Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Détection des défaillances grâce à la détection des valeurs aberrantes
Une lacune par rapport à l'approche précédente peut survenir lorsque vous constatez des taux d'erreur élevés dans plusieurs zones de disponibilité pour une raison non corrélée. Imaginez un scénario dans lequel des EC2 instances sont déployées dans trois zones de disponibilité et où votre seuil d'alarme de disponibilité est de 99 %. Ensuite, une défaillance d'une seule zone de disponibilité se produit, isolant de nombreuses instances et faisant chuter la disponibilité dans cette zone à 55 %. Dans le même temps, mais dans une autre zone de disponibilité, une EC2 instance unique épuise tout le stockage de son EBS volume et ne peut plus écrire de fichiers journaux. Cela l'amène à renvoyer des erreurs, mais il passe tout de même les tests de santé de l'équilibreur de charge, car ceux-ci ne déclenchent pas l'écriture d'un fichier journal. Cela se traduit par une baisse de la disponibilité à 98 % dans cette zone de disponibilité. Dans ce cas, votre seule alarme d'impact de zone de disponibilité ne s'activera pas car vous constatez un impact sur la disponibilité dans plusieurs zones de disponibilité. Cependant, vous pouvez tout de même atténuer la quasi-totalité de l'impact en évacuant la zone de disponibilité altérée.
Dans certains types de charges de travail, il est possible que vous rencontriez régulièrement des erreurs dans toutes les zones de disponibilité où l'indicateur de disponibilité précédent peut ne pas être utile. Prenons par AWS Lambda exemple. AWS permet aux clients de créer leur propre code à exécuter dans la fonction Lambda. Pour utiliser le service, vous devez télécharger votre code dans un ZIP fichier, y compris les dépendances, et définir le point d'entrée de la fonction. Mais parfois, les clients se trompent sur cette partie. Par exemple, ils peuvent oublier une dépendance critique dans le ZIP fichier ou mal saisir le nom de la méthode dans la définition de la fonction Lambda. Cela empêche l'invocation de la fonction et entraîne une erreur. AWS Lambda voit ce genre d'erreurs tout le temps, mais cela n'indique pas que quelque chose ne va pas nécessairement mal. Cependant, un problème tel qu'une altération de la zone de disponibilité peut également provoquer l'apparition de ces erreurs.
Pour détecter un signal dans ce type de bruit, vous pouvez utiliser la détection des valeurs aberrantes afin de déterminer s'il existe un écart statistiquement significatif dans le nombre d'erreurs entre les zones de disponibilité. Bien que nous constations des erreurs dans plusieurs zones de disponibilité, en cas de défaillance réelle de l'une d'entre elles, nous pouvons nous attendre à un taux d'erreur beaucoup plus élevé dans cette zone de disponibilité par rapport aux autres, voire à un taux potentiellement bien inférieur. Mais combien plus haut ou plus bas ?
L'une des méthodes de cette analyse consiste à utiliser un test du Khi carré
Un test du Khi deux évalue la probabilité qu'une certaine distribution des résultats se produise. Dans ce cas, nous nous intéressons à la distribution des erreurs sur un ensemble défini deAZs. Pour cet exemple, pour faciliter les calculs, considérez quatre zones de disponibilité.
Établissez d'abord l'hypothèse nulle, qui définit ce que vous pensez être le résultat par défaut. Dans ce test, l'hypothèse nulle est que vous vous attendez à ce que les erreurs soient réparties uniformément dans chaque zone de disponibilité. Générez ensuite l'hypothèse alternative, selon laquelle les erreurs ne sont pas réparties uniformément, ce qui indique une altération de la zone de disponibilité. Vous pouvez désormais tester ces hypothèses à l'aide des données de vos indicateurs. À cette fin, vous allez échantillonner vos statistiques sur une fenêtre de cinq minutes. Supposons que vous obteniez 1 000 points de données publiés dans cette fenêtre, dans lesquels vous voyez 100 erreurs au total. Vous vous attendez à ce qu'avec une distribution uniforme, les erreurs se produisent 25 % du temps dans chacune des quatre zones de disponibilité. Supposons que le tableau suivant montre ce que vous attendiez par rapport à ce que vous avez réellement vu.
Tableau 1 : Erreurs attendues et réelles observées
| AZ | Expected | Réel |
|---|---|---|
use1-az1 |
25 | 20 |
use1-az2 |
25 | 20 |
use1-az3 |
25 | 25 |
use1-az4 |
25 | 35 |
Donc, vous voyez qu'en réalité, la distribution n'est pas uniforme. Cependant, vous pourriez penser que cela s'est produit en raison d'un certain degré de hasard dans les points de données que vous avez échantillonnés. Il existe un certain niveau de probabilité que ce type de distribution se produise dans l'échantillon tout en supposant que l'hypothèse nulle est vraie. Cela amène à la question suivante : Quelle est la probabilité d'obtenir un résultat au moins aussi extrême ? Si cette probabilité est inférieure à un seuil défini, vous rejetez l'hypothèse nulle. Pour être statistiquement significative
1 Craparo, Robert M. (2007). « Niveau de signification ». Dans Salkind, Neil J. Encyclopedia of Measurement and Statistics 3. Thousand Oaks, CA : SAGE Publications. pages 889 à 891. ISBN1-412-91611-9.
Comment calculez-vous la probabilité d'un tel résultat ? Vous utilisez la statistique x 2 qui fournit des distributions très bien étudiées et qui peut être utilisée pour déterminer la probabilité d'obtenir un résultat aussi extrême ou plus extrême à l'aide de cette formule.
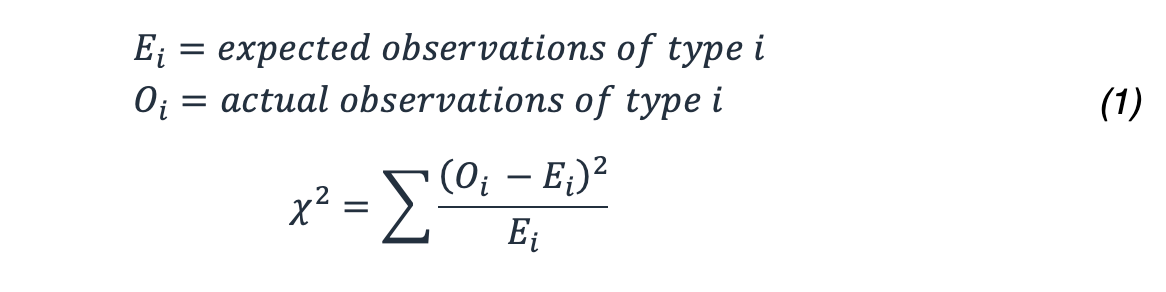
Dans notre exemple, cela se traduit par :
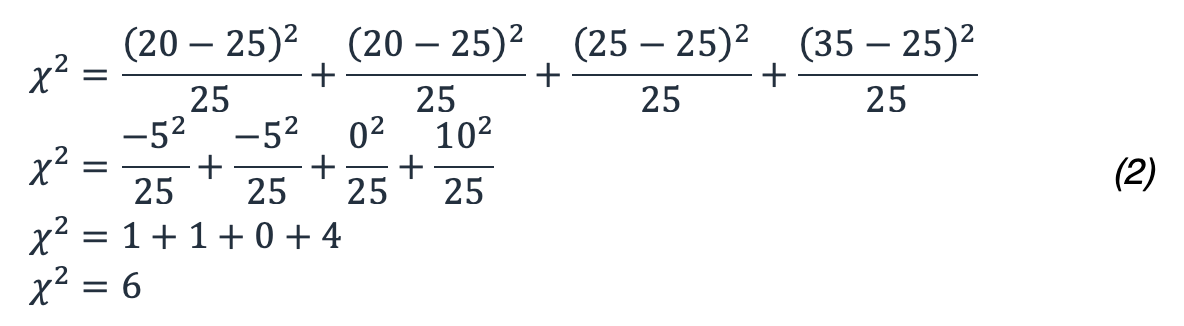
Alors, qu'est-ce 6 que cela signifie en termes de probabilité ? Vous devez examiner une distribution du chi carré avec le degré de liberté approprié. La figure suivante montre plusieurs distributions du Khi carré pour différents degrés de liberté.
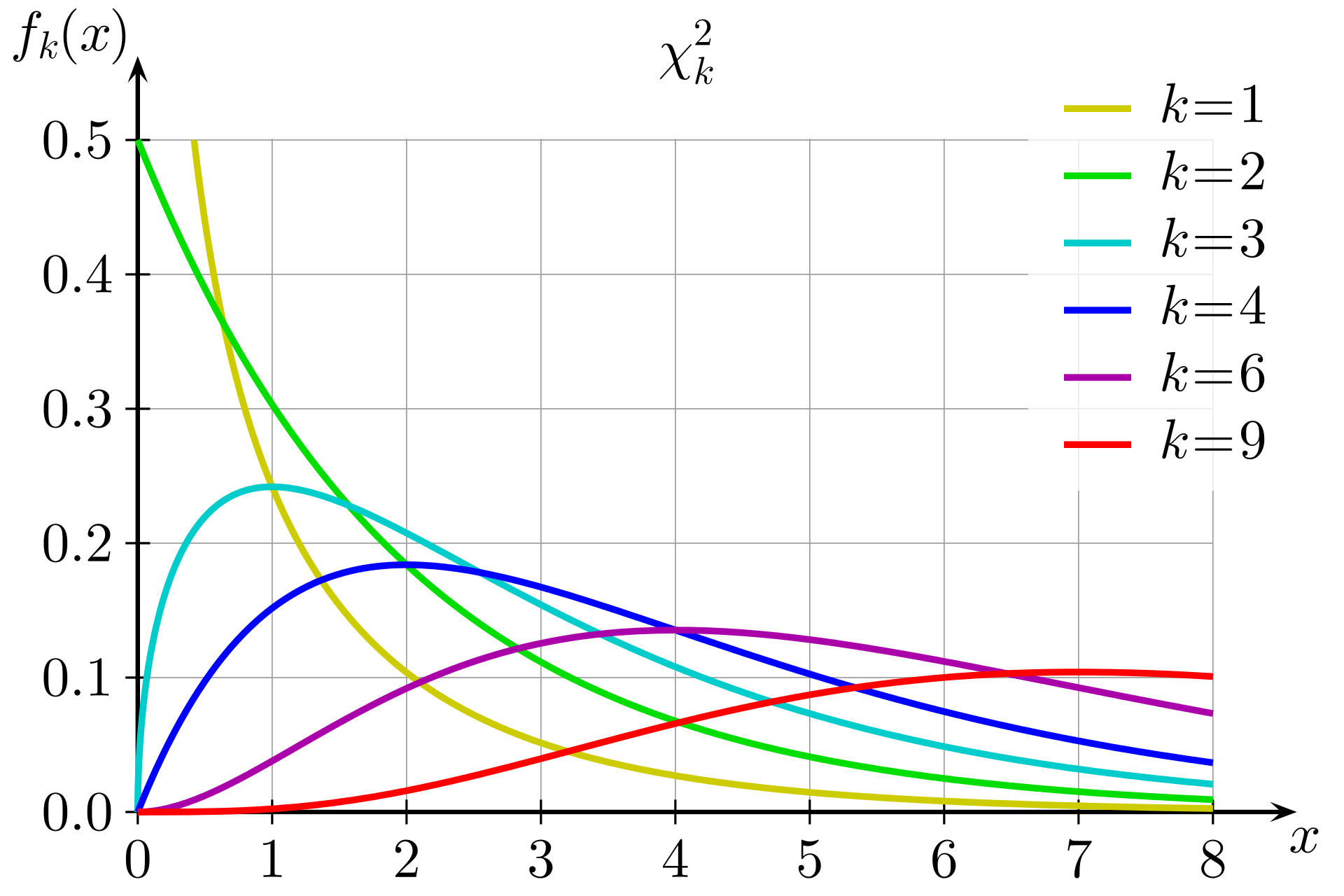
Distributions du Khi carré pour différents degrés de liberté
Le degré de liberté est calculé comme étant inférieur d'un au nombre de choix du test. Dans ce cas, étant donné qu'il existe quatre zones de disponibilité, le degré de liberté est de trois. Ensuite, vous voulez connaître l'aire sous la courbe (l'intégrale) pour x ≥ 6 sur le diagramme k = 3. Vous pouvez également utiliser un tableau précalculé avec les valeurs couramment utilisées pour obtenir une approximation de cette valeur.
Tableau 2 : Valeurs critiques du Khi au carré
| Degrés de liberté | Probabilité inférieure à la valeur critique | ||||
|---|---|---|---|---|---|
| 0,75 | 0,90 | 0,95 | 0,99 | 0,999 | |
| 1 | 1,323 | 2,706 | 3,841 | 6,635 | 10,828 |
| 2 | 2,773 | 4,605 | 5,991 | 9,210 | 13,816 |
| 3 | 4,108 | 6,251 | 7,815 | 11,345 | 16,266 |
| 4 | 5,385 | 7,779 | 9,488 | 13,277 | 18,467 |
Pour trois degrés de liberté, la valeur du Khi carré de six se situe entre les colonnes de probabilité de 0,75 et 0,9. Cela signifie qu'il y a plus de 10 % de chances que cette distribution se produise, ce qui n'est pas inférieur au seuil de 5 %. Par conséquent, vous acceptez l'hypothèse nulle et déterminez qu'il n'y a pas de différence statistiquement significative dans les taux d'erreur entre les zones de disponibilité.
L'exécution d'un test de statistiques du Khi carré n'est pas prise en charge de manière native dans les mathématiques CloudWatch métriques. Vous devrez donc collecter les mesures d'erreur applicables CloudWatch et exécuter le test dans un environnement informatique tel que Lambda. Vous pouvez décider d'effectuer ce test au niveau d'un MVC contrôleur/action ou d'un microservice individuel, ou au niveau de la zone de disponibilité. Vous devez déterminer si une altération de la zone de disponibilité affecterait de la même manière chaque contrôleur/action ou microservice, ou si une DNS défaillance peut avoir un impact sur un service à faible débit et non sur un service à haut débit, ce qui pourrait masquer l'impact une fois agrégé. Dans les deux cas, sélectionnez les dimensions appropriées pour créer la requête. Le niveau de granularité aura également un impact sur les CloudWatch alarmes que vous créez.
Collectez la métrique du nombre d'erreurs pour chaque AZ et contrôleur/action dans une fenêtre temporelle spécifiée. Tout d'abord, calculez le résultat du test du Khi deux comme étant vrai (il y avait un biais statistiquement significatif) ou faux (il n'y en avait pas, c'est-à-dire que l'hypothèse nulle est valable). Si le résultat est faux, publiez un point de données égal à 0 dans votre flux de mesures pour obtenir des résultats au chi-carré pour chaque zone de disponibilité. Si le résultat est vrai, publiez un point de données de 1 pour la zone de disponibilité avec les erreurs les plus éloignées de la valeur attendue et un 0 pour les autres (voir un Annexe B — Exemple de calcul du Khi deux exemple de code pouvant être utilisé dans une fonction Lambda). Vous pouvez suivre la même approche que les alarmes de disponibilité précédentes en créant une alarme CloudWatch métrique de 3 lignes et une alarme métrique de 3 sur 5 CloudWatch en fonction des points de données produits par la fonction Lambda. Comme dans les exemples précédents, cette approche peut être modifiée pour utiliser plus ou moins de points de données dans une fenêtre plus ou moins longue.
Ajoutez ensuite ces alarmes à votre alarme de disponibilité de zone de disponibilité existante pour la combinaison contrôleur/action, illustrée dans la figure suivante.
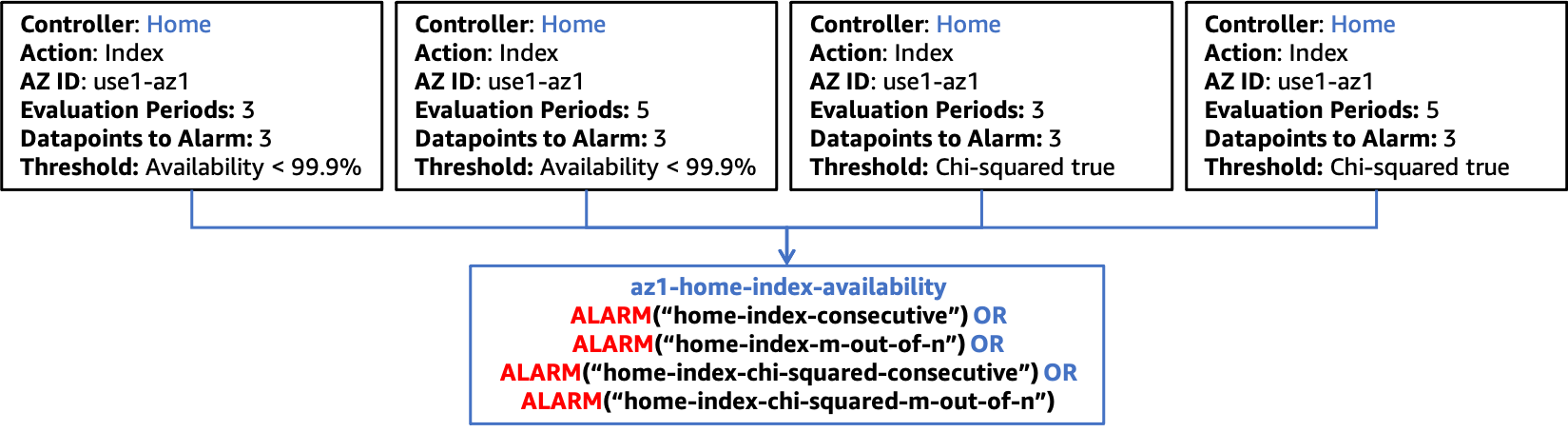
Intégration du test des statistiques du chi-carré aux alarmes composites
Comme indiqué précédemment, lorsque vous intégrez une nouvelle fonctionnalité à votre charge de travail, il vous suffit de créer les alarmes CloudWatch métriques appropriées spécifiques à cette nouvelle fonctionnalité et de mettre à jour le niveau suivant de la hiérarchie composite des alarmes pour inclure ces alarmes. Le reste de la structure de l'alarme reste statique.
