Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Architecture système de l’entrepôt des données
Cette section explique les composants qui constituent l'architecture de l'entrepôt de données Amazon Redshift, comme le montre la figure suivante.
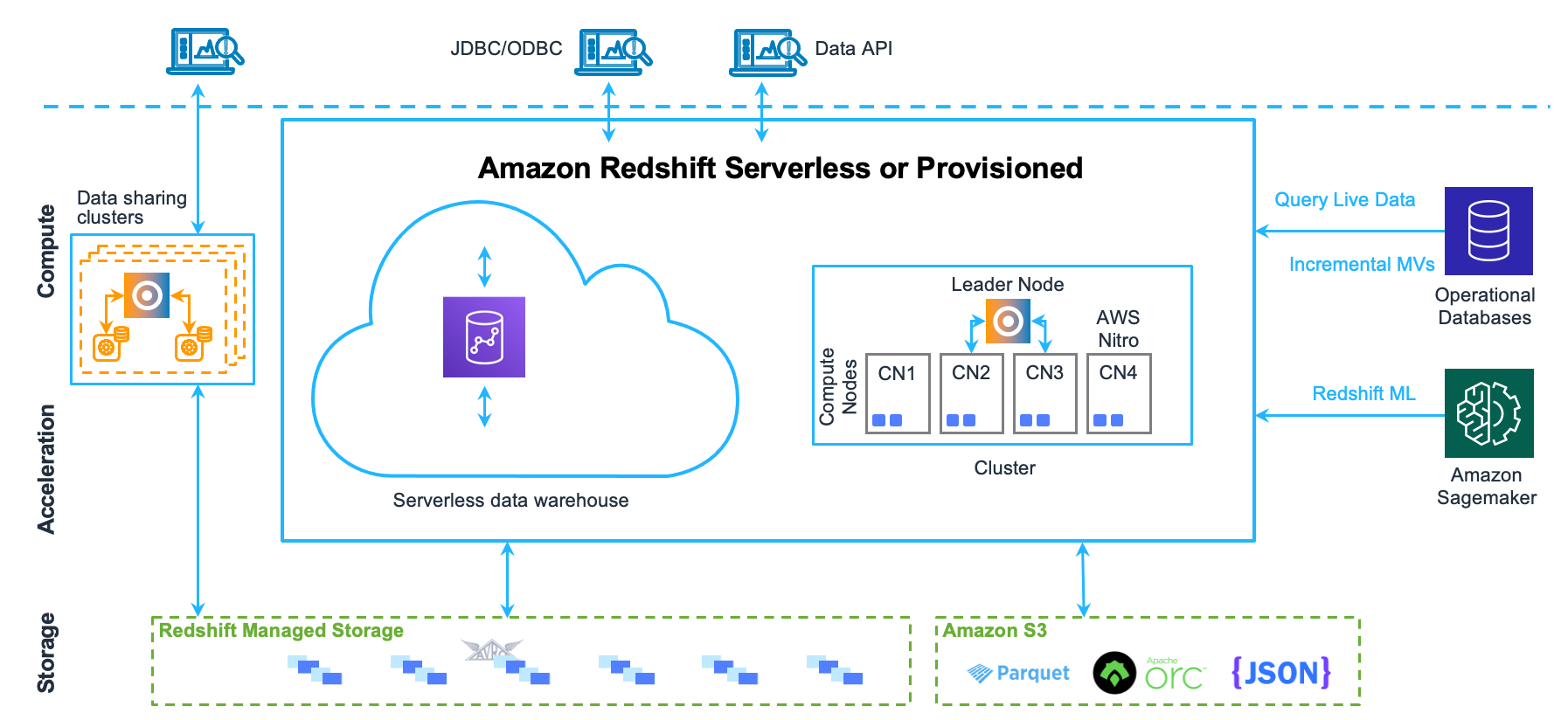
Applications clientes
Amazon Redshift s’intègre à divers outils de chargement de données et d’ETL (extraction, transformation et chargement), ainsi qu’à des outils de reporting, d’exploration de données et d’analyse de la Business Intelligence (BI). Amazon Redshift est basé sur PostgreSQL en norme ouverte, de sorte que la plupart des applications clientes SQL existantes fonctionneront avec des changements minimes. Pour plus d’informations sur les différences importantes entre Amazon Redshift SQL et PostgreSQL, consultez Amazon Redshift et PostgreSQL.
Clusters
Le composant principal de l’infrastructure d’un entrepôt des données Amazon Redshift est un cluster.
Un cluster est composé d’un ou plusieurs nœuds de calcul. Si un cluster est provisionné avec deux nœuds de calcul ou plus, un nœud principal supplémentaire coordonne les nœuds de calcul et gère la communication externe. Votre application cliente n’interagit directement qu’avec le nœud principal. Les nœuds de calcul sont transparents pour les applications externes.
Nœud principal
Le nœud principal gère les communications avec les programmes clients et toute la communication avec les nœuds de calcul. Il analyse et développe des plans d’exécution pour effectuer des opérations de base de données : en particulier, la série d’étapes nécessaires pour obtenir des résultats pour les requêtes complexes. D’après le plan d’exécution, le nœud principal compile le code, distribue le code compilé aux nœuds de calcul et attribue une partie des données à chaque nœud de calcul.
Le nœud principal distribue les instructions SQL aux nœuds de calcul uniquement quand une requête fait référence aux tables stockées sur les nœuds de calcul. Toutes les autres requêtes s’exécutent exclusivement sur le nœud principal. Amazon Redshift est conçu pour implémenter certaines fonctions SQL uniquement sur le nœud principal. Une requête qui utilise une de ces fonctions retourne une erreur si elle fait référence aux tables qui résident sur les nœuds de calcul. Pour plus d'informations, consultez Fonctions SQL prises en charge sur le nœud principal.
Nœuds de calcul
Le nœud principal compile le code des éléments du plan d’exécution et affecte le code aux nœuds de calcul. Les nœuds de calcul exécutent le code compilé et renvoient les résultats intermédiaires au nœud principal pour l’agrégation finale.
Chaque nœud de calcul a ses propres UC et mémoire dédiés, déterminées par le type de nœud. Lorsque votre charge de travail augmente, vous pouvez augmenter la capacité de calcul d’un cluster en augmentant le nombre de nœuds, en mettant à niveau le type de nœud, ou les deux.
Amazon Redshift propose plusieurs types de nœuds pour vos besoins de calcul. Pour plus de détails sur chaque type de nœud, consultez Cluster Amazon Redshift dans le Guide de la gestion du cluster Amazon Redshift.
Redshift Managed Storage
Les données de l’entrepôt des données sont stockées dans un niveau stockage séparé Redshift Managed Storage (RMS). RMS permet d’augmenter votre stockage à plusieurs pétaoctets à l’aide du stockage Amazon S3. RMS vous permet de faire mettre à l’échelle et de payer le calcul et le stockage de manière indépendante, de sorte que vous pouvez dimensionner votre cluster uniquement en fonction de vos besoins en matière de calcul. Il utilise automatiquement le stockage local à haute performance sur SSD comme cache de niveau 1. Il tire également parti d’optimisations telles que la température des blocs de données, leur âge et les modèles de charge de travail, pour fournir des performances élevées tout en adaptant automatiquement le stockage vers Amazon S3 en cas de besoin, sans qu’aucune action ne soit requise.
Tranches de nœud
Un nœud de calcul est divisé en tranches. Chaque tranche se voit attribuer une partie de la mémoire et de l’espace disque du nœud, où elle traite une partie de la charge de travail affectée au nœud. Le nœud principal gère la distribution des données aux tranches et attribue la charge de travail des requêtes ou autres opérations de base de données aux tranches. Les tranches travaillent alors en parallèle pour terminer l’opération.
Le nombre de tranches par nœud est déterminé par la taille de nœud du cluster. Pour plus d’informations sur le nombre de tranches pour chaque taille de nœud, consultez À propos des clusters et des nœuds dans le Guide de gestion Amazon Redshift.
Lorsque vous créez une table, vous pouvez éventuellement spécifier une colonne comme clé de distribution. Lorsque la table est chargée avec les données, les lignes sont distribuées aux tranches des nœuds selon la clé de distribution définie pour une table. Le choix d’une bonne clé de distribution permet à Amazon Redshift d’utiliser le traitement parallèle pour charger les données et exécuter les requêtes efficacement. Pour plus d’informations sur le choix d’une clé de distribution, consultez Choisir le meilleur style de distribution.
Réseau interne
Amazon Redshift tire parti de connexions à large bande passante, de la proximité et de protocoles de communication personnalisés pour fournir une communication réseau privée à très haut débit entre le nœud principal et les nœuds de calcul. Les nœuds de calcul s’exécutent sur un réseau isolé distinct auquel les applications clientes n’accèdent jamais directement.
Bases de données
Un cluster contient une ou plusieurs bases de données. Les données utilisateur sont stockées sur les nœuds de calcul. Votre client SQL communique avec le nœud principal, qui à son tour coordonne l’exécution de la requête avec les nœuds de calcul.
Amazon Redshift est un système de gestion de base de données relationnelle (SGBDR), compatible de ce fait avec d’autres applications SGBDR. Même s’il fournit les mêmes fonctionnalités qu’un SGBDR classique, y compris les fonctions de traitement transactionnel en ligne (OLTP) comme l’insertion et la suppression de données, Amazon Redshift est optimisé pour l’analyse hautes performances et la création de rapports de jeux de données très volumineux.
Amazon Redshift est basé sur PostgreSQL. Amazon Redshift et PostgreSQL présentent un certain nombre de différences très importantes que vous devez prendre en compte lors de la conception et du développement de vos applications d’entrepôt des données. Pour plus d’informations sur les différences entre Amazon Redshift SQL et PostgreSQL, voir Amazon Redshift et PostgreSQL.
