Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
 bases de données
bases de données
AWS les bases de données constituent une base performante, sécurisée et fiable pour alimenter des solutions d'IA génératives et des applications axées sur les données qui génèrent de la valeur pour votre entreprise et vos clients.
Chaque service est décrit après le schéma. Pour vous aider à choisir le service qui répond le mieux à vos besoins, voir Choisir un service AWS de base de données. Pour des informations générales, voir AWS Cloud Bases de données
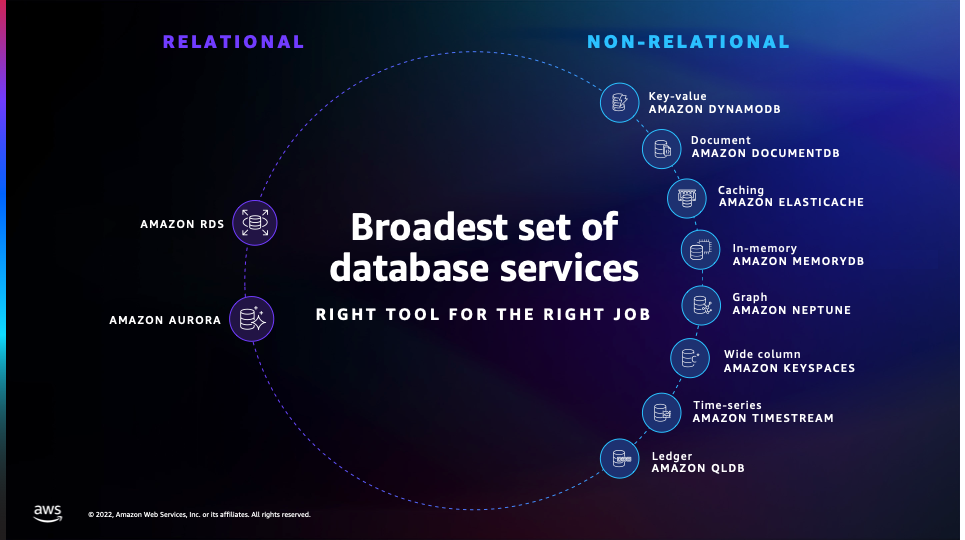
Rubriques
Retournez àAWS services.
Comparez les services AWS de base de données
| Base de données | Cas d’utilisation | Services AWS |
|---|---|---|
| Relationnel |
Applications traditionnelles, planification des ressources d'entreprise (ERP), gestion de la relation client (CRM), commerce électronique |
|
| Clé-valeur |
Applications Web à fort trafic, systèmes de commerce électronique, applications de jeu |
|
| En mémoire |
Mise en cache, gestion de session, classements de jeu, applications géospatiales |
|
| Document |
Gestion de contenu, catalogues, profils utilisateurs |
|
| Larges colonnes |
Applications industrielles à grande échelle pour la maintenance des équipements, la gestion de flotte et l'optimisation des itinéraires |
|
| Graphe |
Détection des fraudes, réseaux sociaux, moteurs de recommandation |
|
| Séries chronologiques |
Applications de l'Internet des objets (IoT) DevOps, télémétrie industrielle |
|
Amazon Aurora
Amazon Aurora
Amazon Aurora est jusqu'à cinq fois plus rapide que les bases de données MySQL standard et trois fois plus rapide que les bases de données PostgreSQL standard. Il assure la sécurité, la disponibilité et la fiabilité des bases de données commerciales à un dixième du coût. Amazon Aurora est entièrement géré par Amazon Relational Database Service (Amazon RDS), qui automatise les tâches administratives fastidieuses telles que le provisionnement du matériel, la configuration de bases de données, l'application de correctifs et les sauvegardes.
Amazon Aurora propose un système de stockage distribué, tolérant aux pannes et autoréparateur qui évolue automatiquement jusqu'à 128 To par instance de base de données. Il offre des performances et une disponibilité élevées avec jusqu'à 15 répliques en lecture à faible latence, une point-in-time restauration, une sauvegarde continue sur Amazon S3 et une réplication sur trois zones de disponibilité ()AZs.
Les I/O-Optimized is a cluster configuration that offers improved price performance and predictable pricing for customers with I/O-intensive applications, such as e-commerce applications, payment processing systems, and financial applications. Aurora-Optimized offers improved performance, increasing throughput and reducing latency to support your most demanding workloads, with up to 40 percent cost savings when your I/O dépenses Amazon Aurora dépassent 25 % des dépenses actuelles de votre base de données Aurora.
L'intégration d'Amazon Aurora MySQL Zero-ETL à Amazon Redshift, désormais disponible en version préliminaire publique, permet l'analyse en temps quasi réel et l'apprentissage automatique des données stockées dans l'édition compatible Aurora MySQL. Les données transactionnelles écrites sur Aurora sont disponibles dans Amazon Redshift en quelques secondes, sans créer ni gérer de pipelines de données complexes.
Amazon DynamoDB
Amazon DynamoDB
La plupart des entreprises les plus dynamiques au monde, telles que Lyft, Airbnb et Redfin, ainsi que des entreprises telles que Samsung, Toyota et Capital One, dépendent de l'envergure et des performances de DynamoDB pour prendre en charge leurs charges de travail critiques.
Des centaines de milliers de AWS clients ont choisi DynamoDB comme base de données de documents et de valeurs clés pour les applications mobiles, le Web, les jeux, les technologies publicitaires, l'Internet des objets (IoT) et d'autres applications nécessitant un accès aux données à faible latence à n'importe quelle échelle. Créez une nouvelle table pour votre application et laissez DynamoDB s'occuper du reste.
Amazon ElastiCache
Amazon ElastiCache
ElastiCache prend en charge deux moteurs de mise en cache en mémoire open source :
-
Redis
: un magasin de données clé-valeur rapide, open source, en mémoire, à utiliser comme base de données, cache, courtier de messages et file d'attente. Amazon ElastiCache (Redis OSS) est un service en mémoire compatible avec Redis qui fournit la puissance ease-of-use et la disponibilité de Redis, ainsi que la disponibilité, la fiabilité et les performances adaptées aux applications les plus exigeantes. Des clusters à nœud unique et jusqu'à 15 partitions sont disponibles, ce qui permet une évolutivité allant jusqu'à 3,55 TiB de données en mémoire. Amazon ElastiCache (Redis OSS) est entièrement géré, évolutif et sécurisé. Cela en fait un candidat idéal pour des cas d'utilisation performants tels que le Web, les applications mobiles, les jeux, les technologies publicitaires et l'IoT. -
Memcached
— un système de mise en cache d'objets mémoire largement adopté. Amazon ElastiCache (Memcached) est compatible avec le protocole Memcached, de sorte que les outils courants que vous utilisez aujourd'hui avec les environnements Memcached existants fonctionneront parfaitement avec le service.
Amazon ElastiCache Serverless est une option sans serveur pour Amazon ElastiCache qui simplifie la gestion du cache et s'adapte instantanément pour prendre en charge les applications les plus exigeantes. Avec ElastiCache Serverless, vous pouvez créer un cache hautement disponible et évolutif en moins d'une minute, éliminant ainsi le besoin de planifier, de provisionner et de gérer la capacité du cluster de cache. ElastiCache Serverless stocke automatiquement les données de manière redondante dans plusieurs zones de disponibilité (AZs) et fournit un accord de niveau de service
Amazon Keyspaces (pour Apache Cassandra)
Amazon Keyspaces (pour Apache Cassandra)
Amazon MemoryDB
Amazon MemoryDB
MemoryDB est compatible avec Redis, un magasin de données open source populaire, qui permet aux clients de créer rapidement des applications en utilisant les mêmes structures de données et commandes Redis flexibles et conviviales qu'ils utilisent déjà aujourd'hui. APIs Avec MemoryDB, toutes vos données sont stockées en mémoire, ce qui vous permet d'atteindre une microseconde en lecture, une latence d'écriture d'un chiffre en millisecondes et un débit élevé. MemoryDB stocke également les données de manière durable dans plusieurs zones de disponibilité à l'aide d'un journal transactionnel distribué pour permettre un basculement rapide, une restauration de base de données et un redémarrage des nœuds. Offrant à la fois des performances en mémoire et une durabilité multi-AZ, MemoryDB peut être utilisée comme base de données principale haute performance pour vos applications de microservices, éliminant ainsi le besoin de gérer séparément un cache et une base de données durable.
Amazon Neptune
Amazon Neptune
Amazon Neptune est hautement disponible, avec des répliques en lecture, une point-in-time restauration, une sauvegarde continue sur Amazon S3 et une réplication entre les zones de disponibilité. Neptune est sécurisé et prend en charge le chiffrement au repos. Neptune étant entièrement géré, vous n'avez plus à vous soucier des tâches de gestion de base de données telles que le provisionnement du matériel, l'application de correctifs logiciels, l'installation, la configuration ou les sauvegardes.
Amazon Neptune Analytics est un moteur de base de données analytique permettant d'analyser rapidement de grands volumes de données graphiques afin d'obtenir des informations et de trouver des tendances à partir des données stockées dans des compartiments Amazon S3 ou dans une base de données Neptune. Neptune Analytics utilise des algorithmes intégrés, la recherche vectorielle et le calcul en mémoire pour exécuter des requêtes sur des données comportant des dizaines de milliards de relations en quelques secondes.
Amazon Relational Database Service
Amazon Relational Database
Amazon RDS est disponible sur plusieurs types d'instances de base de données (optimisées pour la mémoire, les performances ou les E/S) et vous propose six moteurs de base de données courants, notamment MySQL, MariaDB
Amazon RDS pour DB2
Amazon RDS pour Db2
Amazon RDS sur VMware
Amazon Relational Database
Amazon RDS on vous VMware permet d'utiliser la même interface simple que celle que vous utiliseriez pour gérer les bases de données dans VMware les environnements sur site. AWS Vous pouvez facilement répliquer Amazon RDS sur des VMware bases de données vers des instances Amazon RDS AWS, ce qui permet des déploiements hybrides à faible coût pour la reprise après sinistre, l'éclatement des répliques en lecture et la conservation optionnelle des sauvegardes à long terme dans Amazon Simple Storage Service (Amazon S3).
Amazon Timestream
Amazon Timestream
Timestream est une base de données de séries chronologiques spécialement conçue qui stocke et traite efficacement ces données par intervalles de temps. Avec Timestream, vous pouvez facilement stocker et analyser les données des journaux DevOps, les données des capteurs pour les applications IoT et les données de télémétrie industrielle pour la maintenance des équipements. À mesure que vos données augmentent au fil du temps, le moteur de traitement des requêtes adaptatif Timestream comprend leur emplacement et leur format, ce qui simplifie et accélère l'analyse de vos données. Timestream automatise également les cumuls, la rétention, la hiérarchisation et la compression des données, afin que vous puissiez gérer vos données au moindre coût. Timestream fonctionne sans serveur, il n'y a donc aucun serveur à gérer. Il gère les tâches fastidieuses telles que le provisionnement des serveurs, l'application de correctifs logiciels, l'installation, la configuration ou la conservation et la hiérarchisation des données, vous permettant ainsi de vous concentrer sur le développement de vos applications.
Amazon DocumentDB (compatible avec MongoDB)
Amazon DocumentDB (compatible avec MongoDB)
Amazon DocumentDB est entièrement conçu pour vous offrir les performances, l'évolutivité et la disponibilité dont vous avez besoin pour exécuter des charges de travail MongoDB critiques à grande échelle. Amazon DocumentDB implémente les versions open source MongoDB 3.6 et 4.0 d'Apache 2.0 APIs en émulant les réponses qu'un client MongoDB attend d'un serveur MongoDB, ce qui vous permet d'utiliser vos pilotes et outils MongoDB existants avec Amazon DocumentDB (compatible avec MongoDB).
Bases de données gérées par Amazon Lightsail
Les bases de données gérées par Amazon Lightsail
Retournez àAWS services.
