Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Détection d’objets et de concepts
Cette section fournit des informations de détection d’étiquettes dans des images et des vidéos avec Image Amazon Rekognition et Vidéo Amazon Rekognition.
Une étiquette ou une balise constituent un objet ou un concept (y compris des scènes et des actions) détecté dans une image ou une vidéo, en fonction de son contenu. Par exemple, une photo de personnes sur une plage tropicale peut contenir les étiquettes « Palmier » (objet), « Plage » (scène), « Courir » (action) et « Extérieur » (concept).
Étiquettes prises en charge par les opérations de détection d'étiquettes Rekognition
Note
Amazon Rekognition fait des prédictions binaires liées au genre (homme, femme, fille, etc.) sur la base de l’apparence physique d’une personne sur une image donnée. Ce type de prédiction n’est pas conçu pour catégoriser l’identité de genre d’une personne, et vous ne devez pas utiliser Amazon Rekognition pour effectuer une telle détermination. Par exemple, un acteur masculin portant une perruque aux cheveux longs et des boucles d’oreilles pour un rôle peut être prédit comme une femme.
L’utilisation d’Amazon Rekognition pour établir des prédictions binaires entre les sexes convient parfaitement aux cas d’utilisation dans lesquels les statistiques agrégées de répartition par sexe doivent être analysées sans identifier d’utilisateurs spécifiques. Par exemple, le pourcentage d’utilisateurs qui sont des femmes par rapport aux hommes sur une plateforme de médias sociaux.
Nous vous déconseillons d’utiliser des prédictions binaires de sexe pour prendre des décisions ayant un impact sur les droits, la confidentialité ou l’accès aux services d’une personne.
Amazon Rekognition renvoie des étiquettes en anglais. Vous pouvez utiliser Amazon Translate
Le schéma suivant montre l'ordre des opérations d'appel, en fonction de vos objectifs d'utilisation des opérations Amazon Rekognition Image ou Amazon Rekognition Video :
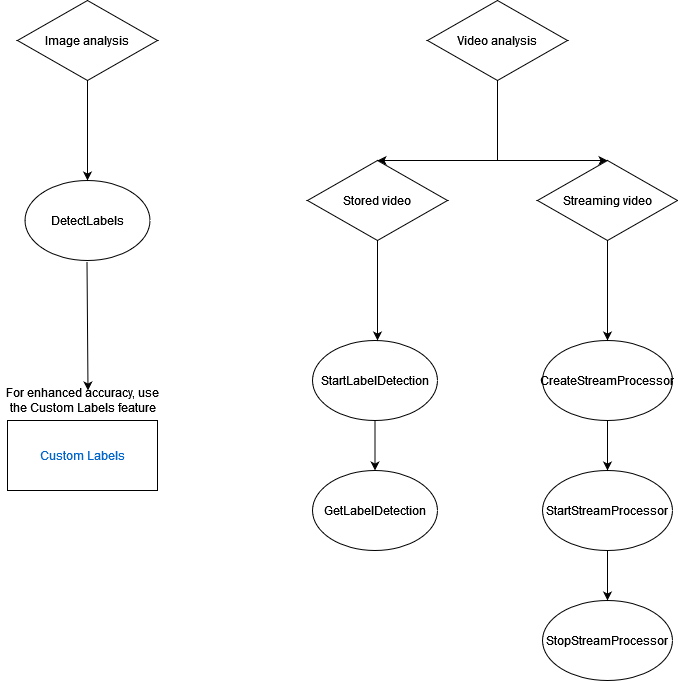
Étiqueter les objets de réponse
Cadres de délimitation
Image Amazon Rekognition et Vidéo Amazon Rekognition peuvent renvoyer le cadre de délimitation pour des étiquettes d’objets courants tels que des voitures, des meubles, des appareils ou des animaux de compagnie. Les informations relatives au cadre de délimitation ne sont pas renvoyées pour les étiquettes d’objets moins courants. Vous pouvez utiliser des cadres de délimitation pour trouver les emplacements exacts des objets dans une image et le nombre d’instances d’objets détectés, ou pour mesurer la taille d’un objet à l’aide des dimensions de ces cadres.
Par exemple, dans l’image suivante, Image Amazon Rekognition peut détecter la présence d’une personne, d’un skateboard, de voitures garées et d’autres informations. Image Amazon Rekognition renvoie également le cadre de délimitation pour une personne détectée, ainsi que d’autres objets détectés, tels que des voitures et des roues.

Score de fiabilité
Vidéo Amazon Rekognition et Image Amazon Rekognition fournissent un score en pourcentage indiquant le degré de confiance d’Amazon Rekognition dans l’exactitude de chaque étiquette détectée.
Parents
Image Amazon Rekognition et Vidéo Amazon Rekognition utilisent une taxonomie hiérarchique des étiquettes d’ancêtres pour classer les étiquettes. Par exemple, une personne qui traverse une route peut être détectée en tant que Pedestrian (Piéton). L’étiquette parent de Pedestrian (Piéton) est Person (Personne). Les deux étiquettes sont renvoyées dans la réponse. Toutes les étiquettes d’ancêtre sont renvoyées et une étiquette donnée contient une liste de ses étiquettes parent et des autres étiquettes d’ancêtre. Par exemple, des étiquettes de grand-parent et d’arrière grand-parent, si elles existent. Vous pouvez utiliser des étiquettes parent pour créer des groupes d’étiquettes liées et autoriser l’interrogation des étiquettes similaires dans une ou plusieurs images. Par exemple, une requête pour tous les véhicules (Vehicles) peut renvoyer une voiture depuis une image et une moto depuis une autre image.
Catégories
Image Amazon Rekognition et Vidéo Amazon Rekognition renvoient des informations sur les catégories d’étiquettes. Les étiquettes font partie de catégories qui regroupent des étiquettes individuelles selon des fonctions et des contextes communs, tels que « Véhicules et automobiles » et « Produits alimentaires et boissons ». Une catégorie d’étiquette peut être une sous-catégorie d’une catégorie parent.
Alias
Outre le renvoi des étiquettes, Image Amazon Rekognition et Vidéo Amazon Rekognition renvoient tous les alias associés à l’étiquette. Les alias sont des étiquettes ayant la même signification ou des étiquettes visuellement interchangeables avec l’étiquette principale renvoyée. Par exemple, « téléphone cellulaire » est un alias de « téléphone portable ».
Dans les versions précédentes, Image Amazon Rekognition renvoyait des alias tels que « téléphone cellulaire » dans la même liste de noms d’étiquette principale qui contenait « téléphone portable ». Image Amazon Rekognition renvoie désormais « Téléphone cellulaire » dans un champ appelé « alias » et « Téléphone portable » dans la liste des noms d’étiquette principaux. Si votre application repose sur les structures renvoyées par une version précédente de Rekognition, vous devrez peut-être transformer la réponse actuelle renvoyée par les opérations de détection d’étiquettes d’images ou de vidéos dans la structure de réponse précédente, dans laquelle toutes les étiquettes et alias sont renvoyés en tant qu’étiquettes principales.
Si vous devez transformer la réponse actuelle de l' DetectLabels API (pour la détection d'étiquettes dans les images) dans la structure de réponse précédente, consultez l'exemple de code dansTransformation de la DetectLabels réponse.
Si vous devez transformer la réponse actuelle de l' GetLabelDetection API (pour la détection d'étiquettes dans les vidéos stockées) dans la structure de réponse précédente, consultez l'exemple de code dansTransformation de la GetLabelDetection réponse.
Propriétés de l’image
Image Amazon Rekognition renvoie des informations sur la qualité de l’image (netteté, luminosité et contraste) pour l’ensemble de l’image. La netteté et la luminosité sont également renvoyées pour le premier plan et l’arrière-plan de l’image. Les propriétés de l’image peuvent également être utilisées pour détecter les couleurs dominantes de l’ensemble de l’image, du premier plan, de l’arrière-plan et des objets dotés de cadres de délimitation.

Voici un exemple des ImageProperties données contenues dans la réponse d'une DetectLabels opération pour l'image suivante :
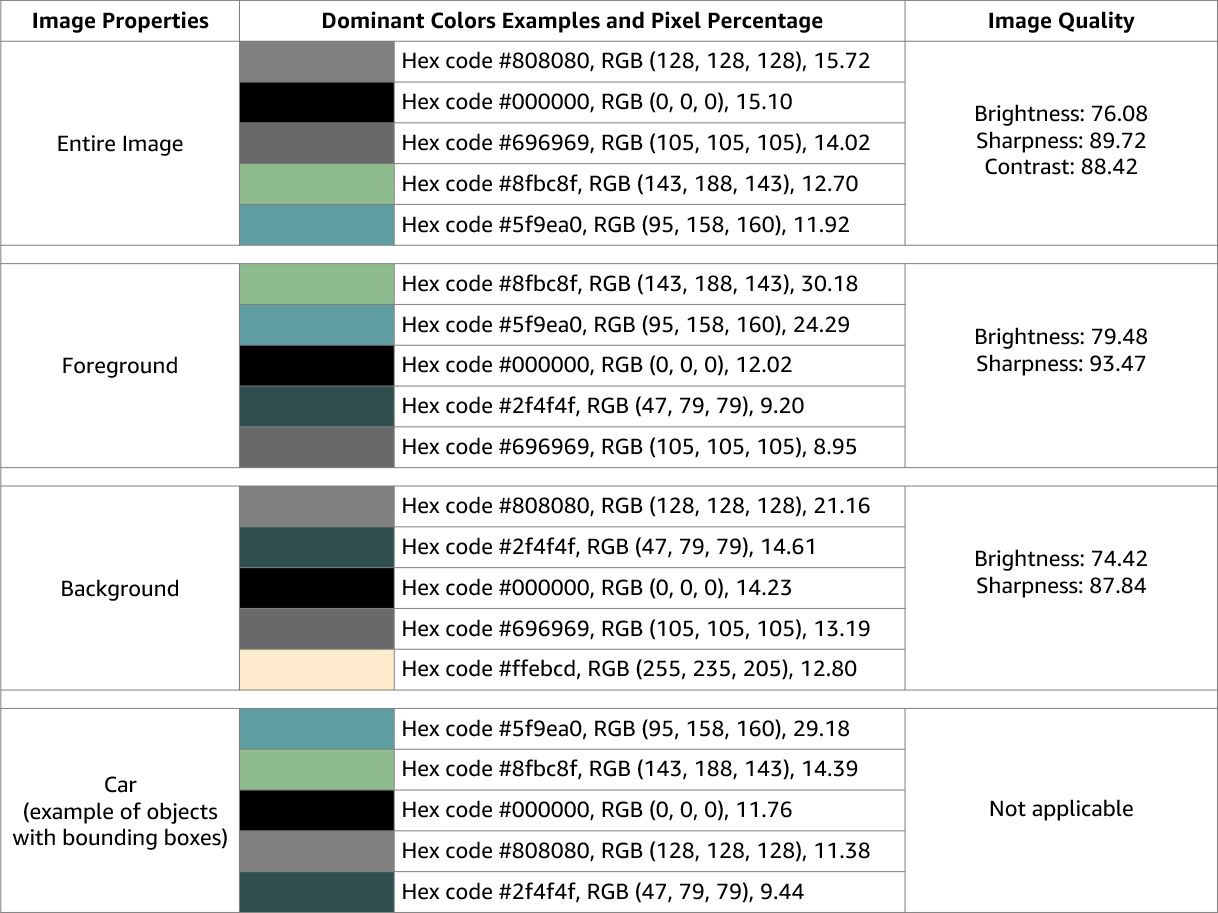
Propriétés de l’image n’est pas disponible pour Vidéo Amazon Rekognition.
Version de modèle
Image Amazon Rekognition et Vidéo Amazon Rekognition renvoient la version du modèle de détection d’étiquette utilisé pour détecter les étiquettes dans une image ou une vidéo stockée.
Filtres d’inclusion et d’exclusion
Vous pouvez filtrer les résultats renvoyés par les opérations de détection d’étiquettes Image Amazon Rekognition et Vidéo Amazon Rekognition. Filtrez les résultats en fournissant des critères de filtrage pour les étiquettes et les catégories. Les filtres d’étiquette peuvent être inclusifs ou exclusifs.
Voir Détection des étiquettes dans une image pour plus d’informations concernant la filtration des résultats obtenus avec DetectLabels.
Voir Détection des étiquettes dans une vidéo pour plus d’informations concernant le filtrage des résultats obtenus par GetLabelDetection.
Tri et agrégation des résultats
Les résultats obtenus à partir de certaines opérations Vidéo Amazon Rekognition peuvent être triés et agrégés en fonction des horodatages et des segments vidéo. Lorsque vous récupérez les résultats d’une tâche de détection d’étiquettes ou de modération de contenu, avec GetLabelDetection ou GetContentModeration respectivement, vous pouvez utiliser les arguments SortBy et AggregateBy pour spécifier la manière dont vous souhaitez que vos résultats soient renvoyés. Vous pouvez utiliser SortBy avec TIMESTAMP ou NAME (noms d'étiquettes) et utiliser TIMESTAMPS ou SEGMENTS avec l' AggregateByargument.
