Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Chargement des données à partir des hôtes distants
Vous pouvez utiliser la commande COPY pour charger des données en parallèle depuis un ou plusieurs hôtes distants, tels que des EC2 instances Amazon ou d'autres ordinateurs. COPY se connecte aux hôtes distants à l’aide de SSH et exécute les commandes sur les hôtes distants pour générer la sortie texte.
L'hôte distant peut être une instance Amazon EC2 Linux ou un autre ordinateur Unix ou Linux configuré pour accepter les connexions SSH. Ce guide part du principe que votre hôte distant est une EC2 instance Amazon. Lorsque la procédure est différente pour un autre ordinateur, le guide signale la différence.
Amazon Redshift peut se connecter à plusieurs hôtes et ouvrir plusieurs connexions SSH à chaque hôte. Amazon Redshift envoie une commande unique via chaque connexion pour générer la sortie texte sur la sortie standard de l’hôte, qu’Amazon Redshift lit ensuite comme un fichier texte.
Avant de commencer
Avant de commencer, vous devez avoir les éléments suivants en place :
-
Une ou plusieurs machines hôtes, telles que des EC2 instances Amazon, auxquelles vous pouvez vous connecter via SSH.
-
Sources de données sur les hôtes.
Vous devez fournir les commandes que le cluster Amazon Redshift exécutera sur les hôtes pour générer la sortie texte. Une fois que le cluster s’est connecté à un hôte, la commande COPY exécute les commandes, lit le texte depuis la sortie standard des hôtes et charge les données en parallèle dans une table Amazon Redshift. La sortie texte doit être sous une forme que la commande COPY peut assimiler. Pour plus d'informations, consultez Préparation de vos données d’entrée
-
Accédez aux hôtes à partir de votre ordinateur.
Pour une EC2 instance Amazon, vous utiliserez une connexion SSH pour accéder à l'hôte. Vous devez accéder à l’hôte pour ajouter la clé publique du cluster Amazon Redshift au fichier de clés autorisées de l’hôte.
-
Un cluster Amazon Redshift en cours d’exécution.
Pour plus d’informations sur le lancement d’un cluster, consultez Guide de démarrage d’Amazon Redshift.
Processus de chargement de données
Cette section vous guide à travers le processus de chargement de données à partir d’hôtes distants. Les sections suivantes fournissent les informations détaillées dont vous avez besoin pour effectuer chaque étape.
-
Étape 1 : Récupérer la clé publique de cluster et les adresses IP de nœud de cluster
La clé publique permet aux nœuds de cluster Amazon Redshift d’établir des connexions SSH aux hôtes distants. Vous allez utiliser l’adresse IP de chaque nœud de cluster pour configurer les groupes de sécurité hôte ou le pare-feu, et permettre l’accès à partir de votre cluster Amazon Redshift à l’aide de ces adresses IP.
-
Étape 2 : Ajouter la clé publique de cluster Amazon Redshift au fichier de clés autorisées de l’hôte
Vous ajoutez la clé publique de cluster Amazon Redshift au fichier des clés autorisées de l’hôte de telle sorte que l’hôte reconnaisse le cluster Amazon Redshift et accepte la connexion SSH.
-
Étape 3 : Configurer l’hôte pour accepter toutes les adresses IP du cluster Amazon Redshift
Pour Amazon EC2, modifiez les groupes de sécurité de l'instance pour ajouter des règles de saisie afin d'accepter les adresses IP Amazon Redshift. Pour les autres hôtes, modifiez le pare-feu de telle sorte que vos nœuds Amazon Redshift puissent établir des connexions SSH à l’hôte distant.
-
Étape 4 : Obtenir la clé publique de l’hôte
Vous pouvez spécifier le cas échéant qu’Amazon Redshift doit utiliser la clé publique pour identifier l’hôte. Vous devez trouver la clé publique et copier le texte dans votre fichier manifeste.
-
Étape 5 : Créer un fichier manifeste
Le manifeste est un fichier texte au format JSON avec les détails dont Amazon Redshift a besoin pour se connecter aux hôtes et récupérer les données.
-
Étape 6 : charger le fichier manifeste sur un compartiment Amazon S3
Amazon Redshift lit le manifeste et utilise ces informations pour se connecter à l’hôte distant. Si le compartiment Amazon S3 ne réside pas dans la même région que votre cluster Amazon Redshift, vous devez utiliser l’option REGION pour spécifier la région dans laquelle les données se trouvent.
-
Étape 7 : Exécuter la commande COPY pour charger les données
Depuis une base de données Amazon Redshift, exécutez la commande COPY pour charger les données dans une table Amazon Redshift.
Étape 1 : Récupérer la clé publique de cluster et les adresses IP de nœud de cluster
Vous allez utiliser l’adresse IP de chaque nœud de cluster pour configurer les groupes de sécurité hôte et permettre l’accès à partir de votre cluster Amazon Redshift à l’aide de ces adresses IP.
Pour récupérer la clé publique de cluster et les adresses IP de nœud de cluster pour votre cluster à l’aide de la console
-
Accédez à la console de gestion Amazon Redshift.
-
Choisissez le lien Clusters dans le volet de navigation.
-
Sélectionnez votre cluster dans la liste.
-
Recherchez le groupe Paramètres d’ingestion SSH.
Notez la Clé publique du cluster et les Adresses IP du nœud. Vous allez les utiliser dans les étapes ultérieures.
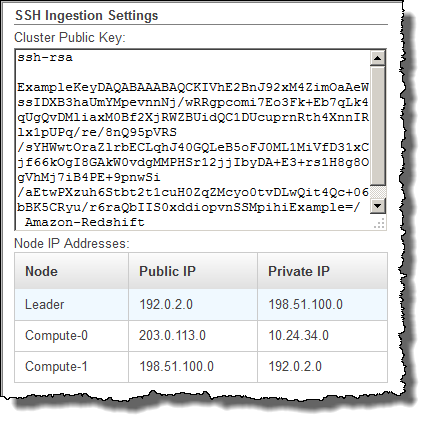
Vous allez utiliser les adresses IP privées de l’étape 3 pour configurer l’hôte et accepter la connexion à partir d’Amazon Redshift. Selon le type d’hôte auquel vous vous connectez à et qu’il figure ou pas dans un VPC, vous allez utiliser les adresses IP publiques ou les adresses IP privées.
Pour récupérer la clé publique de cluster et les adresses IP de nœud de cluster pour votre cluster à l’aide de la CLI Amazon Redshift, exécutez la commande describe-clusters.
Par exemple :
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
La réponse inclura ClusterPublicKey la liste des adresses IP privées et publiques, comme suit :
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
Pour récupérer la clé publique du cluster et les adresses IP des nœuds de cluster de votre cluster à l'aide de l'API Amazon Redshift, utilisez l' DescribeClusters action. Pour plus d'informations, consultez la section describe-clusters dans le guide de l'interface de ligne de commande Amazon Redshift DescribeClustersou dans le guide de l'API Amazon Redshift.
Étape 2 : Ajouter la clé publique de cluster Amazon Redshift au fichier de clés autorisées de l’hôte
Vous ajoutez la clé publique de cluster à chaque fichier de clés autorisées de l’hôte de telle sorte que l’hôte reconnaisse Amazon Redshift et accepte la connexion SSH.
Pour ajouter la clé publique de cluster Amazon Redshift au fichier de clés autorisées de l’hôte
-
Accédez à l’hôte à l’aide d’une connexion SSH.
Pour plus d'informations sur la connexion à une instance via SSH, consultez Connect to Your Instance dans le guide de l' EC2 utilisateur Amazon.
-
Copiez la clé publique Amazon Redshift à partir de la console ou du texte de réponse de la CLI.
-
Copiez et collez le contenu de la clé publique dans le fichier
/home/<ssh_username>/.ssh/authorized_keysde l’hôte distant.<ssh_username>doit correspondre à la valeur du champ « username » du fichier manifeste. Incluez la chaîne complète, y compris le préfixe «ssh-rsa» et le suffixe «Amazon-Redshift». Par exemple :ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
Étape 3 : Configurer l’hôte pour accepter toutes les adresses IP du cluster Amazon Redshift
Si vous travaillez avec une EC2 instance Amazon ou un cluster Amazon EMR, ajoutez des règles de trafic entrant au groupe de sécurité de l'hôte pour autoriser le trafic provenant de chaque nœud de cluster Amazon Redshift. Pour Type, sélectionnez SSH avec le protocole TCP sur le port 22. Pour Source, saisissez les adresses IP du nœud de cluster Amazon Redshift que vous avez récupérées dans Étape 1 : Récupérer la clé publique de cluster et les adresses IP de nœud de cluster. Pour plus d'informations sur l'ajout de règles à un groupe EC2 de sécurité Amazon, consultez Autoriser le trafic entrant pour vos instances dans le guide de EC2 l'utilisateur Amazon.
Utilisez les adresses IP privées quand :
-
Vous avez un cluster Amazon Redshift qui ne se trouve pas dans un Virtual Private Cloud (VPC) et une instance EC2 Amazon -Classic, tous deux situés dans la même région. AWS
-
Vous avez un cluster Amazon Redshift situé dans un VPC et une instance Amazon EC2 -VPC, tous deux situés dans la même région AWS et dans le même VPC.
Sinon, utilisez les adresses IP publiques.
Pour plus d’informations sur l’utilisation d’Amazon Redshift dans un VPC, consultez Gestion des clusters dans un cloud privé virtuel (VPC) dans le Guide de gestion Amazon Redshift.
Étape 4 : Obtenir la clé publique de l’hôte
Vous pouvez fournir le cas échéant la clé publique dans le fichier manifeste de telle sorte qu’Amazon Redshift puisse identifier l’hôte. La commande COPY ne nécessite pas la clé publique de l'hôte mais, pour des raisons de sécurité, nous vous recommandons vivement d'utiliser une clé publique pour empêcher les attaques man-in-the-middle « ».
Vous pouvez trouver la clé publique de l’hôte à l’emplacement suivant, où <ssh_host_rsa_key_name> correspond au nom unique de la clé publique de l’hôte :
: /etc/ssh/<ssh_host_rsa_key_name>.pub
Note
Amazon Redshift prend uniquement en charge les clés RSA. Nous ne prenons pas en charge les clés DSA.
Lorsque vous créez votre fichier manifeste à l’étape 5, vous collez le texte de la clé publique dans le champ « Public Key » de l’entrée du fichier manifeste.
Étape 5 : Créer un fichier manifeste
La commande COPY peut se connecter à plusieurs hôtes à l’aide de SSH et créer plusieurs connexions SSH à chaque hôte. COPY exécute une commande via chaque connexion hôte, puis charge la sortie à partir des commandes en parallèle de la table. Le fichier manifeste est un fichier texte au format JSON qu’Amazon Redshift utilise pour se connecter à l’hôte. Le fichier manifeste spécifie les points de terminaison hôte SSH et les commandes qui sont exécutées sur les hôtes pour renvoyer les données à Amazon Redshift. Le cas échéant, vous pouvez inclure la clé publique de l’hôte, le nom d’utilisateur de connexion et un indicateur obligatoire pour chaque entrée.
Créez le fichier manifeste sur votre ordinateur local. Dans une étape ultérieure, vous téléchargez le fichier vers Amazon S3.
Le fichier manifeste est au format suivant :
{ "entries": [ {"endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", "mandatory":true, "publickey": "<public_key>", "username": "<host_user_name>"}, {"endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", "mandatory":true, "publickey": "<public_key>", "username": "host_user_name"} ] }
Le fichier manifeste contient une construction « entries » pour chaque connexion SSH. Chaque entrée représente une seule connexion SSH. Vous pouvez avoir plusieurs connexions à un seul hôte ou plusieurs connexions à plusieurs hôtes. Les guillemets doubles sont obligatoires comme illustré, aussi bien pour les noms de champ que pour les valeurs. La seule valeur qui n’a pas besoin de guillemets doubles est la valeur booléenne true ou false pour le champ obligatoire.
La liste suivante décrit les champs dans le fichier manifeste.
- point de terminaison
-
Adresse URL ou adresse IP de l’hôte. Par exemple, «
ec2-111-222-333.compute-1.amazonaws.com» ou «22.33.44.56» - command
-
La commande qui sera exécutée par l’hôte pour générer une sortie texte ou binaire (lzop, gzip ou bzip2). La commande peut être n’importe quelle commande que l’utilisateur « host_user_name » est autorisé à exécuter. La commande peut être aussi simple que l’impression d’un fichier ou peut interroger une base de données ou lancer un script. La sortie (fichier texte, fichier binaire gzip, fichier binaire lzop ou fichier binaire bzip2) doit être sous une forme que la commande COPY Amazon Redshift peut intégrer. Pour plus d'informations, consultez Préparation de vos données d’entrée.
- publickey
-
(Facultatif) La clé publique de l’hôte. Si la clé est fournie, Amazon Redshift l’utilise pour identifier l’hôte. Si la clé publique n’est pas fournie, Amazon Redshift n’essaie pas d’identifier l’hôte. Par exemple, si la clé publique de l’hôte distant est
ssh-rsa AbcCbaxxx…xxxDHKJ root@amazon.com, saisissez le texte suivant dans le champ de clé publique :AbcCbaxxx…xxxDHKJ. - mandatory
-
(Facultatif) Indique si la commande COPY doit échouer en cas d’échec de la connexion. L’argument par défaut est
false. Si Amazon Redshift n’établit pas avec succès au moins une connexion, la commande COPY échoue. - nom d’utilisateur
-
(Facultatif) Nom d’utilisateur qui sera utilisé pour vous connecter au système hôte et exécuter la commande à distance. Le nom de connexion d’utilisateur doit être le même que celui de la connexion utilisée pour ajouter la clé publique au fichier de clés autorisées de l’hôte à l’étape 2. Le nom d’utilisateur par défaut est « redshift ».
L’exemple suivant illustre un manifeste complet permettant d’ouvrir quatre connexions vers le même hôte et d’exécuter une commande différente sur chaque connexion :
{ "entries": [ {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata1.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata2.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata3.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"}, {"endpoint":"ec2-184-72-204-112.compute-1.amazonaws.com", "command": "cat loaddata4.txt", "mandatory":true, "publickey": "ec2publickeyportionoftheec2keypair", "username": "ec2-user"} ] }
Étape 6 : charger le fichier manifeste sur un compartiment Amazon S3
Chargez le fichier manifeste sur un compartiment Amazon S3. Si le compartiment Amazon S3 ne réside pas dans la même AWS région que votre cluster Amazon Redshift, vous devez utiliser l'REGIONoption pour spécifier la AWS région dans laquelle se trouve le manifeste. Pour plus d’informations sur la création d’un compartiment Amazon S3 et le chargement d’un fichier, consultez le Guide de l’utilisateur Amazon Simple Storage Service.
Étape 7 : Exécuter la commande COPY pour charger les données
Exécutez une commande COPY pour vous connecter à l’hôte et charger les données dans une table Amazon Redshift. Dans la commande COPY, spécifiez le chemin d’accès à l’objet Amazon S3 explicite pour le fichier manifeste et incluez l’option SSH. Par exemple,
COPY sales FROM 's3://amzn-s3-demo-bucket/ssh_manifest' IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole' DELIMITER '|' SSH;
Note
Si vous utilisez la compression automatique, la commande COPY effectue deux lectures des données, ce qui signifie qu’elle exécute la commande distante à deux reprises. La première lecture consiste à fournir un échantillon pour l’analyse de la compression, puis la deuxième lecture charge réellement les données. Si la double exécution de la commande distante cause un problème en raison des effets secondaires potentiels, vous devez désactiver la compression automatique. Pour désactiver la compression automatique, exécutez la commande COPY avec l’option COMPUPDATE définie sur OFF. Pour de plus amples informations, veuillez consulter Chargement des tables avec compression automatique.
