate
Les avantages de l'utilisation sont les Weaviate suivants :
-
Il est open source et soutenu par une communauté solide.
-
Il est conçu pour la recherche hybride (vecteurs et mots clés).
-
Vous pouvez le déployer en AWS tant qu'offre de logiciel géré en tant que service (SaaS) ou en tant que cluster Kubernetes.
