Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Obtenir des informations sur les données et la qualité des données
Utilisez le Data Quality and Insights Report (Rapport d'informations et de qualité des données) pour effectuer une analyse des données que vous avez importées dans Data Wrangler. Nous vous recommandons de créer le rapport après avoir importé votre jeu de données. Vous pouvez utiliser le rapport pour vous aider à nettoyer et à traiter vos données. Il fournit des informations telles que le nombre de valeurs manquantes et le nombre de valeurs aberrantes. Si vous rencontrez des problèmes avec vos données, tels que des fuites ou des déséquilibres de cible, le rapport d'informations peut signaler ces problèmes.
Utilisez la procédure suivante pour créer un rapport d'informations et de qualité des données. Cela suppose que vous avez déjà importé un jeu de données dans votre flux Data Wrangler.
Pour créer un rapport d'informations et de qualité des données
-
Choisissez + à côté d'un nœud dans votre flux Data Wrangler.
-
Sélectionnez Obtenir des informations sur les données.
-
Dans le champ Nom de l'analyse, spécifiez le nom du rapport d'informations.
-
(Facultatif) Pour Colonne cible, spécifiez la colonne cible.
-
Pour Type de problème, spécifiez Régression ou Classification.
-
Pour Taille des données, spécifiez l'une des valeurs suivantes :
-
50 000 : utilise les 50 000 premières lignes du jeu de données que vous avez importé pour créer le rapport.
-
Jeu de données complet : utilise le jeu de données que vous avez importé pour créer le rapport.
Note
La création d'un rapport sur la qualité des données et les informations sur l'ensemble de données utilise une tâche SageMaker de traitement Amazon. Une tâche de SageMaker traitement fournit les ressources informatiques supplémentaires nécessaires pour obtenir des informations sur toutes vos données. Pour plus d'informations sur les tâches de SageMaker traitement, consultezCharges de travail de transformation des données avec Processing SageMaker .
-
-
Choisissez Créer.
Les rubriques suivantes présentent les sections du rapport :
Vous pouvez télécharger le rapport ou le consulter en ligne. Pour télécharger le rapport, cliquez sur le bouton de téléchargement situé dans l'angle supérieur droit de l'écran. L'image suivante illustre le bouton.

Récapitulatif
Le rapport d'informations comporte un bref résumé des données qui inclut des informations générales telles que les valeurs manquantes, les valeurs non valides, les types de fonctions, le nombre de valeurs aberrantes, etc. Il peut également inclure des avertissements de sévérité élevée qui indiquent des problèmes probables avec les données. Nous vous recommandons d'examiner les avertissements.
Voici un exemple de récapitulatif de rapport.

Colonne cible
Lorsque vous créez le rapport d'informations et de qualité des données, Data Wrangler vous permet de sélectionner une colonne cible. Une colonne cible est une colonne que vous essayez de prédire. Lorsque vous choisissez une colonne cible, Data Wrangler crée automatiquement une analyse de colonne cible. Il classe également les fonctions par ordre de pouvoir prédictif. Lorsque vous sélectionnez une colonne cible, vous devez spécifier si vous tentez de résoudre un problème de régression ou de classification.
Pour la classification, Data Wrangler affiche une table et un histogramme des classes les plus courantes. Une classe est une catégorie. Il présente également des observations, ou des lignes, dont la valeur cible est manquante ou non valide.
L'image suivante illustre un exemple d'analyse de colonne cible pour un problème de classification.

Pour la régression, Data Wrangler affiche un histogramme de toutes les valeurs de la colonne cible. Il présente également des observations, ou des lignes, dont la valeur cible est manquante, non valide ou aberrante.
L'image suivante illustre un exemple d'analyse de colonne cible pour un problème de régression.

Modèle rapide
Le Quick model (modèle rapide) fournit une estimation de la qualité prédite attendue d'un modèle que vous entraînez sur vos données.
Data Wrangler fractionne vos données en blocs d'entraînement et de validation. Il utilise 80 % des échantillons pour l'entraînement et 20 % des valeurs pour la validation. Pour la classification, l'échantillon est un fractionnement stratifié. Pour un fractionnement stratifié, chaque partition de données a le même rapport d'étiquettes. Pour les problèmes de classification, il est important d'avoir le même rapport d'étiquettes entre les blocs d'entraînement et de classification. Data Wrangler entraîne le XGBoost modèle avec les hyperparamètres par défaut. Il applique un arrêt anticipé sur les données de validation et effectue un prétraitement minimal des caractéristiques.
Pour les modèles de classification, Data Wrangler renvoie à la fois un récapitulatif du modèle et une matrice de confusion.
Voici un exemple de récapitulatif de modèle de classification. Pour en savoir plus sur les informations renvoyées, consultez Définitions.

Voici un exemple de matrice de confusion renvoyée par le modèle rapide.

Une matrice de confusion fournit les informations suivantes :
-
Nombre de fois où l'étiquette prédite correspond à la vraie étiquette.
-
Nombre de fois où l'étiquette prédite ne correspondait pas à la vraie étiquette.
La vraie étiquette représente une observation réelle dans vos données. Par exemple, si vous utilisez un modèle pour détecter les transactions frauduleuses, la vraie étiquette représente une transaction réellement frauduleuse ou non frauduleuse. L'étiquette prédite représente l'étiquette que votre modèle attribue aux données.
Vous pouvez utiliser la matrice de confusion pour voir dans quelle mesure le modèle prédit la présence ou l'absence d'une condition. Si vous prédisez des transactions frauduleuses, vous pouvez utiliser la matrice de confusion pour vous faire une idée de la sensibilité et de la spécificité du modèle. La sensibilité fait référence à la capacité du modèle à détecter les transactions frauduleuses. La spécificité fait référence à la capacité du modèle à éviter de détecter les transactions non frauduleuses comme étant frauduleuses.
Voici un exemple de résultats du modèle rapide pour un problème de régression.

Récapitulatif des fonctions
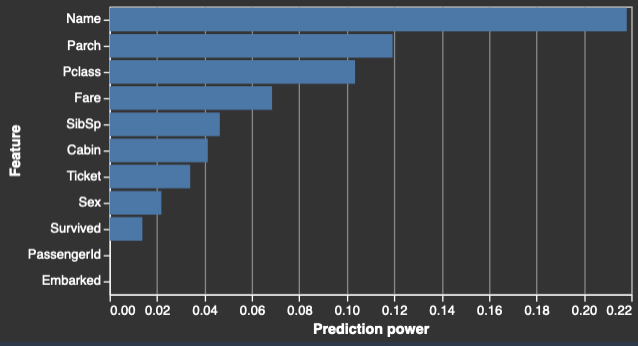
Lorsque vous spécifiez une colonne cible, Data Wrangler classe les fonctions selon leur pouvoir de prédiction. Le pouvoir de prédiction est mesuré sur les données après leur division en bloc d'entraînement de 80 % et en bloc de validation de 20 %. Data Wrangler adapte un modèle à chaque fonction séparément sur le bloc d'entraînement. Il applique un prétraitement minimal des caractéristiques et mesure les performances de prédiction sur les données de validation.
Il normalise les scores dans la plage [0,1]. Les scores de prédiction élevés indiquent des colonnes plus utiles pour prédire la cible par elles-mêmes. Les scores inférieurs indiquent des colonnes qui ne sont pas prédictives de la colonne cible.
Il est rare qu'une colonne qui n'est pas prédictive en elle-même soit prédictive lorsqu'elle est utilisée conjointement avec d'autres colonnes. Vous pouvez utiliser les scores de prédiction en toute confiance pour déterminer si une fonction de votre jeu de données est prédictive.
Un score faible indique généralement que la fonction est redondante. Un score de 1 correspond à des capacités prédictives parfaites, ce qui indique souvent une fuite de cible. La fuite de cible se produit généralement lorsque le jeu de données contient une colonne qui n'est pas disponible au moment de la prédiction. Par exemple, il peut s'agir d'un double de la colonne cible.
Voici des exemples de la table et de l'histogramme qui montrent la valeur de prédiction de chaque caractéristique.

Exemples
Data Wrangler indique si vos échantillons sont anormaux ou si votre jeu de données contient des doublons.
Data Wrangler détecte les échantillons anormaux à l'aide de l'algorithme Isolation Forest (forêt d'isolation). La forêt d'isolation associe un score d'anomalie à chaque échantillon (ligne) du jeu de données. Les scores d'anomalie faibles indiquent des échantillons anormaux. Les scores élevés sont associés à des échantillons non anormaux. Les échantillons présentant un score d'anomalie négatif sont généralement considérés comme anormaux et les échantillons présentant un score d'anomalie positif sont considérés comme non anormaux.
Lorsque vous examinez un échantillon susceptible d'être anormal, nous vous recommandons de prêter attention aux valeurs inhabituelles. Par exemple, des valeurs anormales peuvent être issues d'erreurs qui se sont produites lors de la collecte et du traitement des données. Nous vous recommandons d'utiliser la connaissance du domaine et la logique métier lorsque vous examinez des échantillons anormaux.
Data Wrangler détecte les lignes en double et calcule le rapport des doublons dans vos données. Certaines sources de données peuvent inclure des doublons valides. D'autres sources de données peuvent comporter des doublons indiquant des problèmes liés à la collecte de données. Les échantillons en double issus d'une collecte de données défectueuse peuvent interférer avec les processus de machine learning qui reposent sur le fractionnement des données en blocs d'entraînement et de validation indépendants.
Les éléments suivants sont issus du rapport d'informations et peuvent être affectés par les échantillons en double :
-
Modèle rapide
-
Estimation du pouvoir de prédiction
-
Réglage automatique des hyperparamètres
Vous pouvez retirer des échantillons en double du jeu de données à l'aide de la transformation Drop duplicates (Supprimer des doublons) sous Manage rows (Gérer les lignes). Data Wrangler affiche les lignes les plus fréquemment dupliquées.
Définitions
Les définitions suivantes s'appliquent à des termes techniques utilisés dans le rapport d'informations des données.
