Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Évacuation contrôlée par le plan de commande
Le premier modèle utilise les opérations du plan de données pour empêcher d'effectuer des travaux dans une zone de disponibilité affectée afin d'atténuer l'impact d'un événement. Toutefois, vous utilisez peut-être une architecture qui n'utilise pas d'équilibreurs de charge ou pour laquelle il n'est pas possible de configurer un bilan de santé par hôte. Vous pouvez également souhaiter empêcher le déploiement de nouvelles capacités dans la zone de disponibilité concernée par le biais d'une mise à l'échelle automatique ou d'une planification normale du travail.
Pour résoudre les deux situations, des actions du plan de contrôle sont nécessaires pour mettre à jour la configuration de la ressource. Le modèle fonctionnera pour tous les services dont la configuration réseau peut être mise à jour, par exemple EC2 Auto Scaling, Amazon ECS, Lambda, etc. Cela nécessite d'écrire du code pour chaque service, mais la logique métier suit un modèle standard. Le code doit être exécuté localement par un opérateur répondant à l'événement afin de minimiser les dépendances requises. Le flux de base de la logique du script est illustré dans la figure suivante.
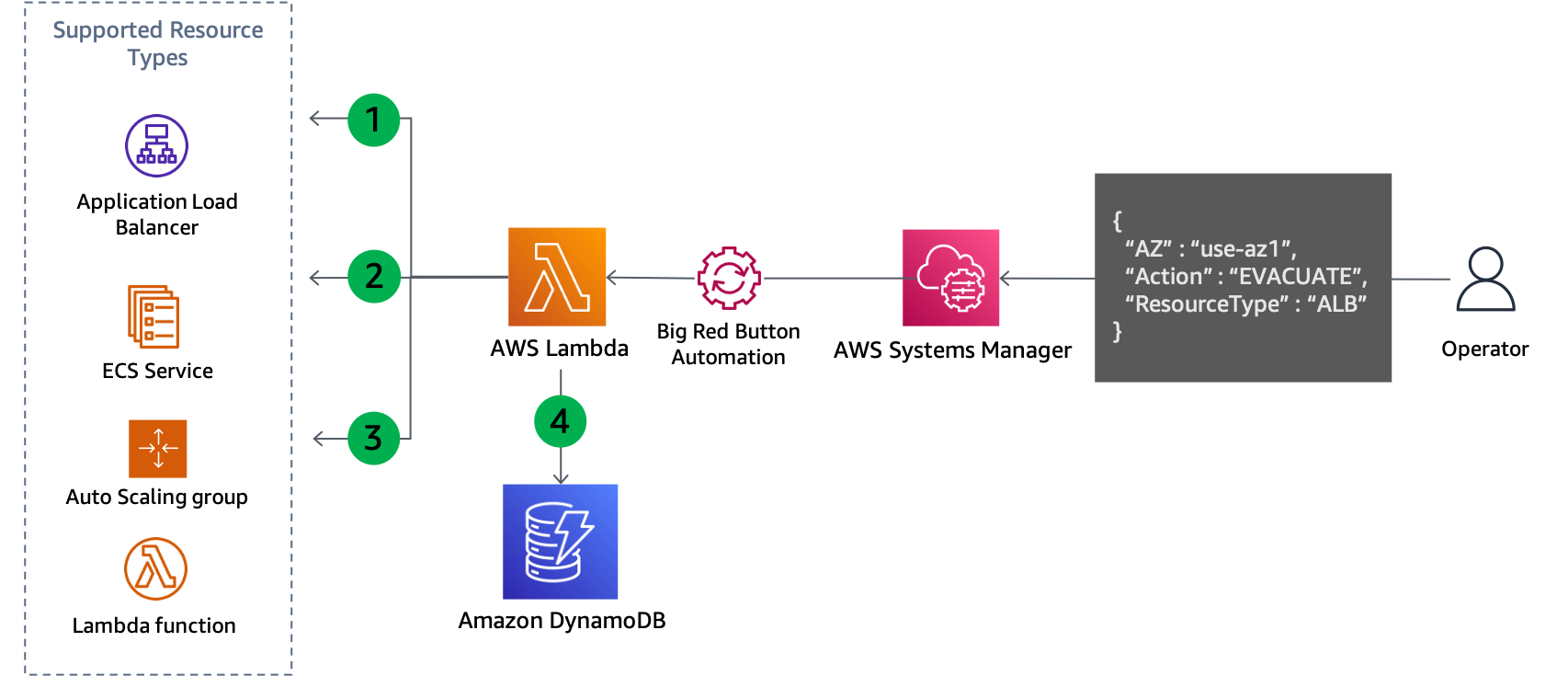
Mise à jour du plan de contrôle pour évacuer une zone de disponibilité
-
Le script répertorie toutes les ressources du type spécifié, telles que le groupe Auto Scaling, le service ECS ou la fonction Lambda, et extrait leurs sous-réseaux à partir des informations sur les ressources. Les ressources prises en charge dépendent de ce que le script a été configuré pour prendre en charge.
-
Il détermine quels sous-réseaux doivent être supprimés en comparant le nom de zone de disponibilité de chaque sous-réseau à son ID de zone de disponibilité mappé qui a été fourni en tant que paramètre d'entrée.
-
La configuration réseau de la ressource est mise à jour pour supprimer les sous-réseaux identifiés.
-
Les détails de la mise à jour sont enregistrés dans une table DynamoDB. L'ID de la zone de disponibilité est enregistré sous la formeclé de partitionet l'ARN ou le nom de la ressource est stocké sous la formeclé de tri. Les sous-réseaux qui ont été supprimés sont stockés sous forme de tableau de chaînes. Enfin, le type de ressource est également stocké et utilisé comme clé de hachage pourIndice secondaire mondial(SIG).
Étant donné que la quatrième étape enregistre les mises à jour effectuées, cette approche se prête également à être facilement réversible lorsque vous êtes prêt à effectuer la restauration, comme le montre la figure suivante.
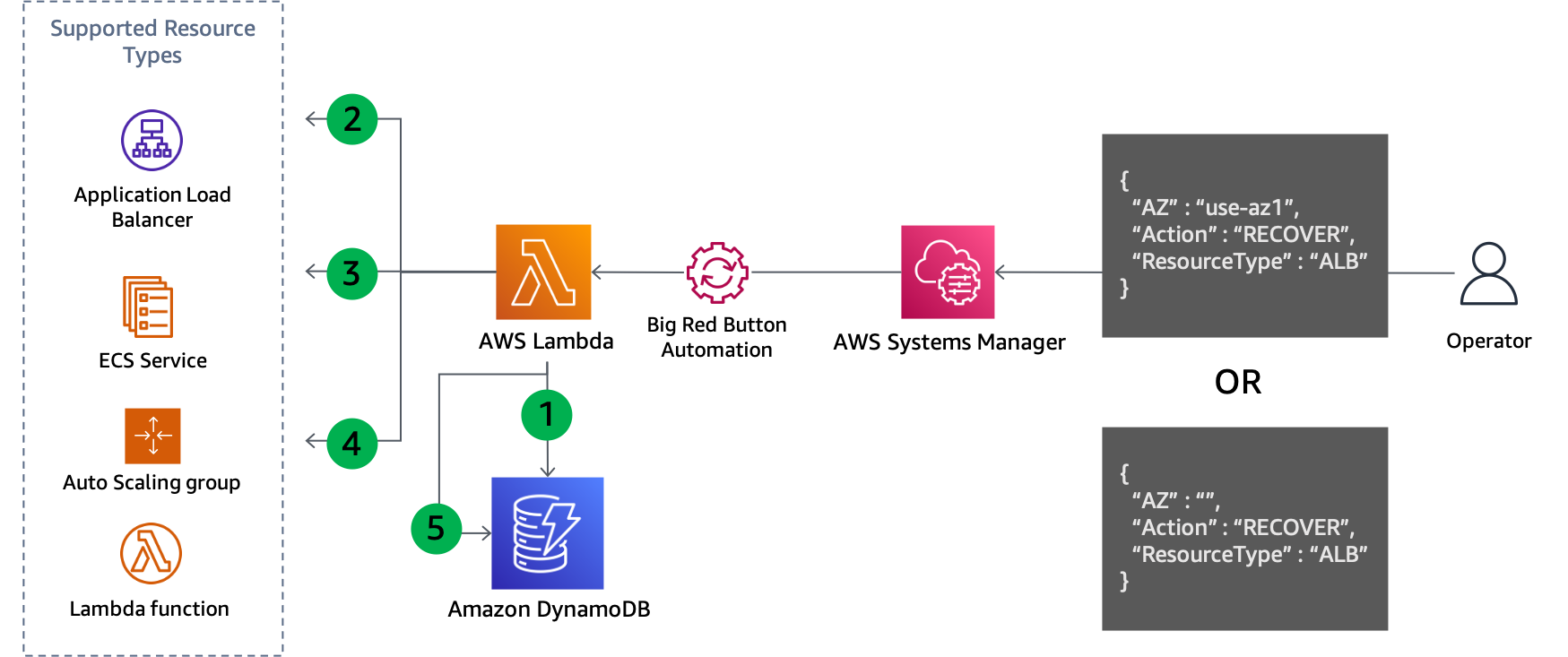
Mise à jour du plan de contrôle en cas d'évacuation de la zone de disponibilité
Étapes de restauration :
-
Interrogez le GSI pour supprimer les sous-réseaux pour chaque ressource du type spécifié dans la zone de disponibilité spécifiée (ou toutes les zones de disponibilité si aucune n'est spécifiée).
-
Décrivez chaque ressource trouvée dans la requête DynamoDB pour obtenir sa configuration réseau actuelle.
-
Combinez les sous-réseaux de la configuration réseau actuelle avec ceux extraits de la requête DynamoDB.
-
Mettez à jour la configuration réseau de la ressource avec le nouvel ensemble de sous-réseaux.
-
Supprimez l'enregistrement de la table DynamoDB une fois la mise à jour terminée avec succès.
Ce schéma généralisé empêche à la fois les travaux de routage vers la zone de disponibilité concernée et empêche le déploiement de nouvelles capacités dans cette zone. Vous trouverez ci-dessous des exemples de la manière dont cela est réalisé pour différents services.
-
Lambda— Met à jour les fonctionsConfiguration du VPCpour supprimer les sous-réseaux de la zone de disponibilité spécifiée.
-
Groupe Auto Scaling—Supprimer les sous-réseaux de la configuration ASGqui remplacera cette capacité dans les zones de disponibilité restantes.
-
Amazon ECS—Mettre à jour la configuration VPC du service ECSpour supprimer les sous-réseaux.
-
Amazon EKS— Postulezsouillures
aux nœuds de la zone de disponibilité affectée pour expulser des pods existants et empêcher la planification de nouveaux pods dans cette zone.
Chaque service réagira différemment à la mise à jour de configuration. Par exemple, Amazon ECS suivra leconfiguration du déploiement du service après une mise à jouret déclenchez un déploiement continu ou un déploiement bleu/vert de nouvelles tâches.
Ces mises à jour peuvent transférer trop rapidement le travail vers les zones de disponibilité saines pour certaines charges de travail. Tout en étant configuré pour être statiquement stable en cas de panne (en disposant de suffisamment de capacité préprovisionnée dans les zones de disponibilité restantes pour gérer le travail de la zone de disponibilité affectée), vous pouvez également souhaiter supprimer progressivement la capacité de la zone de disponibilité affectée.
Si vous envisagez de mettre à jour la configuration réseau de votre groupe Auto Scaling, qui est le groupe cible d'un équilibreur de charge avec équilibrage de charge entre zoneshandicapé, suivez ces instructions.
Auto Scaling réagit à ce changement en utilisantLogique de rééquilibrage des zones de disponibilité. Il lancera des instances dans les autres zones de disponibilité pour atteindre la capacité souhaitée et mettra fin aux instances de la zone de disponibilité que vous avez supprimée. Toutefois, l'équilibreur de charge continuera à répartir le trafic de manière égale entre chaque zone de disponibilité, y compris celle que vous avez supprimée de l'ASG, pendant la résiliation des instances. Cela pourrait entraîner une baisse de la capacité restante dans cette zone de disponibilité jusqu'à ce que toutes les instances y soient clôturées avec succès. Il s'agit du même problème décrit dansIndépendance de la zone de disponibilitéconcernant le déséquilibre des zones de disponibilité lorsque l'équilibrage de charge entre zones est désactivé. Pour éviter que cela ne se produise, vous pouvez :
-
Effectuez toujours l'évacuation de votre zone de disponibilité en premier afin que le trafic ne soit réparti qu'entre les zones de disponibilité restantes
-
Spécifiez unnombre minimal de cibles saines avec basculement DNSpour atteindre le nombre minimum d'objectifs requis pour cette zone de disponibilité.
Cela permettra de garantir que le trafic n'est pas envoyé vers la zone de disponibilité que vous avez supprimée après le début de la fermeture des instances.
