Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Évacuation contrôlée par avion de données
Il existe plusieurs solutions que vous pouvez mettre en œuvre pour effectuer une évacuation de la zone de disponibilité à l'aide d'actions relevant uniquement du plan de données. Cette section décrit trois d'entre eux et les cas d'utilisation dans lesquels vous pouvez choisir l'un plutôt que l'autre.
Lorsque vous utilisez l'une de ces solutions, vous devez vous assurer de disposer d'une capacité suffisante dans les zones de disponibilité restantes pour gérer la charge de la zone de disponibilité que vous quittez. Pour ce faire, la solution la plus résiliente consiste à préprovisionner la capacité requise dans chaque zone de disponibilité. Si vous utilisez trois zones de disponibilité, vous disposerez de 50 % de la capacité requise pour gérer votre charge de pointe déployée dans chacune d'entre elles, de sorte que la perte d'une seule zone de disponibilité vous laisserait tout de même 100 % de la capacité requise sans avoir à vous fier à un plan de contrôle pour en provisionner davantage.
En outre, si vous utilisez EC2 Auto Scaling, assurez-vous que votre groupe Auto Scaling (ASG) n'évolue pas pendant le quart de travail, de sorte qu'à la fin du quart de travail, vous disposiez toujours d'une capacité suffisante dans le groupe pour gérer le trafic de vos clients. Pour ce faire, vous devez vous assurer que la capacité minimale souhaitée de votre ASG est en mesure de faire face à votre charge de clientèle actuelle. Vous pouvez également vous assurer que votre ASG n'évolue pas par inadvertance en utilisant des moyennes dans vos mesures plutôt que des mesures percentiles aberrantes telles que P90 ou P99.
Pendant un quart de travail, les ressources qui ne desservent plus le trafic devraient être très peu utilisées, mais les autres ressources augmenteront leur utilisation en fonction du nouveau trafic, en maintenant la moyenne relativement constante, ce qui empêcherait toute action de mise à l'échelle. Enfin, vous pouvez également utiliser les paramètres de santé du groupe cible pourALBetNLBpour spécifier le basculement DNS avec un pourcentage ou un nombre d'hôtes sains. Cela empêche le trafic d'être acheminé vers une zone de disponibilité ne disposant pas d'un nombre suffisant d'hôtes sains.
Changement zonal dans le contrôleur de restauration des applications (ARC) Route 53
La première solution pour les utilisations d'évacuation des zones de disponibilitéchangement de zone sur la Route 53 ARC. Cette solution peut être utilisée pour les charges de travail de requête/réponse qui utilisent un NLB ou un ALB comme point d'entrée pour le trafic client.
Lorsque vous détectez qu'une zone de disponibilité est altérée, vous pouvez initier un changement de zone avec Route 53 ARC. Une fois que cette opération est terminée et que les réponses DNS mises en cache existantes expirent, toutes les nouvelles demandes sont uniquement acheminées vers les ressources des zones de disponibilité restantes. La figure suivante montre le fonctionnement du décalage zonal. Dans la figure suivante, nous avons un enregistrement d'alias Route 53 pourwww.example.comqui pointe versmy-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. Le décalage zonal est effectué pour la zone de disponibilité 3.
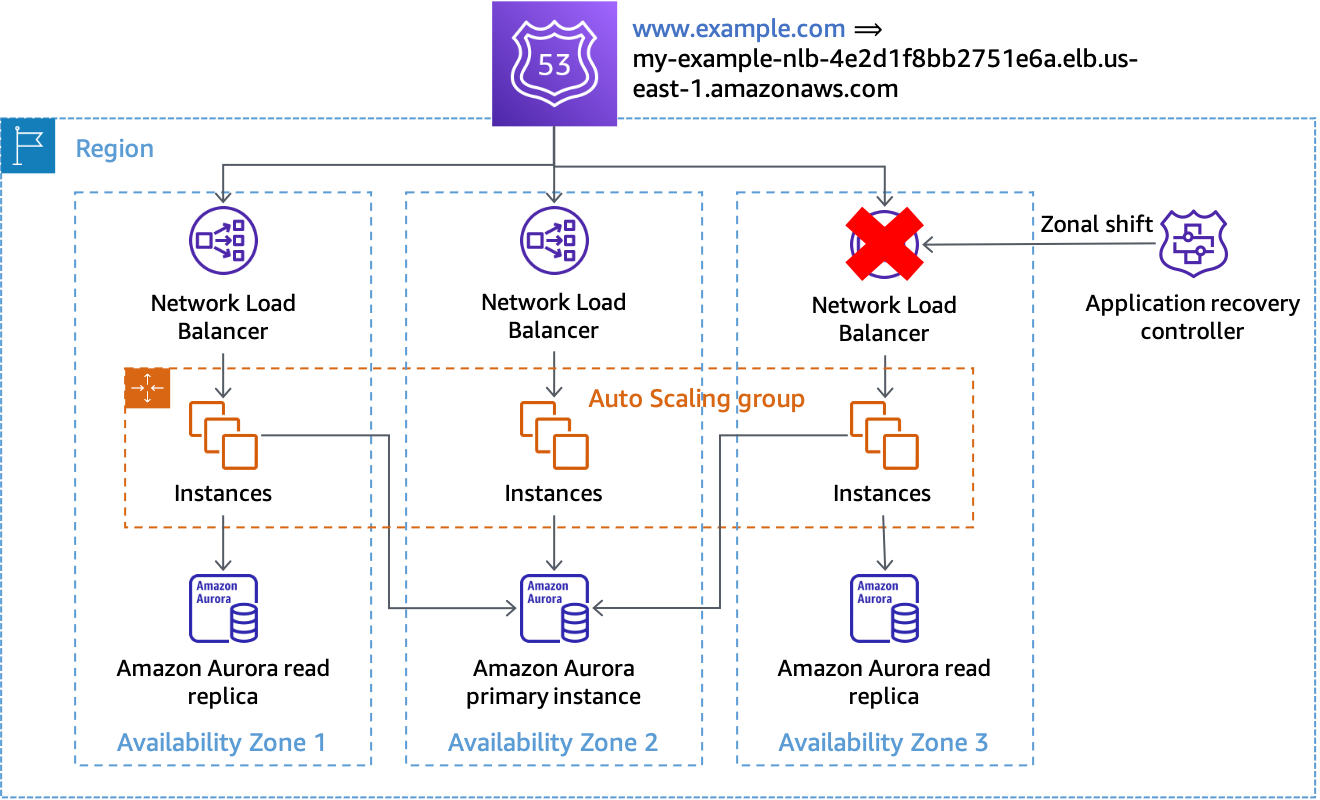
Déplacement zonal
Dans l'exemple, si l'instance de base de données principale ne se trouve pas dans la zone de disponibilité 3, l'exécution du changement de zone est la seule action requise pour obtenir le premier résultat en matière d'évacuation, à savoir empêcher le traitement du travail dans la zone de disponibilité concernée. Si le nœud principal se trouvait dans la zone de disponibilité 3, vous pouviez effectuer un basculement lancé manuellement (qui repose sur le plan de contrôle Amazon RDS) en coordination avec le décalage zonal, si Amazon RDS ne le faisait pas déjà automatiquement. Cela sera vrai pour toutes les solutions contrôlées par plan de données présentées dans cette section.
Vous devez initier le changement de zone à l'aide des commandes CLI ou de l'API afin de minimiser les dépendances requises pour démarrer l'évacuation. Plus le processus d'évacuation est simple, plus il sera fiable. Les commandes spécifiques peuvent être stockées dans un runbook local auquel les ingénieurs de garde peuvent facilement accéder. Le décalage zonal est la solution la plus recommandée et la plus simple pour évacuer une zone de disponibilité.
Route 53 ARC
La seconde solution utilise les fonctionnalités de Route 53 ARC pour spécifier manuellement l'état de santé de certains enregistrements DNS. Cette solution présente l'avantage d'utiliser le plan de données du cluster Route 53 ARC à haute disponibilité, ce qui le rend résilient à la dégradation de deux plans différentsRégions AWS. Cela implique un coût supplémentaire et nécessite une configuration supplémentaire des enregistrements DNS. Pour implémenter ce modèle, vous devez créer des enregistrements d'alias pourNoms DNS spécifiques aux zones de disponibilitéfourni par l'équilibreur de charge (ALB ou NLB). Cela est indiqué dans le tableau suivant.
Tableau 3 : Enregistrements d'alias Route 53 configurés pour les noms DNS zonaux de l'équilibreur de charge
|
Politique de routage: pondéré Nom: Type: Value (Valeur) : Poids: Évaluer la santé de la cible: vrai |
Politique de routage :pondérée Nom: Type : Valeur : Poids : Évaluez l'état de santé cible : |
Politique de routage :pondérée Nom: Type : Valeur : Poids : Évaluez l'état de santé cible : |
Pour chacun de ces enregistrements DNS, vous devez configurer un contrôle de santé de Route 53 associé à un ARC de Route 53contrôle de routage. Lorsque vous souhaitez lancer une évacuation de la zone de disponibilité, définissez l'état du contrôle du routage surOff.AWSvous recommande de le faire à l'aide de l'interface de ligne de commande ou de l'API afin de minimiser les dépendances requises pour démarrer l'évacuation de la zone de disponibilité. En tant quemeilleure pratique, vous devez conserver une copie locale des points de terminaison du cluster Route 53 ARC afin de ne pas avoir à les récupérer depuis le plan de contrôle ARC lorsque vous devez effectuer une évacuation.
Pour minimiser les coûts lors de l'utilisation de cette approche, vous pouvez créer un cluster ARC Route 53 unique et effectuer des contrôles de santé dans un seul cluster.Compte AWSetpartager les bilans de santé avec d'autresComptes AWSuse1-az1) au lieu du nom de la zone de disponibilité (par exemple,us-east-1a) pour vos commandes de routage. Parce queAWSfait correspondre la zone de disponibilité physique de manière aléatoire aux noms des zones de disponibilité pour chacuneCompte AWS, l'utilisation de l'AZ-ID fournit un moyen cohérent de faire référence aux mêmes emplacements physiques. Lorsque vous lancez l'évacuation d'une zone de disponibilité, dites pouruse1-az2, les records de la Route 53 établis dans chaqueCompte AWSdoivent s'assurer qu'ils utilisent le mappage AZ-ID pour configurer le bon bilan de santé pour chaque enregistrement NLB.
Par exemple, supposons que nous ayons un bilan de santé de Route 53 associé à un contrôle de routage Route 53 ARC pouruse1-az2, avec un identifiant de0385ed2d-d65c-4f63-a19b-2412a31ef431. Si c'est dans un autreCompte AWSqui souhaite utiliser ce bilan de santé,us-east-1ca été mappé àuse1-az2, vous devez utiliseruse1-az2bilan de santé pour le dossierus-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. Vous utiliseriez l'identifiant du bilan de santé0385ed2d-d65c-4f63-a19b-2412a31ef431avec ce record de ressources défini.
Utilisation d'un point de terminaison HTTP autogéré
Vous pouvez également implémenter cette solution en gérant votre propre point de terminaison HTTP qui indique l'état d'une zone de disponibilité particulière. Il vous permet de spécifier manuellement quand une zone de disponibilité n'est pas saine en fonction de la réponse du point de terminaison HTTP. Cette solution coûte moins cher que l'utilisation de Route 53 ARC, mais elle est plus coûteuse que le décalage zonal et nécessite la gestion d'une infrastructure supplémentaire. Il présente l'avantage d'être beaucoup plus flexible pour différents scénarios.
Le modèle peut être utilisé avec les architectures NLB ou ALB et les contrôles de santé de Route 53. Il peut également être utilisé dans des architectures sans équilibrage de charge, telles que les systèmes de découverte de services ou de traitement de files d'attente dans lesquels les nœuds de travail effectuent leurs propres contrôles de santé. Dans ces scénarios, les hôtes peuvent utiliser un fil d'arrière-plan dans lequel ils adressent régulièrement une requête au point de terminaison HTTP avec leur identifiant AZ (voirAnnexe A — Obtenir l'ID de la zone de disponibilité pour savoir comment le trouver) et recevoir en retour une réponse concernant l'état de santé de la zone de disponibilité.
Si la zone de disponibilité a été déclarée insalubre, plusieurs options s'offrent à elle pour y répondre. Ils peuvent choisir d'échouer à un contrôle de santé externe provenant de sources telles que ELB, Route 53 ou à des contrôles d'intégrité personnalisés dans des architectures de découverte de services afin de les rendre malsains aux yeux de ces services. Ils peuvent également répondre immédiatement en signalant une erreur s'ils reçoivent une demande, ce qui permet au client de revenir en arrière et de réessayer. Dans les architectures pilotées par les événements, les nœuds peuvent intentionnellement échouer à traiter le travail, par exemple en renvoyant intentionnellement un message SQS dans la file d'attente. Dans les architectures de routeurs professionnels où un service central planifie le travail sur des hôtes spécifiques, vous pouvez également utiliser ce modèle. Le routeur peut vérifier l'état d'une zone de disponibilité avant de sélectionner un travailleur, un point de terminaison ou une cellule. Dans les architectures de découverte de services qui utilisentAWS Cloud Map, tu peuxdécouvrez les points de terminaison en fournissant un filtre dans votre demande
La figure suivante montre comment cette approche peut être utilisée pour plusieurs types de charges de travail.
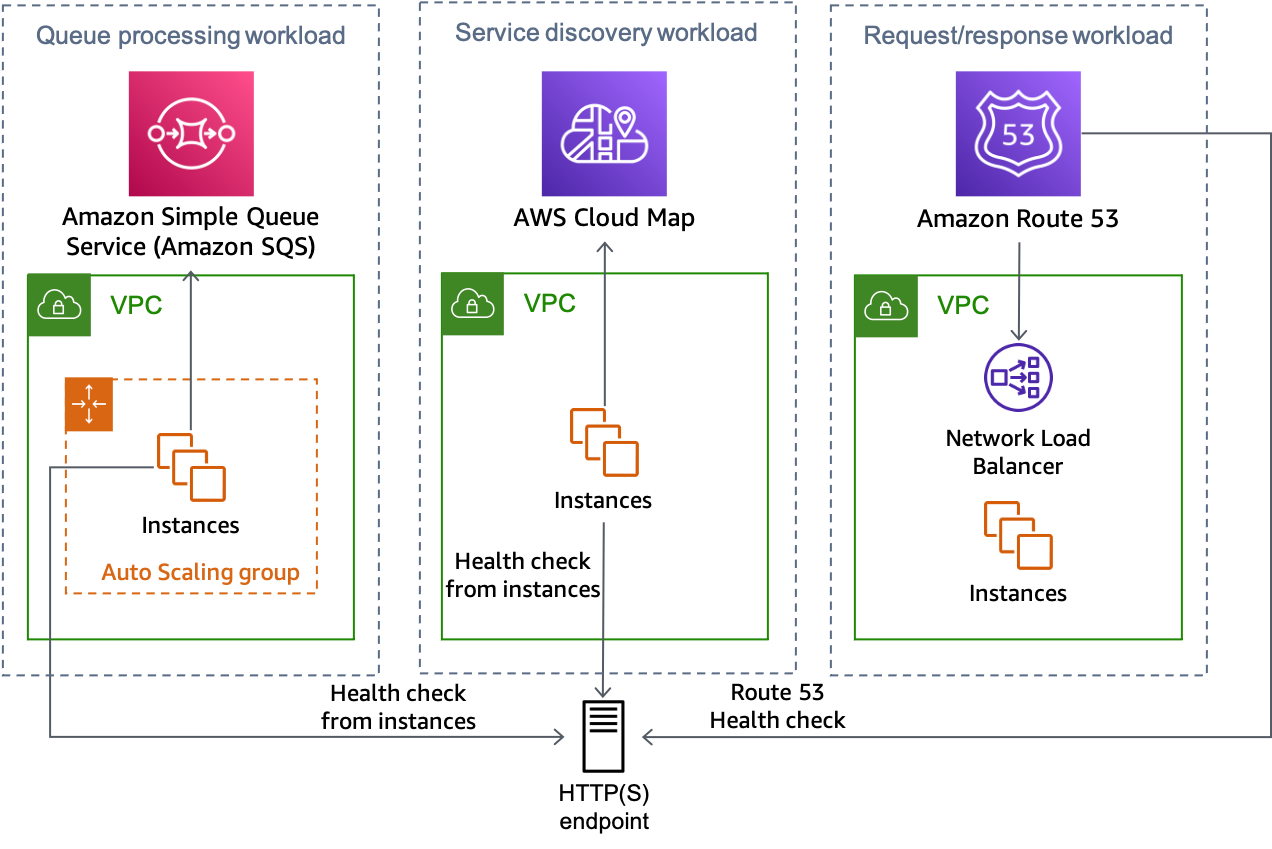
Plusieurs types de charge de travail peuvent tous utiliser la solution de point de terminaison HTTP
Il existe plusieurs manières de mettre en œuvre l'approche des points de terminaison HTTP ; deux d'entre elles sont décrites ci-dessous.
Utilisation d'Amazon S3
Ce modèle a été initialement présenté dans cearticle de blog
Dans ce scénario, vous créeriez des ensembles d'enregistrements de ressources DNS Route 53 pour chaque enregistrement DNS zonal, de la même manière que leItinéraire 53 ARCscénario ci-dessus ainsi que les bilans de santé associés. Toutefois, pour cette implémentation, au lieu d'associer les contrôles de santé aux contrôles de routage ARC Route 53, ils sont configurés pour utiliser unPoint de terminaison HTTPet sont inversés pour éviter qu'une défaillance d'Amazon S3 ne déclenche accidentellement une évacuation. Le bilan de santé est pris en compteen bonne santélorsque l'objet est absent etmauvais pour la santélorsque l'objet est présent. Cette configuration est présentée dans le tableau suivant.
Tableau 4 : Configuration des enregistrements DNS pour l'utilisation des contrôles de santé de Route 53 par zone de disponibilité
|
Type de bilan de santé: surveiller un point de terminaison Protocole : IDENTIFIANT: URL: |
Type de bilan de santé: surveiller un point de terminaison Protocole : IDENTIFIANT: URL: |
Type de bilan de santé: surveiller un point de terminaison Protocole : IDENTIFIANT: URL: |
← | Contrôles de santé |
| ↑ | ↑ | ↑ | ||
|
Politique de routage: pondéré Nom: Type: Value (Valeur) : Poids: Évaluer la santé de la cible: |
Politique de routage :pondérée Nom: Type : Value (Valeur) : Poids : Évaluez l'état de santé cible : |
Politique de routage :pondérée Nom: Type : Value (Valeur) : Poids : Évaluez l'état de santé cible : |
← | Les enregistrements d'alias A de niveau supérieur et à pondération uniforme pointent vers des points de terminaison spécifiques à NLB AZ |
Supposons que la zone de disponibilitéus-east-1aest mappé àuse1-az3dans le compte où nous avons une charge de travail où nous voulons effectuer une évacuation de la zone de disponibilité. Pour le jeu d'enregistrements de ressources créé pourus-east-1a.load-balancer-name.elb.us-east-1.amazonaws.comassocierait un bilan de santé qui teste l'URLhttps://. Lorsque vous souhaitez initier une évacuation de la zone de disponibilité pourbucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3, chargez un fichier nomméuse1-az3.txtau bucket à l'aide de l'interface de ligne de commande ou de l'API. Le fichier n'a pas besoin de contenir de contenu, mais il doit être public pour que le bilan de santé de Route 53 puisse y accéder. La figure suivante montre que cette implémentation est utilisée pour évacueruse1-az3.
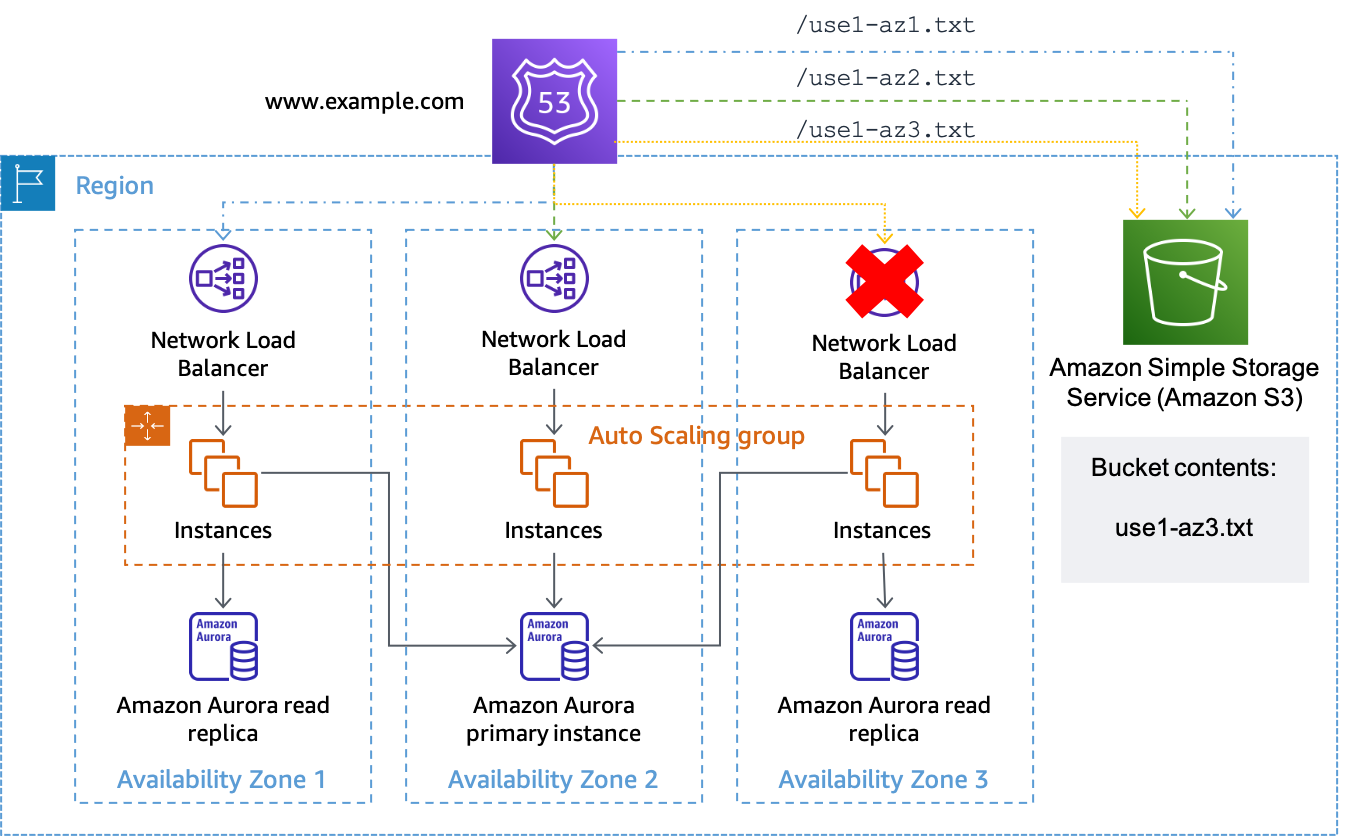
Utilisation d'Amazon S3 comme cible pour un bilan de santé de Route 53
Utilisation d'API Gateway et de DynamoDB
La deuxième implémentation de ce modèle utilise unPasserelle d'API Amazon
Si vous utilisez cette solution avec une architecture NLB ou ALB, configurez vos enregistrements DNS de la même manière que dans l'exemple Amazon S3 ci-dessus, sauf en modifiant le chemin de vérification de l'état pour utiliser le point de terminaison API Gateway et en fournissant leAZ-IDdans le chemin de l'URL. Par exemple, si la passerelle d'API est configurée avec un domaine personnalisé deaz-status.example.com, la demande complète pouruse1-az1ressemblerait àhttps://az-status.example.com/status/use1-az1. Lorsque vous souhaitez lancer l'évacuation d'une zone de disponibilité, vous pouvez créer ou mettre à jour un élément DynamoDB à l'aide de l'interface de ligne de commande ou de l'API. L'article utilise leAZ-IDcomme clé primaire, puis possède un attribut booléen appeléHealthyqui est utilisé pour indiquer comment API Gateway répond. Voici un exemple de code utilisé dans la configuration d'API Gateway pour effectuer cette détermination.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
Si l'attribut esttrue(ou n'est pas présent), API Gateway répond au contrôle de santé par un HTTP 200 ; si ce paramètre est faux, il répond par un HTTP 500. Cette implémentation est illustrée dans la figure suivante.
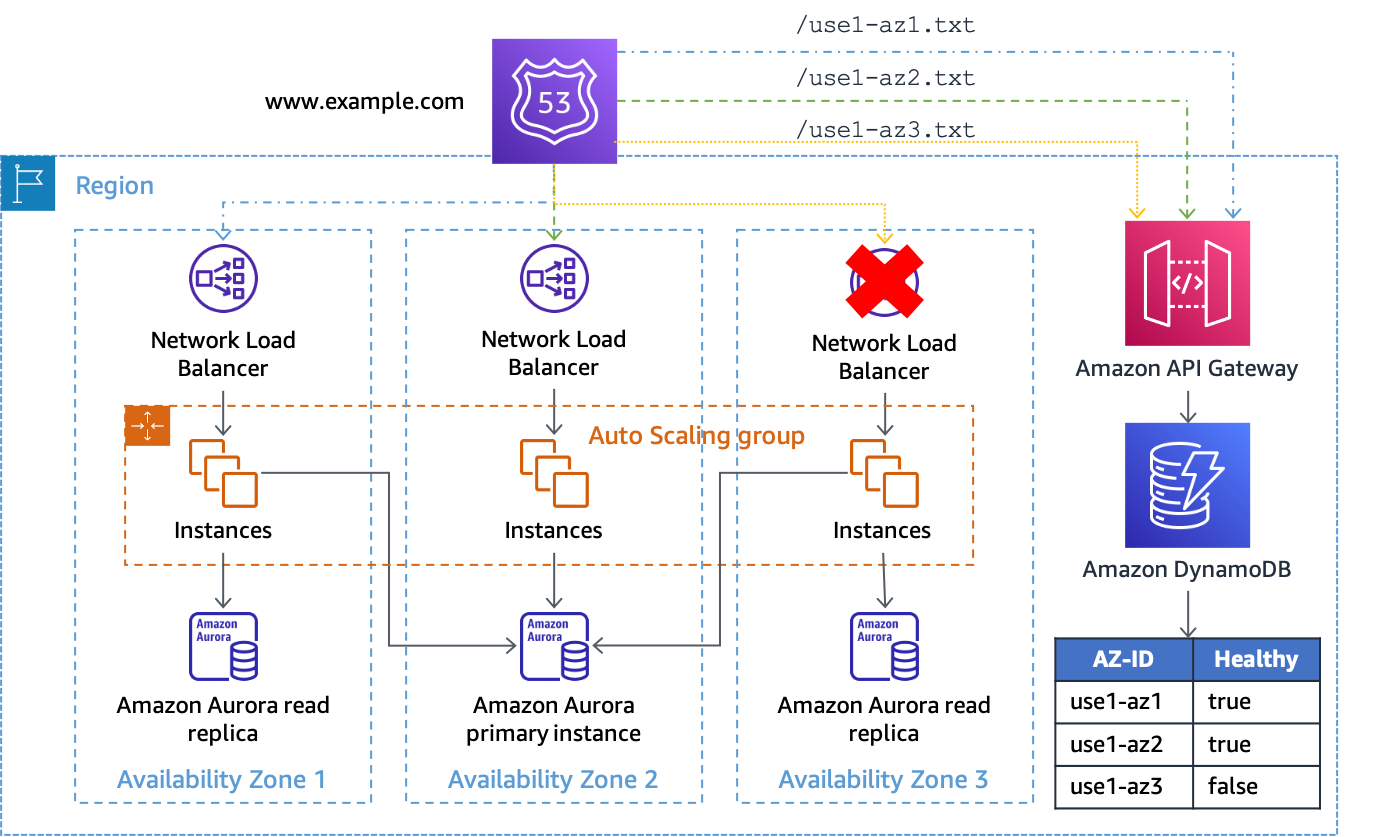
Utilisation d'API Gateway et de DynamoDB comme cible des contrôles de santé de Route 53
Dans cette solution, vous devez utiliser API Gateway en face de DynamoDB afin de rendre le point de terminaison accessible au public et de manipuler l'URL de la demande pour en faire unGetItemdemande pour DynamoDB. La solution offre également de la flexibilité si vous souhaitez inclure des données supplémentaires dans la demande. Par exemple, si vous souhaitez créer des statuts plus précis, par exemple par application, vous pouvez configurer l'URL de vérification de l'état de manière à fournir un ID d'application dans le chemin ou la chaîne de requête qui soit également mis en correspondance avec l'élément DynamoDB.
Le point de terminaison de l'état de la zone de disponibilité peut être déployé de manière centralisée afin que plusieurs ressources puissent vérifier l'état de santé deComptes AWSpeuvent tous utiliser la même vue cohérente de l'état de la zone de disponibilité (en veillant à ce que votre API REST API Gateway et votre table DynamoDB soient adaptées à la charge) et éliminent le besoin de partager les contrôles de santé de Route 53.
La solution peut également être étendue à plusieursRégions AWSà l'aide d'unTableau global Amazon DynamoDB
Si vous développiez une solution permettant à des hôtes individuels de déterminer l'état de santé de leur zone de disponibilité, vous pouvez utiliser des notifications push au lieu de fournir un mécanisme d'extraction pour les contrôles de santé. Pour ce faire, vous pouvez notamment créer une rubrique SNS à laquelle vos clients s'abonnent. Lorsque vous souhaitez déclencher le disjoncteur, publiez un message dans la rubrique SNS indiquant quelle zone de disponibilité est affectée. Cette approche fait des compromis avec la première. Il n'est plus nécessaire de créer et d'exploiter l'infrastructure API Gateway et d'effectuer la gestion des capacités. Cela peut également permettre une convergence plus rapide de l'état de la zone de disponibilité. Toutefois, il supprime la possibilité d'effectuer des requêtes ad hoc et s'appuie surPolitique relative aux nouvelles tentatives de livraison par SNSpour s'assurer que chaque point de terminaison reçoit la notification. Cela nécessite également que chaque charge de travail ou service crée un moyen de recevoir la notification SNS et d'agir en conséquence.
Par exemple, chaque nouvelle instance ou conteneur EC2 lancé devra s'abonner à la rubrique avec un point de terminaison HTTP lors de son démarrage. Ensuite, chaque instance doit implémenter un logiciel qui écoute ce point de terminaison où la notification est envoyée. En outre, si l'instance est affectée par l'événement, elle risque de ne pas recevoir la notification push et de continuer à fonctionner. En revanche, avec une notification d'extraction, l'instance saura si sa demande d'extraction échoue et pourra choisir les mesures à prendre en réponse.
Une deuxième façon d'envoyer des notifications push consiste à utiliser LonglivedWebSocketconnexions. Amazon API Gateway peut être utilisé pour fournir unWebSocketAPIauquel les consommateurs peuvent se connecter et recevoir un message lorsqueenvoyé par le backend. Avec unWebSocket, les instances peuvent à la fois effectuer des extractions périodiques pour s'assurer que leur connexion est saine et recevoir des notifications push à faible latence.
