Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Points de terminaison multi-modèles
Les points de terminaison multimodèles offrent une solution évolutive et économique pour le déploiement d'un grand nombre de modèles. Ils utilisent la même flotte de ressources et un conteneur de service partagé pour héberger tous vos modèles. Cela réduit les coûts d'hébergement en améliorant l'utilisation des points de terminaison par rapport à l'utilisation des points de terminaison à modèle unique. Cela réduit également les frais de déploiement, car Amazon SageMaker AI gère le chargement des modèles en mémoire et leur dimensionnement en fonction des modèles de trafic vers votre point de terminaison.
Le diagramme suivant montre comment les points de terminaison multi-modèles fonctionnent par rapport aux points de terminaison à modèle unique.
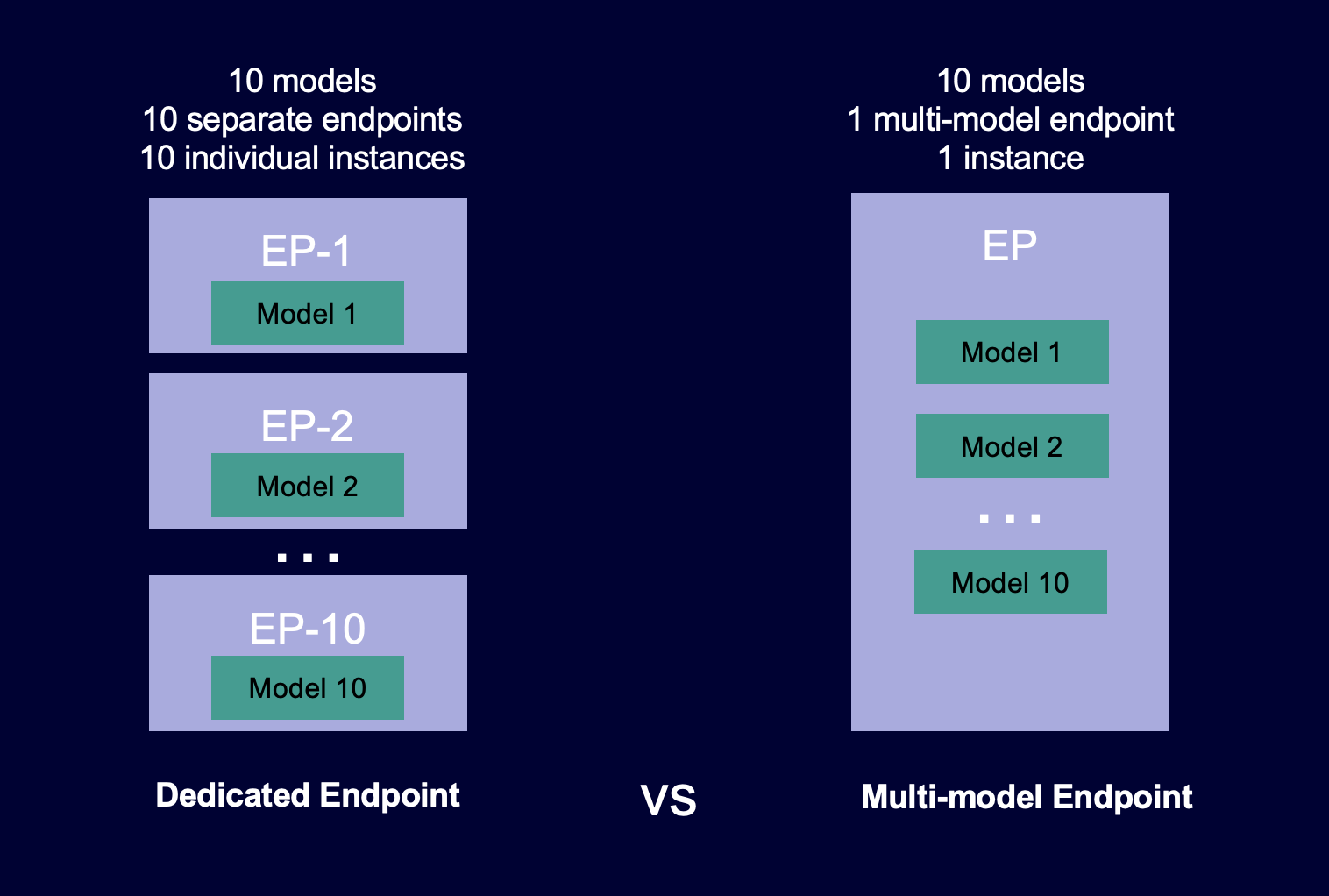
Les points de terminaison multi-modèles sont idéaux pour héberger un grand nombre de modèles utilisant le même cadre de ML sur un conteneur de service partagé. Si vous disposez d'une combinaison de modèles fréquemment et peu utilisés, un point de terminaison multi-modèle peut traiter efficacement ce trafic avec moins de ressources et des économies de coûts plus importantes. Votre application doit être tolérante aux pénalités de latence occasionnelles liées au démarrage à froid qui se produisent lors de l'appel de modèles peu utilisés.
Les points de terminaison multi-modèles permettent d'héberger à la fois des modèles basés sur des processeurs et des GPU. En utilisant des modèles basés sur des GPU, vous pouvez réduire les coûts de déploiement de vos modèles grâce à une utilisation accrue du point de terminaison et de ses instances de calcul accéléré sous-jacentes.
Les points de terminaison multimodèles permettent également le partage du temps des ressources de mémoire sur l'ensemble de vos modèles. Cela fonctionne mieux lorsque les modèles sont assez similaires en taille et en latence d'invocation. Dans ce cas, les points de terminaison multimodèles peuvent utiliser efficacement des instances sur tous les modèles. Si vous avez des modèles qui ont des exigences de transactions par seconde (TPS) significativement plus élevées ou de latence, nous vous recommandons de les héberger sur des points de terminaison dédiés.
Vous pouvez utiliser des points de terminaison multi-modèles dotés des fonctions suivantes :
-
AWS PrivateLinket VPCs
-
Auto scaling (Mise à l'échelle automatique)
-
Serial inference pipelines (Pipelines d'inférence série) (mais un seul conteneur multi-modèle peut être inclus dans un pipeline d'inférence)
-
Test A/B
Vous pouvez utiliser la console AWS SDK for Python (Boto) ou l' SageMaker IA pour créer un point de terminaison multimodèle. Pour les points de terminaison multi-modèles basés sur des processeurs, vous pouvez créer votre point de terminaison multi-modèle avec des conteneurs personnalisés en intégrant la bibliothèque Multi Model Server
Rubriques
Exemples de blocs-notes pour les points de terminaison multi-modèles
Algorithmes, frameworks et instances pris en charge pour les points de terminaison multimodèles
Recommandations d'instance pour les déploiements de points de terminaison multi-modèles
Créez votre propre conteneur pour les points de terminaison multimodèles basés sur l' SageMaker IA
CloudWatch Métriques pour les déploiements de terminaux multimodèles
Définition de politiques Auto Scaling pour les déploiements de points de terminaison multi-modèles
Fonctionnement des points de terminaison multimodèles
SageMaker L'IA gère le cycle de vie des modèles hébergés sur des points de terminaison multimodèles dans la mémoire du conteneur. Au lieu de télécharger tous les modèles d'un compartiment Amazon S3 vers le conteneur lorsque vous créez le point de terminaison, l' SageMaker IA les charge et les met en cache de manière dynamique lorsque vous les invoquez. Lorsque SageMaker l'IA reçoit une demande d'invocation pour un modèle particulier, elle effectue les opérations suivantes :
-
Route la demande vers une instance située derrière le point de terminaison.
-
Télécharge le modèle du compartiment S3 vers le volume de stockage de cette instance.
-
Charge le modèle dans la mémoire du conteneur (processeur ou GPU, selon que vous disposez d'instances basées sur des processeurs ou des GPU) sur cette instance de calcul accéléré. Si le modèle est déjà chargé dans la mémoire du conteneur, l'invocation est plus rapide car l' SageMaker IA n'a pas besoin de le télécharger ni de le charger.
SageMaker L'IA continue d'acheminer les demandes de modèle vers l'instance où le modèle est déjà chargé. Toutefois, si le modèle reçoit de nombreuses demandes d'invocation et qu'il existe des instances supplémentaires pour le point de terminaison multimodèle, l' SageMaker IA achemine certaines demandes vers une autre instance pour répondre au trafic. Si le modèle n'est pas déjà chargé sur la deuxième instance, il est téléchargé sur le volume de stockage de cette instance et chargé dans la mémoire du conteneur.
Lorsque l'utilisation de la mémoire d'une instance est élevée et que l' SageMaker IA doit charger un autre modèle en mémoire, elle décharge les modèles inutilisés du conteneur de cette instance afin de s'assurer qu'il y a suffisamment de mémoire pour charger le modèle. Les modèles qui sont déchargés restent sur le volume de stockage de l'instance et peuvent être chargés dans la mémoire du conteneur ultérieurement sans être téléchargés à nouveau depuis le compartiment S3. Si le volume de stockage de l'instance atteint sa capacité maximale, SageMaker AI supprime tous les modèles inutilisés du volume de stockage.
Pour supprimer un modèle, arrêtez d'envoyer des demandes et supprimez-le du compartiment S3. SageMaker L'IA fournit une fonctionnalité de point de terminaison multimodèle dans un conteneur de service. L'ajout de modèles à un point de terminaison multimodèle et leur suppression ne nécessitent pas la mise à jour du point de terminaison lui-même. Pour ajouter un modèle, vous le chargez dans le compartiment S3 et vous l'appelez. Vous n'avez pas besoin de modifier le code pour l'utiliser.
Note
Lorsque vous mettez à jour un point de terminaison multi-modèle, les demandes d'appel initiales sur le point de terminaison peuvent présenter des latences plus élevées, car le routage intelligent des points de terminaison multi-modèles s'adapte à votre modèle de trafic. Cependant, une fois qu'il connaît votre modèle de trafic, vous pouvez constater de faibles latences pour les modèles les plus fréquemment utilisés. Les modèles moins fréquemment utilisés peuvent présenter des latences de démarrage à froid, car les modèles sont chargés dynamiquement dans une instance.
Exemples de blocs-notes pour les points de terminaison multi-modèles
Pour en savoir plus sur l'utilisation des points de terminaison multi-modèles, vous pouvez essayer les exemples de bloc-notes suivants :
-
Exemples de points de terminaison multi-modèles utilisant des instances basées sur des processeurs :
-
XGBoost Exemple de bloc-notes de point de terminaison multimodèle
: ce bloc-notes explique comment déployer plusieurs XGBoost modèles sur un point de terminaison. -
Exemple de bloc-notes BYOC pour terminaux multimodèles — Ce bloc-notes
explique comment configurer et déployer un conteneur client qui prend en charge les points de terminaison multimodèles dans l'IA. SageMaker
-
-
Exemple de points de terminaison multi-modèles utilisant des instances basées sur des GPU :
-
Exécutez plusieurs modèles de deep learning GPUs avec Amazon SageMaker AI Multi-model endpoints (MME)
— Ce bloc-notes explique comment utiliser un conteneur NVIDIA Triton Inference pour déployer ResNet -50 modèles sur un point de terminaison multimodèle.
-
Pour savoir comment créer et accéder à des instances de bloc-notes Jupyter que vous pouvez utiliser pour exécuter les exemples précédents dans SageMaker AI, consultez. Instances de SageMaker blocs-notes Amazon Après avoir créé une instance de bloc-notes et l'avoir ouverte, choisissez l'onglet Exemples d'SageMaker IA pour voir la liste de tous les exemples d' SageMaker IA. Le bloc-notes de points de terminaison multi-modèles se trouve dans la section ADVANCED FUNCTIONALITY (FONCTIONNALITÉS AVANCÉES). Pour ouvrir un bloc-notes, choisissez son onglet Use (Utiliser), puis Create copy (Créer une copie).
Pour plus d'informations sur des cas d'utilisation des points de terminaison multi-modèles, consultez les blogs et ressources suivants :
-
Vidéo : Hébergement de milliers de modèles grâce à l' SageMaker IA
-
Vidéo : SageMaker AI ML pour le SaaS
-
Blog : How to scale machine learning inference for multi-tenant SaaS use cases
(Comment mettre à l'échelle l'inférence de machine learning pour les cas d'utilisation SaaS à locataires multiples) -
Étude de cas : Veeva Systems
(Systèmes Veeva)
