Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Équité, explicabilité du modèle et détection des biais avec Clarify SageMaker
Vous pouvez utiliser Amazon SageMaker Clarify pour comprendre l'équité et l'explicabilité des modèles, ainsi que pour expliquer et détecter les biais dans vos modèles. Vous pouvez configurer une tâche de traitement SageMaker Clarify pour calculer les métriques de biais et les attributions de fonctionnalités et générer des rapports pour expliquer le modèle. SageMaker Les tâches de traitement Clarify sont implémentées à l'aide d'une image de conteneur SageMaker Clarify spécialisée. La page suivante décrit le fonctionnement de SageMaker Clarify et explique comment démarrer une analyse.
Qu'est-ce que l'équité et l'explicabilité du modèle pour les prédictions de machine learning ?
Les modèles d'apprentissage automatique (ML) aident à prendre des décisions dans des domaines tels que les services financiers, les soins de santé, l'éducation et les ressources humaines. Les décideurs politiques, les régulateurs et les défenseurs des droits ont sensibilisé le public aux défis éthiques et politiques posés par le blanchiment d'argent et les systèmes pilotés par les données. Amazon SageMaker Clarify peut vous aider à comprendre pourquoi votre modèle de machine learning a fait une prédiction spécifique et si ce biais a un impact sur cette prédiction pendant l'entraînement ou l'inférence. SageMaker Clarify fournit également des outils qui peuvent vous aider à créer des modèles d'apprentissage automatique moins biaisés et plus compréhensibles. SageMaker Clarify peut également générer des rapports de gouvernance modèles que vous pouvez fournir aux équipes chargées des risques et de la conformité et aux régulateurs externes. Avec SageMaker Clarify, vous pouvez effectuer les opérations suivantes :
-
Détectez les biais et aidez à expliquer les prédictions de votre modèle.
-
Identifiez les types de biais dans les données de pré-entraînement.
-
Identifiez les types de biais dans les données post-entraînement qui peuvent apparaître pendant la formation ou lorsque votre modèle est en production.
SageMaker Clarify permet d'expliquer comment vos modèles font des prédictions à l'aide des attributions de fonctionnalités. Il peut également surveiller les modèles d'inférence en production pour détecter à la fois le biais et la dérive d'attribution des caractéristiques. Ces informations peuvent vous aider dans les domaines suivants :
-
Réglementation — Les décideurs politiques et autres régulateurs peuvent être préoccupés par les effets discriminatoires des décisions qui utilisent les résultats des modèles de blanchiment d'argent. Par exemple, un modèle de machine learning peut coder un biais et influencer une décision automatisée.
-
Affaires — Les domaines réglementés peuvent avoir besoin d'explications fiables sur la façon dont les modèles de machine learning font des prédictions. L'explicabilité du modèle peut être particulièrement importante pour les industries qui dépendent de la fiabilité, de la sécurité et de la conformité. Cela peut inclure les services financiers, les ressources humaines, les soins de santé et le transport automatisé. Par exemple, les demandes de prêt peuvent avoir besoin d'expliquer comment les modèles de machine learning ont fait certaines prédictions aux agents de crédit, aux prévisionnistes et aux clients.
-
Science des données — Les data scientists et les ingénieurs du machine learning peuvent déboguer et améliorer les modèles de machine learning lorsqu'ils peuvent déterminer si un modèle fait des inférences basées sur des fonctionnalités bruyantes ou non pertinentes. Ils peuvent également comprendre les limites de leurs modèles et les modes de défaillance auxquels ils peuvent être confrontés.
Pour un article de blog expliquant comment concevoir et créer un modèle d'apprentissage automatique complet pour les réclamations automobiles frauduleuses qui intègre SageMaker Clarify dans un pipeline d' SageMaker IA, consultez l'architecte et créez le cycle de vie complet de l'apprentissage automatique avec AWS : une démo end-to-end Amazon SageMaker AI
Meilleures pratiques pour évaluer l'équité et l'explicabilité du cycle de vie du machine learning
L'équité en tant que processus — Les notions de partialité et d'équité dépendent de leur application. La mesure du biais et le choix des mesures de biais peuvent être guidés par des considérations sociales, juridiques et autres considérations non techniques. L'adoption réussie d'approches de blanchiment fondées sur l'équité passe par l'établissement d'un consensus et la mise en place d'une collaboration entre les principales parties prenantes. Il peut s'agir de produits, de politiques, de services juridiques, d'ingénierie, d' AI/ML équipes, d'utilisateurs finaux et de communautés.
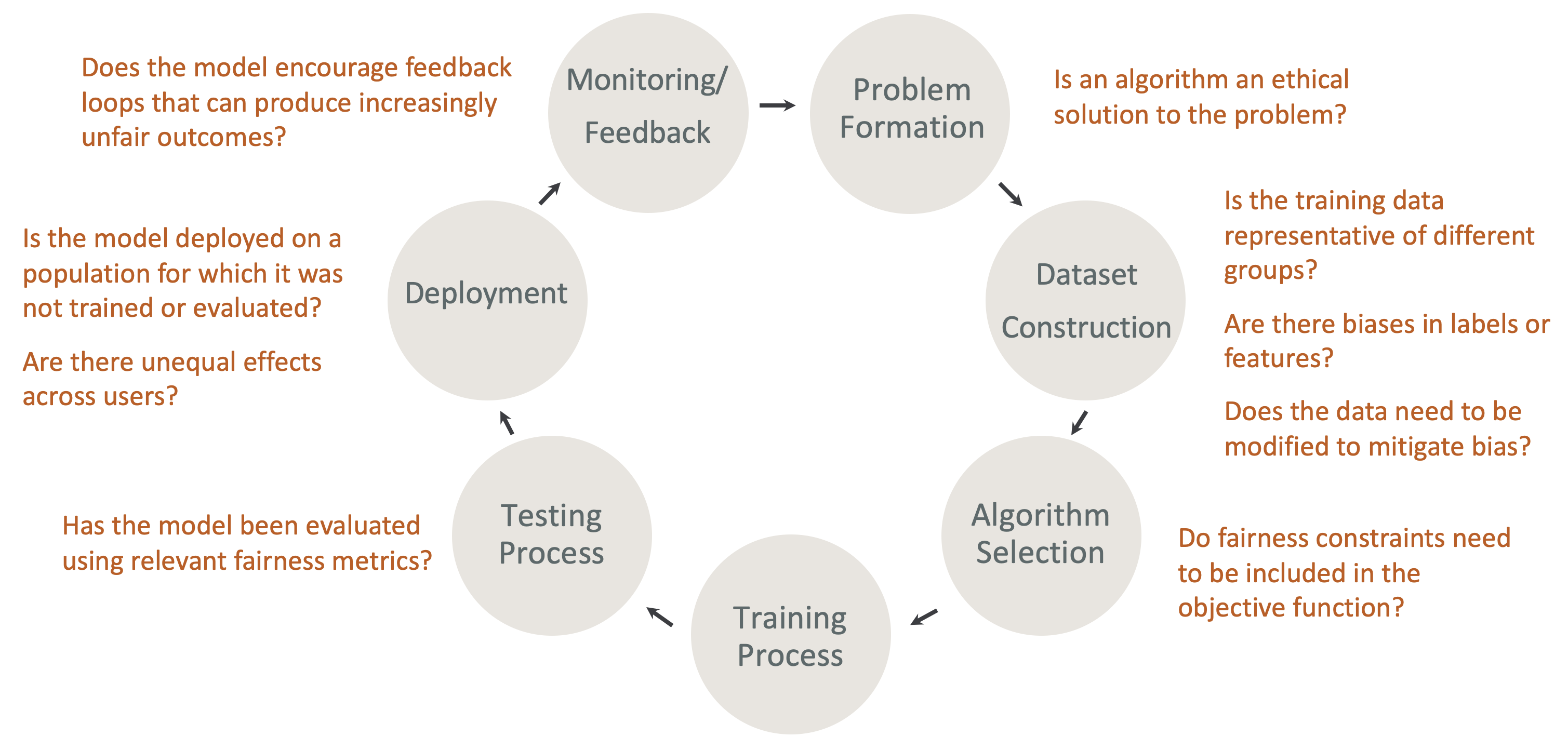
Équité et explicabilité dès la conception dans le cycle de vie du ML — Tenez compte de l'équité et de l'explicabilité à chaque étape du cycle de vie du ML. Ces étapes incluent la formation des problèmes, la construction du jeu de données, la sélection des algorithmes, le processus de formation du modèle, le processus de test, le déploiement, le suivi et le feedback. Il est indispensable de disposer des bons outils pour réaliser cette analyse. Nous vous recommandons de vous poser les questions suivantes au cours du cycle de vie du machine learning :
-
Le modèle encourage-t-il les boucles de rétroaction qui peuvent produire des résultats de plus en plus injustes ?
-
Un algorithme est-il une solution éthique au problème ?
-
Les données d'entraînement sont-elles représentatives de différents groupes ?
-
Y a-t-il des biais dans les étiquettes ou les fonctionnalités ?
-
Les données doivent-elles être modifiées pour atténuer les biais ?
-
Les contraintes d'équité doivent-elles être incluses dans la fonction objective ?
-
Le modèle a-t-il été évalué à l'aide de mesures d'équité pertinentes ?
-
Y a-t-il des effets inégaux entre les utilisateurs ?
-
Le modèle est-il déployé sur une population pour laquelle il n'a pas été formé ou évalué ?
Guide des explications sur l' SageMaker IA et de la documentation sur les biais
Des biais peuvent apparaître et être mesurés dans les données avant et après l'entraînement d'un modèle. SageMaker Clarify peut fournir des explications pour les prédictions des modèles après l'entraînement et pour les modèles déployés en production. SageMaker Clarify peut également surveiller les modèles en production pour détecter toute dérive dans leurs attributions explicatives de base et calculer des bases de référence si nécessaire. La documentation permettant d'expliquer et de détecter les biais à l'aide de SageMaker Clarify est structurée comme suit :
-
Pour plus d'informations sur la configuration d'une tâche de traitement en fonction du biais et de l'explicabilité, voir. Configurer un Job de traitement SageMaker Clarify
-
Pour plus d'informations sur la détection des biais dans le prétraitement des données avant leur utilisation pour entraîner un modèle, voirBiais des données avant l'entraînement.
-
Pour plus d'informations sur la détection des données post-entraînement et des biais du modèle, voirDonnées post-entraînement et biais du modèle.
-
Pour plus d'informations sur l'approche d'attribution de caractéristiques indépendante du modèle pour expliquer les prédictions du modèle après l'entraînement, voir. Explicabilité du modèle
-
Pour plus d'informations sur la surveillance de la dérive de la contribution des fonctionnalités par rapport à la ligne de base établie lors de l'entraînement du modèle, voirDérive d'attribution des fonctionnalités pour les modèles en production.
-
Pour plus d'informations sur la surveillance des modèles en production pour la dérive de la ligne de base, voirDérive de biais pour les modèles en production.
-
Pour plus d'informations sur l'obtention d'explications en temps réel à partir d'un point de terminaison d' SageMaker IA, consultezExplicabilité en ligne avec Clarify SageMaker .
Comment fonctionnent les tâches SageMaker Clarify Processing
Vous pouvez utiliser SageMaker Clarify pour analyser vos ensembles de données et modèles afin de déterminer s'ils sont explicables et biaisés. Une tâche de traitement SageMaker Clarify utilise le conteneur de traitement SageMaker Clarify pour interagir avec un compartiment Amazon S3 contenant vos ensembles de données d'entrée. Vous pouvez également utiliser SageMaker Clarify pour analyser un modèle client déployé sur un point de terminaison d'inférence SageMaker basé sur l'IA.
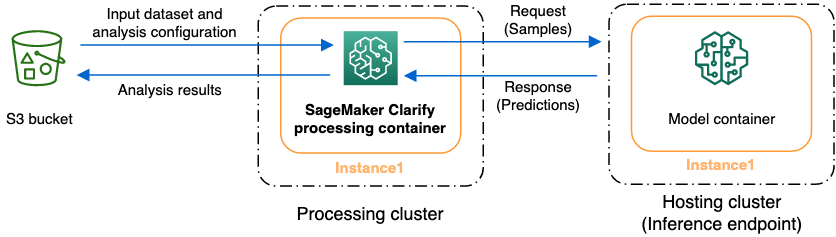
Le graphique suivant montre comment une tâche de traitement SageMaker Clarify interagit avec vos données d'entrée et, éventuellement, avec un modèle client. Cette interaction dépend du type spécifique d'analyse effectué. Le conteneur de traitement SageMaker Clarify obtient le jeu de données en entrée et la configuration pour l'analyse à partir d'un compartiment S3. Pour certains types d'analyse, notamment l'analyse des caractéristiques, le conteneur de traitement SageMaker Clarify doit envoyer des demandes au conteneur du modèle. Il récupère ensuite les prédictions de modèle à partir de la réponse envoyée par le conteneur de modèle. Ensuite, le conteneur de traitement SageMaker Clarify calcule et enregistre les résultats de l'analyse dans le compartiment S3.
Vous pouvez exécuter une tâche de traitement SageMaker Clarify à plusieurs étapes du cycle de vie du flux de travail d'apprentissage automatique. SageMaker Clarify peut vous aider à calculer les types d'analyse suivants :
-
Mesures de biais avant l'entraînement. Ces indicateurs peuvent vous aider à comprendre le biais de vos données afin de pouvoir y remédier et d'entraîner votre modèle sur un ensemble de données plus juste. Consultez Métriques de biais de pré-entraînement pour plus d'informations sur les mesures de biais avant l'entraînement. Pour exécuter une tâche d'analyse des métriques de biais de pré-entraînement, vous devez fournir le jeu de données et un fichier de configuration d'analyse JSON à Fichiers de configuration d'analyse.
-
Mesures de biais après l'entraînement. Ces mesures peuvent vous aider à comprendre tout biais introduit par un algorithme, les choix d'hyperparamètres ou tout biais qui n'était pas apparent plus tôt dans le flux. Pour plus d'informations sur les mesures de biais après l'entraînement, voirDonnées post-entraînement et mesures de biais du modèle. SageMaker Clarify utilise les prédictions du modèle en plus des données et des étiquettes pour identifier les biais. Pour exécuter une tâche d'analyse des métriques de biais de post-entraînement, vous devez fournir le jeu de données et un fichier de configuration d'analyse JSON. La configuration doit inclure le nom du modèle ou du point de terminaison.
-
Des valeurs de Shapley, qui peuvent vous aider à comprendre l'impact de votre fonctionnalité sur les prévisions de votre modèle. Pour plus d'informations sur les valeurs de Shapley, consultez. Attributions de fonctions utilisant des valeurs de Shapley Cette fonctionnalité nécessite un modèle entraîné.
-
Des diagrammes de dépendance partielle (PDPs), qui peuvent vous aider à comprendre dans quelle mesure votre variable cible prévue changerait si vous faisiez varier la valeur d'une caractéristique. Pour plus d'informations PDPs, voir Tracés de dépendance partielle (PDPs) Analyse Cette fonctionnalité nécessite un modèle entraîné.
SageMaker Clarifier les besoins, modéliser les prédictions pour calculer les mesures de biais et les attributions de fonctionnalités après l'entraînement. Vous pouvez fournir un point de terminaison ou SageMaker Clarify créera un point de terminaison éphémère en utilisant le nom de votre modèle, également appelé point de terminaison fantôme. Le conteneur SageMaker Clarify supprime le point de terminaison fantôme une fois les calculs terminés. À un niveau élevé, le conteneur SageMaker Clarify effectue les étapes suivantes :
-
Il valide les entrées et les paramètres.
-
Il crée le point de terminaison miroir (si un nom de modèle est fourni).
-
Il charge le jeu de données en entrée dans un bloc de données.
-
Il obtient des prédictions de modèle à partir du point de terminaison, si nécessaire.
-
Il calcule les métriques de biais et les attributions de fonctionnalités.
-
Il supprime le point de terminaison miroir.
-
Il génère les résultats d'analyse.
Une fois la tâche de traitement SageMaker Clarify terminée, les résultats de l'analyse sont enregistrés à l'emplacement de sortie que vous avez spécifié dans le paramètre de sortie de traitement de la tâche. Ces résultats incluent un fichier JSON contenant les métriques de biais et les attributions de fonctionnalités globales, un rapport visuel et des fichiers supplémentaires pour les attributions de fonctionnalités locales. Vous pouvez télécharger ces résultats depuis l'emplacement de sortie et les consulter.
Pour plus d'informations sur les mesures de biais, l'explicabilité et leur interprétation, consultez Découvrez comment Amazon SageMaker Clarify aide à détecter les biais
Exemples de blocs-notes
Les sections suivantes contiennent des blocs-notes destinés à vous aider à commencer à utiliser SageMaker Clarify, à l'utiliser pour des tâches spéciales, notamment dans le cadre d'une tâche distribuée, et pour la vision par ordinateur.
Premiers pas
Les exemples de blocs-notes suivants montrent comment utiliser SageMaker Clarify pour démarrer avec les tâches d'explicabilité et de biais du modèle. Ces tâches incluent la création d'une tâche de traitement, la formation d'un modèle d'apprentissage automatique (ML) et le suivi des prédictions du modèle :
-
Explicabilité et détection des biais avec Amazon SageMaker Clarify : utilisez Clarify
pour créer une tâche de traitement SageMaker afin de détecter les biais et d'expliquer les prédictions du modèle. -
Surveillance de la dérive des biais et de la dérive d'attribution des fonctionnalités Amazon SageMaker Clarify
— Utilisez Amazon SageMaker Model Monitor pour surveiller la dérive des biais et la dérive de l'attribution des fonctionnalités au fil du temps. -
Comment lire un ensemble de données au format JSON Lines
dans une tâche de traitement SageMaker Clarify -
Atténuez les biais, entraînez un autre modèle impartial et placez-le dans le registre des modèles
: utilisez la technique de suréchantillonnage des minorités synthétiques (SMOTE) et SageMaker clarifiez pour atténuer les biais, entraînez un autre modèle, puis insérez le nouveau modèle dans le registre des modèles. Cet exemple de bloc-notes montre également comment placer les nouveaux artefacts du modèle, notamment les données, le code et les métadonnées du modèle, dans le registre des modèles. Ce carnet fait partie d'une série qui montre comment intégrer SageMaker Clarify dans un pipeline d' SageMaker IA décrit dans l'Architecte et comment créer le cycle de vie complet de l'apprentissage automatique avec un article de AWS blog.
Cas spéciaux
Les carnets suivants vous montrent comment utiliser un SageMaker Clarify dans des cas particuliers, notamment dans votre propre conteneur et pour les tâches de traitement du langage naturel :
-
Équité et explicabilité avec SageMaker Clarify (apportez votre propre conteneur)
— Créez votre propre modèle et conteneur qui peuvent s'intégrer à SageMaker Clarify pour mesurer les biais et générer un rapport d'analyse d'explicabilité. Cet exemple de bloc-notes présente également les termes clés et vous montre comment accéder au rapport via SageMaker Studio Classic. -
Équité et explicabilité avec le traitement distribué SageMaker Clarify Spark
: utilisez le traitement distribué pour exécuter une tâche SageMaker Clarify qui mesure le biais d'un ensemble de données avant l'entraînement et le biais d'un modèle après l'entraînement. Cet exemple de bloc-notes explique également comment obtenir une explication de l'importance des fonctionnalités d'entrée sur la sortie du modèle et comment accéder au rapport d'analyse d'explicabilité via SageMaker Studio Classic. -
Explicabilité avec SageMaker Clarify - Graphiques de dépendance partielle (PDP)
— Utilisez SageMaker Clarify pour générer PDPs et accéder à un rapport d'explicabilité du modèle. -
Explication de l'analyse des sentiments du texte à l'aide SageMaker de l'explicabilité du traitement du langage naturel (NLP)
Clarify — Utilisez SageMaker Clarify pour l'analyse des sentiments du texte. -
Utilisez l'explicabilité de la vision par ordinateur (CV) pour la classification des images et la détection d'
objets .
Il a été vérifié que ces blocs-notes fonctionnent dans Amazon SageMaker Studio Classic. Si vous avez besoin d'instructions pour ouvrir un bloc-notes dans Studio Classic, consultezCréation ou ouverture d'un bloc-notes Amazon SageMaker Studio Classic. Si vous êtes invité à choisir un noyau, choisissez Python 3 (Science des données).
