Amazon Redshift ne prendra plus en charge la création de nouveaux Python UDFs à compter du 1er novembre 2025. Si vous souhaitez utiliser Python UDFs, créez la version UDFs antérieure à cette date. Le Python existant UDFs continuera à fonctionner normalement. Pour plus d'informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Minimiser les temps d'aspiration
Amazon Redshift trie automatiquement les données et exécute l’opération VACUUM DELETE en arrière-plan. Cela réduit la nécessité d’exécuter la commande VACUUM. Passer l'aspirateur est un processus qui peut prendre beaucoup de temps. En fonction de la nature de vos données, nous recommandons les pratiques suivantes afin de minimiser les temps d'aspiration.
Rubriques
Décidez s'il faut réindexer
Vous pouvez souvent améliorer de façon significative les performances des requêtes en utilisant un style de tri entrelacé, mais au fil du temps les performances peuvent se dégrader si la distribution des valeurs des colonnes de clé de tri change.
Lorsque vous chargez initialement une table entrelacée vide à l’aide de COPY ou CREATE TABLE AS, Amazon Redshift crée automatiquement l’index entrelacé. Si vous chargez initialement une table entrelacée à l’aide d’INSERT, vous devez exécuter VACUUM REINDEX après pour initialiser l’index entrelacé.
Au fil du temps, à mesure que vous ajoutez des lignes avec de nouvelles valeurs de clé de tri, les performances peuvent se dégrader si la distribution des valeurs dans les colonnes de clés change. Si vos nouvelles lignes se trouvent principalement dans la plage de valeurs des clés de tri existantes, vous n’avez pas besoin de réindexer. Exécutez VACUUM SORT ONLY ou VACUUM FULL pour rétablir l’ordre de tri.
Le moteur de requête est en mesure d’utiliser l’ordre de tri pour sélectionner efficacement les blocs de données qui doivent être analysés pour traiter une requête. Pour un tri entrelacé, Amazon Redshift analyse les valeurs des colonnes de clé de tri pour déterminer l’ordre de tri optimal. Si la distribution des valeurs de clés change, ou est altérée, au fur et à mesure que les lignes sont ajoutées, la politique de tri n’est plus optimale et l’avantage des performances de tri se dégrade. Pour réanalyser la distribution des clés de tri, vous pouvez exécuter une opération VACUUM REINDEX. Comme l’opération de réindexation prend du temps, pour décider si une table peut bénéficier d’une réindexation, interrogez la vue SVV_INTERLEAVED_COLUMNS.
Par exemple, la requête suivante affiche les détails des tables qui utilisent les clés de tri entrelacé.
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
La valeur de interleaved_skew est un rapport qui indique le degré de déformation. Une valeur égale à 1 signifie qu’il n’y a pas de déformation. Si la déformation est supérieure à 1,4, une opération VACUUM REINDEX améliore généralement les performances, sauf si la déformation est inhérente à l’ensemble jeu sous-jacent.
Vous pouvez utiliser la valeur de date dans last_reindex pour déterminer le temps qui s’est écoulé depuis la dernière réindexation.
Réduire la taille de la région non triée
La région non triée croît lors du chargement de grandes quantités de nouvelles données dans des tables qui contiennent déjà des données ou lorsque vous ne pas videz pas les tables dans le cadre de vos opérations régulières de maintenance. Pour éviter les longues opérations VACUUM, utilisez les pratiques suivantes :
-
Exécutez les opérations VACUUM sur une base régulière.
Si vous chargez vos tables par petits incréments (mises à jour quotidiennes qui représentent un faible pourcentage du nombre total de lignes de la table, par exemple), l’exécution régulière de VACUUM aide à s’assurer que les opérations VACUUM individuelles se déroulent rapidement.
-
Exécutez d’abord le chargement le plus important.
Si vous avez besoin de charger une nouvelle table avec plusieurs opérations COPY, exécutez d’abord le chargement le plus important. Lorsque vous exécutez un chargement initial dans une table nouvelle ou tronquée, toutes les données sont chargées directement dans la région triée et, par conséquent, aucune opération VACUUM n’est obligatoire.
-
Tronquez une table au lieu de supprimer toutes les lignes.
La suppression des lignes d’une table ne récupère pas l’espace que les lignes occupaient jusqu’à ce que vous effectuiez une opération VACUUM ; cependant, la troncation d’une table vide la table et récupère l’espace, et, par conséquent, aucune opération VACUUM n’est obligatoire. Une autre solution consiste à supprimer la table et à la recréer.
-
Tronquez ou supprimez les tables de test.
Si vous chargez un petit nombre de lignes dans une table à des fins de test, ne supprimez pas les lignes lorsque vous avez terminé. A la place, tronquez la table et rechargez les lignes dans le cadre de l’opération de chargement de production suivante.
-
Exécutez une copie complète.
Si une table qui utilise une table de clé de tri composée possède une grande région non triée, une copie complète est beaucoup plus rapide qu’une opération VACUUM. Une copie complète recrée et remplit une table à l’aide d’une insertion en bloc, qui retrie automatiquement la table. Si une table possède une grande région non triée, une copie complète est beaucoup plus rapide qu’une opération VACUUM. Cependant, vous ne pouvez pas effectuer de mises à jour simultanées pendant une opération de copie complète, alors que cela est possible durant une opération VACUUM. Pour de plus amples informations, veuillez consulter Bonnes pratiques Amazon Redshift pour la conception de requêtes.
Réduire le volume des lignes fusionnées
Si une opération VACUUM doit fusionner de nouvelles lignes dans la région triée d’une table, le temps nécessaire pour l’opération augmente au fur et à mesure que la table se développe. Vous pouvez améliorer les performances de l’opération VACUUM en réduisant le nombre de lignes à fusionner.
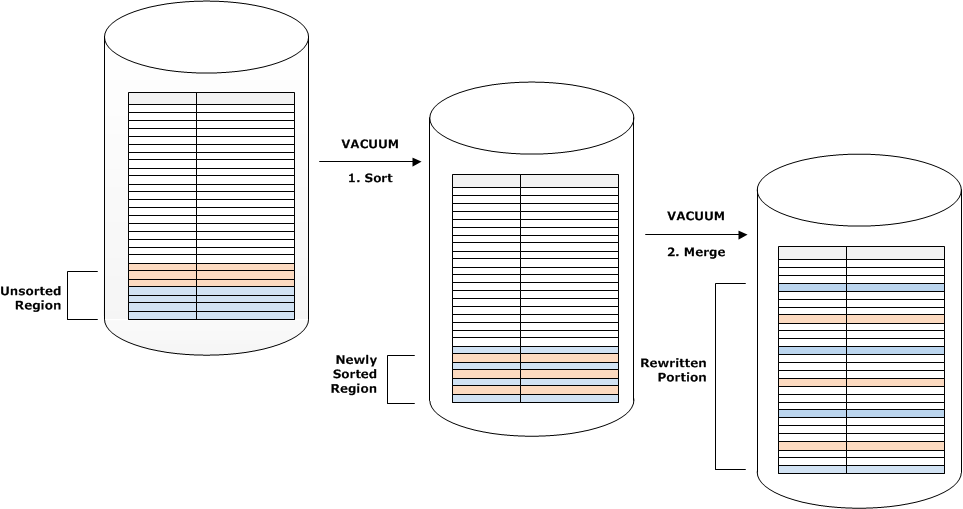
Avant une opération VACUUM, une table se compose d’une région triée en tête de table, suivie d’une région non triée, qui croît chaque fois que des lignes sont ajoutées ou mises à jour. Lorsqu’un ensemble de lignes est ajouté par une opération COPY, le nouvel ensemble de lignes est trié sur la clé de tri tel qu’il est ajouté à la région non triée en fin de table. Les nouvelles lignes sont classées au sein de leur propre ensemble, mais pas au sein de la région non triée.
Le schéma suivant illustre la région non triée après deux opérations COPY successives, où la clé de tri est CUSTID. Pour plus de simplicité, cet exemple montre une clé de tri composée, mais les mêmes principes s’appliquent aux clés de tri entrelacé, sauf que l’impact de la région non triée est une plus grande pour les tables entrelacées.

Une opération VACUUM restaure l’ordre de tri de la table en deux étapes :
-
Triez la région non triée dans une région nouvellement triée.
La première étape est relativement bon marché, parce que seule la région non triée est réécrite. Si la plage des valeurs de clé de tri de la région nouvellement triée est supérieure à la plage existante, seules les nouvelles lignes doivent être réécrites, et l’opération VACUUM est terminée. Par exemple, si la région triée contient des valeurs d’ID comprises entre 1 et 500 et que les opérations de copie suivantes ajoutent des valeurs de clé supérieures à 500, seule la région non triée doit être réécrite.
-
Fusionnez la région nouvellement triée avec la région précédemment triée.
Si les clés de la région nouvellement triée chevauchent les clés de la région triée, l’opération VACUUM doit fusionner les lignes. En commençant par le début de la région nouvellement triée (à la clé de tri la plus basse), l’opération VACUUM écrit les lignes fusionnées à partir de la région précédemment triée et de la région nouvellement triée dans un nouvel ensemble de blocs.
L’étendue selon laquelle la nouvelle plage de clés de tri chevauche les clés de tri existantes détermine l’étendue selon laquelle la région précédemment triée doit être réécrite. Si les clés non triées sont dispersées à travers la plage de tri existante, une opération VACUUM peut avoir besoin de réécrire Des parties existantes de la table.
Le schéma suivant montre comment une opération VACUUM trie et fusionne les lignes qui sont ajoutées à une table où CUSTID est la clé de tri. Comme chaque opération de copie ajoute un nouvel ensemble de lignes avec des valeurs de clé qui chevauchent les clés existantes, presque la totalité de la table doit être réécrite. Le schéma illustre une seule étape de tri et fusion, mais, en pratique, une grand opération VACUUM se compose d’une série d’étapes incrémentielles de tri et de fusion.

Si la plage de clés de tri d’un ensemble de nouvelles lignes chevauche la plage des clés existantes, le coût de l’étape de fusion continue à croître proportionnellement à la taille de la table au fur et à mesure que la table augmente, tandis que le coût de l’étape de tri demeure proportionnel à la taille de la région non triée. Dans un tel cas, le coût de l’étape de fusion éclipse le coût de l’étape de tri, comme l’illustre le schéma suivant.
Pour déterminer quelle proportion d’une table a été refusionnée, interrogez SVV_VACUUM_SUMMARY après la fin de l’opération VACUUM. La requête suivante affiche les conséquences de six opérations VACUUM successives tandis que CUSTSALES croît au fil du temps.
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
La colonne merge_increments fournit une indication de la quantité de données qui a été fusionnée pour chaque opération VACUUM. Si le nombre d’incréments de fusion sur des opérations VACUUM consécutives augmente proportionnellement à la croissance de la taille de la table, cela indique que chaque opération VACUUM refusionne un nombre croissant de lignes de la table, car la région existante et la région nouvellement triée se chevauchent.
Chargez vos données dans l'ordre des clés de tri
Si vous chargez vos données dans l’ordre de la clé de tri avec une commande COPY, vous aurez peut-être moins (voire plus du tout) besoin d’avoir recours à l’opération VACUUM.
La commande COPY ajoute automatiquement de nouvelles lignes à la région triée de la table lorsque toutes les conditions suivantes sont définies sur true :
-
La table utilise une clé de tri composée avec une seule colonne de tri.
-
La colonne de tri est NOT NULL.
-
La table est triée ou vide à 100 %.
-
Toutes les nouvelles lignes sont plus élevées dans l’ordre de tri que les lignes existantes, y compris les lignes marquées pour la suppression. Dans ce cas, Amazon Redshift utilise les huit premiers octets de la clé de tri pour déterminer l’ordre de tri.
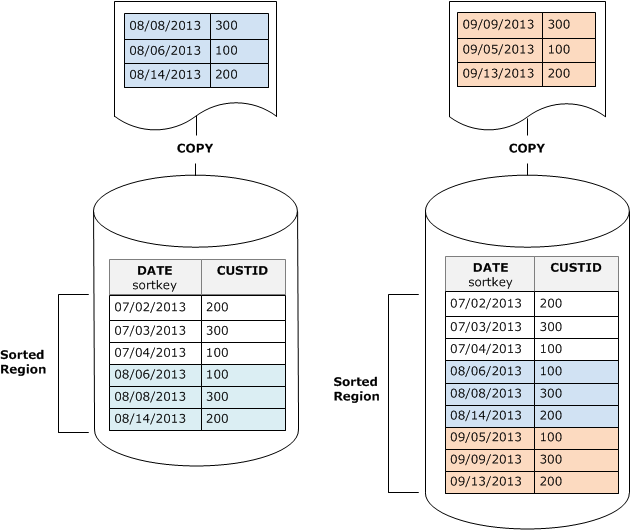
Par exemple, supposons que vous ayez une table qui enregistre les événements clients à l’aide d’un ID client et de l’heure. Si vous triez sur l’ID client, il est probable que la plage des clés de tri des nouvelles lignes ajoutées par les chargements incrémentiels chevauchent la plage existante, comme illustré dans l’exemple précédent, ce qui conduit à une opération VACUUM coûteuse.
Si vous définissez votre clé de tri sur une colonne d’horodatage, vos nouvelles lignes sont ajoutées dans l’ordre de tri à la fin de la table, comme l’illustre le schéma suivant, ce qui rend l’opération VACUUM moins (voire plus du tout) nécessaire.
Utilisez des tables de séries chronologiques pour réduire les données stockées
Si vous maintenez les données pendant une période aléatoire, utilisez une série de tables, comme l’illustre le schéma suivant.

Créez une table chaque fois que vous ajoutez un ensemble de données, puis supprimez la table la plus ancienne de la série. Vous bénéficiez d’un double avantage :
-
Vous évitez le coût supplémentaire de suppression des lignes, parce qu’une opération DROP TABLE est beaucoup plus efficace qu’une opération DELETE massive.
-
Si les tables sont triées par horodate, aucune opération VACUUM n’est nécessaire. Si chaque table contient les données pour un mois, une opération VACUUM devra au plus réécrire la valeur d’un mois de données, même si les tables ne sont pas triées par horodatage.
Vous pouvez créer une vue UNION ALL à utiliser par les requêtes de création de rapports qui masque le fait que les données sont stockées en plusieurs tables. Si une requête filtre sur la clé de tri, le planificateur de requête peut efficacement ignorer toutes les tables qui ne sont pas utilisées. Comme une opération UNION ALL peut être moins efficace pour les autres types de requêtes, vous devez évaluer les performances de la requête dans le contexte de toutes les requêtes qui utilisent les tables.
