Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Charges de travail de transformation des données avec Processing SageMaker
SageMaker Le traitement fait référence aux capacités de l' SageMaker IA à exécuter des tâches de pré-traitement et de post-traitement des données, d'ingénierie des fonctionnalités et d'évaluation de modèles sur l'infrastructure entièrement gérée de l' SageMaker IA. Ces tâches sont exécutées en tant que tâches de traitement. Vous trouverez ci-dessous des informations et des ressources pour en savoir plus sur SageMaker le traitement.
Grâce à l'API de SageMaker traitement, les scientifiques des données peuvent exécuter des scripts et des blocs-notes pour traiter, transformer et analyser des ensembles de données afin de les préparer à l'apprentissage automatique. Combiné aux autres tâches critiques d'apprentissage automatique fournies par l' SageMaker IA, telles que la formation et l'hébergement, Processing vous offre les avantages d'un environnement d'apprentissage automatique entièrement géré, y compris tout le support de sécurité et de conformité intégré à l' SageMaker IA. Vous avez la possibilité d'utiliser les conteneurs de traitement de données intégrés ou d'apporter vos propres conteneurs pour une logique de traitement personnalisée, puis de soumettre des tâches à exécuter sur une infrastructure gérée par l' SageMaker IA.
Note
Vous pouvez créer une tâche de traitement par programmation en appelant l'action CreateProcessingJobAPI dans n'importe quel langage pris en charge par l' SageMaker IA ou en utilisant le. AWS CLI Pour plus d'informations sur la façon dont cette action d'API se traduit par une fonction dans la langue de votre choix, consultez la section Voir aussi de CreateProcessingJob et choisissez un SDK. À titre d'exemple, pour les utilisateurs de Python, reportez-vous à la section Amazon SageMaker Processing
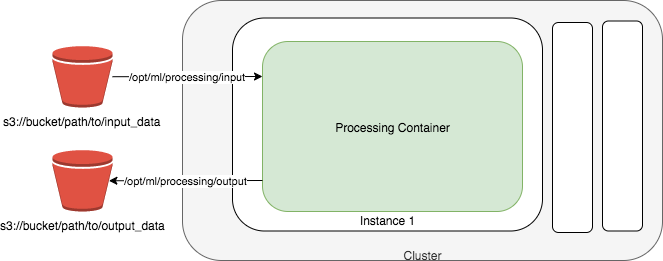
Le schéma suivant montre comment Amazon SageMaker AI lance une tâche de traitement. Amazon SageMaker AI prend votre script, copie vos données depuis Amazon Simple Storage Service (Amazon S3), puis extrait un conteneur de traitement. L'infrastructure sous-jacente d'une tâche de traitement est entièrement gérée par Amazon SageMaker AI. Une fois que vous avez soumis une tâche de traitement, l' SageMaker IA lance les instances de calcul, traite et analyse les données d'entrée, puis libère les ressources une fois celles-ci terminées. La sortie de la tâche de traitement est stockée dans le compartiment Amazon S3 que vous avez spécifié.
Note
Vos données d'entrée doivent être stockées dans un compartiment Amazon S3. Vous pouvez également utiliser Amazon Athena ou Amazon Redshift comme sources d'entrée.
Astuce
Pour découvrir les bonnes pratiques en matière de calcul distribué pour l'entraînement au machine learning (ML) et les tâches de traitement en général, consultez Meilleures pratiques en matière d'informatique distribuée et d' SageMaker intelligence artificielle.
Utiliser Amazon SageMaker Processing Sample Notebooks
Nous fournissons deux exemples de blocs-notes Jupyter qui montrent comment effectuer le prétraitement des données, l'évaluation des modèles ou les deux.
Pour un exemple de bloc-notes expliquant comment exécuter des scripts scikit-learn pour effectuer le prétraitement des données ainsi que l'apprentissage et l'évaluation de modèles avec le SDK SageMaker Python pour le traitement, consultez scikit-learn Processing.
Pour un exemple de bloc-notes expliquant comment utiliser Amazon SageMaker Processing pour effectuer un prétraitement distribué des données avec Spark, consultez la section Traitement distribué (Spark)
Pour savoir comment créer et accéder à des instances de bloc-notes Jupyter que vous pouvez utiliser pour exécuter ces exemples dans SageMaker AI, consultez. Instances de SageMaker blocs-notes Amazon Après avoir créé une instance de bloc-notes et l'avoir ouverte, choisissez l'onglet Exemples d'SageMaker IA pour voir la liste de tous les exemples d' SageMaker IA. Pour ouvrir un bloc-notes, choisissez son onglet Use (Utiliser), puis Create copy (Créer une copie).
Surveillez les tâches SageMaker de traitement d'Amazon à l'aide de CloudWatch journaux et de statistiques
Amazon SageMaker Processing fournit des CloudWatch journaux et des statistiques Amazon pour surveiller les tâches de traitement. CloudWatch fournit des mesures relatives au processeur, au processeur graphique, à la mémoire, à la mémoire graphique et au disque, ainsi qu'à la journalisation des événements. Pour plus d’informations, consultez Métriques Amazon SageMaker AI sur Amazon CloudWatch et CloudWatch Journaux pour Amazon SageMaker AI.
