Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Créer un point de terminaison multimodèle
Vous pouvez utiliser la console SageMaker AI ou le AWS SDK for Python (Boto) pour créer un point de terminaison multimodèle. Pour créer un point de terminaison basé sur un processeur ou un GPU via la console, consultez la procédure de console décrite dans les sections suivantes. Si vous souhaitez créer un point de terminaison multimodèle avec le AWS SDK for Python (Boto), utilisez la procédure CPU ou GPU décrite dans les sections suivantes. Les flux de travail de processeur et de GPU sont similaires mais présentent plusieurs différences, notamment en ce qui concerne les exigences relatives aux conteneurs.
Rubriques
Créer un point de terminaison multi-modèle (console)
Vous pouvez créer des points de terminaison multi-modèles basés sur des processeurs et des GPU via la console. Utilisez la procédure suivante pour créer un point de terminaison multimodèle via la console SageMaker AI.
Pour créer un point de terminaison multimodèle (console)
-
Ouvrez la console Amazon SageMaker AI à l'adresse https://console.aws.amazon.com/sagemaker/
. -
Choisissez Model (Modèle), puis dans le groupe Inference (Inférence) choisissez Create model (Créer un modèle).
-
Dans Model name (Nom du modèle), entrez un nom.
-
Pour IAM role (Rôle IAM), choisissez ou créez un rôle IAM auquel la politique IAM
AmazonSageMakerFullAccessest attachée. -
Dans la section Container definition (Définition de conteneur), pour Provide model artifacts and inference image options (Fournir les options d'artefacts de modèle et d'image d'inférence), choisissez Use multiple models (Utiliser plusieurs modèles).
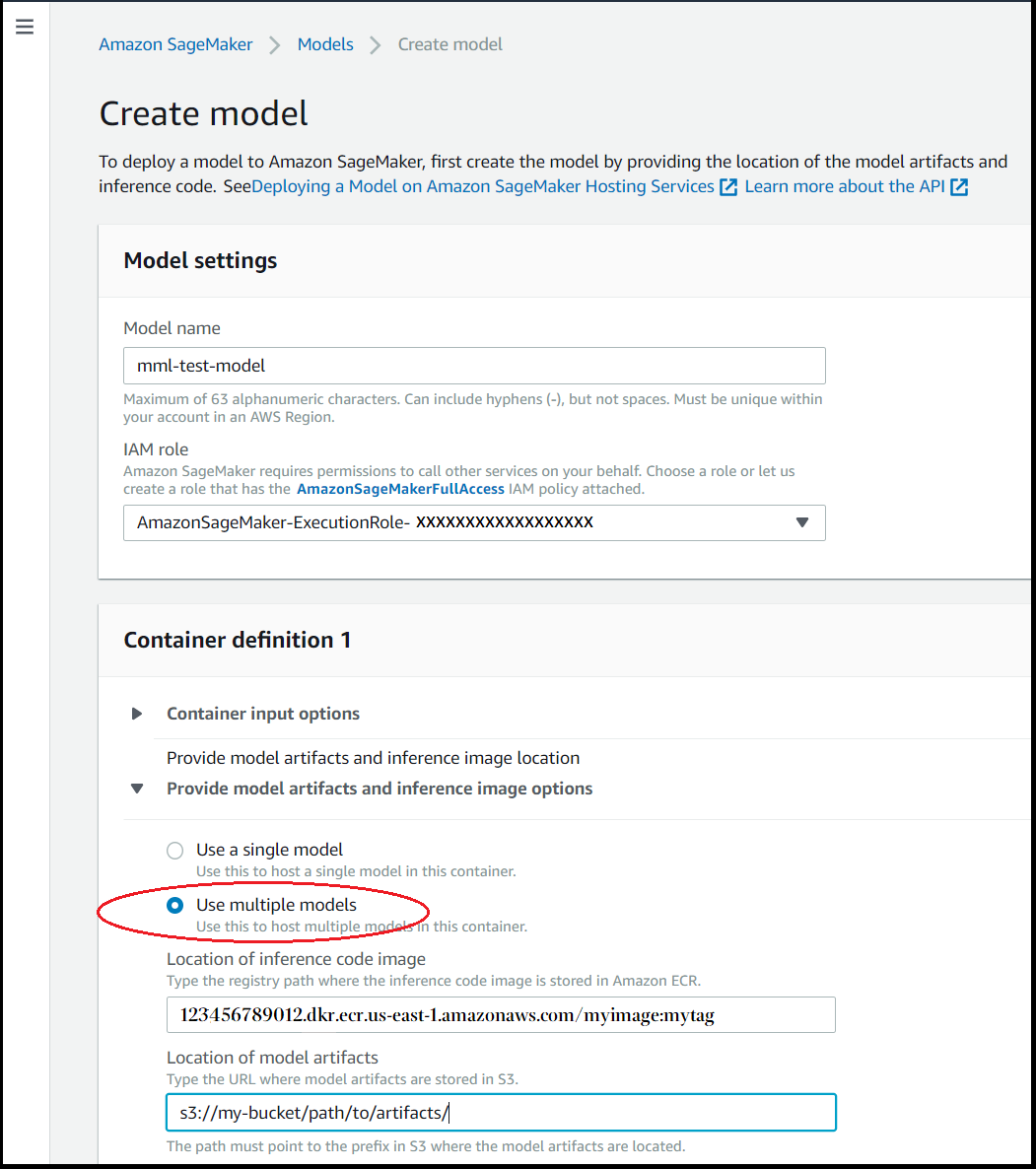
-
Pour Inference container image (Image du conteneur d'inférence), entrez le chemin Amazon ECR de l'image de conteneur souhaitée.
Pour les modèles de GPU, vous devez utiliser un conteneur basé sur le serveur d'inférence NVIDIA Triton. Pour obtenir la liste des images de conteneurs compatibles avec des points de terminaison basés sur des GPU, consultez NVIDIA Triton Inference Containers (SM support only)
(Conteneurs d'inférence NVIDIA Triton (support SM uniquement)). Pour plus d'informations sur le serveur d'inférence NVIDIA Triton, voir Utiliser le serveur d'inférence Triton avec IA. SageMaker -
Sélectionnez Create model.
-
Déployez votre point de terminaison multimodèle comme vous le feriez pour un point de terminaison de modèle unique. Pour obtenir des instructions, consultez Déployer le modèle sur les services d'hébergement SageMaker AI.
Créez un point de terminaison multimodèle à l' CPUs aide du AWS SDK pour Python (Boto3)
Utilisez la section suivante pour créer un point de terminaison multi-modèle basé sur des instances de processeur. Vous créez un point de terminaison multimodèle à l'aide de l' SageMaker intelligence artificielle d'Amazon create_modelcreate_endpoint_configcreate_endpointMode, MultiModel. Vous devez également transmettre le champ ModelDataUrl qui spécifie le préfixe dans Amazon S3 où se trouvent les artefacts de modèle, au lieu du chemin d'accès à un artefact de modèle unique, comme vous le feriez pour le déploiement d'un modèle unique.
Pour un exemple de bloc-notes utilisant l' SageMaker IA pour déployer plusieurs XGBoost modèles sur un point de terminaison, consultez la section XGBoost Exemple de bloc-notes de point de terminaison multimodèle
La procédure suivante décrit les étapes clés utilisées dans cet exemple pour créer un point de terminaison multi-modèle basé sur un processeur.
Pour déployer le modèle (AWS SDK pour Python (Boto 3))
-
Obtenez un conteneur avec une image qui prend en charge le déploiement de points de terminaison multimodèles. Pour obtenir la liste des algorithmes intégrés et des conteneurs de cadre qui prennent en charge les points de terminaison multimodèles, veuillez consulter Algorithmes, frameworks et instances pris en charge pour les points de terminaison multimodèles. Dans cet exemple, nous utilisons l'algorithme intégré Algorithme k-NN (K-Nearest Neighbors, k plus proches voisins). Nous appelons la fonction utilitaire du SDK SageMaker Python
image_uris.retrieve()pour obtenir l'adresse de l'image de l'algorithme intégré K-Nearest Nearest Neighbors.import sagemaker region = sagemaker_session.boto_region_name image = sagemaker.image_uris.retrieve("knn",region=region) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } -
Procurez-vous un client AWS SDK pour Python (Boto3) SageMaker AI et créez le modèle qui utilise ce conteneur.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Facultatif) Si vous utilisez un pipeline d'inférence série, obtenez le ou les conteneurs supplémentaires à inclure dans le pipeline et incluez-le dans l'argument
ContainersdeCreateModel:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )Note
Vous ne pouvez utiliser qu'un seul point de multi-model-enabled terminaison dans un pipeline d'inférence en série.
-
(Facultatif) Si votre cas d'utilisation ne bénéficie pas de la mise en cache des modèles, définissez la valeur du champ
ModelCacheSettingdu paramètreMultiModelConfigsurDisabled, et incluez-la dans l'argumentContainerde l'appel àcreate_model. La valeur du champModelCacheSettingestEnabledpar défaut.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Configurez le point de terminaison multimodèle pour le modèle. Nous vous recommandons de configurer vos points de terminaison avec au moins deux instances. Cela permet à l' SageMaker IA de fournir un ensemble de prédictions hautement disponibles sur plusieurs zones de disponibilité pour les modèles.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.m4.xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] )Note
Vous ne pouvez utiliser qu'un seul point de multi-model-enabled terminaison dans un pipeline d'inférence en série.
-
Créez le point de terminaison multimodèle à l'aide des paramètres
EndpointNameetEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
Créez un point de terminaison multimodèle à l' GPUs aide du AWS SDK pour Python (Boto3)
Utilisez la section suivante pour créer un point de terminaison multi-modèle basé sur des GPU. Vous créez un point de terminaison multimodèle à l'aide de l' SageMaker intelligence artificielle d'Amazon create_modelcreate_endpoint_configcreate_endpointMode, MultiModel. Vous devez également transmettre le champ ModelDataUrl qui spécifie le préfixe dans Amazon S3 où se trouvent les artefacts de modèle, au lieu du chemin d'accès à un artefact de modèle unique, comme vous le feriez pour le déploiement d'un modèle unique. Pour les points de terminaison multi-modèles basés sur des GPU, vous devez également utiliser un conteneur avec le serveur d'inférence NVIDIA Triton optimisé pour fonctionner sur des instances de GPU. Pour obtenir la liste des images de conteneurs compatibles avec des points de terminaison basés sur des GPU, consultez NVIDIA Triton Inference Containers (SM support only)
Pour un exemple de bloc-notes expliquant comment créer un point de terminaison multimodèle soutenu par GPUs, voir Exécuter plusieurs modèles d'apprentissage profond avec des points de terminaison multimodèles (MME) GPUs Amazon SageMaker AI
La procédure suivante décrit les étapes clés pour créer un point de terminaison multi-modèle basé sur un GPU.
Pour déployer le modèle (AWS SDK pour Python (Boto 3))
-
Définissez l'image de conteneur. Pour créer un point de terminaison multimodèle prenant en charge les ResNet modèles par GPU, définissez le conteneur qui utilisera l'image du serveur NVIDIA Triton. Ce conteneur prend en charge les points de terminaison multi-modèles et est optimisé pour s'exécuter sur des instances de GPU. Nous appelons la fonction utilitaire SageMaker AI Python SDK
image_uris.retrieve()pour obtenir l'adresse de l'image. Par exemple :import sagemaker region = sagemaker_session.boto_region_name // Find the sagemaker-tritonserver image at // https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-triton/resnet50/triton_resnet50.ipynb // Find available tags at https://github.com/aws/deep-learning-containers/blob/master/available_images.md#nvidia-triton-inference-containers-sm-support-only image = "<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/sagemaker-tritonserver:<TAG>".format( account_id=account_id_map[region], region=region ) container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel', "Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "resnet"}, } -
Procurez-vous un client AWS SDK pour Python (Boto3) SageMaker AI et créez le modèle qui utilise ce conteneur.
import boto3 sagemaker_client = boto3.client('sagemaker') response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container]) -
(Facultatif) Si vous utilisez un pipeline d'inférence série, obtenez le ou les conteneurs supplémentaires à inclure dans le pipeline et incluez-le dans l'argument
ContainersdeCreateModel:preprocessor_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<PREPROCESSOR_IMAGE>:<TAG>' } multi_model_container = { 'Image': '<ACCOUNT_ID>.dkr.ecr.<REGION_NAME>.amazonaws.com/<IMAGE>:<TAG>', 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [preprocessor_container, multi_model_container] )Note
Vous ne pouvez utiliser qu'un seul point de multi-model-enabled terminaison dans un pipeline d'inférence en série.
-
(Facultatif) Si votre cas d'utilisation ne bénéficie pas de la mise en cache des modèles, définissez la valeur du champ
ModelCacheSettingdu paramètreMultiModelConfigsurDisabled, et incluez-la dans l'argumentContainerde l'appel àcreate_model. La valeur du champModelCacheSettingestEnabledpar défaut.container = { 'Image': image, 'ModelDataUrl': 's3://<BUCKET_NAME>/<PATH_TO_ARTIFACTS>', 'Mode': 'MultiModel' 'MultiModelConfig': { // Default value is 'Enabled' 'ModelCacheSetting': 'Disabled' } } response = sagemaker_client.create_model( ModelName ='<MODEL_NAME>', ExecutionRoleArn = role, Containers = [container] ) -
Configurez le point de terminaison multi-modèle avec des instances basées sur des GPU pour le modèle. Nous vous recommandons de configurer vos points de terminaison avec plusieurs instances afin de garantir une haute disponibilité et un plus grand nombre d'accès au cache.
response = sagemaker_client.create_endpoint_config( EndpointConfigName ='<ENDPOINT_CONFIG_NAME>', ProductionVariants=[ { 'InstanceType': 'ml.g4dn.4xlarge', 'InitialInstanceCount': 2, 'InitialVariantWeight': 1, 'ModelName':'<MODEL_NAME>', 'VariantName': 'AllTraffic' } ] ) -
Créez le point de terminaison multimodèle à l'aide des paramètres
EndpointNameetEndpointConfigName.response = sagemaker_client.create_endpoint( EndpointName ='<ENDPOINT_NAME>', EndpointConfigName ='<ENDPOINT_CONFIG_NAME>')
