Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation de la solution
Cadre de ML évolutif
Dans une entreprise comptant des millions de clients répartis entre plusieurs secteurs d'activité, les flux de travail de ML exigent l'intégration de données détenues et gérées par des équipes cloisonnées utilisant des outils différents pour débloquer la valeur métier. Les banques s'engagent à protéger les données de leurs clients. De même, l'infrastructure utilisée pour le développement de modèles de ML est également soumise à de rigoureuses normes de sécurité. Cette sécurité supplémentaire ajoute de la complexité et a un impact sur le délai de valorisation des nouveaux modèles de machine learning. Dans un framework de machine learning évolutif, vous pouvez utiliser un ensemble d'outils modernisé et standardisé pour réduire les efforts nécessaires à la combinaison de différents outils et simplifier le route-to-live processus pour les nouveaux modèles de machine learning.
Traditionnellement, la gestion et le soutien des activités de science des données dans le secteur des services financiers sont contrôlés par une équipe chargée de la plateforme centrale qui recueille les exigences, alloue les ressources et maintient l'infrastructure pour les équipes chargées des données à l'échelle de l'organisation. Pour rapidement mettre à l'échelle l'utilisation du machine learning au sein des équipes fédérées de l'entreprise, vous pouvez utiliser un cadre de ML évolutif en vue de proposer des fonctionnalités en libre-service aux développeurs de nouveaux modèles et de pipelines. Ces développeurs peuvent ainsi déployer une infrastructure moderne, préalablement approuvée, normalisée et sécurisée. En fin de compte, ces fonctionnalités en libre-service réduisent la dépendance de votre entreprise à l'égard des équipes chargées de la plateforme centralisées et accélèrent le délai de valorisation du développement de modèles de ML.
Le cadre de ML évolutif permet aux consommateurs de données (par exemple, les scientifiques des données ou les ingénieurs de ML) d'exploiter la valeur métier en leur donnant la possibilité d'effectuer les opérations suivantes :
Parcourir et découvrir les données préalablement approuvées requises pour l'entraînement des modèles
Accéder rapidement et facilement aux données préalablement approuvées
Utiliser des données préalablement approuvées afin de prouver la viabilité du modèle
Mettre le modèle éprouvé en production pour que d'autres puissent l'utiliser
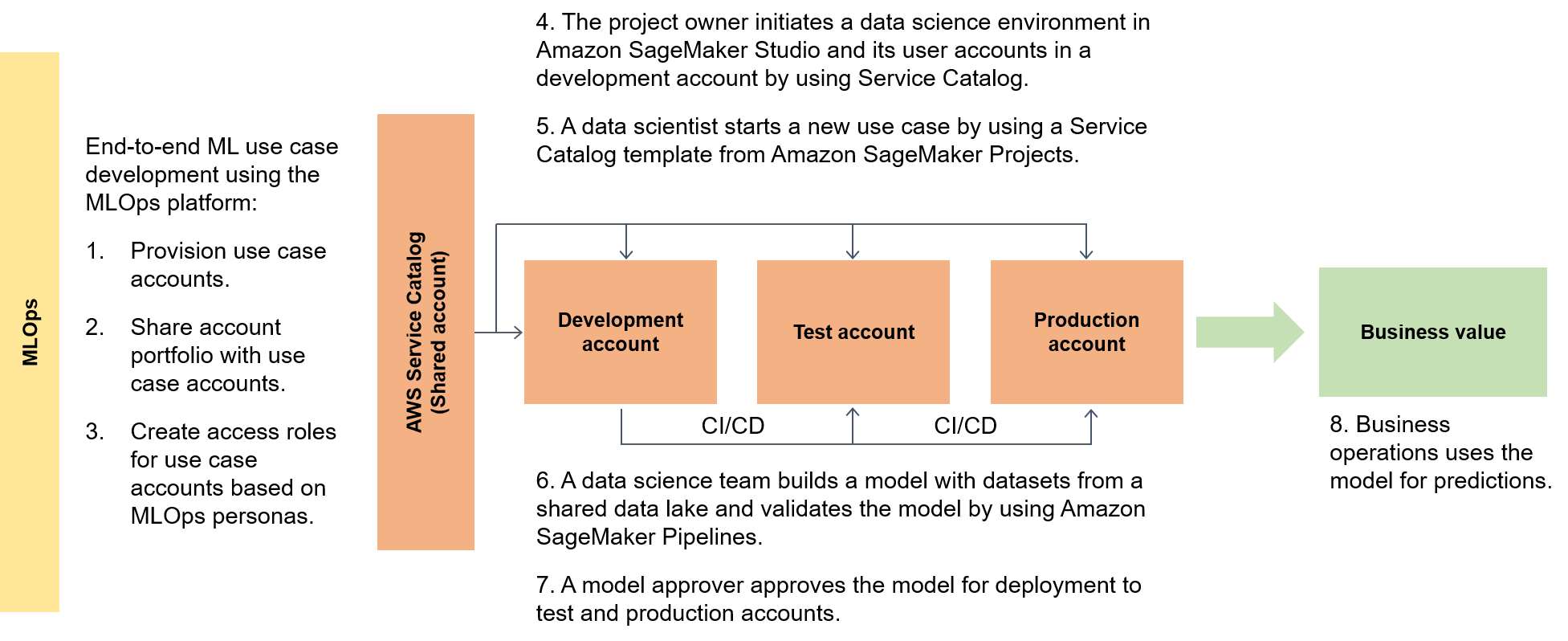
Le schéma suivant met en évidence le end-to-end flux du framework et la voie simplifiée à suivre pour les cas d'utilisation du ML.
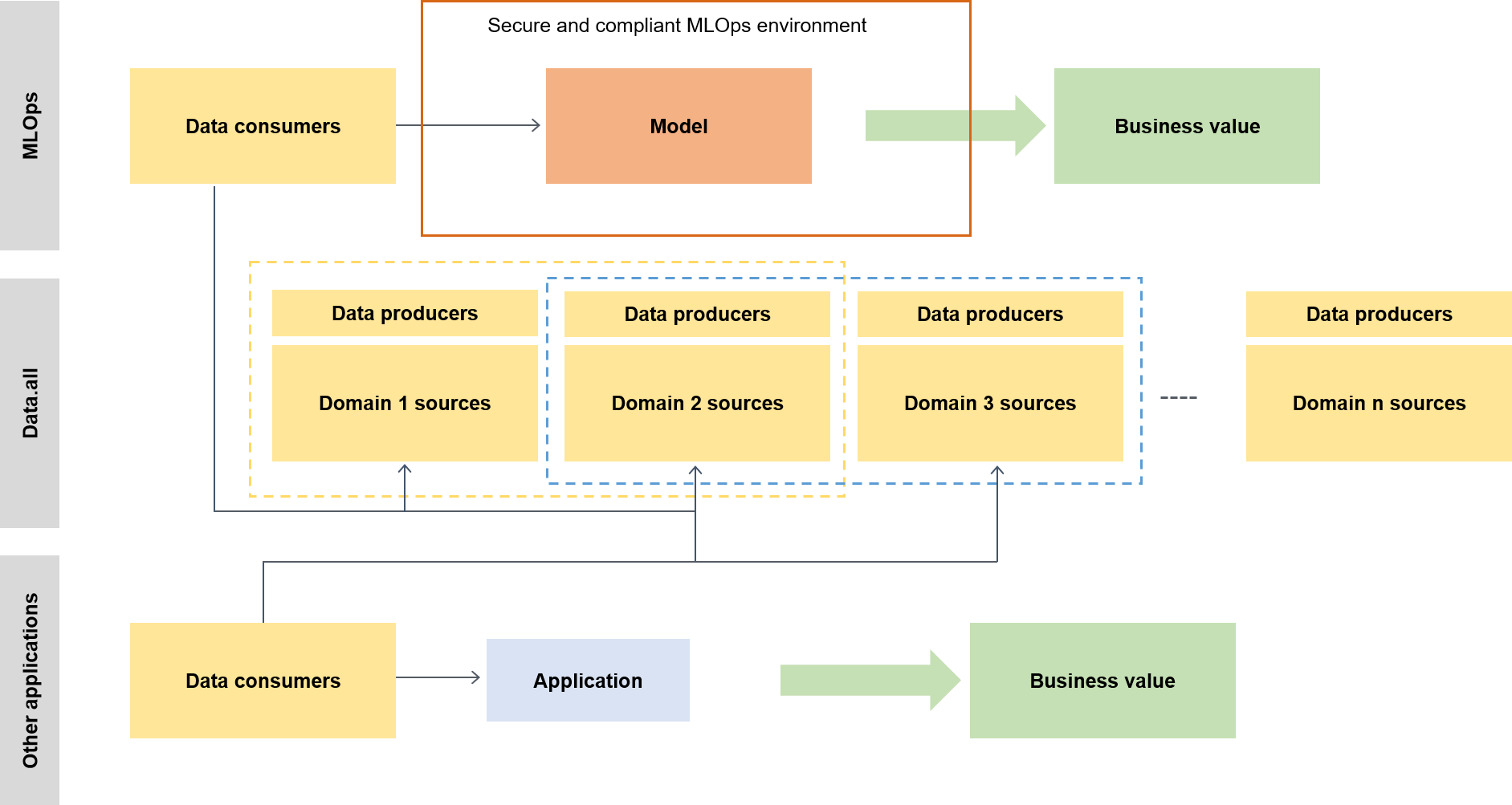
Dans un contexte plus large, les consommateurs de données utilisent un accélérateur sans serveur appelé data.all pour obtenir des données à partir de plusieurs lacs de données et les utiliser par la suite pour entraîner leurs modèles, comme le montre le schéma suivant.
À un niveau inférieur, le cadre de ML évolutif contient les éléments suivants :
Déploiement d'une infrastructure en libre-service : réduisez votre dépendance à l'égard des équipes centralisées.
Système central de gestion de packages Python : mettez à disposition des packages Python préalablement approuvés pour le développement de modèles.
Pipelines CI/CD pour le développement et la promotion de modèles : réduisez la durée de vie en incluant des pipelines d'intégration continue et de déploiement continu (CI/CD) dans le cadre de vos modèles d'infrastructure en tant que code (IaC).
Capacités de test de modèles — Tirez parti des fonctionnalités de test unitaire, de test de modèle, de end-to-end test d'intégration et de test qui sont automatiquement disponibles pour les nouveaux modèles.
Découplage et orchestration des modèles : évitez les calculs inutiles et renforcez vos déploiements en découplant les étapes du modèle en fonction des besoins en ressources informatiques et en orchestrant les différentes étapes à l'aide d'Amazon AI Pipelines. SageMaker
Standardisation du code — Améliorez la qualité de votre code en utilisant l'intégration de CI/CD pipelines pour valider les normes PEP 8 (Python Enhancement Proposal)
. Modèles de ML génériques à démarrage rapide : obtenez des modèles Service Catalog qui instancient vos environnements de modélisation ML (développement, pré-production et production) et les pipelines associés en un clic en utilisant SageMaker AI Projects pour le déploiement.
Surveillance de la qualité des données et des modèles : assurez-vous que vos modèles répondent aux exigences opérationnelles et respectent votre niveau de tolérance au risque en utilisant Amazon SageMaker AI Model Monitor pour surveiller automatiquement la dérive de vos données et la qualité du modèle.
Surveillance des biais : permettez aux propriétaires de vos modèles de prendre des décisions justes et équitables en vérifiant automatiquement s'il existe des déséquilibres dans les données et si des modifications survenues dans le monde ont biaisé votre modèle.
Un hub central pour les métadonnées
Data.all
SageMaker validation
Pour prouver les capacités de l' SageMaker IA sur une gamme d'architectures de traitement des données et d'apprentissage automatique, l'équipe chargée de la mise en œuvre des fonctionnalités sélectionne, en collaboration avec l'équipe de direction bancaire, des cas d'utilisation de complexité variable provenant de différentes divisions de clients bancaires. Les données du cas d'utilisation sont masquées et mises à disposition dans un compartiment de données Amazon Simple Storage Service (Amazon S3) local
Lorsque la migration du modèle de l'environnement de formation d'origine vers une architecture d' SageMaker IA est terminée, votre lac de données hébergé dans le cloud met les données à disposition pour qu'elles puissent être lues par les modèles de production. Les prévisions générées par les modèles de production sont ensuite réécrites dans le lac de données.
Une fois que les cas d'utilisation candidats ont été migrés, le cadre de ML évolutif prend une référence initiale pour les métriques cibles. Vous pouvez comparer la référence aux délais précédents sur site ou d'autres fournisseurs de cloud pour mettre en évidence les améliorations temporelles qu'offre le cadre de ML évolutif.
