OPS10-BP02 Disposer d’un processus par alerte
Il est essentiel d’établir un processus clair et défini pour chaque alerte de votre système afin de garantir une gestion efficace et efficiente des incidents. Cette pratique garantit que chaque alerte entraîne une réponse spécifique et exploitable, améliorant ainsi la fiabilité et la réactivité de vos opérations.
Résultat escompté : chaque alerte déclenche un plan de réponse spécifique et bien défini. Dans la mesure du possible, les réponses sont automatisées, avec une propriété clairement établie et une procédure de remontée définie. Les alertes sont liées à une base de connaissances actualisée afin que chaque opérateur puisse réagir de manière cohérente et efficace. Les réponses sont rapides et uniformes à tous les niveaux, ce qui améliore l’efficacité et la fiabilité opérationnelles.
Anti-modèles courants :
-
Les alertes n’ont pas de processus de réponse prédéfini, ce qui entraîne des résolutions improvisées et différées.
-
En raison de la surcharge d’alertes, celles qui sont importantes sont ignorées.
-
Les alertes ne sont pas traitées de manière cohérente en raison de l’absence de définition claire de la propriété et des responsabilités.
Avantages liés au respect de cette bonne pratique :
-
Réduction de la lassitude liée aux alertes en ne déclenchant que des alertes exploitables.
-
Diminution du délai moyen de résolution (MTTR) des problèmes opérationnels.
-
Diminution du délai moyen d’investigation (MTTI), ce qui contribue à réduire le MTTR.
-
Capacité accrue à mettre à l’échelle les réponses opérationnelles.
-
Amélioration de la cohérence et de la fiabilité dans la gestion des événements opérationnels.
Par exemple, vous disposez d’un processus défini pour les événements AWS Health pour les comptes critiques, y compris les alarmes d’application, les problèmes opérationnels et les événements planifiés du cycle de vie (comme la mise à jour des versions d’Amazon EKS avant la mise à jour automatique des clusters), et vous donnez à vos équipes la possibilité de surveiller activement ces événements, de les communiquer et d’y répondre. Ces actions vous aident à prévenir les interruptions de service causées par des modifications côté AWS ou à les atténuer plus rapidement en cas de problèmes inattendus.
Niveau d’exposition au risque si cette bonne pratique n’est pas respectée : élevé
Directives d’implémentation
Pour disposer d’un processus par alerte, il est nécessaire d’établir un plan de réponse clair pour chaque alerte, d’automatiser les réponses dans la mesure du possible et d’améliorer continuellement ces processus en fonction des commentaires opérationnels et de l’évolution des exigences.
Étapes d’implémentation
Le schéma suivant illustre le flux de travail de gestion des incidents dans AWS Systems Manager Incident Manager
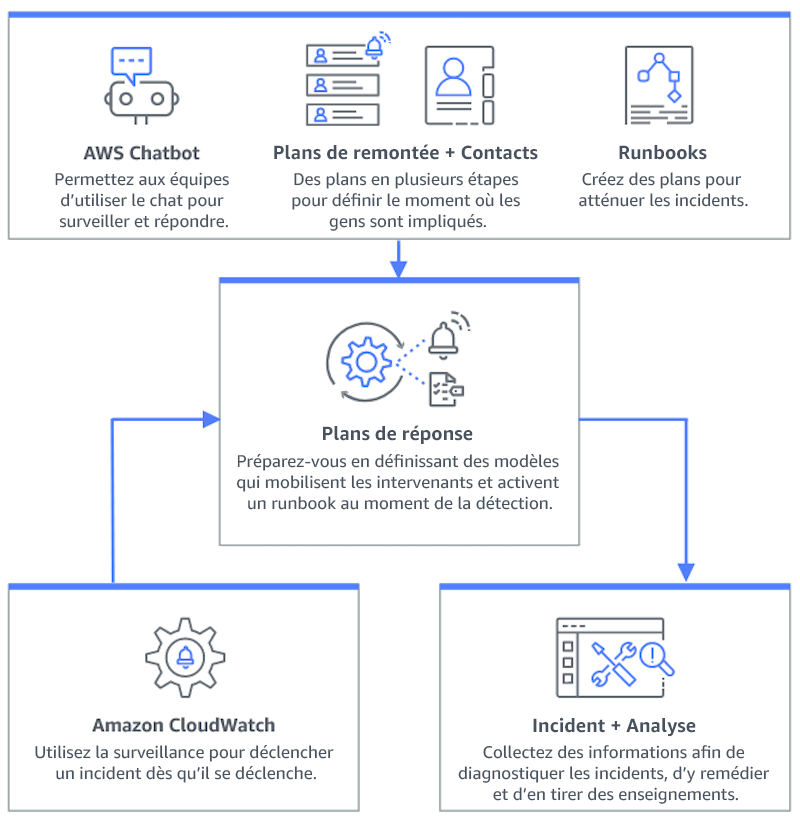
-
Utiliser des alarmes composites : créez des alarmes composites dans CloudWatch pour regrouper les alarmes associées, réduire le bruit et permettre des réponses plus pertinentes.
-
Restez informé avec AWS Health : AWS Health est la source d’informations faisant autorité sur l’intégrité de vos ressources AWS Cloud. Utilisez AWS Health pour visualiser et être informé de tous les événements de service en cours et des changements à venir, tels que les événements de cycle de vie planifiés, afin de pouvoir prendre des mesures pour atténuer les impacts.
-
Créez des notifications d’événements AWS Health spécialement adaptées aux e-mails et aux canaux de discussion via Notifications des utilisateurs AWS et intégrez-les de manière programmatique à vos outils de surveillance et d’alerte via Amazon EventBridge ou l’API AWS Health.
-
Planifiez et suivez l’évolution des événements d’intégrité qui nécessitent une action en intégrant des outils de gestion des modifications ou des outils ITSM (tels que Jira ou ServiceNow) que vous utilisez peut-être déjà via Amazon EventBridge ou l’API AWS Health.
-
Si vous utilisez AWS Organizations, activez la vue de l’organisation pour AWS Health afin d’agréger les événements AWS Health sur l’ensemble des comptes.
-
-
Intégrer les alarmes Amazon CloudWatch avec Incident Manager : configurez les alarmes CloudWatch pour créer automatiquement des incidents dans AWS Systems Manager Incident Manager.
-
Intégrer Amazon EventBridge à Incident Manager : créez des règles EventBridge pour réagir aux événements et créer des incidents à l’aide de plans d’intervention définis.
-
Préparez-vous aux incidents dans Incident Manager :
-
Établissez des plans d’intervention détaillés dans Incident Manager pour chaque type d’alerte.
-
Établissez des canaux de chat par le biais de Amazon Q Developer dans les applications de chat connecté aux plans d’intervention dans Incident Manager, afin de faciliter la communication en temps réel lors d’incidents sur des plateformes telles que Slack, Microsoft Teams et Amazon Chime.
-
Intégrez les dossiers d’exploitation d’automatisation de la gestion des systèmes dans Incident Manager pour générer des interventions automatisées en cas d’incidents.
-
Ressources
Bonnes pratiques associées :
Documents connexes :
Vidéos connexes :
Exemples connexes :
