Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Présentation du parallélisme des modèles
Le parallélisme de modèle est une méthode d'entraînement distribué dans laquelle le modèle de deep learning est partitionné sur plusieurs appareils, au sein des instances ou entre celles-ci. Cette page d'introduction fournit une présentation générale du parallélisme des modèles, une description de la manière dont il peut aider à résoudre les problèmes qui surviennent lors de l'entraînement de modèles DL généralement de très grande taille, et des exemples de ce que propose la bibliothèque de modèles SageMaker parallèles pour aider à gérer les stratégies de modélisation parallèle ainsi que la consommation de mémoire.
Qu'est-ce que le parallélisme des modèles ?
L'augmentation de la taille des modèles de deep learning (couches et paramètres) permet une meilleure précision pour des tâches complexes telles que la reconnaissance d'image et le traitement du langage naturel. Toutefois, il y a une limite à la taille maximale de modèle que vous pouvez faire tenir dans la mémoire d'un GPU individuel. Lors de l'entraînement de modèles DL, les limites de mémoire du GPU peuvent constituer un goulet d'étranglement :
-
Elles limitent la taille du modèle que vous pouvez entraîner, car l'empreinte mémoire d'un modèle évolue proportionnellement au nombre de paramètres.
-
Elles limitent la taille de lot par GPU pendant l'entraînement, ce qui réduit l'utilisation du GPU et l'efficacité de l'entraînement.
Pour surmonter les limites associées à l'entraînement d'un modèle sur un seul GPU, SageMaker fournit la bibliothèque model parallel qui permet de distribuer et d'entraîner efficacement les modèles DL sur plusieurs nœuds de calcul. En outre, cette bibliothèque vous permet de profiter d'un entraînement distribué optimisé à l'aide d'appareils intégrant EFA, qui améliorent les performances de la communication entre les nœuds avec une faible latence, un débit élevé et le contournement du système d'exploitation.
Estimation des besoins en mémoire avant d'utiliser le parallélisme de modèle
Avant d'utiliser la bibliothèque SageMaker model parallel, considérez les points suivants pour vous faire une idée des besoins en mémoire liés à l'entraînement de grands modèles DL.
Pour une tâche d'entraînement utilisant les optimiseurs AMP (FP16) et Adam, la mémoire GPU requise par paramètre est d'environ 20 octets, que nous pouvons décomposer comme suit :
-
Un FP16 paramètre d'environ 2 octets
-
Un FP16 gradient d'environ 2 octets
-
Un état d' FP32 optimisation d'environ 8 octets basé sur les optimiseurs Adam
-
Une FP32 copie du paramètre d'environ 4 octets (nécessaire pour l'opération
optimizer apply(OA)) -
Une FP32 copie du gradient d'environ 4 octets (nécessaire pour l'opération OA)
Même un modèle DL relativement petit, avec 10 milliards de paramètres, peut nécessiter au moins 200 Go de mémoire, ce qui dépasse nettement la mémoire GPU standard (par exemple, NVIDIA A100 avec 40/80 Go de mémoire et V100 avec 16/32 Go) disponible sur un GPU individuel. Notez qu'en plus des besoins en mémoire pour les états de modèle et d'optimiseur, il existe d'autres consommateurs de mémoire tels que les activations générées dans la transmission vers l'avant. La mémoire requise peut être largement supérieure à 200 Go.
Pour les formations distribuées, nous vous recommandons d'utiliser des instances Amazon EC2 P3 et P4 dotées respectivement de NVIDIA V100 et A100 Tensor Core. GPUs Pour plus de détails sur les spécifications telles que les cœurs de processeur, la RAM, le volume de stockage attaché et la bande passante réseau, consultez la section Accelerated Computing de la page Amazon EC2 Instance Types
Même avec les instances de calcul accéléré, il est évident que des modèles avec environ 10 milliards de paramètres, tels que Megatron-LM et T5, et des modèles encore plus grands avec des centaines de milliards de paramètres, tels que GPT-3, ne peuvent pas faire tenir les réplicas de modèles dans chaque périphérique GPU.
Utilisation par la bibliothèque des techniques d'économie de mémoire et de parallélisme de modèle
La bibliothèque comprend différents types de fonctionnalités de parallélisme de modèle et de fonctionnalités d'économie de mémoire, telles que le partitionnement de l'état de l'optimiseur, les points de contrôle d'activation et le déchargement d'activation. Toutes ces techniques peuvent être combinées pour entraîner efficacement des modèles de grande taille composés de centaines de milliards de paramètres.
Rubriques
Parallélisme de données fragmenté (disponible pour) PyTorch
Le parallélisme des données partitionnées est une technique d'entraînement distribuée économisant de la mémoire qui divise l'état d'un modèle (paramètres du modèle, dégradés et états de l'optimiseur) au sein d'un groupe parallèle de données. GPUs
Vous pouvez appliquer le parallélisme de données partitionnées à votre modèle en tant que stratégie autonome. De plus, si vous utilisez les instances GPU les plus performantes équipées du NVIDIA A100 Tensor Core GPUsml.p4d.24xlarge, vous pouvez profiter de la vitesse d'entraînement améliorée grâce au AllGather fonctionnement proposé par SMDDP Collectives.
Pour approfondir le parallélisme des données fragmentées et apprendre à le configurer ou à utiliser une combinaison du parallélisme de données fragmenté avec d'autres techniques telles que le parallélisme tensoriel et l'entraînement, voir. FP16 Parallélisme des données partitionnées
Parallélisme du pipeline (disponible pour PyTorch et) TensorFlow
Le parallélisme de pipeline partitionne l'ensemble de couches ou d'opérations sur l'ensemble de dispositifs, laissant chaque opération intacte. Lorsque vous spécifiez une valeur pour le nombre de partitions de modèle (pipeline_parallel_degree), le nombre total de GPUs (processes_per_host) doit être divisible par le nombre de partitions de modèle. Pour configurer cela correctement, vous devez spécifier les bonnes valeurs pour les paramètres pipeline_parallel_degree et processes_per_host. Le calcul simple est le suivant :
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
La bibliothèque se charge de calculer le nombre de réplicas du modèle (également appelé data_parallel_degree) en fonction des deux paramètres d'entrée que vous fournissez.
Par exemple, si vous définissez "pipeline_parallel_degree": 2 et "processes_per_host": 8 utilisez une instance ML avec huit processeurs graphiques, par exempleml.p3.16xlarge, la bibliothèque configure automatiquement le modèle distribué sur le parallélisme des données GPUs et le parallélisme quadridirectionnel. L'image suivante montre comment un modèle est distribué sur les huit, ce qui permet d' GPUs obtenir un parallélisme des données quadridirectionnel et un parallélisme des pipelines bidirectionnel. Chaque réplique de modèle, dans laquelle nous la définissons comme un groupe parallèle de pipelines et l'étiquetons comme suitPP_GROUP, est partitionnée en deux GPUs. Chaque partition du modèle est affectée à quatre GPUs, les quatre répliques de partitions se trouvant dans un groupe data parallel et étiquetées commeDP_GROUP. Sans parallélisme de tenseur, le groupe de parallélisme de pipeline est essentiellement le groupe de parallélisme de modèle.

Pour explorer le parallélisme de pipeline, consultez Principales fonctionnalités de la bibliothèque de parallélisme des SageMaker modèles.
Pour commencer à exécuter votre modèle à l'aide du parallélisme de pipeline, voir Run a SageMaker Distributed Training Job with the SageMaker Model Parallel Library.
Parallélisme tensoriel (disponible pour) PyTorch
Le parallélisme de tenseurs divise les couches individuelles, ou nn.Modules, entre les dispositifs, pour qu'elles soient exécutées en parallèle. La figure suivante illustre l'exemple le plus simple de la façon dont la bibliothèque divise un modèle à quatre couches pour obtenir un parallélisme de tenseur bidirectionnel ("tensor_parallel_degree": 2). Les couches de chaque réplique du modèle sont coupées en deux et réparties en deux GPUs. Dans ce cas d'exemple, la configuration parallèle du modèle inclut également "pipeline_parallel_degree": 1 et "ddp": True (utilise le PyTorch DistributedDataParallel package en arrière-plan), de sorte que le degré de parallélisme des données passe à huit. La bibliothèque gère la communication entre les réplicas de modèles distribués par tenseur.
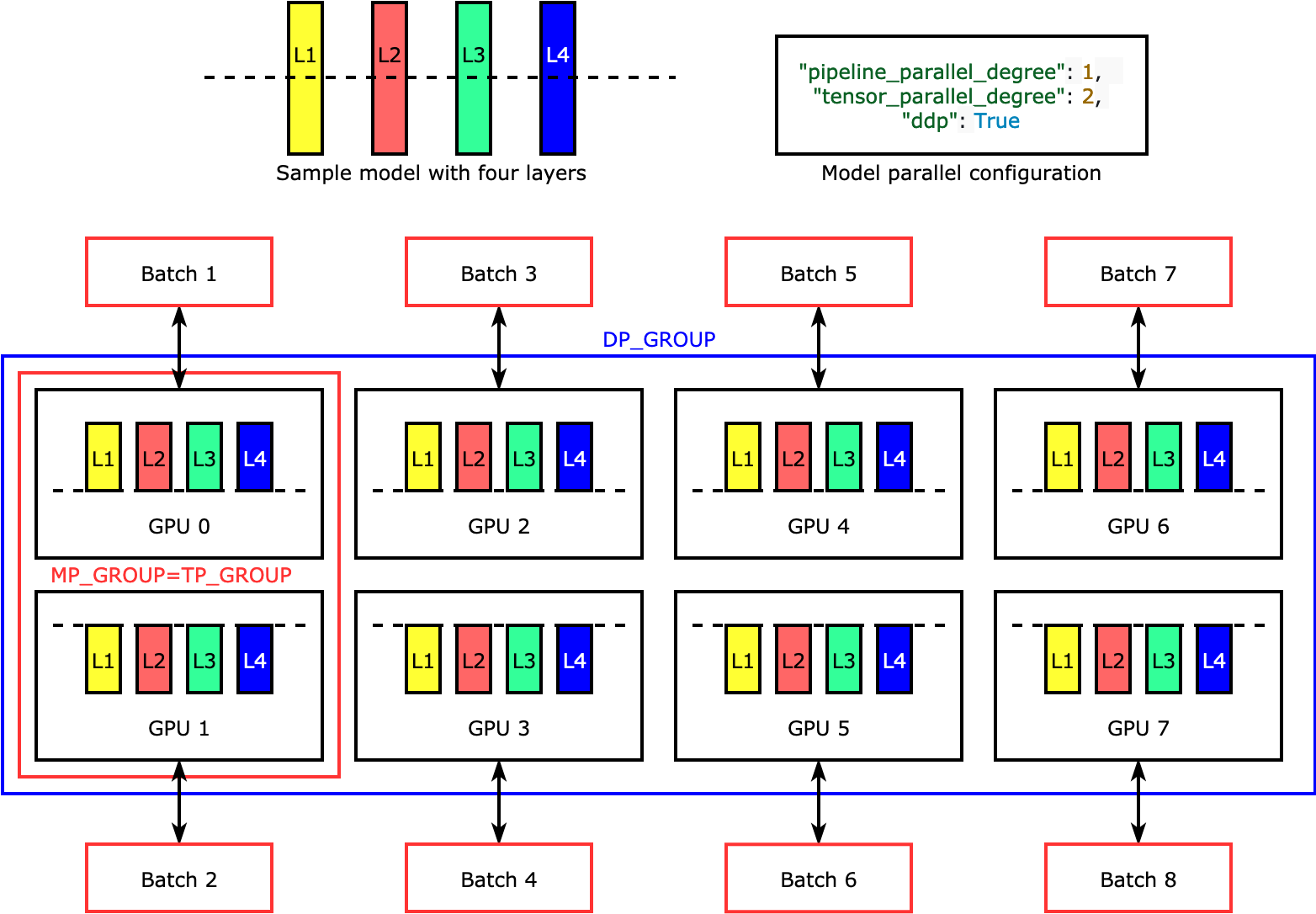
L'utilité de cette fonctionnalité réside dans le fait que vous pouvez sélectionner des couches spécifiques ou un sous-ensemble de couches pour appliquer le parallélisme de tenseur. Pour en savoir plus sur le parallélisme des tenseurs et d'autres fonctionnalités permettant d'économiser de la mémoire PyTorch, et pour apprendre à définir une combinaison de parallélisme de pipeline et de tenseur, voir. Parallélisme de tenseur
Sharding de l'état de l'optimiseur (disponible pour) PyTorch
Pour comprendre comment la bibliothèque effectue le partitionnement de l'état de l'optimiseur, envisagez un exemple de modèle simple à quatre couches. L'idée clé pour optimiser le partitionnement des états est que vous n'avez pas besoin de reproduire l'état de votre optimiseur dans tous vos. GPUs Au lieu de cela, un seul réplica de l'état de l'optimiseur est partitionné entre les rangs parallèles de données, sans redondance entre les appareils. Par exemple, le GPU 0 conserve l'état de l'optimiseur pour la couche 1, le GPU 1 suivant contient l'état de l'optimiseur pour la couche 2 (L2), etc. La figure animée suivante montre une propagation vers l'arrière avec la technique de partitionnement de l'état de l'optimiseur. À la fin de la propagation vers l'arrière, il y a le temps de calcul et de réseau pour l'opération optimizer apply (OA) pour mettre à jour les états de l'optimiseur et l'opération all-gather (AG) pour mettre à jour les paramètres du modèle pour la prochaine itération. Surtout, l'opération reduce peut chevaucher le calcul sur GPU 0, ce qui entraîne une propagation vers l'arrière plus rapide et plus efficace en termes de mémoire. Dans l'implémentation actuelle, les opérations AG et OA ne chevauchent pas compute. Cela peut entraîner un calcul étendu pendant l'opération AG, pouvant donner lieu à un compromis.

Pour plus d'informations sur l'utilisation de cette fonctionnalité, consultez Partitionnement de l'état de l'optimiseur.
Activation, déchargement et point de contrôle (disponible pour) PyTorch
Pour enregistrer la mémoire GPU, la bibliothèque prend en charge les points de contrôle d'activation afin d'éviter de stocker des activations internes dans la mémoire GPU pour les modules spécifiés par l'utilisateur pendant la transmission vers l'avant. La bibliothèque recalcule ces activations pendant la transmission vers l'arrière. En outre, la fonctionnalité de déchargement d'activation décharge les activations stockées dans la mémoire CPU et les récupère dans le GPU pendant la transmission vers l'arrière, afin de réduire encore l'empreinte mémoire d'activation. Pour plus d'informations sur l'utilisation de ces fonctionnalités, consultez Points de contrôle d'activation et Déchargement de l'activation.
Choix des techniques appropriées pour votre modèle
Pour plus d'informations sur le choix des techniques et des configurations appropriées, consultez les meilleures pratiques parallèles en matière de modèles SageMaker distribués et les conseils et pièges en matière de configuration.
