Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Parallélisme des données partitionnées
Le parallélisme de données partitionné est une technique d'entraînement distribuée économisant de la mémoire qui divise l'état d'un modèle (paramètres du modèle, gradients et états de l'optimiseur) au sein d'un groupe de données parallèles. GPUs
Note
Le parallélisme des données partitionnées est disponible PyTorch dans la bibliothèque de parallélisme des SageMaker modèles v1.11.0 et versions ultérieures.
Lorsque vous étendez votre tâche d'entraînement à un grand cluster de processeurs graphiques, vous pouvez réduire l'empreinte mémoire par GPU du modèle en répartissant l'état d'entraînement du modèle sur plusieurs. GPUs Cela présente deux avantages : vous pouvez adapter des modèles plus grands, qui risqueraient sinon de manquer de mémoire avec un parallélisme des données standard, ou vous pouvez augmenter la taille du lot en utilisant la mémoire GPU libérée.
La technique standard de parallélisme des données reproduit les états d'apprentissage dans le groupe GPUs in the data parallel et effectue une agrégation de gradient en fonction de l'opération. AllReduce Le parallélisme des données partitionnées modifie la procédure d'entraînement distribué à données parallèles standard pour tenir compte de la nature partitionnée des états de l'optimiseur. Un groupe de rangs sur lequel les états du modèle et de l'optimiseur sont partitionnés est appelé groupe de partitionnement. La technique de parallélisme des données fragmentées partage les paramètres pouvant être entraînés d'un modèle ainsi que les dégradés correspondants et les états de l'optimiseur dans le groupe de partitionnement. GPUs
SageMaker L'IA parvient à un parallélisme des données fragmenté grâce à la mise en œuvre de MIC, dont il est question dans le billet de AWS blog Near linear scaling of gigantic-model trainingAllGatheropération. Après la transmission vers l'avant ou l'arrière de chaque couche, la méthode MiCS partitionne à nouveau les paramètres pour économiser de la mémoire GPU. Pendant le passage en arrière, les MICS réduisent les dégradés et les répartissent simultanément tout au long GPUs de l'opération. ReduceScatter Enfin, la méthode MiCS applique les gradients partitionnés et réduits locaux à leurs partitions de paramètres locales correspondantes, en utilisant les partitions locales des états de l'optimiseur. Pour réduire la surcharge de communication, la bibliothèque de parallélisme du SageMaker modèle préextrait les couches à venir lors de la passe avant ou arrière, et superpose les communications réseau aux calculs.
L'état d'entraînement du modèle est répliqué dans l'ensemble des groupes de partitionnement. Cela signifie qu'avant d'appliquer les gradients aux paramètres, l'opération AllReduce doit avoir lieu dans tous les groupes de partitionnement, en plus de l'opération ReduceScatter qui a lieu au sein du groupe de partitionnement.
En effet, le parallélisme des données partitionnées introduit un compromis entre la surcharge de communication et l'efficacité de la mémoire GPU. L'utilisation du parallélisme des données partitionnées augmente les coûts de communication, mais l'empreinte mémoire par GPU (à l'exclusion de l'utilisation de la mémoire due aux activations) est divisée par le degré de parallélisme des données partitionnées, ce qui permet d'intégrer des modèles plus grands dans le cluster de GPU.
Sélection du degré de parallélisme de données partitionnées
Lorsque vous sélectionnez une valeur pour le degré de parallélisme de données partitionnées, cette valeur doit diviser le degré de parallélisme de données de manière égale. Par exemple, pour une tâche de parallélisme des données à 8 voies, choisissez 2, 4 ou 8 comme degré de parallélisme des données partitionnées. Lorsque vous choisissez le degré de parallélisme des données partitionnées, nous vous recommandons de commencer par un petit nombre, puis de l'augmenter progressivement jusqu'à ce que le modèle tienne dans la mémoire avec la taille de lot souhaitée.
Sélection de la taille du lot
Après avoir configuré le parallélisme de données partitionnées, assurez-vous de trouver la configuration d'entraînement la plus optimale pouvant s'exécuter avec succès sur le cluster de GPU. Pour la formation de grands modèles linguistiques (LLM), commencez par la taille du lot 1, puis augmentez-la progressivement jusqu'à ce que vous atteigniez le point de réception de l'erreur out-of-memory (OOM). Si vous rencontrez l'erreur OOM même avec la plus petite taille de lot, appliquez un degré plus élevé de parallélisme de données partitionnées ou une combinaison de parallélisme de données partitionnées et de parallélisme de tenseurs.
Rubriques
Comment appliquer le parallélisme de données partitionnées à votre tâche d'entraînement
Parallélisme des données partitionnées avec les collectifs SMDDP
Entraînement à précision mixte avec parallélisme de données partitionnées
Parallélisme de données partitionnées avec parallélisme de tenseurs
Conseils et considérations concernant l'utilisation du parallélisme de données partitionnées
Comment appliquer le parallélisme de données partitionnées à votre tâche d'entraînement
Pour commencer à utiliser le parallélisme des données partitionnées, appliquez les modifications requises à votre script d'apprentissage et configurez l' SageMaker PyTorch estimateur avec les paramètres. sharded-data-parallelism-specific Pensez également à prendre des valeurs de référence et des exemples de blocs-notes comme point de départ.
Adaptez votre script PyTorch d'entraînement
Suivez les instructions de l'étape 1 : Modifiez un script d' PyTorch entraînement pour encapsuler les objets du modèle et de l'optimiseur avec les smdistributed.modelparallel.torch enveloppes des modules torch.nn.parallel ettorch.distributed.
(Facultatif) Modification supplémentaire pour enregistrer les paramètres externes du modèle
Si votre modèle est construit avec torch.nn.Module et qu'il utilise des paramètres qui ne sont pas définis dans la classe de module, vous devez les enregistrer manuellement dans le module pour que SMP collecte les paramètres complets pendant ce temps. Pour enregistrer les paramètres d'un module, utilisez smp.register_parameter(module,
parameter).
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
Configuration de l' SageMaker PyTorch estimateur
Lorsque vous configurez un SageMaker PyTorch estimateur dansÉtape 2 : Lancer un job de formation à l'aide du SDK SageMaker Python, ajoutez les paramètres du parallélisme des données fragmentées.
Pour activer le parallélisme des données partitionnées, ajoutez le sharded_data_parallel_degree paramètre à l'estimateur. SageMaker PyTorch Ce paramètre indique le nombre de points GPUs sur lesquels l'état d'apprentissage est fragmenté. La valeur pour sharded_data_parallel_degree doit être un entier compris entre 1 et le degré de parallélisme des données, et elle doit diviser de manière égale le degré de parallélisme des données. Notez que la bibliothèque détecte automatiquement le nombre de GPUs donc le degré de parallélisme des données. Les paramètres supplémentaires suivants sont disponibles pour configurer le parallélisme des données partitionnées.
-
"sdp_reduce_bucket_size"(int, default : 5e8) — Spécifie la taille des compartiments de dégradé PyTorch DDPen nombre d'éléments du dtype par défaut. -
"sdp_param_persistence_threshold"(entier, par défaut : 1e6) : spécifie la taille d'un tenseur de paramètres en nombre d'éléments qui peuvent persister sur chaque GPU. Le parallélisme de données fractionné divise chaque tenseur de paramètres au sein d' GPUs un groupe de données parallèles. Si le nombre d'éléments dans le tenseur de paramètres est inférieur à ce seuil, le tenseur de paramètres n'est pas divisé ; cela permet de réduire la surcharge de communication car le tenseur de paramètres est répliqué entre données parallèles. GPUs -
"sdp_max_live_parameters"(entier, par défaut : 1e9) : spécifie le nombre maximal de paramètres pouvant être simultanément dans un état d'entraînement recombiné pendant la transmission vers l'avant ou vers l'arrière. La récupération de paramètres avec l'opérationAllGathers'interrompt lorsque le nombre de paramètres actifs atteint le seuil donné. Notez que l'augmentation de ce paramètre augmente l'empreinte mémoire. -
"sdp_hierarchical_allgather"(booléen, par défaut : True) : si ce paramètre a pour valeurTrue, l'opérationAllGathers'exécute de manière hiérarchique : elle s'exécute d'abord dans chaque nœud, puis sur tous les nœuds. Pour les tâches d'entraînement distribué à plusieurs nœuds, l'opérationAllGatherhiérarchique est automatiquement activée. -
"sdp_gradient_clipping"(valeur à virgule flottante, par défaut : 1,0) : spécifie un seuil pour l'écrêtage de gradient de la norme L2 des gradients avant leur propagation vers l'arrière via les paramètres du modèle. Lorsque le parallélisme des données partitionnées est activé, l'écrêtage de gradient est également activé. Le seuil par défaut est1.0. Réglez ce paramètre si vous rencontrez le problème d'explosion de gradient.
Le code suivant montre un exemple de configuration du parallélisme des données partitionnées.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
Référence de configurations
L'équipe de formation SageMaker distribuée fournit les configurations de référence suivantes que vous pouvez utiliser comme point de départ. Vous pouvez extrapoler à partir des configurations précédentes pour expérimenter et estimer l'utilisation de la mémoire GPU pour la configuration de votre modèle.
Parallélisme des données partitionnées avec les collectifs SMDDP
| Modèle/le nombre de paramètres | Nombre d'instances | Type d’instance | Durée de la séquence | Taille globale du lot | Taille du mini-lot | Degré de parallélisation des données partitionnées |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
Par exemple, si vous augmentez la longueur de séquence d'un modèle de 20 milliards de paramètres ou si vous augmentez la taille du modèle à 65 milliards de paramètres, vous devez d'abord essayer de réduire la taille du lot. Si le modèle ne correspond toujours pas à la plus petite taille de lot (la taille de lot de 1), essayez d'augmenter le degré de parallélisme du modèle.
Parallélisme de données partitionnées avec parallélisme de tenseurs et NCCL Collectives
| Modèle/le nombre de paramètres | Nombre d'instances | Type d’instance | Durée de la séquence | Taille globale du lot | Taille du mini-lot | Degré de parallélisation des données partitionnées | Degré de parallélisation du tenseur | Déchargement de l'activation |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | Y |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | Y |
L'utilisation combinée du parallélisme des données fragmentées et du parallélisme des tenseurs est utile lorsque vous souhaitez adapter un modèle de langage étendu (LLM) à un cluster à grande échelle tout en utilisant des données texte dont la longueur de séquence est plus longue, ce qui permet d'utiliser une taille de lot plus petite, et donc de gérer l'utilisation de la mémoire du GPU pour vous entraîner sur des séquences de texte plus longues. LLMs Pour en savoir plus, consultez Parallélisme de données partitionnées avec parallélisme de tenseurs.
Pour des études de cas, des benchmarks et d'autres exemples de configuration, consultez le billet de blog New performance improvements in Amazon SageMaker AI model parallel library
Parallélisme des données partitionnées avec les collectifs SMDDP
La bibliothèque de parallélisme des SageMaker données propose des primitives de communication collective (collectifs SMDDP) optimisées pour l'infrastructure. AWS Il parvient à l'optimisation en adoptant un modèle de all-to-all-type communication utilisant Elastic Fabric Adapter (EFA), ce qui permet de créer des collectifs à haut débit et moins sensibles à la latence, de décharger le traitement lié à la communication vers le processeur et de libérer
Note
Le parallélisme de données partitionné avec SMDDP Collectives est disponible dans la bibliothèque de parallélisme de SageMaker modèles v1.13.0 et versions ultérieures, et dans la bibliothèque de parallélisme de données v1.6.0 et versions ultérieures. SageMaker Consultez également Supported configurations pour utiliser le parallélisme des données partitionnées avec les collectifs SMDDP.
Dans le cas du parallélisme des données partitionnées, qui est une technique couramment utilisée dans l'entraînement distribué à grande échelle, le collectif AllGather est utilisé pour reconstituer les paramètres de la couche partitionnée pour les calculs de passes en avant et en arrière, en parallèle avec le calcul GPU. Pour les modèles de grande taille, réaliser l'opération AllGather est essentiel pour éviter les problèmes d'engorgement du GPU et ralentir la vitesse d'entraînement. Lorsque le parallélisme des données partitionnées est activé, les collectifs SMDDP entrent dans ces collectifs AllGather critiques en termes de performances, améliorant ainsi le débit d'entraînement.
S'entraîner avec les collectifs SMDDP
Lorsque le parallélisme des données partitionnées est activé pour votre tâche d'entraînement et qu'il répond aux exigences Supported configurations, les collectifs SMDDP sont automatiquement activés. En interne, les collectifs SMDDP optimisent le AllGather collectif pour qu'il soit performant sur l' AWS infrastructure et s'en remettent au NCCL pour tous les autres collectifs. De plus, dans les configurations non prises en charge, tous les collectifs, y compris AllGather, utilisent automatiquement le backend NCCL.
Depuis la version 1.13.0 de la bibliothèque de parallélisme des SageMaker modèles, le "ddp_dist_backend" paramètre est ajouté aux options. modelparallel La valeur par défaut de ce paramètre de configuration est "auto", qui utilise les collectifs SMDDP chaque fois que possible et revient à NCCL dans le cas contraire. Pour forcer la bibliothèque à toujours utiliser NCCL, spécifiez "nccl" sur le paramètre de configuration "ddp_dist_backend".
L'exemple de code suivant montre comment configurer un PyTorch estimateur à l'aide du parallélisme de données fragmenté avec le "ddp_dist_backend" paramètre, qui est défini "auto" par défaut et dont l'ajout est donc facultatif.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Configurations prises en charge
L'opération AllGather avec les collectifs SMDDP est activée dans les tâches d'entraînement lorsque toutes les exigences de configuration suivantes sont remplies.
-
Le degré de parallélisme des données partitionnées est supérieur à 1
-
Instance_countsupérieur à 1 -
Instance_typeégal àml.p4d.24xlarge -
SageMaker conteneur d'entraînement pour PyTorch v1.12.1 ou version ultérieure
-
La bibliothèque de parallélisme des SageMaker données v1.6.0 ou version ultérieure
-
La bibliothèque de parallélisme des SageMaker modèles v1.13.0 ou version ultérieure
Réglage des performances et de la mémoire
Les collectifs SMDDP utilisent une mémoire GPU supplémentaire. Deux variables d'environnement permettent de configurer l'utilisation de la mémoire GPU en fonction des différents cas d'utilisation des modèles d'entraînement.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES: pendant l'opérationAllGatherSMDDP, la mémoire tampon d'entréeAllGatherest copiée dans une mémoire tampon temporaire pour la communication entre nœuds. La variableSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTEScontrôle la taille (en octets) de cette mémoire tampon temporaire. Si la taille de la mémoire tampon temporaire est inférieure à la taille de la mémoire tampon d'entréeAllGather, le collectifAllGatherrevient à utiliser NCCL.-
Valeur par défaut : 16 * 1024 * 1024 (16 Mo)
-
Valeurs acceptables : tout multiple de 8 192
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES: la variableSMDDP_AG_SORT_BUFFER_SIZE_BYTESpermet de dimensionner la mémoire tampon temporaire (en octets) pour contenir les données collectées lors de la communication entre nœuds. Si la taille de la mémoire tampon temporaire est inférieure à1/8 * sharded_data_parallel_degree * AllGather input size, le collectifAllGatherrevient à utiliser NCCL.-
Valeur par défaut : 128 * 1024 * 1024 (128 Mo)
-
Valeurs acceptables : tout multiple de 8 192
-
Conseils de réglage sur les variables de taille de la mémoire tampon
Les valeurs par défaut des variables d'environnement devraient fonctionner correctement dans la plupart des cas d'utilisation. Nous recommandons de régler ces variables uniquement si l'entraînement se heurte à l'erreur out-of-memory (OOM).
La liste suivante présente quelques conseils de réglage visant à réduire l'empreinte de la mémoire GPU des collectifs SMDDP tout en préservant les gains de performances qui en découlent.
-
Réglage de
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES-
La taille de la mémoire tampon d'entrée
AllGatherest plus petite pour les modèles plus petits. Par conséquent, la taille requise pourSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpeut être plus petite pour les modèles comportant moins de paramètres. -
La taille de la mémoire tampon
AllGatherd'entrée diminue au fur et à mesure que l'onsharded_data_parallel_degreeaugmente, car le modèle est davantage GPUs segmenté. Par conséquent, la taille requise pourSMDDP_AG_SCRATCH_BUFFER_SIZE_BYTESpeut être plus petite pour les tâches d'entraînement avec des valeurs élevées poursharded_data_parallel_degree.
-
-
Réglage de
SMDDP_AG_SORT_BUFFER_SIZE_BYTES-
La quantité de données collectées à partir de la communication entre nœuds est moins importante pour les modèles comportant moins de paramètres. Par conséquent, la taille requise pour
SMDDP_AG_SORT_BUFFER_SIZE_BYTESpeut être plus petite pour de tels modèles avec moins de paramètres.
-
Certains collectifs peuvent revenir à l'utilisation de NCCL ; par conséquent, vous risquez de ne pas bénéficier du gain de performances des collectifs SMDDP optimisés. Si de la mémoire GPU supplémentaire est disponible, vous pouvez envisager d'augmenter les valeurs de SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES et SMDDP_AG_SORT_BUFFER_SIZE_BYTES pour tirer parti du gain de performances.
Le code suivant montre comment configurer les variables d'environnement en les ajoutant mpi_options au paramètre de distribution de l' PyTorch estimateur.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
Entraînement à précision mixte avec parallélisme de données partitionnées
Pour économiser davantage de mémoire sur le GPU grâce à des nombres à virgule flottante à demi-précision et à un parallélisme de données fragmenté, vous pouvez activer le format à virgule flottante 16 bits (FP16) ou le format à virgule flottante Brain
Note
Un entraînement de précision mixte avec parallélisme de données fragmenté est disponible dans la bibliothèque de parallélisme des SageMaker modèles v1.11.0 et versions ultérieures.
Pour la FP16 formation avec le parallélisme des données fragmentées
Pour exécuter un FP16 entraînement avec un parallélisme de données fragmenté, ajoutez-le "fp16": True" au dictionnaire de smp_options configuration. Dans votre script d'entraînement, vous pouvez choisir entre les options de mise à l'échelle statique et dynamique des pertes via le module smp.DistributedOptimizer. Pour de plus amples informations, veuillez consulter FP16 Entraînement avec le parallélisme des modèles.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
Pour la BF16 formation avec le parallélisme des données fragmentées
La fonctionnalité de parallélisme des données fragmentée de l' SageMaker IA permet de s'entraîner au BF16 type de données. Le type de BF16 données utilise 8 bits pour représenter l'exposant d'un nombre à virgule flottante, tandis que le type de FP16 données utilise 5 bits. La préservation des 8 bits pour l'exposant permet de conserver la même représentation de l'exposant d'un nombre à virgule flottante à précision unique () FP32 de 32 bits. Cela simplifie la conversion entre FP32 et et BF16 est nettement moins susceptible de provoquer des problèmes de débordement et de sous-débit qui surviennent souvent lors de l' FP16 entraînement, en particulier lors de l'entraînement de modèles plus grands. Bien que les deux types de données utilisent 16 bits au total, cette plage de représentation accrue de l'exposant dans le BF16 format se fait au détriment de la précision. Dans le cadre de l'entraînement de grands modèles, cette baisse de précision est souvent considérée comme un compromis acceptable pour la plage et la stabilité de l'entraînement.
Note
Actuellement, la BF16 formation ne fonctionne que lorsque le parallélisme des données partitionnées est activé.
Pour exécuter un BF16 entraînement avec un parallélisme de données fragmenté, ajoutez-le "bf16": True au dictionnaire de smp_options configuration.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
Parallélisme de données partitionnées avec parallélisme de tenseurs
Si vous utilisez le parallélisme de données partitionnées et que vous devez également réduire la taille globale du lot, envisagez d'utiliser le parallélisme de tenseurs avec le parallélisme de données partitionnées. Lorsque vous entraînez un modèle de grande taille avec un parallélisme de données partitionnées sur un très grand cluster de calcul (généralement 128 nœuds ou plus), même une petite taille de lot par GPU se traduit par une taille de lot globale très importante. Cela peut entraîner des problèmes de convergence ou de faibles performances de calcul. La réduction de la taille des lots par GPU n'est parfois pas possible avec le seul parallélisme de données partitionnées lorsqu'un seul lot est déjà volumineux et ne peut pas être réduit davantage. Dans de tels cas, l'utilisation du parallélisme de données partitionnées en combinaison avec le parallélisme de tenseurs permet de réduire la taille globale du lot.
Le choix des degrés de parallélisme de données partitionnées et de parallélisme de tenseurs optimaux dépend de l'échelle du modèle, du type d'instance et de la taille de lot globale qui est raisonnable pour que le modèle à converger. Nous vous recommandons de partir d'un faible degré de parallélisme tenseur pour adapter la taille du lot global au cluster de calcul afin de résoudre les out-of-memory erreurs CUDA et d'obtenir les meilleures performances. Consultez les deux exemples de cas suivants pour découvrir comment la combinaison du parallélisme des tenseurs et du parallélisme des données fragmentées vous aide à ajuster la taille globale du lot en le regroupant GPUs pour le parallélisme du modèle, ce qui se traduit par une diminution du nombre de répliques de modèles et une réduction de la taille globale du lot.
Note
Cette fonctionnalité est disponible dans la bibliothèque de parallélisme des SageMaker modèles v1.15 et prend en charge la version 1.13.1. PyTorch
Note
Cette fonctionnalité est disponible pour les modèles pris en charge par la fonctionnalité de parallélisme de tenseurs de la bibliothèque. Pour trouver la liste des modèles pris en charge, consultez Prise en charge des modèles Transformer Hugging Face. Notez également que vous devez transférer tensor_parallelism=True à l'argument smp.model_creation lorsque vous modifiez votre script d'entraînement. Pour en savoir plus, consultez le script de formation train_gpt_simple.py
Exemple 1
Supposons que nous voulions entraîner un modèle sur un cluster de 1 536 GPUs (192 nœuds de 8 nœuds chacun), GPUs en définissant le degré de parallélisme des données partitionnées sur 32 (sharded_data_parallel_degree=32) et la taille du lot par GPU sur 1, chaque lot ayant une longueur de séquence de 4 096 jetons. Dans ce cas, il existe 1 536 réplicas de modèles, la taille globale du lot devient 1 536 et chaque lot global contient environ 6 millions de jetons.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
L'ajout d'un parallélisme de tenseurs peut réduire la taille globale du lot. Un exemple de configuration peut consister à définir le degré de parallélisme du tenseur sur 8 et la taille du lot par GPU sur 4. Cela forme 192 groupes de tenseurs parallèles ou 192 répliques de modèles, où chaque réplique de modèle est répartie sur 8. GPUs La taille de lot de 4 correspond à la quantité de données d'entraînement par itération et par groupe de parallélisme de tenseurs ; en d'autres termes, chaque réplica de modèle consomme 4 lots par itération. Dans ce cas, la taille globale du lot devient 768 et chaque lot global contient environ 3 millions de jetons. Par conséquent, la taille globale du lot est réduite de moitié par rapport au cas précédent avec un parallélisme de données partitionnées uniquement.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
Exemple 2
Lorsque le parallélisme de données partitionnées et le parallélisme de tenseurs sont activés, la bibliothèque applique d'abord le parallélisme de tenseur et partitionne le modèle sur cette dimension. Pour chaque rang de parallélisme de tenseurs, le parallélisme de données est appliqué conformément au sharded_data_parallel_degree.
Par exemple, supposons que nous voulions définir 32 GPUs avec un degré de parallélisme du tenseur de 4 (formant des groupes de 4 GPUs), un degré de parallélisme des données partitionnées de 4, pour aboutir à un degré de réplication de 2. L'affectation crée huit groupes de GPU basés sur le degré de parallélisme de tenseurs, comme suit : (0,1,2,3), (4,5,6,7), (8,9,10,11), (12,13,14,15), (16,17,18,19), (20,21,22,23), (24,25,26,27), (28,29,30,31). C'est-à-dire que quatre GPUs forment un groupe parallèle de tenseurs. Dans ce cas, le groupe de parallèles de données réduit pour le 0e rang GPUs des groupes de tenseurs parallèles serait. (0,4,8,12,16,20,24,28) Le groupe de parallélisme de données réduit est segmenté en fonction du degré de parallélisme des données fragmenté de 4, ce qui donne lieu à deux groupes de réplication pour le parallélisme des données. GPUs(0,4,8,12)formez un groupe de partitionnement, qui détient collectivement une copie complète de tous les paramètres du 0e rang parallèle du tenseur, GPUs (16,20,24,28) et formez un autre groupe de ce type. D'autres rangs de parallélisme de tenseurs possèdent également des groupes de partitionnement et de réplication similaires.
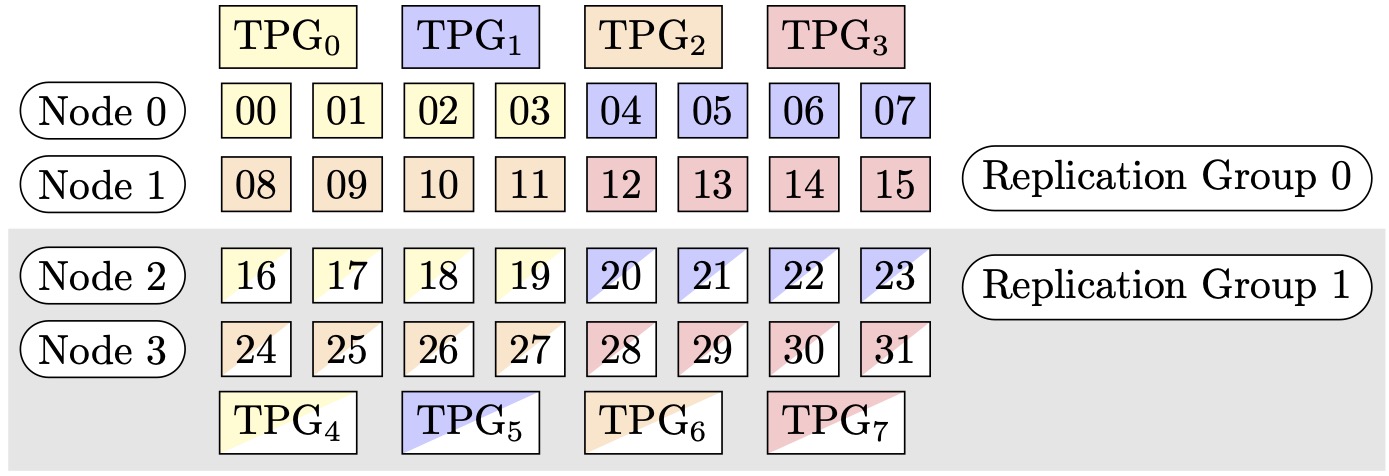
Figure 1 : Groupes de parallélisme tensoriel pour (nœuds, degré de parallélisme des données fragmentées, degré de parallélisme des tenseurs) = (4, 4, 4), où chaque rectangle représente un GPU avec des indices compris entre 0 et 31. Les groupes de parallélisme des tenseurs de GPUs forme TPG en 0 TPG. 7 Les groupes de réplication sont ({TPG0, TPG4}, {TPG1, TPG5} et {TPG 23, TPG 67}) ; chaque paire de groupes de réplication partage la même couleur mais remplie différemment.
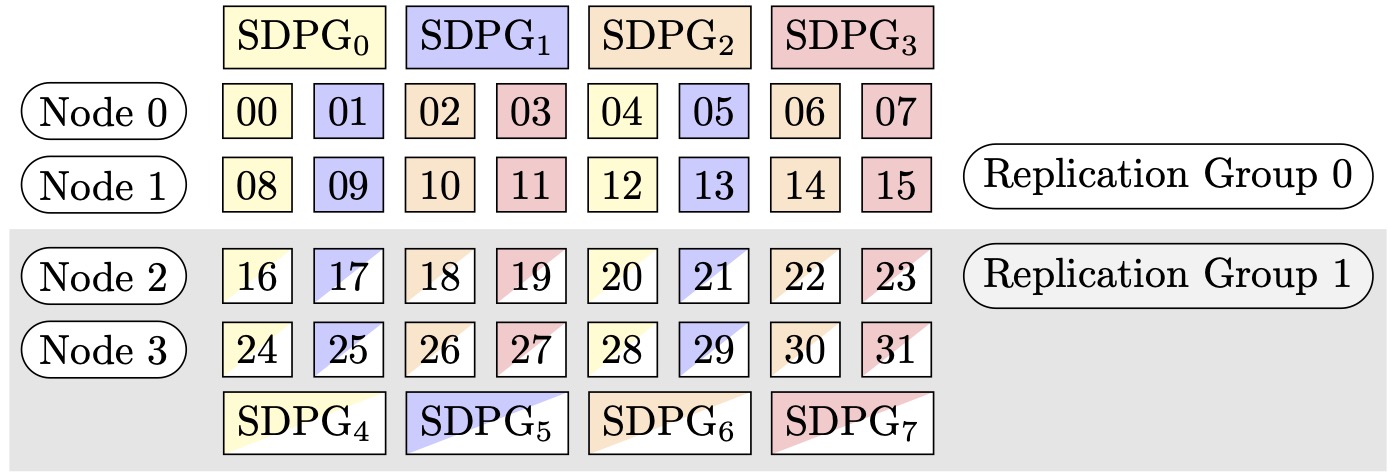
Figure 2 : Groupes de parallélisme de données partitionnées pour (nœuds, degré de parallélisme des données fragmentées, degré de parallélisme des tenseurs) = (4, 4, 4), où chaque rectangle représente un GPU avec des indices compris entre 0 et 31. Le GPUs formulaire fragmenté regroupe des groupes de parallélisme de données de SDPG à 0 SDPG. 7 Les groupes de réplication sont ({SDPG0, SDPG4}, {SDPG1, SDPG5} et {SDPG 23, SDPG 67}) ; chaque paire de groupes de réplication partage la même couleur mais remplie différemment.
Comment activer le parallélisme de données partitionnées avec le parallélisme de tenseurs
Pour utiliser le parallélisme de données fragmenté avec le parallélisme tensoriel, vous devez définir les deux paramètres sharded_data_parallel_degree et, tensor_parallel_degree dans la configuration, distribution lors de la création d'un objet de la classe d'estimateur. SageMaker PyTorch
Vous devez également activer prescaled_batch. Cela signifie qu'au lieu que chaque GPU lise son propre lot de données, chaque groupe de parallélisme de tenseurs lit collectivement un lot combiné de la taille de lot choisie. En fait, au lieu de diviser le jeu de données en parties égales au nombre de GPUs (ou taille parallèle des donnéessmp.dp_size()), il le divise en parties égales au nombre de parties GPUs divisées par tensor_parallel_degree (également appelé taille réduite des données parallèles,smp.rdp_size()). Pour plus de détails sur le traitement par lots prédimensionnés, consultez Prescaled Batchtrain_gpt_simple.py
L'extrait de code suivant montre un exemple de création d'un objet PyTorch estimateur basé sur le scénario susmentionné dans. Exemple 2
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
Conseils et considérations concernant l'utilisation du parallélisme de données partitionnées
Tenez compte des points suivants lorsque vous utilisez le parallélisme de données fragmenté de la bibliothèque de parallélisme du SageMaker modèle.
-
Le parallélisme des données fragmentées est compatible avec l'entraînement. FP16 Pour organiser un FP16 entraînement, consultez la FP16 Entraînement avec le parallélisme des modèles section.
-
Le parallélisme de données partitionnées est compatible avec le parallélisme de tenseurs. Les éléments suivants sont ceux que vous devrez peut-être prendre en compte pour utiliser le parallélisme de données partitionnées avec le parallélisme de tenseurs.
-
Lorsque vous utilisez le parallélisme de données partitionnées avec le parallélisme de tenseur, les couches d'intégration sont également automatiquement réparties dans le groupe de parallélisme de tenseurs. En d'autres termes, le paramètre
distribute_embeddingest automatiquement défini surTrue. Pour plus d'informations sur le parallélisme de tenseurs, consultez Parallélisme de tenseur. -
Notez que le parallélisme de données partitionnées associé au parallélisme de tenseurs utilise actuellement les collectifs NCCL comme backend de la stratégie d'entraînement distribuée.
Pour plus d'informations, consultez la section Parallélisme de données partitionnées avec parallélisme de tenseurs.
-
-
Le parallélisme de données partitionnées n'est actuellement pas compatible avec le parallélisme de pipelines, ni le partitionnement de l'état de l'optimiseur. Pour activer le parallélisme de données partitionnées, désactivez le partitionnement de l'état de l'optimiseur et définissez le degré de parallélisme de pipelines sur 1.
-
Les fonctionnalités des points de contrôle d'activation et du déchargement de l'activation sont compatibles avec le parallélisme des données partitionnées.
-
Pour utiliser le parallélisme des données partitionnées avec cumul de gradient, définissez l'argument
backward_passes_per_stepsur le nombre d'étapes de cumul lors de l'enveloppement de votre modèle avec le modulesmdistributed.modelparallel.torch.DistributedModel. Cela garantit que l'opération AllReducede gradient entre les groupes de réplication du modèle (groupes de partitionnement) a lieu à la limite du cumul de gradient. -
Vous pouvez vérifier vos modèles entraînés avec le parallélisme de données fragmenté à l'aide du point de contrôle de la bibliothèque, et. APIs
smp.save_checkpointsmp.resume_from_checkpointPour de plus amples informations, veuillez consulter Vérification d'un PyTorch modèle distribué (pour la bibliothèque de parallélisme des SageMaker modèles v1.10.0 et versions ultérieures). -
Le comportement du paramètre de configuration
delayed_parameter_initializationchange dans le cadre du parallélisme des données partitionnées. Lorsque ces deux fonctionnalités sont activées simultanément, les paramètres sont immédiatement initialisés lors de la création du modèle d'une manière partitionnée au lieu de retarder l'initialisation des paramètres, de sorte que chaque rang initialise et stocke sa propre partition de paramètres. -
Lorsque le parallélisme des données partitionnées est activé, la bibliothèque effectue un écrêtage de gradient en interne lorsque l'appel
optimizer.step()s'exécute. Vous n'avez pas besoin d'utiliser un utilitaire APIs pour le découpage en dégradé, tel quetorch.nn.utils.clip_grad_norm_(). Pour ajuster la valeur de seuil pour le découpage en dégradé, vous pouvez la définir via le sdp_gradient_clippingparamètre de configuration des paramètres de distribution lorsque vous créez l' SageMaker PyTorch estimateur, comme indiqué dans la section. Comment appliquer le parallélisme de données partitionnées à votre tâche d'entraînement
