Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture
Le schéma suivant décrit l'architecture de la solution décrite dans ce guide. Une AWS Glue tâche lit les données d'un bucket Amazon Simple Storage Service (Amazon S3), un service de stockage d'objets basé sur le cloud qui vous permet de stocker, de protéger et de récupérer des données. Vous pouvez lancer le AWS Glue Spark SQL tâche via le AWS Management Console, AWS Command Line Interface (AWS CLI) ou l' AWS Glue API. Le AWS Glue Spark SQL job traite les données brutes dans un compartiment Amazon S3, puis stocke les données traitées dans un autre compartiment.
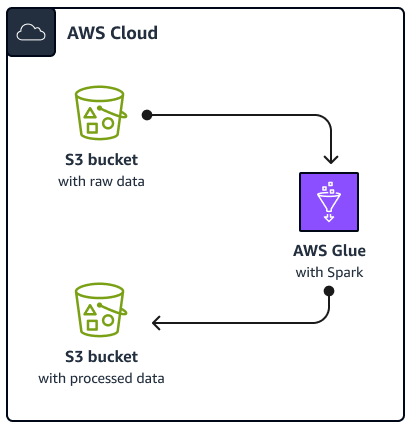
À titre d'exemple, ce guide décrit un AWS GlueSpark SQL job, qui est écrit en Python and Spark SQL (PySpark). Ce AWS Glue travail est utilisé pour démontrer les meilleures pratiques pour Spark SQL réglage. Bien que ce guide se concentre sur AWS Glue, les meilleures pratiques de ce guide s'appliquent également à Amazon EMR Spark SQL emplois.
Le schéma suivant décrit le cycle de vie d'un Spark SQL requête. Le Spark SQL Catalyst Optimizer génère un plan de requêtes. Un plan de requête est une série d'étapes, telles que des instructions, utilisées pour accéder aux données d'un système de base de données relationnelle SQL. Pour développer une solution optimisée pour les performances Spark
SQL plan de requête, la première étape consiste à visualiser le EXPLAIN plan, à l'interpréter, puis à l'ajuster. Vous pouvez utiliser le plugin Spark SQL interface utilisateur (UI) ou Spark SQL History Server pour visualiser le plan.
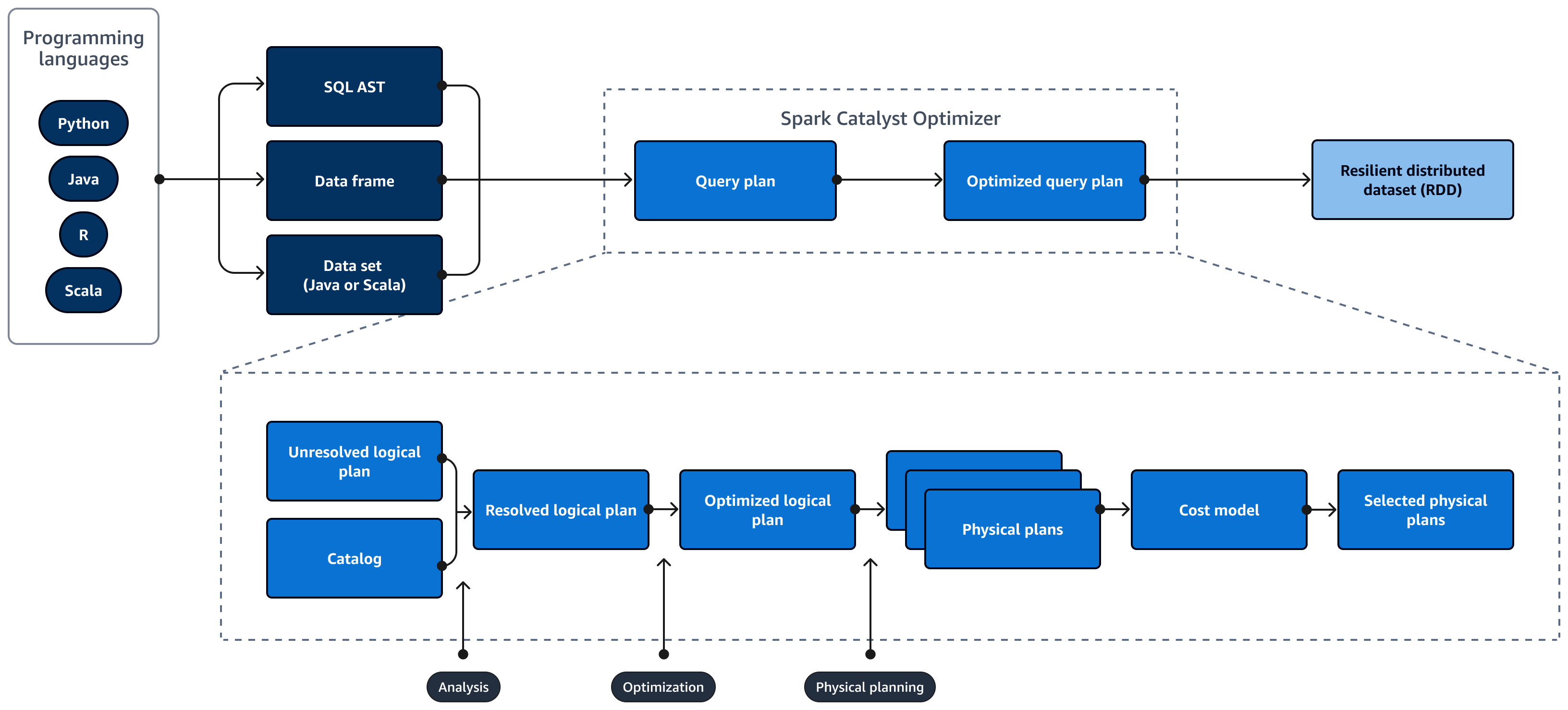
Spark Catalyst Optimizer convertit le plan de requête initial en un plan de requête optimisé comme suit :
-
Analyse et déclaration APIs — La phase d'analyse est la première étape. Le plan logique non résolu, dans lequel les objets référencés dans la requête SQL ne sont pas connus ou ne correspondent pas à une table d'entrée, est généré avec des attributs et des types de données indépendants. Le Spark SQL Catalyst Optimizer applique ensuite un ensemble de règles pour créer un plan logique. L'analyseur SQL peut générer un arbre de syntaxe abstraite SQL (AST) et le fournir comme entrée pour le plan logique. L'entrée peut également être un bloc de données ou un objet de jeu de données construit à l'aide d'une API. Le tableau suivant indique dans quels cas vous devez utiliser du SQL, des blocs de données ou des ensembles de données.
SQL Images de données Jeux de données Erreurs de syntaxe Environnement d’exécution Temps de compilation Temps de compilation Erreurs d'analyse Environnement d’exécution Environnement d’exécution Temps de compilation Pour plus d'informations sur les types d'entrées, consultez les points suivants :
-
Une API de jeu de données fournit une version typée. Cela réduit les performances en raison de la forte dépendance à l'égard des fonctions lambda définies par l'utilisateur. Le RDD ou les ensembles de données sont typés de manière statique. Par exemple, lorsque vous définissez un RDD, vous devez fournir explicitement la définition du schéma.
-
Une API de trame de données fournit des opérations relationnelles non typées. Les trames de données sont typées dynamiquement. Comme pour RDD, lorsque vous définissez un bloc de données, le schéma reste le même. Les données sont toujours structurées. Toutefois, ces informations ne sont disponibles qu'au moment de l'exécution. Cela permet au compilateur d'écrire des instructions de type SQL et de définir de nouvelles colonnes à la volée. Par exemple, il peut ajouter des colonnes à un bloc de données existant sans avoir à définir une nouvelle classe pour chaque opération.
-
A Spark SQL la requête est évaluée pour détecter les erreurs de syntaxe et d'analyse pendant l'exécution, ce qui permet des temps d'exécution plus rapides.
-
-
Catalogue —Spark SQL les usages Apache Hive Metastore (HMS) pour gérer les métadonnées des entités relationnelles persistantes, telles que les bases de données, les tables, les colonnes et les partitions.
-
Optimisation — L'optimiseur réécrit le plan de requête en utilisant l'heuristique et le coût. Il effectue les opérations suivantes pour produire un plan logique optimisé :
-
Colonnes de pruneaux
-
Utilise les prédicats vers le bas
-
Réorganise les jointures
-
-
Les plans physiques et le planificateur — Spark SQL Catalyst Optimizer convertit le plan logique en un ensemble de plans physiques. Cela signifie qu'il convertit le quoi en comment.
-
Plans physiques sélectionnés — Spark SQL Catalyst Optimizer sélectionne le plan physique le plus rentable.
-
Plan de requêtes optimisé — Spark SQL exécute le plan de requête optimisé en termes de performances et de coûts. Spark SQL La gestion de la mémoire suit l'utilisation de la mémoire et répartit la mémoire entre les tâches et les opérateurs. Le Spark SQL Le moteur Tungsten peut améliorer considérablement l'efficacité de la mémoire et du processeur pour Spark SQL applications. Il implémente également le traitement de modèles de données binaires et fonctionne directement sur les données binaires. Cela permet de contourner le besoin de désérialisation et de réduire considérablement les frais associés à la conversion et à la désérialisation des données.
