Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Afficher un rapport sur les performances d'un modèle de pilote automatique
Un rapport sur la qualité du modèle Amazon SageMaker AI (également appelé rapport de performance) fournit des informations et des informations de qualité sur le meilleur modèle candidat généré par une tâche AutoML. Cela inclut des informations sur les détails de la tâche, le type de problème du modèle, la fonction objective et d'autres informations relatives au type de problème. Ce guide explique comment afficher graphiquement les indicateurs de performance d'Amazon SageMaker Autopilot ou les afficher sous forme de données brutes dans un fichier JSON.
Par exemple, dans les problèmes de classification, le rapport de qualité du modèle inclut les éléments suivants :
-
Matrice Confusion
-
Aire située sous la courbe ROC (AUC)
-
Informations pour comprendre les faux positifs et les faux négatifs
-
Compromis entre les vrais positifs et les faux positifs
-
Compromis entre la précision et le rappel
Autopilot fournit également des métriques de performance pour tous vos modèles candidats. Ces métriques sont calculées à l'aide de toutes les données d'entraînement et sont utilisées pour estimer les performances du modèle. La zone de travail principale inclut ces métriques par défaut. Le type de métrique est déterminé par le type de problème à résoudre.
Consultez la documentation de référence de SageMaker l'API Amazon pour obtenir la liste des métriques disponibles prises en charge par Autopilot.
Vous pouvez trier vos modèles candidats par la métrique appropriée pour vous aider à sélectionner et à déployer le modèle qui répond aux besoins de votre entreprise. Pour connaître les définitions de ces métriques, consultez la rubrique Métriques des candidats Autopilot.
Pour consulter un rapport de performances provenant d'une tâche Autopilot, procédez comme suit :
-
Cliquez sur l'icône Accueil (
 ) dans le volet de navigation de gauche pour afficher le menu de navigation supérieur d'Amazon SageMaker Studio Classic.
) dans le volet de navigation de gauche pour afficher le menu de navigation supérieur d'Amazon SageMaker Studio Classic. -
Sélectionnez la carte AutoML dans la zone de travail principale. Ceci ouvre un nouvel onglet Autopilot.
-
Dans la section Name (Nom), sélectionnez la tâche Autopilot qui contient les détails que vous souhaitez examiner. Ceci ouvre un nouvel onglet de Tâche Autopilot.
-
Le panneau Autopilot job (Tâche Autopilot) répertorie les valeurs de métriques, y compris la métrique Objective (Objectif) pour chaque modèle sous Model name (Nom du modèle). Le Best model (Meilleur modèle) est répertorié en haut de la liste sous Model name (Nom du modèle) et est également mis en évidence dans l'onglet Models (Modèles).
-
Pour consulter les détails du modèle, sélectionnez le modèle qui vous intéresse et sélectionnez View model details (Afficher les détails du modèle). Ceci ouvre un nouvel onglet Détails du modèle.
-
-
Choisissez l'onglet Performance (Performances) entre l'onglet Explainability (Explicabilité) et l'onglet Artifacts (Artefacts).
-
Dans la partie supérieure droite de l'onglet, sélectionnez la flèche déroulante sur le bouton Download Performance Reports (Télécharger les rapports de performance).
-
La flèche vers le bas propose deux options pour afficher les métriques de performances Autopilot :
-
Vous pouvez télécharger le rapport de performances au format PDF pour visualiser les métriques sous forme graphique.
-
Vous pouvez afficher les métriques en tant que données brutes et les télécharger sous la forme d'un fichier JSON.
-
-
Pour obtenir des instructions sur la création et l'exécution d'une tâche AutoML dans SageMaker Studio Classic, consultez. Créez des tâches de régression ou de classification pour les données tabulaires à l'aide de l'API AutoML
Le rapport de performances contient deux sections. La première contient des détails sur la tâche Autopilot qui a produit le modèle. La deuxième contient un rapport sur la qualité du modèle.
Détails de la tâche Autopilot
La première section du rapport fournit des informations générales sur la tâche Autopilot qui a produit le modèle. Ces détails de tâche incluent les informations suivantes :
-
Nom du candidat Autopilot
-
Nom de la tâche Autopilot
-
Type de problème
-
Métrique d'objectif
-
Direction de l'optimisation
Rapport de qualité du modèle
Des informations sur la qualité du modèle sont générées par les analyses du modèle Autopilot. Le contenu du rapport généré dépend du type de problème résolu : régression, classification binaire ou classification multi-classes. Le rapport spécifie le nombre de lignes incluses dans le jeu de données d'évaluation et le moment auquel l'évaluation a eu lieu.
Tableaux de métriques
La première partie du rapport sur la qualité du modèle contient des tableaux de métriques. Ils sont adaptés au type de problème traité par le modèle.
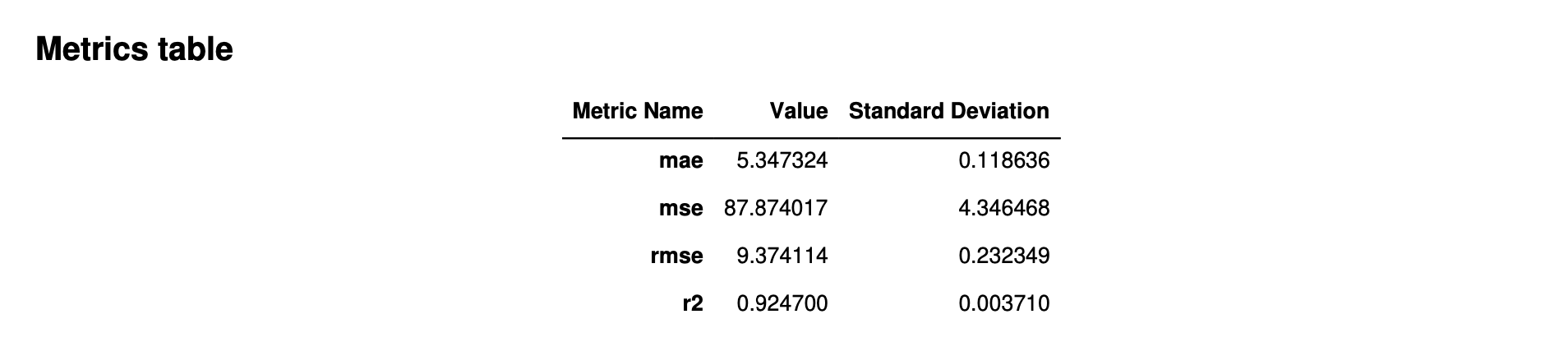
L'image suivante est un exemple de tableau de métriques généré par Autopilot pour un problème de régression. Il indique le nom, la valeur et l'écart type de la métrique.
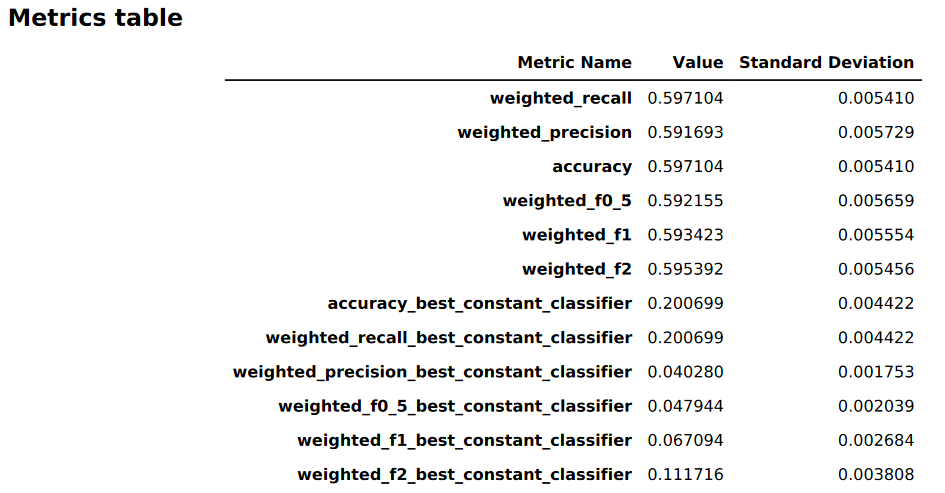
L'image suivante est un exemple de tableau de métriques généré par Autopilot pour un problème de classification multi-classes. Il indique le nom, la valeur et l'écart type de la métrique.
Informations graphiques sur les performances du modèle
La deuxième partie du rapport sur la qualité du modèle contient des informations graphiques qui vous aident à évaluer les performances du modèle. Le contenu de cette section dépend du type de problème utilisé dans la modélisation.
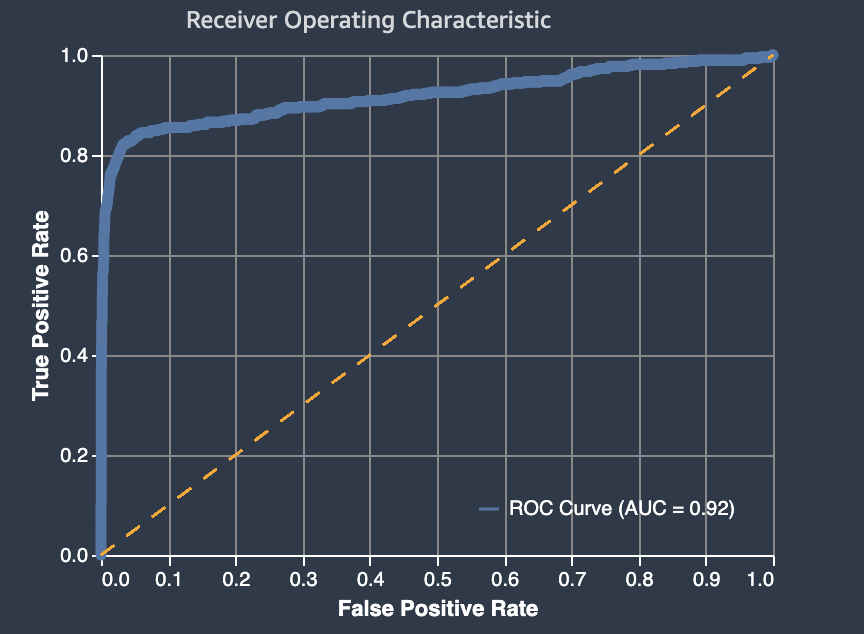
La zone située sous la courbe ROC.
L'aire sous la courbe caractéristique de fonctionnement du récepteur représente le compromis entre les taux de vrais positifs et de faux positifs. Il s'agit d'une métrique de précision conforme aux normes du secteur, utilisée pour les modèles de classification binaire. L'aire sous la courbe (AUC) mesure l'aptitude du modèle à prédire un score plus élevé pour les exemples de positifs, par rapport aux exemples de négatifs. La métrique AUC fournit une métrique regroupée des performances du modèle sur tous les seuils de classification possibles.
Elle renvoie une valeur décimale comprise entre 0 et 1. Les valeurs AUC proches de 1 indiquent que le modèle de machine learning est très précis. Les valeurs proches de 0,5 indiquent que le modèle n'est pas meilleur que de deviner au hasard. Les valeurs AUC proches de 0 indiquent que le modèle a appris les bonnes tendances, mais effectue des prédictions aussi imprécises que possible. Les valeurs proches de zéro peuvent indiquer un problème lié aux données. Pour plus d'informations sur la métrique AUC, accédez à l'article Courbe ROC
Voici un exemple de graphe d'aire sous la courbe caractéristique de fonctionnement du récepteur permettant d'évaluer les prédictions effectuées par un modèle de classification binaire. La fine ligne pointillée représente la zone située sous la courbe des caractéristiques de fonctionnement du récepteur à laquelle un modèle qui classe les no-better-than-random suppositions obtiendrait un score, avec un score AUC de 0,5. Les courbes de modèles de classification plus précise se situent au-dessus de cette ligne de base aléatoire, où le taux de vrais positifs dépasse le taux de faux positifs. L'aire sous la courbe caractéristique de fonctionnement du récepteur représentant la performance du modèle de classification binaire correspond à la ligne épaisse continue.
Un résumé des composantes du graphe relatives au taux de faux positifs (FPR) et au taux de vrais positifs (TPR) est défini comme suit.
-
Prédictions correctes
-
Vrai positif (TP) : la valeur prévue est 1 et la valeur vraie est 1.
-
Vrai négatif (TN) : la valeur prévue est 0 et la valeur vraie est 0.
-
-
Prédictions erronées
-
Faux positif (FP) : la valeur prévue est 1, mais la vraie valeur est 0.
-
Faux négatif (FN) : la valeur prévue est 0, mais la vraie valeur est 1.
-
Le taux de faux positifs (FPR) mesure la fraction de vrais négatifs (TN) faussement prédits comme positifs (FP), par rapport à la somme des FP et des TN. La plage est comprise entre 0 et 1. Plus la valeur est petite et meilleure est la précision prédictive.
-
TFP = FP/(FP+TN)
Le taux de vrais positifs (TPR) mesure la fraction de vrais positifs correctement prédits comme positifs (TP), par rapport à la somme des TP et des faux négatifs (FN). La plage est comprise entre 0 et 1. Plus la valeur est grande et meilleure est la précision prédictive.
-
TPR = TP/(TP+FN)
Matrice Confusion
Une matrice de confusion permet de visualiser la précision des prédictions faites par un modèle de classification binaire et multi-classes pour différents problèmes. La matrice de confusion du rapport sur la qualité du modèle contient les éléments suivants.
-
Le nombre et le pourcentage de prédictions correctes et incorrectes pour les étiquettes réelles
-
Le nombre et le pourcentage de prédictions exactes sur la diagonale, du coin supérieur gauche au coin inférieur droit
-
Le nombre et le pourcentage de prédictions inexactes sur la diagonale, du coin supérieur droit au coin inférieur gauche
Les prédictions incorrectes d'une matrice de confusion sont les valeurs de confusion.
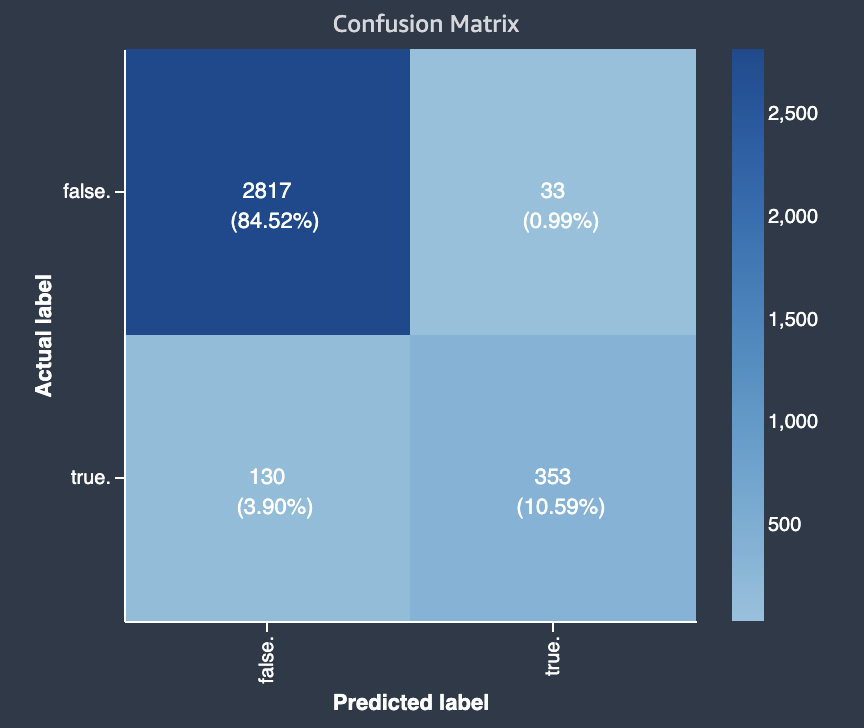
Le diagramme suivant est un exemple de matrice de confusion pour un problème de classification binaire. Elle contient les informations suivantes :
-
L'axe vertical est divisé en deux rangées contenant des étiquettes réelles vraies et fausses.
-
L'axe horizontal est divisé en deux colonnes contenant des étiquettes vraies et fausses prédites par le modèle.
-
La barre de couleur attribue une tonalité plus foncée à un plus grand nombre d'échantillons afin d'indiquer visuellement le nombre de valeurs classées dans chaque catégorie.
Dans cet exemple, le modèle a prédit correctement 2 817 valeurs fausses réelles et 353 valeurs vraies réelles. Le modèle a prédit incorrectement que 130 valeurs vraies réelles étaient fausses et que 33 valeurs fausses réelles étaient vraies. La différence de tonalité indique que le jeu de données n'est pas équilibré. Le déséquilibre est dû au fait qu'il y a beaucoup plus d'étiquettes fausses réelles que d'étiquettes vraies réelles.
Le diagramme suivant est un exemple de matrice de confusion pour un problème de classification multi-classes. La matrice de confusion du rapport sur la qualité du modèle contient les éléments suivants.
-
L'axe vertical est divisé en trois rangées contenant trois étiquettes réelles différentes.
-
L'axe horizontal est divisé en trois colonnes contenant des étiquettes prédites par le modèle.
-
La barre de couleur attribue une tonalité plus foncée à un plus grand nombre d'échantillons afin d'indiquer visuellement le nombre de valeurs classées dans chaque catégorie.
Dans l'exemple ci-dessous, le modèle a correctement prédit 354 valeurs réelles pour l'étiquette f, 1094 valeurs pour l'étiquette i et 852 valeurs pour l'étiquette m. La différence de tonalité indique que le jeu de données n'est pas équilibré car il existe beaucoup plus d'étiquettes pour la valeur i que pour f ou m.
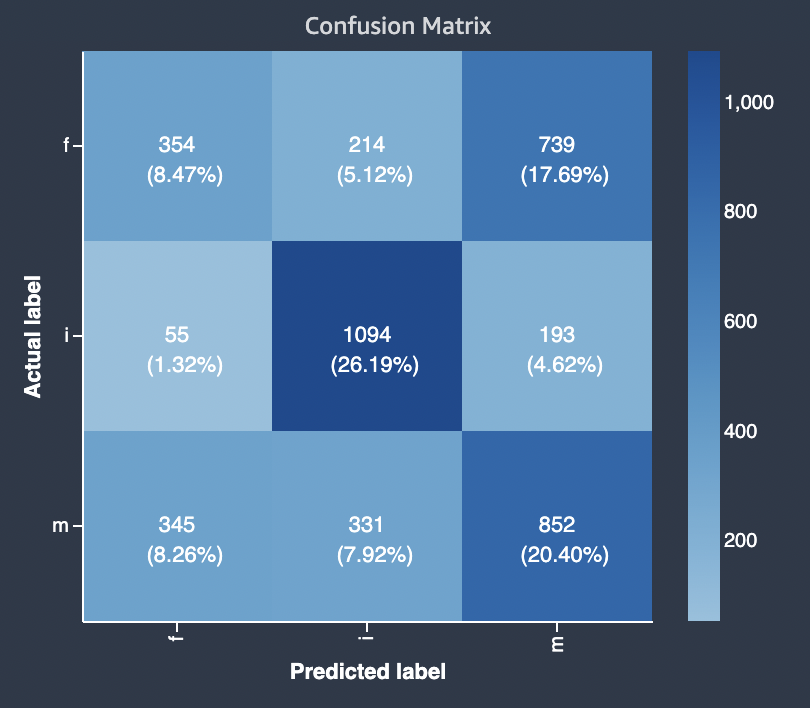
La matrice de confusion du rapport sur la qualité du modèle fourni peut prendre en charge un maximum de 15 étiquettes pour les types de problèmes de classification multi-classes. Si une ligne correspondant à une étiquette affiche une valeur Nan, cela signifie que le jeu de données de validation utilisé pour vérifier les prévisions du modèle ne contient pas de données portant cette étiquette.
Courbe de gain
Dans la classification binaire, une courbe de gain prédit l'avantage cumulé de l'utilisation d'un pourcentage du jeu de données pour trouver une étiquette positive. La valeur du gain est calculée pendant l'entraînement en divisant le nombre cumulé d'observations positives par le nombre total d'observations positives dans les données, à chaque décile. Si le modèle de classification créé pendant l'entraînement est représentatif des données invisibles, vous pouvez utiliser la courbe de gain pour prédire le pourcentage de données que vous devez cibler pour obtenir un pourcentage d'étiquettes positives. Plus le pourcentage du jeu de données utilisé est élevé, plus le pourcentage d'étiquettes positives trouvées est élevé.
Dans l'exemple de graphe suivant, la courbe de gain est la ligne dont la pente change. La ligne droite correspond au pourcentage d'étiquettes positives trouvées en sélectionnant au hasard un pourcentage de données dans le jeu de données. En ciblant 20 % du jeu de données, vous pouvez vous attendre à trouver plus de 40 % d'étiquettes positives. À titre d'exemple, vous pouvez envisager d'utiliser une courbe de gain pour déterminer vos efforts dans le cadre d'une campagne marketing. En utilisant notre exemple de courbe de gain, pour que 83 % des habitants d'un quartier achètent des cookies, vous enverriez une publicité à environ 60 % de la population du quartier.
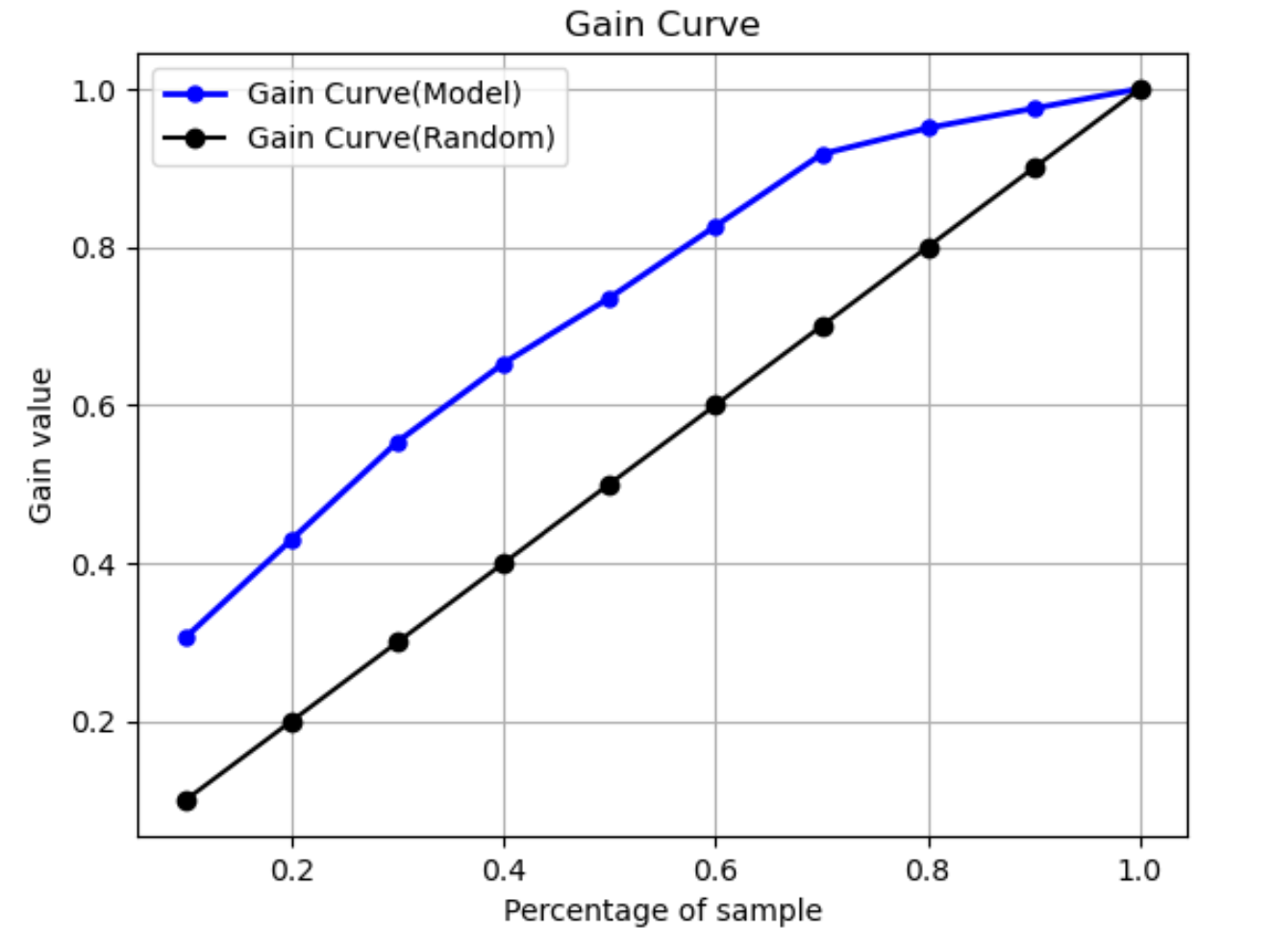
Courbe de Lift
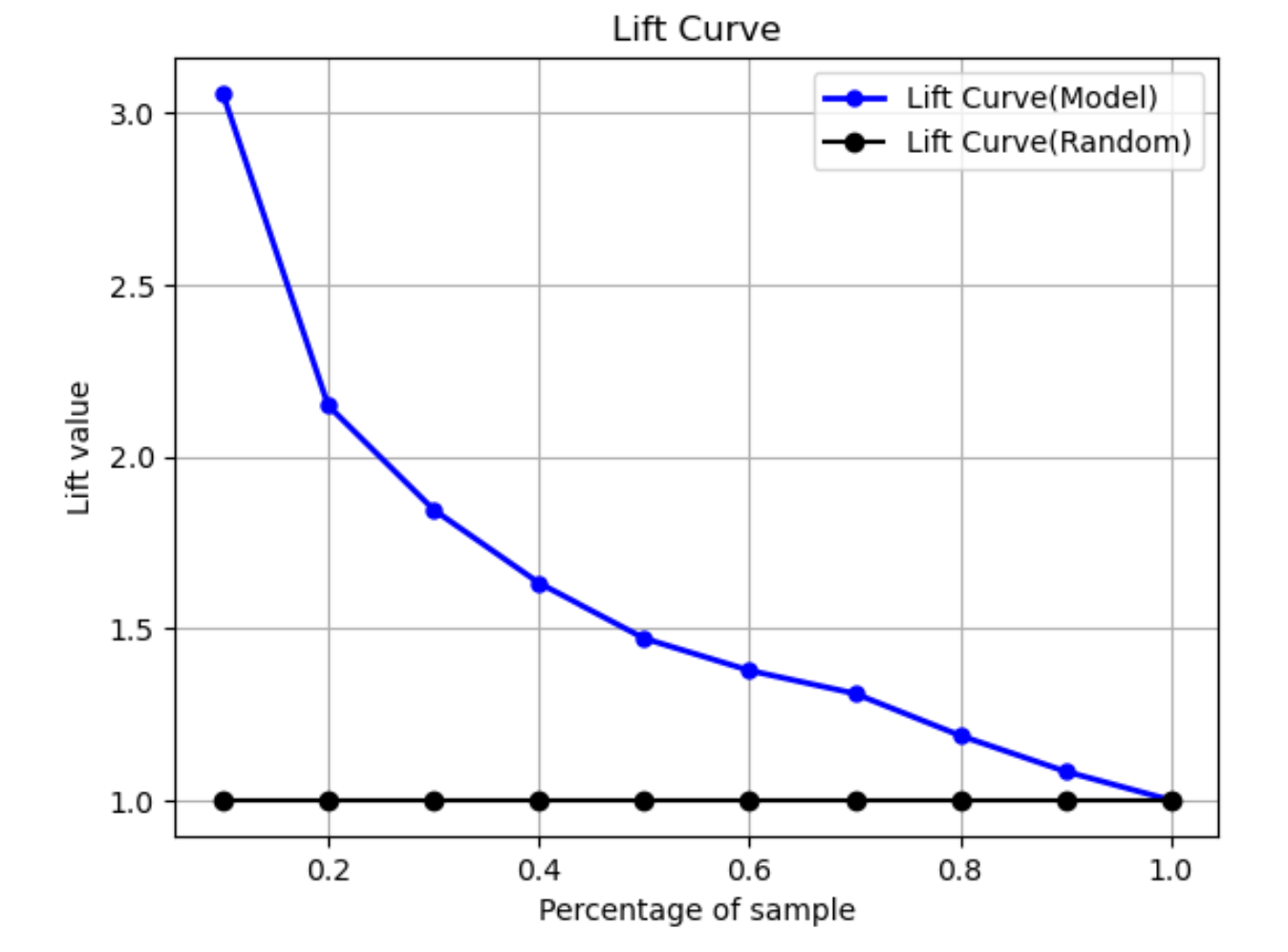
En classification binaire, la courbe de Lift illustre l'amélioration apportée par l'utilisation d'un modèle entraîné pour prédire la probabilité de trouver une étiquette positive par rapport à une estimation aléatoire. La valeur de Lift est calculée pendant l'entraînement en utilisant le ratio du pourcentage de gain par rapport au ratio d'étiquettes positives à chaque décile. Si le modèle créé pendant l'entraînement est représentatif des données invisibles, utilisez la courbe de Lift pour prédire l'avantage à utiliser le modèle par rapport à des suppositions aléatoires.
Dans l'exemple de graphe suivant, la courbe de Lift est la ligne dont la pente change. La ligne droite est la courbe de Lift associée à la sélection aléatoire du pourcentage correspondant dans le jeu de données. Si vous ciblez 40 % du jeu de données avec les étiquettes de classification de votre modèle, vous pouvez vous attendre à trouver environ 1,7 fois plus d'étiquettes positives que vous auriez trouvées en sélectionnant au hasard 40 % des données invisibles.
Courbe de rappel de précision
La courbe de précision-rappel représente le compromis entre précision et rappel pour les problèmes de classification binaire.
La précision mesure la fraction de positifs réels qui sont prédits comme positifs (TP) parmi l'ensemble des prédictions positives (TP et faux positifs). La plage est comprise entre 0 et 1. Plus la valeur est grande et meilleure est la précision des valeurs prédites.
-
Précision = TP/(TP+FP)
Recall mesure la fraction de positifs réels prévus comme positifs (TP) par rapport à toutes les prédictions positives réelles (TP et faux négatifs). Ceci est également connu sous le nom de sensibilité ou de véritable taux positif. La plage est comprise entre 0 et 1. Une valeur plus élevée indique une meilleure détection des valeurs positives de l'exemple.
-
Rappel = TP/(TP+FN)
L'objectif d'un problème de classification est d'étiqueter correctement autant d'éléments que possible. Un système avec un rappel élevé, mais une faible précision, renvoie un pourcentage élevé de faux positifs.
Le graphe suivant illustre un filtre de courrier indésirable qui marque chaque e-mail comme courrier indésirable. Son rappel est élevé, mais sa précision est faible, car le rappel ne mesure pas les faux positifs.
Accordez plus de poids au rappel qu'à la précision si votre problème a une faible pénalité pour les valeurs de faux positifs, mais une pénalité élevée pour le fait de manquer un résultat vrai positif. Par exemple, la détection d'une collision imminente dans un véhicule autonome.
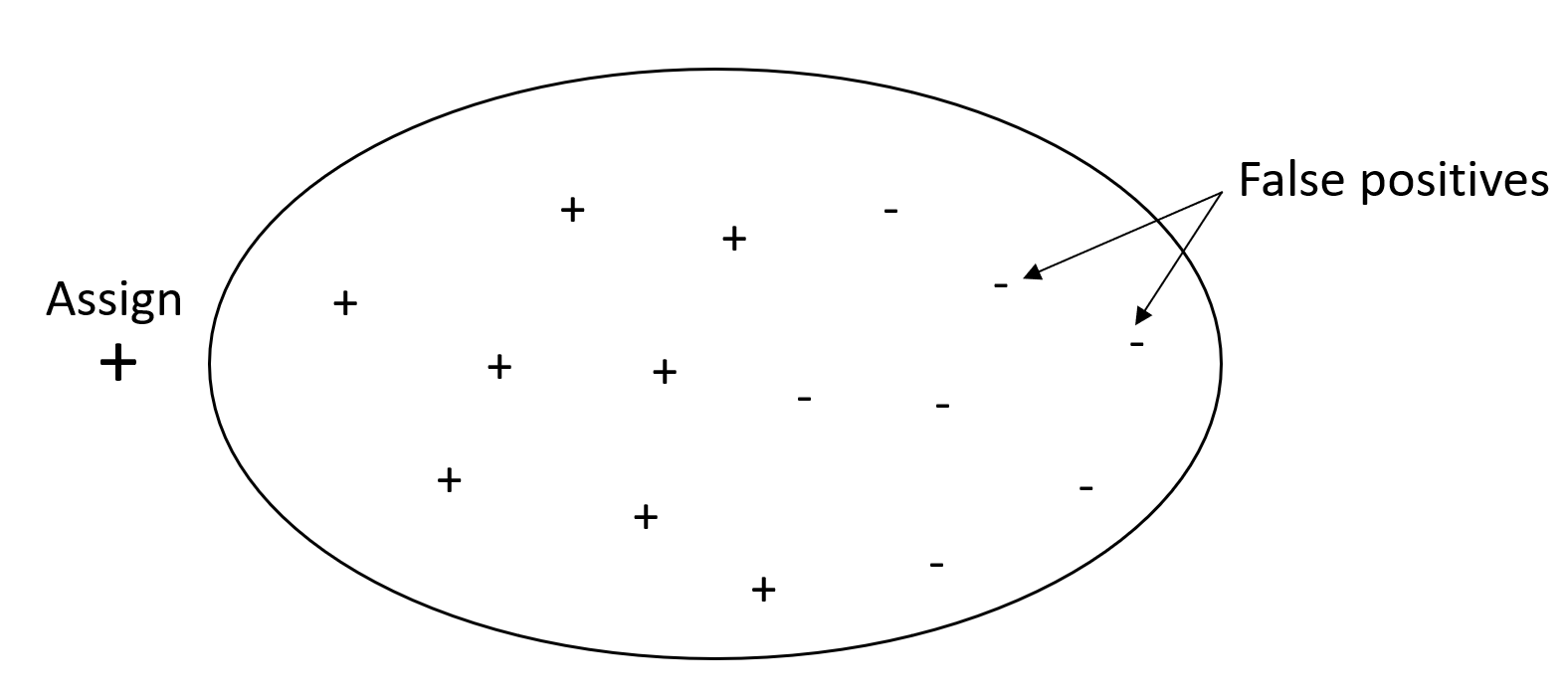
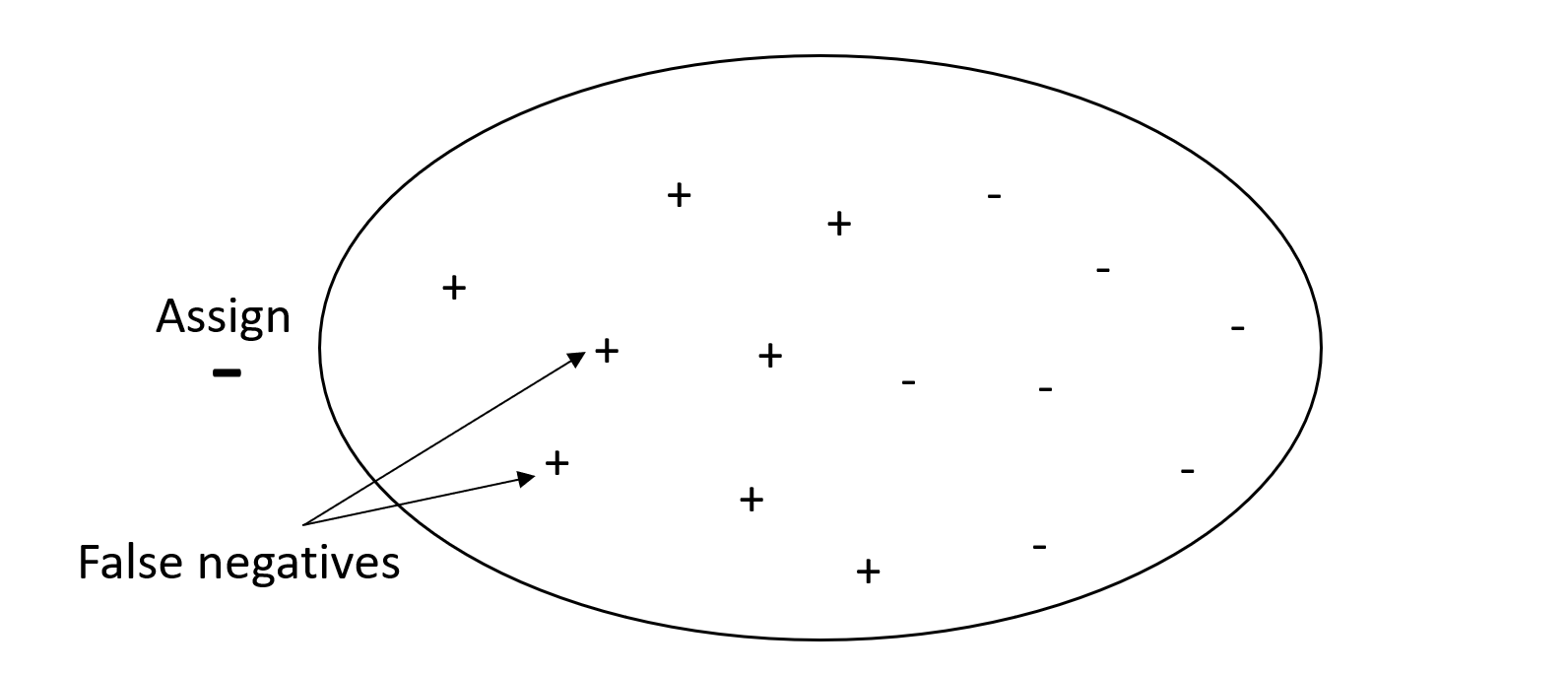
En revanche, un système avec précision élevée, mais faible rappel, renvoie un pourcentage élevé de faux négatifs. Un filtre de courrier indésirable qui marque chaque e-mail comme souhaitable (et non comme courrier indésirable) a une précision élevée et un faible rappel, car la précision ne mesure pas les faux négatifs.
Si votre problème a une faible pénalité pour les valeurs de faux négatifs, mais une pénalité élevée pour le fait de manquer des résultats de vrais négatifs, accordez plus de poids à la précision qu'au rappel. Par exemple, le signalement d'un filtre suspect pour un contrôle fiscal.
Le graphe suivant représente un filtre de courrier indésirable à précision élevée, mais faible rappel, car la précision ne mesure pas les faux négatifs.
Un modèle qui réalise des prédictions avec à la fois une précision élevée et un rappel élevé produit un grand nombre de résultats correctement étiquetés. Pour en savoir plus, consultez Précision et rappel
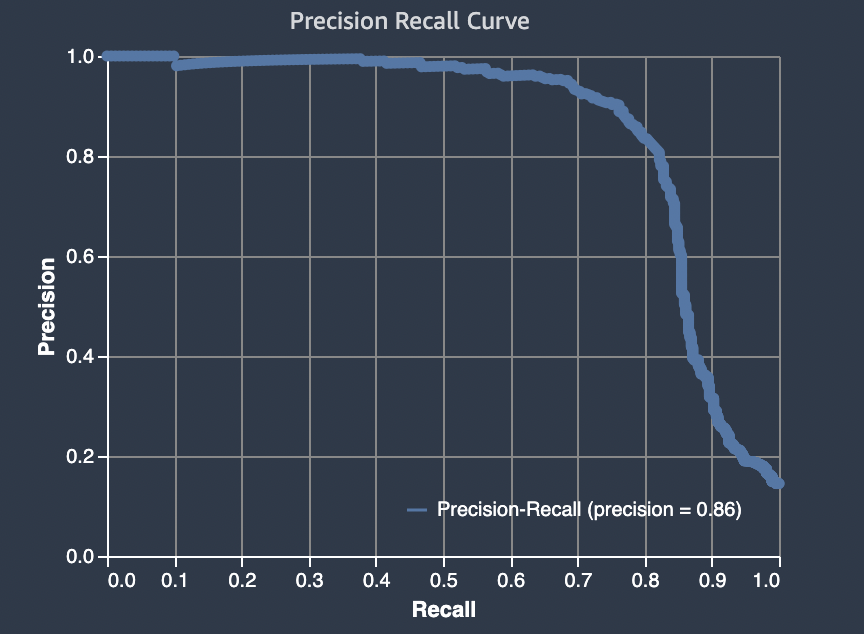
Aire sous la courbe précision-rappel (AUPRC)
Pour les problèmes de classification binaire, Amazon SageMaker Autopilot inclut un graphique de la zone située sous la courbe de rappel de précision (AUPRC). La métrique AUPRC fournit une mesure agrégée des performances du modèle sur tous les seuils de classification possibles et utilise à la fois la précision et le rappel. La courbe AUPRC ne prend pas en compte le nombre de vrais négatifs. Il peut donc être utile d'évaluer les performances du modèle dans les cas où les données contiennent un grand nombre de vrais négatifs. Par exemple, pour modéliser un gène contenant une mutation rare.
Le graphique suivant est un exemple de graphe AUPRC. La précision à sa valeur la plus élevée est de 1 et le rappel est de 0. Dans le coin inférieur droit du graphe, le rappel est sa valeur la plus élevée (1) et la précision est 0. Entre ces deux points, la courbe AUPRC illustre le compromis entre la précision et le rappel à différents seuils.
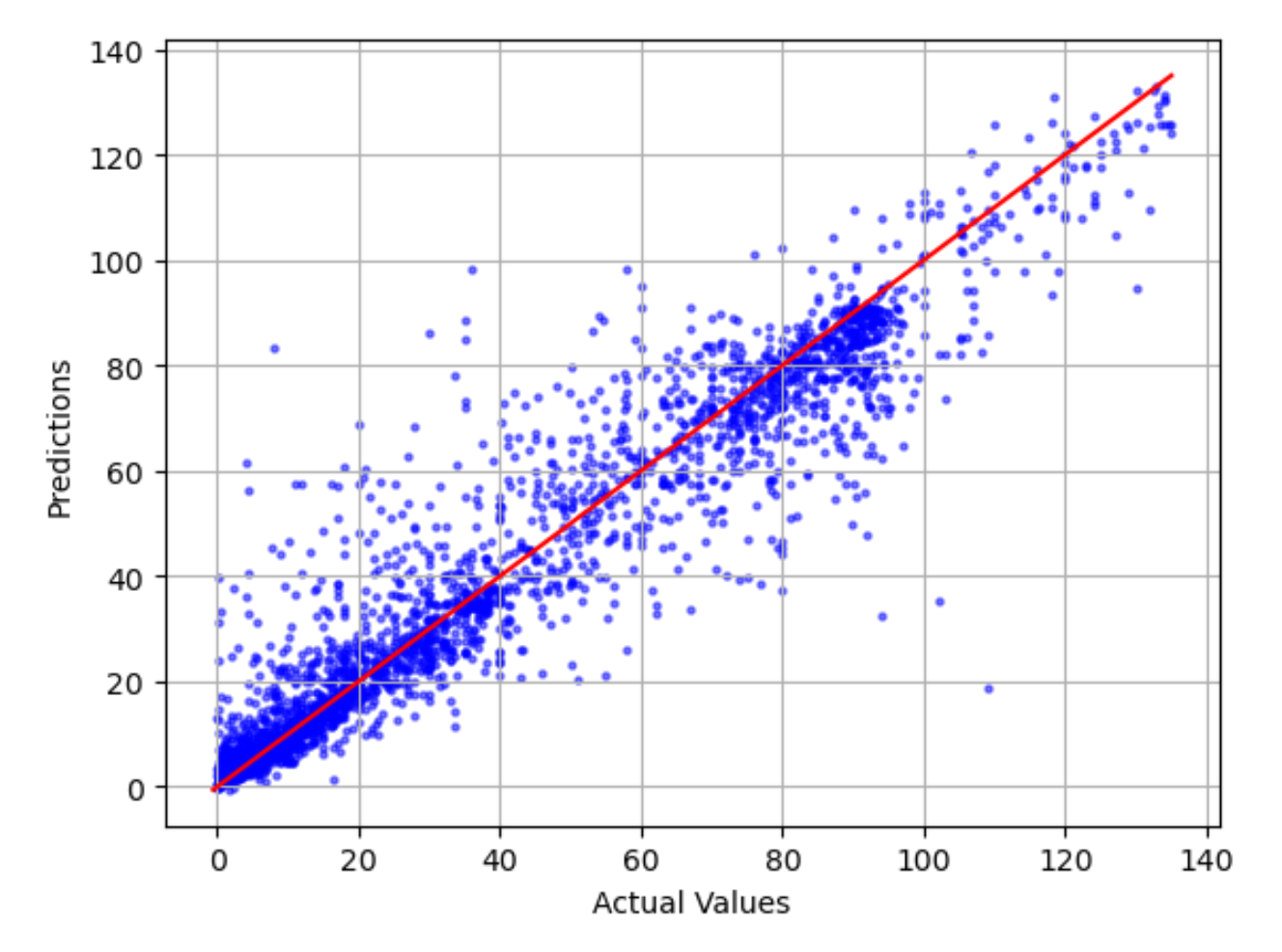
Tracé des valeurs réelles par rapport aux prédictions
Le tracé des valeurs réelles par rapport aux prédictions montre la différence entre les valeurs réelles et les valeurs prédites du modèle. Dans l'exemple de graphe suivant, la ligne continue est une droite de meilleur ajustement. Si le modèle était précis à 100 %, chaque point prédit serait égal à son point réel correspondant et se situerait sur cette droite de meilleur ajustement. La distance par rapport à la droite de meilleur ajustement est une indication visuelle de l'erreur du modèle. Plus la distance par rapport à la droite de meilleur ajustement est grande, plus l'erreur du modèle est importante.
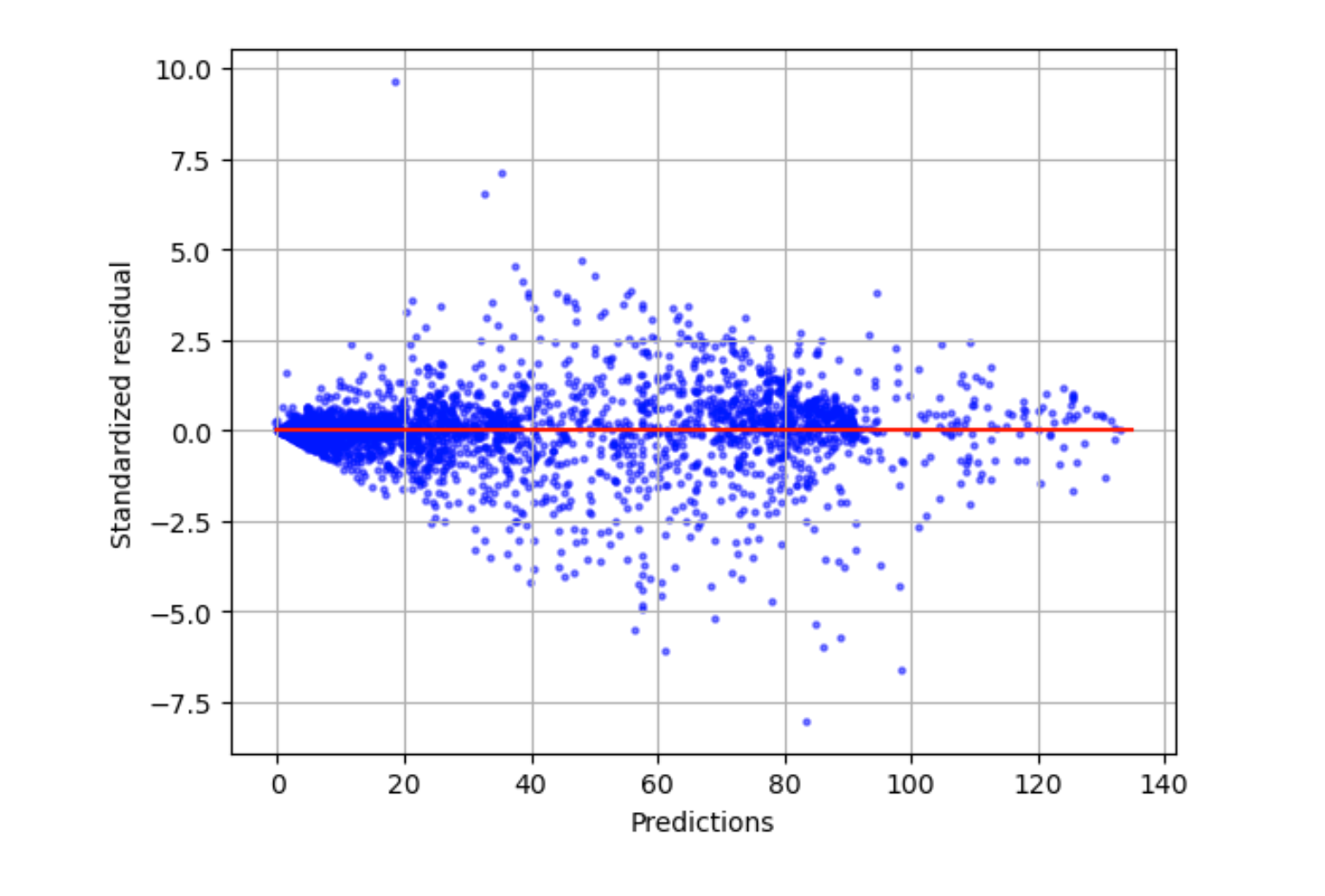
Tracé résiduel normalisé
Un tracé résiduel normalisé intègre les termes statistiques suivants :
residual-
Un résiduel (brut) indique la différence entre les valeurs réelles et les valeurs prédites par votre modèle. Plus la différence est importante, plus la valeur résiduelle est importante.
standard deviation-
L'écart type est une mesure de la façon dont les valeurs varient par rapport à une valeur moyenne. Un écart type élevé indique que de nombreuses valeurs sont très différentes de leur valeur moyenne. Un écart type faible indique que de nombreuses valeurs sont proches de leur valeur moyenne.
standardized residual-
Un résiduel normalisé divise les résiduels bruts par leur écart type. Les résiduels normalisés comportent des unités d'écart type et sont utiles pour identifier les valeurs aberrantes dans les données, quelle que soit la différence d'échelle des résiduels bruts. Si un résiduel normalisé est beaucoup plus petit ou plus grand que les autres résiduels normalisés, cela indique que le modèle ne correspond pas bien à ces observations.
Le tracé résiduel normalisé mesure la force de la différence entre les valeurs observées et attendues. La valeur réelle prédite est affichée sur l'axe X. Un point dont la valeur est supérieure à la valeur absolue de 3 est généralement considéré comme une valeur aberrante.
L'exemple de graphe suivant montre qu'un grand nombre de résiduels normalisés sont regroupés autour de 0 sur l'axe horizontal. Les valeurs proches de zéro indiquent que le modèle correspond bien à ces points. Les points situés en haut et en bas du tracé ne sont pas bien prédits par le modèle.
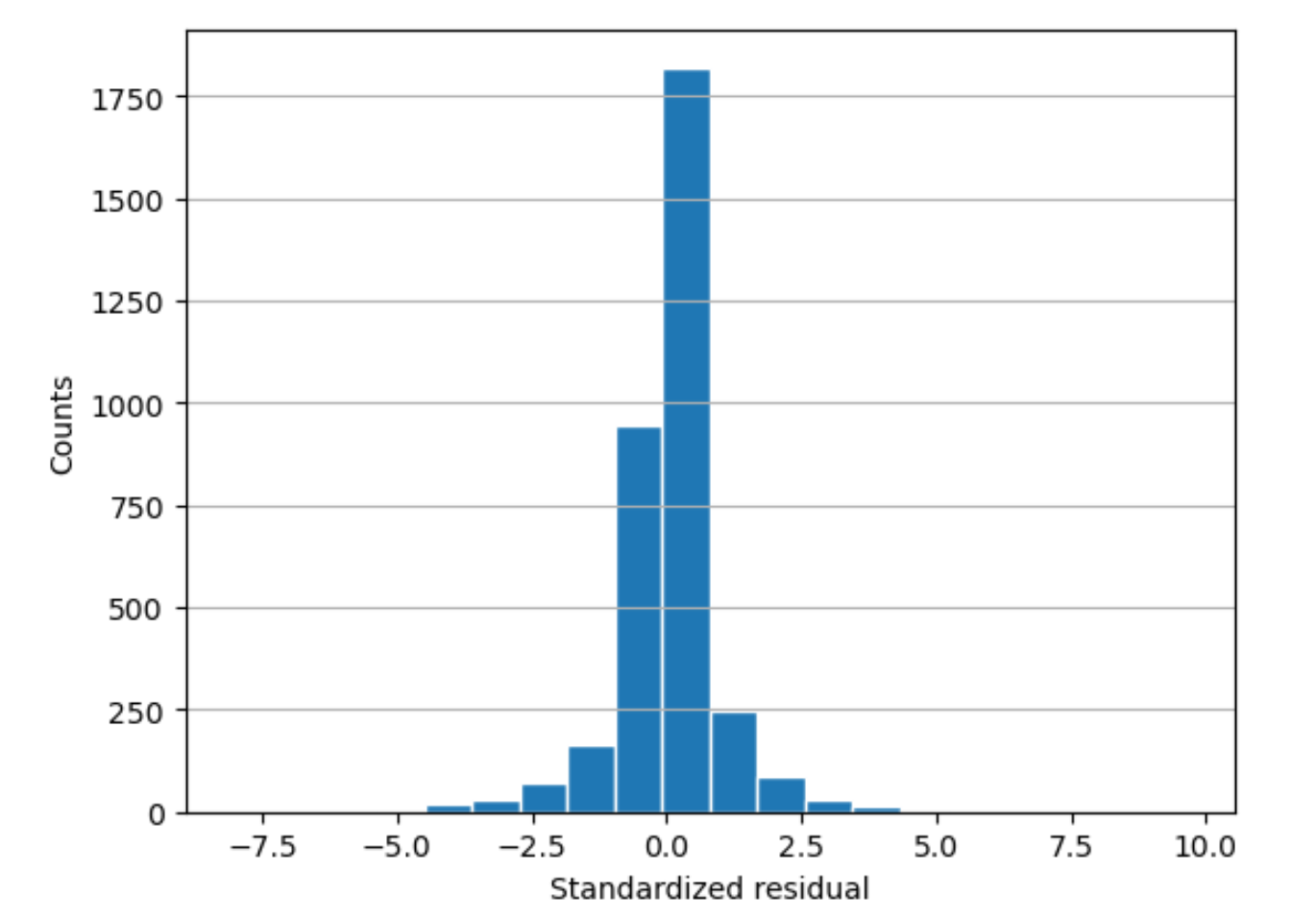
Histogramme résiduel
Un histogramme résiduel intègre les termes statistiques suivants :
residual-
Un résiduel (brut) indique la différence entre les valeurs réelles et les valeurs prédites par votre modèle. Plus la différence est importante, plus la valeur résiduelle est importante.
standard deviation-
L'écart type est une mesure du degré de variation des valeurs par rapport à une valeur moyenne. Un écart type élevé indique que de nombreuses valeurs sont très différentes de leur valeur moyenne. Un écart type faible indique que de nombreuses valeurs sont proches de leur valeur moyenne.
standardized residual-
Un résiduel normalisé divise les résiduels bruts par leur écart type. Les résiduels normalisés ont des unités d'écart type. Ils sont utiles pour identifier les valeurs aberrantes dans les données, quelle que soit la différence d'échelle des résiduels bruts. Si un résiduel normalisé est beaucoup plus petit ou plus grand que les autres résiduels normalisés, cela indique que le modèle ne correspond pas bien à ces observations.
histogram-
Un histogramme est un graphe qui indique la fréquence d'apparition d'une valeur.
L'histogramme résiduel montre la distribution des valeurs résiduelles normalisées. Un histogramme distribué en forme de cloche centrée sur zéro indique que le modèle ne prédit pas systématiquement trop haut ou trop bas une plage particulière de valeurs cibles.
Dans le graphique suivant, les valeurs résiduelles normalisées indiquent que le modèle correspond bien aux données. Si le graphe montrait des valeurs très éloignées de la valeur centrale, cela indiquerait que ces valeurs ne correspondent pas bien au modèle.